以下链接是个人关于MVSNet(R-MVSNet)-多视角立体深度推导重建 所有见解,如有错误欢迎大家指出,我会第一时间纠正。有兴趣的朋友可以加微信:17575010159 相互讨论技术。若是帮助到了你什么,一定要记得点赞!因为这是对我最大的鼓励。 文末附带 \color{blue}{文末附带} 文末附带 公众号 − \color{blue}{公众号 -} 公众号− 海量资源。 \color{blue}{ 海量资源}。 海量资源。
3D点云重建0-00:MVSNet(R-MVSNet)–目录-史上最新无死角讲解:https://blog.csdn.net/weixin_43013761/article/details/102852209
话不多说,我们继续前面的3.3 Depth Map
3.3 Depth Map。。。。。。
Depth Map Refinement 从probability volume,也就是论文图示的这个部分:  得到的,是一个不错的深度图,但是因为比较大的感受野范围进行了正则化,边界可能会存在平滑的现象(翻译得有模有样,但是不知道啥意思)。他有点类似于语义分割,或者说抠图。为什么这么说?因为r img肯定是包含了边界信息的,因此我们用r img去对初始深度图进行提炼,让深度图的表述更加精确。其灵感主要来自于最近比较流行的抠图算法,在MVSNet最后阶段,我们采用了端到端训练的残差网络对MVSNet,把r img图像改变成和初始深度图的大小一样,然后他他们组合成4个通道的特征图,当作网络的输入,如下:
得到的,是一个不错的深度图,但是因为比较大的感受野范围进行了正则化,边界可能会存在平滑的现象(翻译得有模有样,但是不知道啥意思)。他有点类似于语义分割,或者说抠图。为什么这么说?因为r img肯定是包含了边界信息的,因此我们用r img去对初始深度图进行提炼,让深度图的表述更加精确。其灵感主要来自于最近比较流行的抠图算法,在MVSNet最后阶段,我们采用了端到端训练的残差网络对MVSNet,把r img图像改变成和初始深度图的大小一样,然后他他们组合成4个通道的特征图,当作网络的输入,如下:  然后经过经过11层,通道数为32的2D卷积,输出一个单通道的深度图,这个深度图就是上面的Refined Depth Map。在2D卷积的最后一层是没有使用BN,ReLU以及残差网络单元。另外为了防止一定范围内的偏差,在送入网络的时候,把像素转化到[0,1],等提炼之后再恢复过来。
然后经过经过11层,通道数为32的2D卷积,输出一个单通道的深度图,这个深度图就是上面的Refined Depth Map。在2D卷积的最后一层是没有使用BN,ReLU以及残差网络单元。另外为了防止一定范围内的偏差,在送入网络的时候,把像素转化到[0,1],等提炼之后再恢复过来。
loss部分其实很好理解。他主要考虑到两方面的loss,一个GT(ground truth )与初始深度图计算损失,一个是与提炼之后的深度图计算损失。再这里还要涉及的一个问题就是,我们的GT(ground truth )可能只有部分是有效的的,如下:  可以看待GT中,有的地方是紫色的,可以理解为背景。对于背景是不需要参与损失计算的。所以我们再源码中看到mask的操作(后续讲解),计算loss的公式如下,万变不离其宗,就是像素做差:
可以看待GT中,有的地方是紫色的,可以理解为背景。对于背景是不需要参与损失计算的。所以我们再源码中看到mask的操作(后续讲解),计算loss的公式如下,万变不离其宗,就是像素做差: 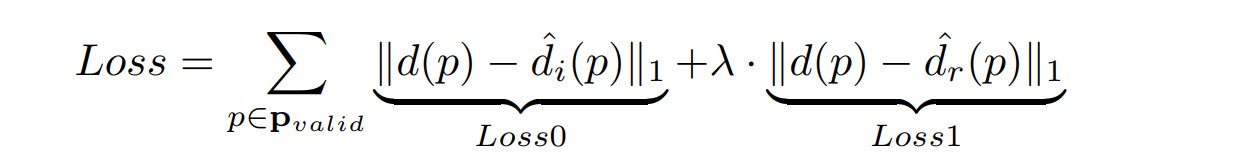 这里的
P
v
a
l
i
d
P_{valid}
Pvalid表示的就是GT有效的像素,
d
(
p
)
d(p)
d(p)表示GT中像素P的深度,
d
^
i
(
p
)
\hat{d}_i(p)
d^i(p)表示初始深度图像素p的深度,
d
^
r
(
p
)
\hat{d}_r(p)
d^r(p)表示提炼深度图像素p的深度,其中的参数
λ
\lambda
