
ffmpeg内置了很多滤镜库,都封装在AVFilter模块中,通过这个滤镜模块可以用来更加方便的处理音视频。比如视频分辨率压缩滤镜scale(用来对视频的分辨率进行缩放),视频翻转滤镜transpose(对视频进行上下左右的翻转);音频格式转换滤镜aformat(它实际上最终是调用avresample滤镜实现的),volume(用来调整音量大小)等等。
-
关于ffmpeg的滤镜AVFilter源码及编译 1、默认情况下libavfilter模块会编译如下文件: OBJS = allfilters.o audio.o avfilter.o avfiltergraph.o buffersink.o buffersrc.o drawutils.o fifo.o formats.o framepool.o framequeue.o graphdump.o graphparser.o transform.o video.o 以上来自libavfilter/Makefile,所以就算编译ffmpeg时加入--disable-filters 也会将这些文件编译进去生成libavfilter库; 如果要将整个libavfilter模块禁用掉,在根目录Makefile将如下语句注释掉即可: FFLIBS-$(CONFIG_AVFILTER) += avfilter
2、如果要使用音频格式转换滤镜时需要添加如下选项: aformat滤镜用于音频格式(如采样率,采样格式,声道类型)的转换(相当于实现了SwrContext的功能),它内部最终调用的aresample滤镜,而aresample滤镜内部又是用libswresample模块 的SwrContext实现的 --enable-filter=aformat;--enable-filter=aresample 3、如果要使用音频声音变化滤镜时需要添加如下选项: --enable-filter=volume 4、分别对应的滤镜名称为 ff_af_aformat;ff_af_aresample;ff_af_volume 5、ffmpeg所有的滤镜在libavfilter/filter_list.c文件下
通过aformat滤镜和volume滤镜实现音频格式转换,音量调整功能来学习滤镜的使用流程,其实不管是音频还是视频滤镜使用流程都是一样的。
ffmpeg的音频滤镜是通过滤镜管道来进行管理的,滤镜管道可以将各个滤镜连接到一起,形成一个处理流水线,流程如下: srcfilter-->volumefilter->aformat....->otherfilter->sinkfilter
- 1、一个音频滤镜管道必须要有一个输入滤镜(abuffer,用于接收要处理的数据),一个输出滤镜(abuffersink,用于提供处理好的数据)
- 2、每一个滤镜(AVFilter)都有一个滤镜上下文AVFilterContext(也称为滤镜实例)与之对应,滤镜的参数通过这个上下文来设置
- 3、输入滤镜的输出端口连接着volume滤镜的输入端口,volume滤镜的输出端口连接着aformat的输入端口,aformat的输出端口连接着输出滤镜的输入端口, 这样就形成了一个滤镜处理链
音频滤镜的使用流程有两种方式,这里分别进行说明。 方式一:
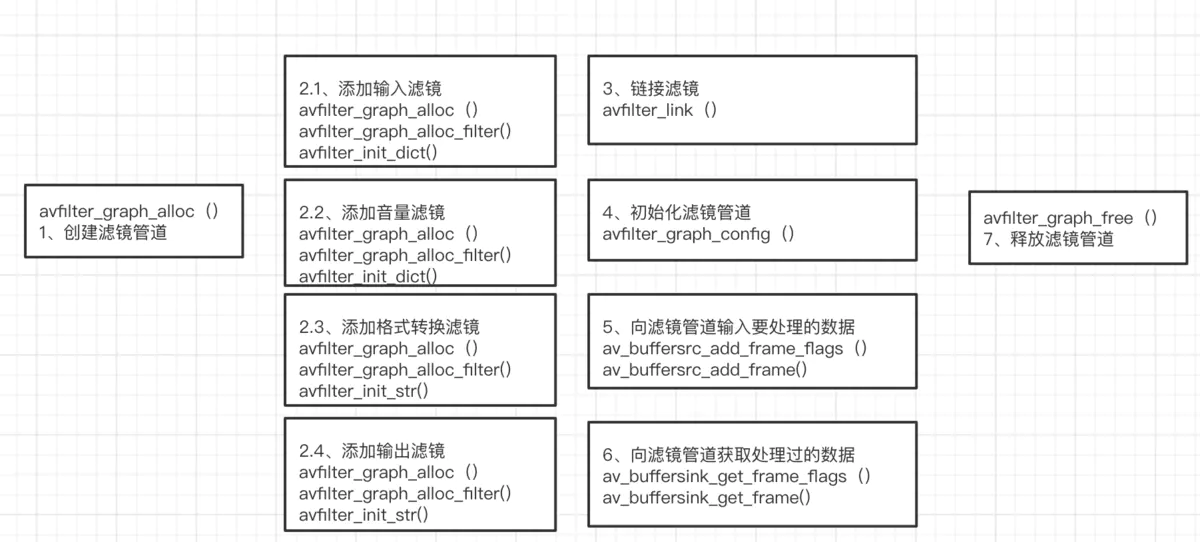
image.png
- 总结:滤镜初始化流程为 1、创建滤镜管道 2、创建各个滤镜(其中输入滤镜,输出滤镜是必须的滤镜),每个滤镜的创建为固定的流程(创建滤镜,创建滤镜上下文,设置滤镜参数并初始化上下文) 3、连接各个滤镜(其中输入滤镜一定要放在第一个,输出滤镜一定要放到最后一个) 4、初始化滤镜管道 5、av_buffersrc_add_frame()函数添加要进行滤镜处理的数据 6、av_buffersink_get_frame()函数获取处理好了的音频数据
方式二:

image.png
- 总结起来使用步骤为: 1、创建滤镜管道 2、创建各个滤镜(其中输入滤镜,输出滤镜是必须的滤镜),每个滤镜的创建为固定的流程(创建滤镜,创建滤镜上下文,设置滤镜参数并初始化上下文) 3、连接各个滤镜(其中输入滤镜一定要放在第一个,输出滤镜一定要放到最后一个) 4、初始化滤镜管道 5、av_buffersrc_add_frame()函数添加要进行滤镜处理的数据 6、av_buffersink_get_frame()函数获取处理好了的音频数据 其中2、3步骤每一个滤镜的处理步骤都一样,只是参数不同而已。ffmpeg针对性的提出了另外一种初始化每个滤镜的简化的处理方式。它通过给定格式的滤镜字符串来解析出 并初始化每个滤镜,同时自动添加到滤镜管道中。滤镜字符串的格式如下: filter_name1=par_name1=par_val1,filter_name2=par_name1=par_val1 如果滤镜只需要一个参数,可以简化为filter_name=par_val;如果滤镜有多个参数,则多个参数用":"分隔filter_name=par_name1=par_val1:par_name2=par_val2: 多个滤镜之间则用","分隔 如: aresample=44100,aformat=sample_fmts=s32:channel_layouts=mono
公共代码文件
#ifndef AudioVolume_hpp
#define AudioVolume_hpp
#include
#include
#include
using namespace std;
extern "C" {
#include "Common.h"
#include
#include
#include
#include
#include
#include
#include
#include
#include
}
class AudioVolume
{
public:
AudioVolume();
