该小节我们讲解一下在AudioFlinger这一层的对音量调节的代码流程,分为以下四个部分进行讲解: a. AudioFlinger对master volume, stream volume的初始化与设置 b. PlaybackThread对master volume, stream volume的初始化与设置 c. AudioTrack volume的设置 d. 这3种音量的使用
下面是音量调节调用的时序图:  在阅读时序图之前,我们先看看源码,在AudioFlinger,PlaybackThread,AudioTrack 中有没有音量相关的属性,首先打开 AudioFlinger.h:
在阅读时序图之前,我们先看看源码,在AudioFlinger,PlaybackThread,AudioTrack 中有没有音量相关的属性,首先打开 AudioFlinger.h:
bool mMasterMute; //代表master是否需要静音
float mMasterVolume; //master的音量
/**因为有多个Stream,所以其为一个数组,定义在下面*/
stream_type_t mStreamTypes[AUDIO_STREAM_CNT];
struct stream_type_t {
stream_type_t()
: volume(1.0f),
mute(false)
{
}
float volume;
bool mute; //代表是否被静音
};
我们在打开frameworks\av\services\audioflinger\Thread.h文件:
// mMasterMute is in both PlaybackThread and in AudioFlinger. When a
// PlaybackThread needs to find out if master-muted, it checks it's local
// copy rather than the one in AudioFlinger. This optimization saves a lock.
/*该变量来自于AudioFlinger中的同名变量*/
bool mMasterMute;
/*这个数组比AudioFlinger中的数组多一项用来控制DuplicatingThread对应的ouput track,其可以在两个声卡上播放同样的声音,该小节我们不关心*/
float mMasterVolume;
/*同上,用来描述一个stream的音量,以及其是否被静音*/
stream_type_t mStreamTypes[AUDIO_STREAM_CNT];
最后我们打开AudioTrack.h
/*APP设置左右声道的音量*/
float mVolume[2];
现在我们来查看一下时序图:  当AudioFlinger被构造出来的时候,mMasterVolume初始值为1,mMasterMute的初始值为flase(不静音),根据:
当AudioFlinger被构造出来的时候,mMasterVolume初始值为1,mMasterMute的初始值为flase(不静音),根据:
stream_type_t mStreamTypes[AUDIO_STREAM_CNT];
struct stream_type_t {
stream_type_t()
: volume(1.0f),
mute(false)
{
}
float volume;
bool mute; //代表是否被静音
};
我们可以知道mStreamTypes数组中,每个mStreamTypes结构体初始值,volume为1,mute为flase。其上就是他们设置初始值。在AudioFlinger构建是完成。当AudioFlinger使用loadModule加载硬件动态库(HAL文件)时:  根据时序我们找到:
根据时序我们找到:
audio_module_handle_t AudioFlinger::loadHwModule_l(const char *name)
audio_hw_device_t *dev;
/*该函数会调用hal文件中的open函数,得到一个audio_hw_device_t *dev*/
int rc = load_audio_interface(name, &dev);
/*如果提供了get_master_volume函数*/
if (NULL != dev->get_master_volume) {
/*从硬件读取MasterVolume*/
if (OK == dev->get_master_volume(dev, &mv)) {
/*硬件读取到的mMasterVolume 赋值给mMasterVolume */
mMasterVolume = mv;
/*如果提供了get_master_mute函数*/
if (NULL != dev->get_master_mute) {
/*获得masterMute*/
if (OK == dev->get_master_mute(dev, &mm)) {
/*设置mMasterMute ,代表是否静音*/
mMasterMute = mm;
/*如果HAL提供了set_master_volume函数*/
if ((NULL != dev->set_master_volume) &&
/*设置mMasterVolume,该mMasterVolume可能是读取硬件的,也可能是AudioFlinger在初始化时赋值的*/
(OK == dev->set_master_volume(dev, mMasterVolume))) {
flags = static_cast(flags |
AudioHwDevice::AHWD_CAN_SET_MASTER_VOLUME);
}
/*如果HAL提供了set_master_mute函数*/
if ((NULL != dev->set_master_mute) &&
/*设置mMasterMute,该mMasterMute可能是读取硬件的,也可能是AudioFlinger在初始化时赋值的*/
(OK == dev->set_master_mute(dev, mMasterMute))) {
flags = static_cast(flags |
AudioHwDevice::AHWD_CAN_SET_MASTER_MUTE);
}
其上的audio_hw_device_t 包含了各种函数:
......
