这篇是我在先后学习了《汇编原理》、《CSAPP》第三章和《x86 data sheet》,以及经历了大量google后写出的总结性文档,用于自查和复习。若能有所助益,不胜荣幸。如有错漏,烦请不吝赐教。
1. 从C到汇编在初学C语言时,我们都会写一个叫做hello.c的文件,通过编译(广义)这个文件(及库文件)并执行,计算机会在屏幕上显示"Hello world!"这一行字符串。但是,我们不禁发问,计算机究竟是怎样理解hello.c中的代码的?
显然,计算机不可能直接理解这么抽象的语句,它只认识高电平和低电平,也就是二进制语言(010010...)。编译器就负责把人类写的源文件“翻译”成计算机认识的二进制文件。“翻译”的牵涉到一系列工具和复杂的过程,主要是预由预处理器把源代码中的宏去掉/替换;由编译器将源代码翻译为汇编程序(这是我们的主角);由汇编器将汇编程序翻译为目标文件,目标文件已经是二进制文件了,但它还不能执行;链接器则将多个目标文件合为一个可执行文件。然后我们执行可执行文件时,计算机会将可执行文件中的二进制代码搬到内存,拆解为一系列的指令,CPU按照一定的顺序执行这些指令,就完成了对可执行文件的执行。如果这部分看不懂,你就需记住一句话,计算机并不直接执行源文件,而是执行编译完成后生成的可执行二进制文件。
让我以x86_64下的hello.c为例。

这是源代码

这是二进制代码(为了显示方便,用16进制代替了)
那汇编语言是什么呢?它是源代码和二进制代码之间的桥梁,它与二进制代码一一对应,同时又具备了可读性。可以说,它就是文本化的二进制代码。在发明高级语言之前,它一直是人类使用的程序语言。让我们看看hello.c对应的汇编语言是什么样子的。

汇编语言(节选)
实际上,它与二进制代码的一一对应关系很容易看出:

左边是二进制,右边是汇编
2. x86_64平台上的汇编语言我们知道高级语言,如C语言,的编写规则与硬件平台无关。同样一份C语言文件,在x86,x86_64, arm上(可以搭载windows,macOS,linux)发挥着相同的功能,这也正是高级语言的优势之一。然而,很不幸,汇编语言是高度定制化的,同样一份源代码在不同的平台上生成的汇编代码是不同的。这是因为汇编代码其实就是一条一条的指令,然而不同的机器上的指令集体系结构是不同的。在x86_64平台上,你需要用到它提供的它自己的复杂指令集;在arm机器上,则要用到它自身的精简指令集。打个不是很恰当的比方,可以把生成可执行的二进制文件想象成为x86_64和arm分别建造房屋,然而x86_64只提供石头,arm只提供砖块。虽然最终房屋的功能都是相同的,但是它们的外貌一定是有差别的。
我在日常学习中主要用到x86_64的平台(恰如大多数人),所以本文解决如何看懂x86_64上的汇编语言的问题。说到这儿,不得不提到x86_64平台的一些关键点。
2.1 16个64位的寄存器(而构成的寄存器文件)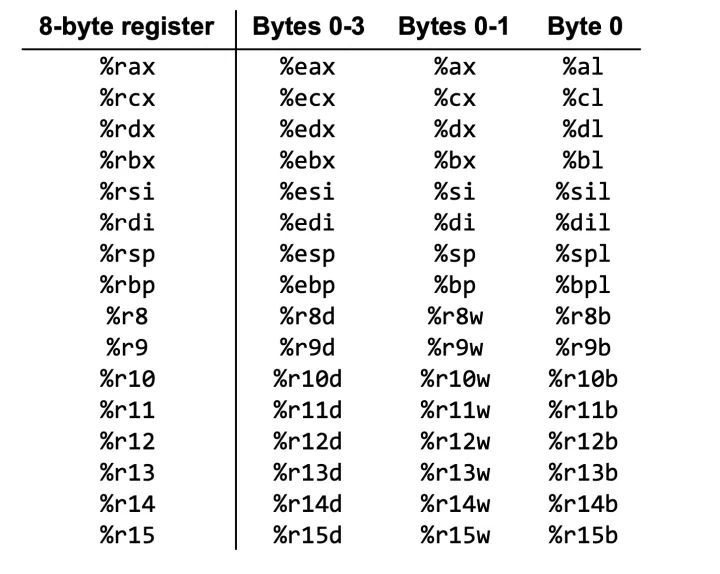
16个寄存器
寄存器用途不一,但主要还是用于存储变量或地址的值。等等,看到这幅图,有没有一个疑惑:明明是16个寄存器,为何却有64个名称?
因为我们遇到的变量不一定都是64位的。以%rax为例,比如我要存储一个char类型的变量,那么我用得到的只有它的低8位,所以专门为这8位取名为%al(l代表low);同理,如果要存储short类型的变量,则要用到它的低16位,专以%ax名之;若变量是int类型的,则要用到低32位,以%eax命名。
这16个寄存器中,有的要承担特殊的任务,如果%rsp用于指向栈顶,%rax(及%eax等)要存储函数返回的值,有6个寄存器要用来保存函数的参数值,而有的则没有限制。
其它寄存器还有caller-saved(调用者保存), callee-saved(被调用者保存)的特性,这些在下文都会有详细的解释,这里只做简单的提示。
下图更加全面地展示了寄存器堆及其特点(源自CSAPP):