λ在实验中是被设置为1的。
这里的
P
v
a
l
i
d
P_{valid}
Pvalid表示的就是GT有效的像素,
d
(
p
)
d(p)
d(p)表示GT中像素P的深度,
d
^
i
(
p
)
\hat{d}_i(p)
d^i(p)表示初始深度图像素p的深度,
d
^
r
(
p
)
\hat{d}_r(p)
d^r(p)表示提炼深度图像素p的深度,其中的参数
λ
\lambda
λ在实验中是被设置为1的。
Data Preparation 现在 MVS的数据集提供的GT一般都是点云或者网格形式,所以我们需要取去产生深度图的GT。DTU是一个比较大的MVS(多视角立体)数据集,其中的图像包含了一百多个场景,每个场景都有不同的关照强度对应,并且带有正常点云的相关标签,我们只使用过滤出来的screened Poisson surface reconstruction(SPSR-大概是个神经网络,猜的)去生成网格曲面, 然后根据这些视点生成我们训练要的深度图。为了获得高质量的网格结果,我们把SPSR的参数,depth-of-tree设置为11,trimming-factor为9.5(减少边缘区域网格的虚影)。MVSNet在和其他的网络做比较的时候,我们选择了相同的训练集和测试集。考虑到每个scan(后面代码分析解释)中有49种图片,每种图片带有7种不同的关照强度。我们会把每个图片都当初r img进行训练。DTU 数据集总共提供了27097个训练样本。 View Selection 我们每次训练使用一张r img和两张s img(N=3),那么我们怎么去选择这些视角图呢?作者定义了一个分值
s
(
i
,
j
)
=
∑
p
G
(
θ
i
j
(
p
)
)
s(i,j) = \sum_pG(\theta_{ij}(p))
s(i,j)=∑pG(θij(p))。对每个s img都会和r img计算这个
s
s
s分值,这里
p
p
p是两幅图 i img和 j img的公共轨迹,
θ
i
j
(
p
)
=
(
180
/
π
)
a
r
c
c
o
s
(
(
c
i
−
p
)
⋅
(
c
j
−
p
)
)
\theta_{ij}(p)=(180/\pi)arccos((c_i-p)·(c_j-p))
θij(p)=(180/π)arccos((ci−p)⋅(cj−p))表示的是
P
P
P偏移基线的角度,
c
c
c表示的是摄像头的中心。
G
G
G是一个高斯分段函数,根据
θ
\theta
θ的不同,计算方式不一样:  在实验中,
θ
\theta
θ,
σ
1
\sigma_1
σ1,
σ
2
\sigma_2
σ2分别被设置为5,1,和10。为什么要根据这个公式来计算S,然后根据S选择视觉图,我也不是很了解,如果我后面想通了,就为大家解释一下,如果没有想明白,那就算了哈。
当然,如果那位大佬想明白了,一定要告知我,小的感激不尽!
\color{#FF0000}{当然,如果那位大佬想明白了,一定要告知我,小的感激不尽!}
当然,如果那位大佬想明白了,一定要告知我,小的感激不尽! 注意的是,这些视角图在进行特征提取的时候都会变小,然后放入4个缩放尺寸的3D编码-解码卷积,输入图像的尺寸必须能被32整除。考虑到GPU内存消耗的原因,我们把图片由原来的1600×1200缩小到800×600,然后围绕着中心点进行剪裁,剪裁成W = 640 和 H = 512的图片当作网络的输入,所以输入摄像头的参数也要随之变化。假如输入的样本,其深度均匀的分布在[425,935]mn,分辨率为2mn(D=256),我们编程的框架是TensorFlow,使用Tesla P100显卡,迭代了100 000次。
在实验中,
θ
\theta
θ,
σ
1
\sigma_1
σ1,
σ
2
\sigma_2
σ2分别被设置为5,1,和10。为什么要根据这个公式来计算S,然后根据S选择视觉图,我也不是很了解,如果我后面想通了,就为大家解释一下,如果没有想明白,那就算了哈。
当然,如果那位大佬想明白了,一定要告知我,小的感激不尽!