~AudioVolume();
/** 方式一:实现调整声音的大小以及改变音频数据的格式功能
* 1、可以调整声音的大小
* 2、可以改变音频的采样率,采样格式,声道类型等等格式
* 使用音频滤镜实现,改变后达到想要的效果
* 备注:以MP3音频为例;
*/
void doChangeAudioVolume();
/** 方式二:实现调整声音的大小以及改变音频数据的格式功能
* 1、可以调整声音的大小
* 2、可以改变音频的采样率,采样格式,声道类型等等格式
* 使用音频滤镜实现,改变后达到想要的效果
* 备注:以MP3音频为例;与方式一不同的地方在于滤镜管道的初始化方式更加简单
*/
void doChangeAudioVolume2();
private:
// 用于解析本地音频源文件
AVFormatContext *in_fmt;
// 用于写入改变后的音频数据到目标文件
AVFormatContext *ou_fmt;
// 用于解码的
AVCodecContext *de_ctx;
// 用于编码的
AVCodecContext *en_ctx;
AVFrame *de_frame;
AVFrame *en_frame;
// 处理音频转换的滤镜管道
AVFilterGraph *graph;
// 输入滤镜上下文(滤镜实例)
AVFilterContext *src_flt_ctx;
// 输出滤镜上下文(滤镜实例)
AVFilterContext *sink_flt_ctx;
// 输入滤镜
AVFilter *src_flt;
// 输出滤镜
AVFilter *sink_flt;
int next_audio_pts;
void doDecode(AVPacket *packt);
void doEncode(AVFrame *frame);
void releasesources();
};
#endif /* AudioVolume_hpp */
方式一实现代码:
void AudioVolume::doChangeAudioVolume()
{
string curFile(__FILE__);
unsigned long pos = curFile.find("2-video_audio_advanced");
if (pos == string::npos) {
LOGD("not find file");
return;
}
string srcDic = curFile.substr(0,pos) + "filesources/";
string srcpath = srcDic + "test-mp3-1.mp3";
string dstpath = srcDic + "1-addaudiovolome-1.mp3";
enum AVSampleFormat dst_smp_fmt = AV_SAMPLE_FMT_S32;
uint64_t dst_ch_layout = AV_CH_LAYOUT_MONO;
int dst_sample_rate = 48000;
#define dst_volume 0.05 // 音量大小 范围0.0-1.0
if (avformat_open_input(&in_fmt, srcpath.c_str(), NULL, NULL) < 0) {
LOGD("avformat_open_input fail");
return;
}
if (avformat_find_stream_info(in_fmt, NULL) < 0) {
LOGD("avformat_find_stream_info ()");
return;
}
av_dump_format(in_fmt, 0, srcpath.c_str(), 0);
AVStream *stream = in_fmt->streams[0];
AVCodec *decodec = avcodec_find_decoder(stream->codecpar->codec_id);
if (!decodec) {
LOGD("not find codec");
releasesources();
return;
}
if ((de_ctx = avcodec_alloc_context3(decodec)) == NULL) {
LOGD("avcodec_alloc_context3 fail");
releasesources();
return;
}
// 设置解码参数;直接从源文件音频流解码参数中拷贝
if (avcodec_parameters_to_context(de_ctx, stream->codecpar) < 0) {
LOGD("pamameters fail");
releasesources();
return;
}
/** 遇到问题:解码mp3时提示"[mp3float @ 0x10180be00] Could not update timestamps for skipped samples."
* 分析原因:来自ffmpeg.c文件的注释:
* Useful for subtitles retiming by lavf (FIXME), skipping samples in * audio, and video decoders such as cuvid or mediacodec
* ist->dec_ctx->pkt_timebase = ist->st->time_base;
* 解决方案:给解码器de_ctx设置pkt_timebase
*/
de_ctx->pkt_timebase = stream->time_base;
// 初始化解码器上下文
if (avcodec_open2(de_ctx, decodec, NULL) < 0) {
LOGD("avcodec_open2() fail");
releasesources();