/**
* set the audio volume for all audio activities other than voice call.
* Range between 0.0 and 1.0. If any value other than 0 is returned,
* the software mixer will emulate this capability.
*/
int (*set_master_volume)(struct audio_hw_device *dev, float volume);
/**
* Get the current master volume value for the HAL, if the HAL supports
* master volume control. AudioFlinger will query this value from the
* primary audio HAL when the service starts and use the value for setting
* the initial master volume across all HALs. HALs which do not support
* this method may leave it set to NULL.
*/
int (*get_master_volume)(struct audio_hw_device *dev, float *volume);
......
我们继续往下:  我们看看:
我们看看:
/*调用带函数,传入某个stream。以及一个value值*/
status_t AudioFlinger::setStreamVolume(audio_stream_type_t stream, float value,audio_io_handle_t output)
/*value会被保存在mStreamTypes数组的对应stream的volume中*/
mStreamTypes[stream].volume = value;
/*根据stream找到对应的线程,*/
for (size_t i = 0; i setStreamVolume(stream, value);
其上setStreamVolume的实现如下:
void AudioFlinger::PlaybackThread::setStreamVolume(audio_stream_type_t stream, float value)
{
Mutex::Autolock _l(mLock);
mStreamTypes[stream].volume = value;
broadcast_l();
}
可以知道其会把value保存在线程的PlaybackThread线程的mStreamTypes[stream].volume中。所以AudioFlinger与PlaybackThread的他们的mStreamTypes数组是一致的。其暂时只是保存起来而已,并没有写入硬件。在播放声音的时候,才会用到他。
PlaybackThread通过前面我们已经分析完成AudioFlinger,现在我们来分析PlaybackThread,受我们看看他的构造函数:  在构造函数中,其会确定上面的一些初始值,打开Thread.cpp:
在构造函数中,其会确定上面的一些初始值,打开Thread.cpp:
AudioFlinger::PlaybackThread::PlaybackThread()
// Assumes constructor is called by AudioFlinger with it's mLock held, but
// it would be safer to explicitly pass initial masterVolume/masterMute as
// parameter.
//
// If the HAL we are using has support for master volume or master mute,
// then do not attenuate or mute during mixing (just leave the volume at 1.0
// and the mute set to false).
/*其初始值来源于audioFlinger*/
mMasterVolume = audioFlinger->masterVolume_l();
mMasterMute = audioFlinger->masterMute_l();
mStreamTypes[stream].volume = mAudioFlinger->streamVolume_l(stream);
mStreamTypes[stream].mute = mAudioFlinger->streamMute_l(stream);
以上都是初始值,当然也能通过某些函数,对其进行设置:
void AudioFlinger::PlaybackThread::setMasterMute(bool muted)
if (mOutput && mOutput->audioHwDev &&
mMasterMute = false;
} else {
mMasterMute = muted;
void AudioFlinger::PlaybackThread::setMasterVolume(float value)
if (mOutput && mOutput->audioHwDev &&
mMasterVolume = 1.0;
} else {
mMasterVolume = value;
}
void AudioFlinger::PlaybackThread::setStreamMute(audio_stream_type_t stream, bool muted)
mStreamTypes[stream].volume = value;
void AudioFlinger::PlaybackThread::setStreamVolume(audio_stream_type_t stream, float value)
mStreamTypes[stream].mute = muted;
可以看到,其都是进行了一些值的保存,并没有实质的操作。现在我们讲解AudioTrack 。
AudioTrack打开AudioTrack.cpp文件,在讲解之前,我们需要回顾一个知识,我们说在应用程序创建AudioTrack时,会到时AudioFlinger中PlaybackThread的mTracks数组中创建一个Track,该Track与应用程序的AudioTrack意义对应,他们之间通过共享内存传递数据,AudioTrack与Track都是通过一个mProxy访问数据。AudioTrack的为Client mProxy,Track为Service mProxy。