\color{#FF0000}{当然,如果那位大佬想明白了,一定要告知我,小的感激不尽!}
当然,如果那位大佬想明白了,一定要告知我,小的感激不尽! 注意的是,这些视角图在进行特征提取的时候都会变小,然后放入4个缩放尺寸的3D编码-解码卷积,输入图像的尺寸必须能被32整除。考虑到GPU内存消耗的原因,我们把图片由原来的1600×1200缩小到800×600,然后围绕着中心点进行剪裁,剪裁成W = 640 和 H = 512的图片当作网络的输入,所以输入摄像头的参数也要随之变化。假如输入的样本,其深度均匀的分布在[425,935]mn,分辨率为2mn(D=256),我们编程的框架是TensorFlow,使用Tesla P100显卡,迭代了100 000次。
Depth Map Filter(深度图过滤) 上面的网络是对每个像素进行深度估算,处于转化为3D点云操作的前面,有必要过滤掉背景以及一些异常点。我们提出了两种标准,称为photometric(关照)和geometric(几何) 一致性的深度图过滤。 photometric一致性深度匹配质量:在前面我们提到过,我们使用probability map(概率图)去评估深度估算的质量。可以注意到,这个体素概率低于0.8的可以看作离群点。  geometric 约束测量多个视角:其类似于这个人眼,利用左右视角差去观测立体目标。我们将参考像素
p
1
p_1
p1通过他的深度
d
1
d_1
d1投影到其他的视角像素
p
i
p_i
pi,然后根据
p
i
p_i
pi的深度
d
i
d_i
di,又把
p
i
p_i
pi重映射到r img上面。简单的说,把其他2维视觉图,映射到立体空间,然后再重立体空间映射到另外一个视角。如果重映射的坐标
p
r
e
p
r
o
j
p_{reproj}
preproj 和重映射深度
d
r
e
p
r
o
j
d_{reproj}
dreproj 分别满足
∣
p
r
e
p
r
o
j
−
p
1
∣
<
1
|p_{reproj}-p_1|
geometric 约束测量多个视角:其类似于这个人眼,利用左右视角差去观测立体目标。我们将参考像素
p
1
p_1
p1通过他的深度
d
1
d_1
d1投影到其他的视角像素
p
i
p_i
pi,然后根据
p
i
p_i
pi的深度
d
i
d_i
di,又把
p
i
p_i
pi重映射到r img上面。简单的说,把其他2维视觉图,映射到立体空间,然后再重立体空间映射到另外一个视角。如果重映射的坐标
p
r
e
p
r
o
j
p_{reproj}
preproj 和重映射深度
d
r
e
p
r
o
j
d_{reproj}
dreproj 分别满足
∣
p
r
e
p
r
o
j
−
p
1
∣
<
1
|p_{reproj}-p_1|

- 史上最全slam从零开始-总目录
- (01)ORB-SLAM2源码无死角解析-(00)目录_最新无死角讲解
- 目标检测00-00:mmdetection(Foveabox为例)-目录-史上最新无死角讲解
- 风格迁移1-00:Liquid Warping GAN(Impersonator)-目录-史上最新无死角讲解
- 姿态估计1-00:FSA-Net(头部姿态估算)-目录-史上最新无死角讲解
- 姿态估计0-00:DenseFusion(6D姿态估计)-目录-史上最新无死角讲解
- 3D点云重建0-00:MVSNet(R-MVSNet)-目录-史上最新无死角讲解
- 视觉工作项目-为后来的你,提供一份帮助!
- 行人检测0-00:LFFD-目录-史上最新无死角解读
- 行人重识别0-00:DG-Net(ReID)-目录-史上最新无死角讲解