return;
}
// 编码器
AVCodec *en_codec = avcodec_find_encoder(stream->codecpar->codec_id);
if (!en_codec) {
LOGD("en_codec not found");
releasesources();
return;
}
en_ctx = avcodec_alloc_context3(en_codec);
if (!en_ctx) {
LOGD("en_ctx avcodec_alloc_context3 fail");
releasesources();
return;
}
// 设置编码参数
en_ctx->sample_fmt = select_sample_format(en_codec, dst_smp_fmt);
en_ctx->sample_rate = select_sample_rate(en_codec, dst_sample_rate);
en_ctx->channel_layout = select_channel_layout(en_codec, dst_ch_layout);
en_ctx->time_base = stream->time_base;
en_ctx->bit_rate = stream->codecpar->bit_rate;
if (avformat_alloc_output_context2(&ou_fmt, NULL, NULL, dstpath.c_str()) < 0) {
LOGD("avformat_alloc_output_context2 fail");
releasesources();
return;
}
AVStream *ou_stream = avformat_new_stream(ou_fmt, NULL);
if (ou_fmt->oformat->flags & AVFMT_GLOBALHEADER) {
en_ctx->flags = AV_CODEC_FLAG_GLOBAL_HEADER;
}
if (avcodec_open2(en_ctx, NULL, NULL) < 0) {
LOGD("avcodec_open2() fail");
releasesources();
return;
}
// 设置流参数;这里直接从编码器拷贝
if (avcodec_parameters_from_context(ou_stream->codecpar, en_ctx) < 0) {
LOGD("avcodec_pamameters_from_context fail");
releasesources();
return;
}
if (!(ou_fmt->oformat->flags & AVFMT_NOFILE)) {
if (avio_open2(&ou_fmt->pb, dstpath.c_str(), AVIO_FLAG_WRITE, NULL, NULL) < 0) {
LOGD("avio_open2 fail");
releasesources();
return;
}
}
// 写入文件头
if (avformat_write_header(ou_fmt, NULL) < 0) {
LOGD("avformat_write_header fail");
releasesources();
return;
}
// 1、创建滤镜管道
graph = avfilter_graph_alloc();
// 2、添加输入滤镜;此滤镜是滤镜管道必须的滤镜,它作为滤镜管道的源头,用于接收从外部输入的数据
const AVFilter *src_flt = avfilter_get_by_name("abuffer");
if (!src_flt) {
LOGD("abuffer is not find");
releasesources();
return;
}
// 2.1 创建输入滤镜的上下文(输入滤镜实例)并添加到滤镜管道中;最后一个参数名随意起
src_flt_ctx = avfilter_graph_alloc_filter(graph, src_flt, "src_buffer");
if (!src_flt_ctx) {
LOGD("avfilter_graph_alloc_filter() fail");
releasesources();
return;
}
/** 2.2 设置输入滤镜的相关参数(采样率,采样格式,时间基,声道类型,声道数)并初始化,这里的参数要跟实际输入的音频数据参数保持一致;这是第一种初始化滤镜参数的方式
* av_opt_setxxx()系列函数最后一个参数的含义:
* 0:只在对象的AVClass的option属性里面查找是否有对应的参数赋值,如果没有那么设置将无效;
* AV_OPT_SEARCH_CHILDREN:先在对象的AVClass的child_next指向的AVClass的option属性查找是否有对应的参数,然后在对象的AVClass的option属性查找对应参数
* AV_OPT_SEARCH_FAKE_OBJ:先在对象的AVClass的child_class_next指向的AVClass的option属性查找是否有对应的参数,然后在对象的AVClass的option属性查找对应参数
* 遇到问题:avfilter_init_str()函数返回失败
* 分析原因:调用av_opt_set_xx()系列函数给src_flt_ctx设置参数时无效,因为之前最后一个参数传的为0,AVFilterContext的option属性是不含有这些参数的(它的option属性
* 的child_next指向的AVClass的option属性才有这些参数),所以最后一个参数应该为AV_OPT_SEARCH_CHILDREN
* 解决方案:将最后一个参数设置为AV_OPT_SEARCH_CHILDREN