:
/*传入的是左声道,已经右声道的音量*/
status_t AudioTrack::setVolume(float left, float right)
{
// This duplicates a test by AudioTrack JNI, but that is not the only caller
if (isnanf(left) || left GAIN_FLOAT_UNITY ||
isnanf(right) || right GAIN_FLOAT_UNITY) {
return BAD_VALUE;
}
AutoMutex lock(mLock);
/*传入的音量值保存在mVolume数组中*/
mVolume[AUDIO_INTERLEAVE_LEFT] = left;
mVolume[AUDIO_INTERLEAVE_RIGHT] = right;
/*setVolumeLR会把做声道与右声道的值,组装成一个数*/
mProxy->setVolumeLR(gain_minifloat_pack(gain_from_float(left), gain_from_float(right)));
if (isOffloaded_l()) {
mAudioTrack->signal();
}
return NO_ERROR;
}
其上的setVolumeLR实现如下:
// set stereo gains
void setVolumeLR(gain_minifloat_packed_t volumeLR) {
/*mCblk表示共享内存的头部,他是一个结构体,其中含有音量*/
mCblk->mVolumeLR = volumeLR;
}
从这个我们可以知道,应用程序去设置音量,也是非常简单的,调用AudioTrack中的setVolume函数就可以了。他会这些值保存在AudioTrack本身的数组中,同时也会把这个值放到共享内存的头部。
到此为止我们已经讲解了AudioFlinger,PlaybackThread,AudioTrack他们3个方面对音量设置: 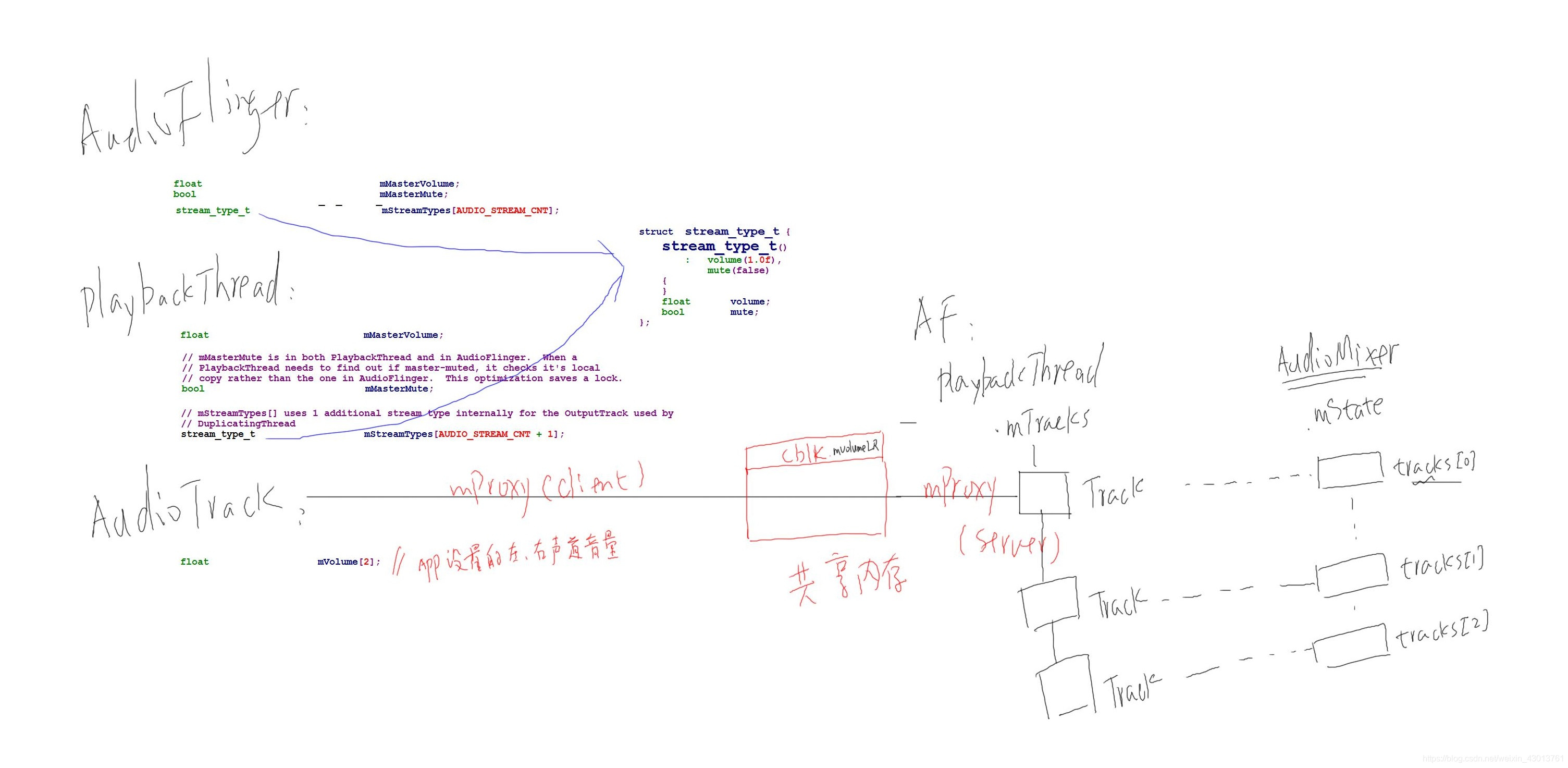
但是我们应该怎么使用呢?我们的继续往下看: 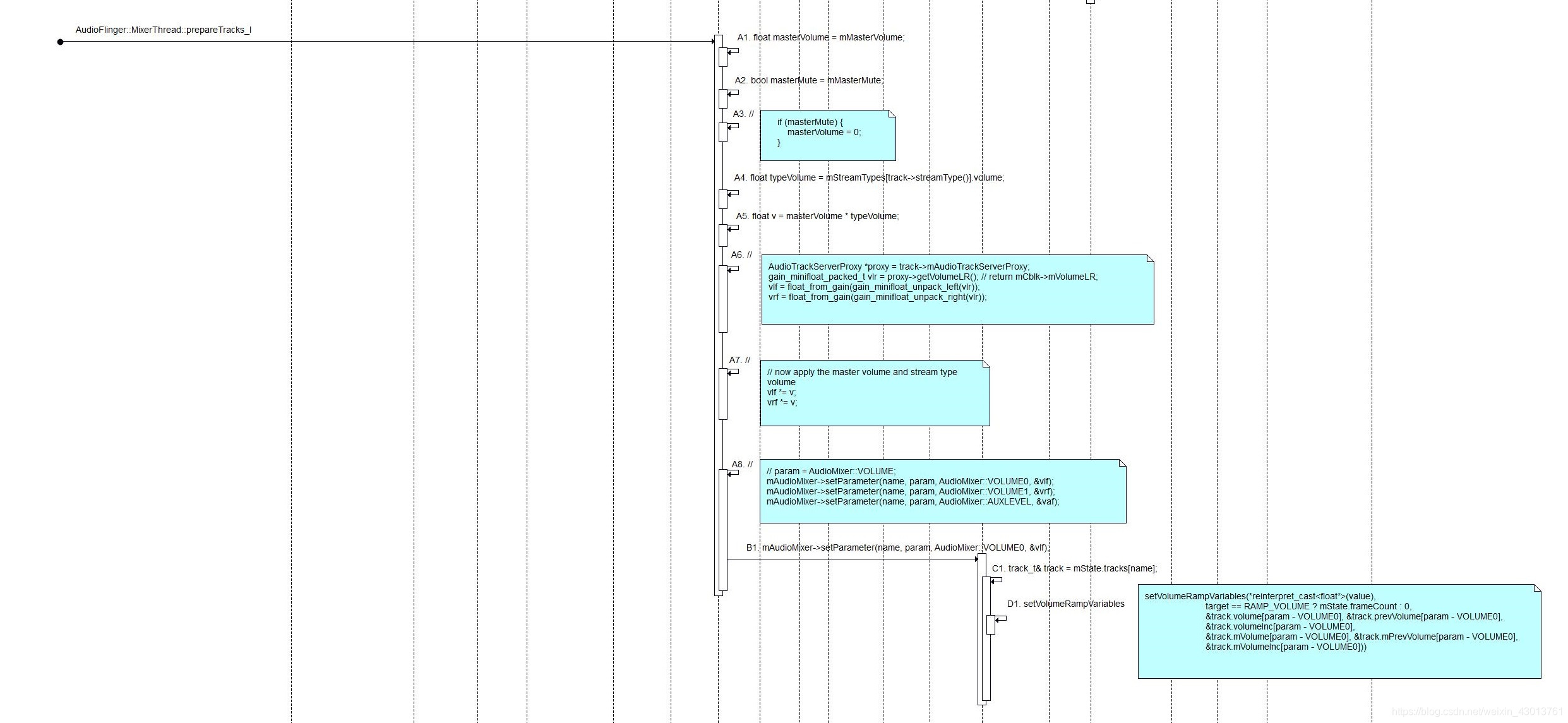 之前我们提到过,在需要播放声音的时候,需要AudioFlinger::MixerThread去准备Track中的数据,准备完成之后,在把他写入到硬件上去,所谓的准备是怎么准备呢? 就是混音,把多个需要播放的声音混合起来,对个需要播放声音的音量各有不同,所以说,我们需要一个混音器。
之前我们提到过,在需要播放声音的时候,需要AudioFlinger::MixerThread去准备Track中的数据,准备完成之后,在把他写入到硬件上去,所谓的准备是怎么准备呢? 就是混音,把多个需要播放的声音混合起来,对个需要播放声音的音量各有不同,所以说,我们需要一个混音器。
每个线程都有一个AudioMixer,他负责吧多个Track中的数据混合播放,在AudioMixer中会对每一个音量,都有一个结构体与其对应,我们打开AudioMixer.h:
class AudioMixer
struct track_t {
......
// TODO: Eventually remove legacy integer volume settings
union {
int16_t volume[MAX_NUM_VOLUMES]; // U4.12 fixed point (top bit should be zero)
int32_t volumeRL;
};
int32_t prevVolume[MAX_NUM_VOLUMES];
int32_t volumeInc[MAX_NUM_VOLUMES];
};
struct state_t {
uint32_t enabledTracks;
uint32_t needsChanged;
size_t frameCount;
process_hook_t hook; // one of process__*, never NULL
int32_t *outputTemp;
int32_t *resampleTemp;
NBLog::Writer* mLog;
int32_t reserved[1];
// FIXME allocate dynamically to save some memory when maxNumTracks < MAX_NUM_TRACKS
track_t tracks[MAX_NUM_TRACKS] __attribute__((aligned(32)));
};
在上小节中,我们简单的描述过怎么混音:
app1:
data1_mix = data1_in * master_volume * stream1_volume * AudioTrack1_volume
app2:
data2_mix = data2_in * master_volume * stream2_volume * AudioTrack2_volume
混合在一起:
data_mix = data1_mix + data2_mix
根据时序图我们打开Thread.cpp,找到AudioMixer中的:
AudioFlinger::PlaybackThread::mixer_state AudioFlinger::MixerThread::prepareTracks_l(Vector *tracksToRemove)
/*取出masterMute,masterVolume*/
float masterVolume = mMasterVolume;
bool masterMute = mMasterMute;
/*如果masterMute = 1,则表示其想静音*/
if (masterMute) {
/*让音量为0*/
masterVolume = 0;
}
/*一个循环*/
for (size_t i=0 ; istreamType()].volume;
float v = masterVolume * typeVolume;
AudioTrackServerProxy *proxy = track->mAudioTrackServerProxy;
/*从proxy中取出取出音量,其就是通过头部保存的音量,其含有左右声道的音量*/
gain_minifloat_packed_t vlr = proxy->getVolumeLR();
/*提取左右声道的值*/