*/
// 在libavfilter/buffersrc.c文件中可以找到定义
char ch_layout[64];
av_get_channel_layout_string(ch_layout, sizeof(ch_layout), stream->codecpar->channels, stream->codecpar->channel_layout);
av_opt_set(src_flt_ctx, "channel_layout", ch_layout, AV_OPT_SEARCH_CHILDREN);
av_opt_set_sample_fmt(src_flt_ctx, "sample_fmt", (enum AVSampleFormat)stream->codecpar->format, AV_OPT_SEARCH_CHILDREN);
av_opt_set_q(src_flt_ctx, "time_base", stream->time_base, AV_OPT_SEARCH_CHILDREN);
av_opt_set_int(src_flt_ctx, "sample_rate", stream->codecpar->sample_rate, AV_OPT_SEARCH_CHILDREN);
av_opt_set_int(src_flt_ctx, "channels", stream->codecpar->channels, AV_OPT_SEARCH_CHILDREN);
// 因为前面已经通过av_opt_set()函数给src_flt_ctx设置了对应参数的值,所以这里初始化的时候不需要再传递任何参数了
if (avfilter_init_dict(src_flt_ctx, NULL) < 0) { // 这里换成avfilter_init_str()函数也是可以的
LOGD("init abuffer filter parameters fail");
releasesources();
return;
}
// 3、添加声音调整滤镜
const AVFilter *volume_filter = avfilter_get_by_name("volume");
if (!volume_filter) {
LOGD("volume filter get fail");
releasesources();
return;
}
// 3.1 创建声音调整滤镜的上下文并加入到滤镜管道中,最后一个参数名随意起
AVFilterContext *volume_ctx = avfilter_graph_alloc_filter(graph,volume_filter,"volume");
if (!volume_filter) {
LOGD("volume avfilter_graph_alloc_filter() fail");
releasesources();
return;
}
// 3.2 初始化声音调整滤镜的相关参数并初始化;这是第二种初始化滤镜参数的方式
AVDictionary *volume_dic = NULL;
av_dict_set(&volume_dic, "volume", AV_STRINGIFY(dst_volume), 0);
if (avfilter_init_dict(volume_ctx, &volume_dic) < 0) {
LOGD("avfilter_init_dic() fail");
releasesources();
return;
}
av_dict_free(&volume_dic);
// 4、创建格式转化滤镜;
const AVFilter *aformat = avfilter_get_by_name("aformat");
if (!aformat) {
LOGD("avformat filter get fail");
releasesources();
return;
}
// 4.1创建格式转换的上下文
AVFilterContext *aformat_ctx = avfilter_graph_alloc_filter(graph,aformat,"format");
if (!aformat_ctx) {
LOGD("avfilter_graph_alloc_filter() fail");
releasesources();
return;
}
// 4.2 设置格式转换滤镜参数并初始化;具体参数的名字见libavfilter/af_aformat.c文件的aformat_options变量
// 这是第三种设置滤镜参数的方式,采用key1=value1:key2=value2....的字符串形式组织各个参数的值,avfilter_init_str()函数内部会自己解析
char format_opts[128];
sprintf(format_opts, "sample_fmts=%s:sample_rates=%d:channel_layouts=0x%" PRIx64,av_get_sample_fmt_name(en_ctx->sample_fmt),en_ctx->sample_rate,(uint64_t)en_ctx->channel_layout);
printf("val = %s \n",format_opts);
if (avfilter_init_str(aformat_ctx, format_opts) < 0) {
LOGD("avfilter_init_str() fail");
releasesources();
return;
}
// 5、创建输出滤镜
const AVFilter *sink = avfilter_get_by_name("abuffersink");
if (!sink) {
LOGD("sink avfilter_get_by_name fail");
releasesources();
return;
}
// 5.1 创建输出滤镜的上下文
sink_flt_ctx = avfilter_graph_alloc_filter(graph,sink,"sink");
if (!sink_flt_ctx) {
LOGD("sink filter ctx fail");
releasesources();
return;
}
// 5.2 初始化输出滤镜;由于输出滤镜是接受最后一个滤镜的数据,只是做一个中转,所以不需要设置任何参数
if (avfilter_init_str(sink_flt_ctx, NULL) < 0) {
LOGD("sink filter init fail");
releasesources();
return;
}
/** 6、将各个滤镜连接起来(第一个滤镜一定是输入滤镜,最后一个滤镜一定是输出滤镜)
* avfilter_link()中代表将第一个参数对应滤镜输出端口(端口号为srcpad,一般都是0)连接到第三个参数对应滤镜的输入端口(端口号为dstpad,一般都是0)
* 如下代最终滤镜的连接顺序为:
* srcbuffer->volume->aformat->sink
*/
int ret = avfilter_link(src_flt_ctx, 0, volume_ctx, 0);
if (ret >= 0) {
ret = avfilter_link(volume_ctx, 0, aformat_ctx, 0);
}
if (ret >= 0) {
ret = avfilter_link(aformat_ctx, 0, sink_flt_ctx, 0);
}
if (ret < 0) {
LOGD("avfilter_link fail");
releasesources();
return;
}
// 7、配置滤镜管道(也即初始化滤镜管道);只有初始化滤镜管道后才可以使用各个滤镜进行音频处理;第二个参数用来打印日志的上下文,设为NULL即可
if (avfilter_graph_config(graph,NULL) < 0) {
LOGD("avfilter_graph_config fail");
releasesources();
return;
}
/** 遇到问题:重新编码时提示"[libmp3lame @ 0x10380b800] more samples than frame size (avcodec_encode_audio2)"
* 分析原因:因为编码器上下文中设置的frame_size的大小为1152,而通过滤镜管道的av_buffersink_get_frame()函数获取的AVFrame的nb_samples的大小为1254 >=1152
* 解决方案:通过av_buffersink_set_frame_size()给输出滤镜设置输出固定的AVFrame的nb_samples的大小
*
* 分析:av_buffersink_set_frame_size()函数内部实际上是将AVFilterLink的min_samples,max_samples,partial_buf_size都设置为了这个值。那么当调用av_buffersink_get_frame()函数时
* 每次输出的AVFrame大小将为这个值
* 备注:av_buffersink_set_frame_size()的调用必须再avfilter_link()连接之后,否则会崩溃
*/
if (!(en_codec->capabilities & AV_CODEC_CAP_VARIABLE_FRAME_SIZE)) {
av_buffersink_set_frame_size(sink_flt_ctx, en_ctx->frame_size);
}
/** 总结:滤镜初始化流程为
* 1、创建滤镜管道
* 2、创建各个滤镜(其中输入滤镜,输出滤镜是必须的滤镜),每个滤镜的创建为固定的流程(创建滤镜,创建滤镜上下文,设置滤镜参数并初始化上下文)
* 3、连接各个滤镜(其中输入滤镜一定要放在第一个,输出滤镜一定要放到最后一个)
* 4、初始化滤镜管道
* 5、av_buffersrc_add_frame()函数添加要进行滤镜处理的数据
* 6、av_buffersink_get_frame()函数获取处理好了的音频数据
*/
AVPacket *in_pkt = av_packet_alloc();
while (av_read_frame(in_fmt, in_pkt) == 0) {
// 解码
doDecode(in_pkt);
av_packet_unref(in_pkt);
}
// 刷新缓冲区
doDecode(NULL);
// 写入文件尾部
av_write_trailer(ou_fmt);
// 释放资源
releasesources();
}
void AudioVolume::doDecode(AVPacket *packt)
{
if (!de_frame) {
de_frame = av_frame_alloc();
en_frame = av_frame_alloc();
en_frame->sample_rate = en_ctx->sample_rate;
en_frame->channel_layout = en_ctx->channel_layout;
en_frame->format = en_ctx->sample_fmt;
en_frame->nb_samples = en_ctx->frame_size;
if(av_frame_get_buffer(en_frame, 0) < 0) {
LOGD("av_frame_get_buffer fail");
releasesources();
return;
}