vlf = float_from_gain(gain_minifloat_unpack_left(vlr));
vrf = float_from_gain(gain_minifloat_unpack_right(vlr));
/*都与之前的V进行相乘*/
vlf *= v; //master_volume * stream_volume * AudioTrack_left
vrf *= v; //master_volume * stream_volume * AudioTrack_right
/*把vlf与vrf传入给AudioMixer*/
mAudioMixer->setParameter(name, param, AudioMixer::VOLUME0, &vlf);
mAudioMixer->setParameter(name, param, AudioMixer::VOLUME1, &vrf);
我们知道
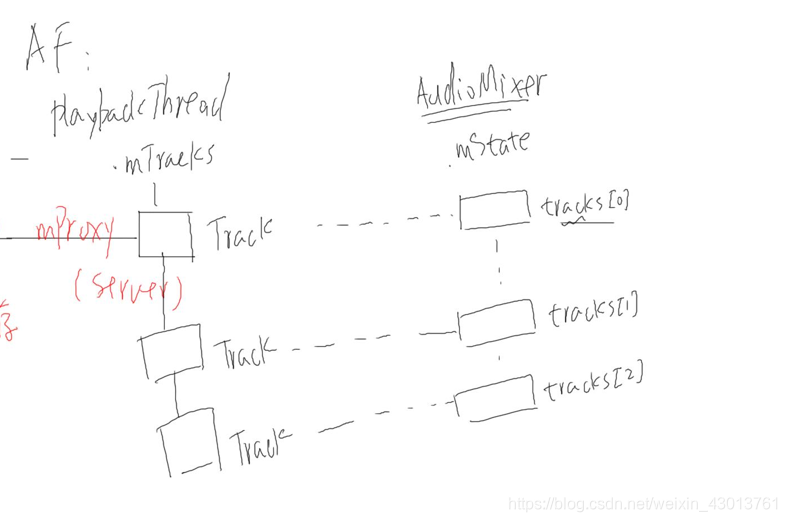 AudioFlinger中PlaybackThread的每个Track,在MixerThread中都有一个Track与他对应,我们来看看Track结构体:
AudioFlinger中PlaybackThread的每个Track,在MixerThread中都有一个Track与他对应,我们来看看Track结构体:  根据前面的分析我们知道,当调用AudioFlinger::PlaybackThread::mixer_state AudioFlinger::MixerThread::prepareTracks_l会导致一下事情发生: 会把每一个AudioTrack的音量保存到AudioMixer中对应的Track结构体,其会保存在Trackr的如下蓝色变量中,其有两种保存方式:
根据前面的分析我们知道,当调用AudioFlinger::PlaybackThread::mixer_state AudioFlinger::MixerThread::prepareTracks_l会导致一下事情发生: 会把每一个AudioTrack的音量保存到AudioMixer中对应的Track结构体,其会保存在Trackr的如下蓝色变量中,其有两种保存方式: 
union {
int16_t volume[MAX_NUM_VOLUMES]; // U4.12 fixed point (top bit should be zero)
int32_t volumeRL;
};
int32_t prevVolume[MAX_NUM_VOLUMES];
一种是整数保存,一种是浮点数保存,K= master_volume * stream2_volume * AudioTrack volume ,其值K为一个系数,这个系数,在接下来的混音过程中会用到,我们先忽略在AudioMixer的track_t中怎么保存音量,我们先来看看这个系数怎么在混音过程中起到作用。
打来AudioMixer.h文件,之前提到过混音时,实际上对每个track的处理最终都会调用到这些track的函数如:
static void track__genericResample(track_t* t, int32_t* out, size_t numFrames, int32_t* temp,
int32_t* aux);