if (av_frame_make_writable(en_frame) < 0) {
LOGD("av_frame_make_writable fail");
releasesources();
return;
}
}
avcodec_send_packet(de_ctx, packt);
while (true) {
int ret = avcodec_receive_frame(de_ctx, de_frame);
if (ret == AVERROR_EOF) {
// 清空编码缓冲区
doEncode(NULL);
break;
} else if(ret < 0) {
break;
}
// 解码成功;利用音频滤镜进行转换
ret = av_buffersrc_add_frame_flags(src_flt_ctx,de_frame,AV_BUFFERSRC_FLAG_PUSH);
if (ret < 0) {
LOGD("av_buffersrc_add_frame() fail");
releasesources();
return;
}
while (true) {
ret = av_buffersink_get_frame_flags(sink_flt_ctx, en_frame,AV_BUFFERSINK_FLAG_NO_REQUEST);
if (ret == AVERROR_EOF) { // 说明结束了
break;
} else if (ret < 0) {
break;
}
// 重新编码
AVStream *stream = ou_fmt->streams[0];
en_frame->pts = stream->time_base.den/stream->codecpar->sample_rate*next_audio_pts;
next_audio_pts += en_frame->nb_samples;
doEncode(en_frame);
}
}
}
方式二实现代码:
void AudioVolume::doChangeAudioVolume2()
{
string curFile(__FILE__);
unsigned long pos = curFile.find("2-video_audio_advanced");
if (pos == string::npos) {
LOGD("not find file");
return;
}
string srcDic = curFile.substr(0,pos) + "filesources/";
string srcpath = srcDic + "test-mp3-1.mp3";
string dstpath = srcDic + "1-audiovolume-2.mp3";
int dst_sample_rate = 48000;
enum AVSampleFormat dst_sample_fmt = AV_SAMPLE_FMT_S32;
int64_t dst_ch_layout= AV_CH_LAYOUT_MONO;
if (avformat_open_input(&in_fmt, srcpath.c_str(), NULL, NULL) < 0) {
LOGD("avformat_open_input fail");
return;
}
if (avformat_find_stream_info(in_fmt, NULL) < 0) {
LOGD("avformat_find_stream_info() fail");
releasesources();
return;
}
AVStream *in_stream = in_fmt->streams[0];
AVCodecID codecId = in_stream->codecpar->codec_id;
AVCodec *de_codec = avcodec_find_decoder(codecId);
if (!de_codec) {
LOGD("not find codec %s",avcodec_get_name(codecId));
releasesources();
}
de_ctx = avcodec_alloc_context3(de_codec);
// 设置解码器参数
avcodec_parameters_to_context(de_ctx, in_stream->codecpar);
// 必须设置,否则会提示"Could not update timestamps for skipped samples."并且在调用av_buffersrc_add_frame_flag()函数时会崩溃
de_ctx->pkt_timebase = in_stream->time_base;
// 初始化解码器
if (avcodec_open2(de_ctx, de_codec, NULL) < 0) {
LOGD("de_ctx init fail()");
releasesources();
return;
}
// 创建编码器以及封装器
if (avformat_alloc_output_context2(&ou_fmt, NULL, NULL, dstpath.c_str()) < 0) {
LOGD("avformat_alloc_output_context2() fail");
releasesources();
return;
}
AVStream *stream = avformat_new_stream(ou_fmt, NULL);
AVCodec *en_codec = avcodec_find_encoder(codecId);
if (!en_codec) {
LOGD("encodec not find %s",avcodec_get_name(codecId));
releasesources();
return;
}
en_ctx = avcodec_alloc_context3(en_codec);
if (!en_ctx) {
LOGD("en_codec context fail");
releasesources();
return;
}
// 设置编码参数;这里和源文件一样
en_ctx->sample_rate = select_sample_rate(en_codec, dst_sample_rate);
en_ctx->sample_fmt = select_sample_format(en_codec, dst_sample_fmt);
en_ctx->channel_layout = select_channel_layout(en_codec, dst_ch_layout);
en_ctx->time_base = in_stream->time_base;
en_ctx->bit_rate = in_stream->codecpar->bit_rate;
if (ou_fmt->oformat->flags & AVFMT_GLOBALHEADER) {
en_ctx->flags = AV_CODEC_FLAG_GLOBAL_HEADER;
}
// 初始化编码器
if (avcodec_open2(en_ctx, en_codec, NULL) < 0) {
LOGD("avcodec_open2() fail");
releasesources();
return;
}
// 设置封装器流参数;从编码器拷贝
avcodec_parameters_from_context(stream->codecpar, en_ctx);
if (!(ou_fmt->oformat->flags & AVFMT_NOFILE)) {
if (avio_open2(&ou_fmt->pb, dstpath.c_str(), AVIO_FLAG_WRITE, NULL, NULL) < 0) {
LOGD("avio_open2() fail");
releasesources();
return;
}
}
// 写入文件头
if (avformat_write_header(ou_fmt, NULL) < 0) {
LOGD("avformat_write_header()");
releasesources();
return;
}
// 1、创建滤镜管道
AVFilterGraph *graph = avfilter_graph_alloc();
// 2、创建源滤镜,用于接收要处理的AVFrame
const AVFilter *src_filter = avfilter_get_by_name("abuffer");
char src_args[200] = {0};
sprintf(src_args, "time_base=%d/%d:sample_rate=%d:sample_fmt=%s:channel_layout=0x%" PRIX64,
in_stream->time_base.num,in_stream->time_base.den,in_stream->codecpar->sample_rate,av_get_sample_fmt_name((enum AVSampleFormat)in_stream->codecpar->format),(uint64_t)in_stream->codecpar->channel_layout);
int ret = avfilter_graph_create_filter(&src_flt_ctx, src_filter, NULL, src_args, NULL, graph);
if (ret < 0) {
LOGD("avfilter_graph_create_filter fail");
releasesources();
return;
}
// 3、创建输出滤镜,向外输出滤镜处理过的AVFrame
const AVFilter *sink_filter = avfilter_get_by_name("abuffersink");
if (!sink_filter) {
LOGD("abuffersink not find");
releasesources();
return;
}
ret = avfilter_graph_create_filter(&sink_flt_ctx, sink_filter, NULL, NULL, NULL, graph);
if (ret < 0) {
LOGD("avfilter_graph_create_filter fail");
releasesources();
return;
}
/** 4、创建处理音频数据的各个滤镜(通过滤镜描述符)
* 关于AVFilterInOut:
* 1、它是一个链表,通过它可以用来将所有的滤镜串联起来,方便进行管理。开始于abuffer滤镜,结束于abuffersink滤镜;
* 2、它就是为通过滤镜描述符创建滤镜来服务的,滤镜描述符按照指定的格式描述了一个个滤镜,而一个AVFilterInout代表了一个滤镜和滤镜上下文;
* 4、需要单独释放,通过avfilter_inout_free()
*/
AVFilterInOut *inputs = avfilter_inout_alloc();
AVFilterInOut *outputs = avfilter_inout_alloc();
char filter_desc[200] = {0};
sprintf(filter_desc, "aresample=%d,aformat=sample_fmts=%s:channel_layouts=%s",en_ctx->sample_rate,
av_get_sample_fmt_name(en_ctx->sample_fmt),av_get_channel_name(en_ctx->channel_layout));