static void track__nop(track_t* t, int32_t* out, size_t numFrames, int32_t* temp, int32_t* aux);
static void track__16BitsStereo(track_t* t, int32_t* out, size_t numFrames, int32_t* temp,
int32_t* aux);
static void track__16BitsMono(track_t* t, int32_t* out, size_t numFrames, int32_t* temp,
int32_t* aux);
static void volumeRampStereo(track_t* t, int32_t* out, size_t frameCount, int32_t* temp,
int32_t* aux);
static void volumeStereo(track_t* t, int32_t* out, size_t frameCount, int32_t* temp,
int32_t* aux);
等等,我们查看一下:
/*处理十六位的立体声数据*/
void AudioMixer::track__16BitsStereo(track_t* t, int32_t* out, size_t frameCount,int32_t* temp __unused, int32_t* aux)
// constant gain
else {
/*这里的volumeRL就是比例系数,前面说的K*/
const uint32_t vrl = t->volumeRL;
do {
/*取出原始数据,其为32为,即包含了左右声道的数据*/
uint32_t rl = *reinterpret_cast(in);
in += 2;
/*保存最终的左声道数据*/
out[0] = mulAddRL(1, rl, vrl, out[0]);
/*保存最终的右声道数据*/
out[1] = mulAddRL(0, rl, vrl, out[1]);
out += 2;
} while (--frameCount);
}
现在我们来讲讲AudioMixer中,音量如何保存,前面提到有两种,一种为整数保存,一种为float。后面我们都会使用float,这是发展趋势。但是现在我们android系统使用的是整数方式,那么他是怎么保存的呢? 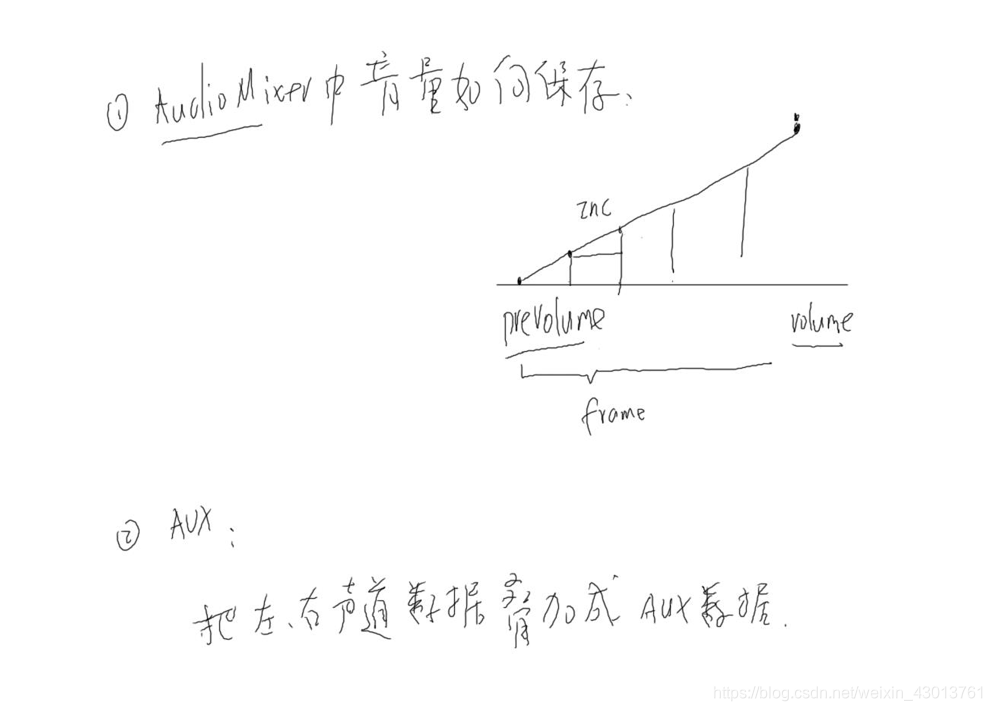 如上,我们的嗓声音从原来的很低,突然提到很高,人的耳朵可能一下受不了,所以AudioMixer给了一种方法,可以让声音慢慢提升,前一步与后一步的差值就是inc,即阶梯值。所以现在我们看看:
如上,我们的嗓声音从原来的很低,突然提到很高,人的耳朵可能一下受不了,所以AudioMixer给了一种方法,可以让声音慢慢提升,前一步与后一步的差值就是inc,即阶梯值。所以现在我们看看: 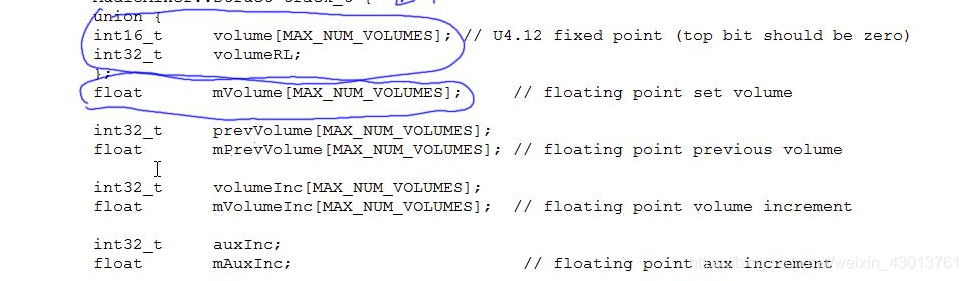 注意其上分为了小数和整数。其上的aux,代表当通道,有的设备只能支持一个声道的数据,那么就会把左右声道进行合成。
注意其上分为了小数和整数。其上的aux,代表当通道,有的设备只能支持一个声道的数据,那么就会把左右声道进行合成。