// 设置outputs的相关参数;outputs代表向滤镜描述符的第一个滤镜的输入端口输出数据,由于第一个滤镜的input label标签默认为"in",
// 所以这里outputs的name也设置为"in"
outputs->name = av_strdup("in");
outputs->filter_ctx = src_flt_ctx;
outputs->pad_idx = 0;
outputs->next = NULL;
// 设置inputs相关参数;inputs代表接受滤镜描述符的最后一个滤镜的输出端口输出的数据,由于最后一个滤镜的output label标签默认为"out",
// 所以这里inputs的name也设置为"out"
inputs->name = av_strdup("out");
inputs->filter_ctx = sink_flt_ctx;
inputs->pad_idx = 0;
inputs->next = NULL;
// 5、通过滤镜描述符创建并初始化各个滤镜并且按照滤镜描述符的顺序连接到一起
if ((ret = avfilter_graph_parse_ptr(graph, filter_desc, &inputs, &outputs, NULL)) < 0) {
LOGD("avfilter_graph_parse_ptr() fail");
releasesources();
return;
}
// 设置abuffersink输出AVFrame的nbsamples与编码器需要的frame_size大小一致
if (!(en_codec->capabilities & AV_CODEC_CAP_VARIABLE_FRAME_SIZE)) {
av_buffersink_set_frame_size(sink_flt_ctx, en_ctx->frame_size);
}
// 6、配置滤镜管道(初始化滤镜)
if (avfilter_graph_config(graph, NULL) < 0) {
LOGD("avfilter_graph_config() fail");
releasesources();
return;
}
AVPacket *pkt = av_packet_alloc();
while (av_read_frame(in_fmt, pkt) == 0) {
doDecode(pkt);
av_packet_unref(pkt);
}
doDecode(NULL);
LOGD("结束了。。。。");
av_write_trailer(ou_fmt);
// 释放资源
releasesources();
avfilter_inout_free(&inputs);
avfilter_inout_free(&outputs);
}
- 总结: 通过代码可以看到,两种滤镜的使用方式差别在于avfilter_config_graph之前的代码,很显然方式二更加简洁和节省代码
-
问题1 遇到问题:解码mp3时提示"[mp3float @ 0x10180be00] Could not update timestamps for skipped samples." 分析原因:来自ffmpeg.c文件的注释:Useful for subtitles retiming by lavf (FIXME), skipping samples in * audio, and video decoders such as cuvid or mediacodec 解决方案:给解码器de_ctx设置pkt_timebase
-
问题2 遇到问题:avfilter_init_str()函数返回失败 分析原因:调用av_opt_set_xx()系列函数给src_flt_ctx设置参数时无效,因为之前最后一个参数传的为0,AVFilterContext的option属性是不含有这些参数的(它的option属性的child_next指向的AVClass的option属性才有这些参数),所以最后一个参数应该为AV_OPT_SEARCH_CHILDREN 解决方案:将最后一个参数设置为AV_OPT_SEARCH_CHILDREN 备注:在libavfilter/buffersrc.c文件中可以找到定义
-
问题3 遇到问题:重新编码时提示"[libmp3lame @ 0x10380b800] more samples than frame size (avcodec_encode_audio2)" 分析原因:因为编码器上下文中设置的frame_size的大小为1152,而通过滤镜管道的av_buffersink_get_frame()函数获取的AVFrame的nb_samples的大小为1254 >=1152 解决方案:通过av_buffersink_set_frame_size()给输出滤镜设置输出固定的AVFrame的nb_samples的大小 备注: av_buffersink_set_frame_size()函数内部实际上是将AVFilterLink的min_samples,max_samples,partial_buf_size都设置为了这个值。那么当调用av_buffersink_get_frame()函数时每次输出的AVFrame大小将为这个值 备注:av_buffersink_set_frame_size()的调用必须再avfilter_link()连接之后,否则会崩溃
https://github.com/nldzsz/ffmpeg-demo
位于cppsrc目录下文件AudioVolume.hpp/AudioVolume.cpp中
项目下示例可运行于iOS/android/mac平台,工程分别位于demo-ios/demo-android/demo-mac三个目录下,可根据需要选择不同平台