先不要管“虚拟”二字,它与主题无关。内存像个仓库,不管是二进制代码本身还是部分临时变量都存储在内存中(还有部分存储在寄存器文件中),它们时刻准备着为CPU所用(访问或写入)。你可以把内存看作一块超级大的数组,所以内存的每一个单元(字节)都有自己的地址。
2.3 栈(stack)学过数据结构的话,就会非常熟悉栈的特性:它遵循着后进先出(LIFO)的原则。而在x86-64的内存中,也有栈空间,它在程序运行时发挥着重要的作用:它储存着临时变量,担任过程调用的中转站即保存返回地址,(可能过多的)参数,为当前过程储存临时变量。
栈最重要的特征是有一个栈顶指针,这就是%rsp(16个寄存器之一)。我们知道,栈能操作的数据只有存储在栈顶的数据,所以几乎所有与栈相关的指令都离不开这根指针。栈有两个操作:压栈(push)和弹出(pop)。实际上,压栈是指,将栈顶指针往下移动若干个字节,使得栈的容量增大,再把新的数据填入栈顶。为什么要往下移动呢?因为栈是向下“生长”的,也就是说,新进来的数据的地址小于旧的数据。如下图。

而弹出是指,将栈顶指针上移若干字节。不必改变原来栈顶的值,因为随着栈顶指针的上移,原来的栈顶已经被排除在栈的范围之外。
在过程调用中,栈被分为多个部分,每一部分专门为一个过程服务,被称为“栈帧”,这个也留待后讲。
2.4 PC寄存器PC(Program counter)寄存器,在汇编语言中以%rip表示,是非常关键的寄存器,它是CPU执行指令时的“指挥棒”。因为指令序列都保存在内存中,所以每一条指令都有相应的(虚拟)地址,如下图:

红框内的就是指令对应的地址
PC寄存器就存储着正在执行的指令的下一条要执行的指令。因此,每执行一条指令,下一条指令的地址就被放在PC寄存器中了。形象地说,PC寄存器像一个“指哪儿打哪儿”的将军。如果你不想呆板地按照空间顺序一条一条的执行指令,那你只需要把你想执行的那一条指令的地址搬到PC寄存器上即可(实际上跳转指令和函数调用就是用这个原理实现的)。
PC寄存器并不会显式地出现在汇编代码中,其值的变化都是暗地里进行的。
2.5 条件码躲在暗处的除了PC寄存器外,还有一种叫做“条件码”的东西。它的作用是记录最近一次进行算术或逻辑指令后的状态。这个也会在后面细讲。
3 指令前文提到,汇编代码是很多条指令的序列,一个指令可以完成一个CPU操作。那我们就先来细细研究一下单条指令的特征和格式。
一条指令由操作码和0~2个操作数构成。操作码指定了当前指令要执行的操作,如将两数相加,操作数则是操作码的作用对象。因此可以看出,指令的长度不固定,短则1个字节,长则15字节。
3.1 操作数操作数可以是立即数、寄存器、内存地址。下面是表示这三种操作数的方法(来自x64 data sheet):

请仔细阅读
举例来说,$5是立即数,它的值5;%rax是寄存器,它的值是寄存器%rax中的值;0xf7是内存地址,它的值是内存中地址为0x07的某种类型的值;(%rax)也是内存的地址,只不过,该地址保留在寄存器%rax中;0xf7(%rax, %rbp, 4)也是内存的地址,所有的内存寻址方式都可以写成这种类型。
3.2 操作码操作码分为算术逻辑类、数据传输类、控制类等等。
- 算术和逻辑指令操作码
请看下面的指令
addq $3, %rdiadd代表相加,第一个操作数是源操作数,第二个是目的操作数。这个指令把立即数3加到寄存器%rdi中。如果之前%rdi中存储的值是8,则执行该指令之后变为11。
那么,add的后缀q代表什么呢?它代表着操作数的大小。有4种后缀:
b-字节(byte,8比特)、
w-字(word,16比特)、
l-双字(doubleword,32比特)
q-四字(quadword, 64比特)
算术逻辑类除了相加,还有减、乘、异或、按位或、按位与等等。如下表:

上面的例子都有两个操作数,其实还有仅一个操作数的算术逻辑运算:

2. 数据传输指令操作码:
movb $bl, %al表示把%bl寄存器中的值赋值给%al
pushq %rbp表示将%rbp的值压入栈中:即先使栈顶指针寄存器%rsp的值减少8,再将%rbp的值赋值给%rsp所指的内存单元。(回忆前面讲的压栈)
popq %rsi表示将栈顶的8个字节的值弹出,并赋给寄存器%rsi。
3. 控制类
4. 比较和测试操作码
cmpb %al, %bl
testq %rax, %rbx接下来,我将由简单到复杂,举出一系列例子来说明如何看懂汇编代码。
首先,如何来获取一段汇编代码呢?有两种方法。
首先准备好一个源文件(我用的是hello.c)

然后使用命令
gcc -Og -S hello.chello.c请替换为自己文件的名字,然后就会得到*.s的文件,这个文件里的就是这个源代码对应的汇编代码:

注意加上-Og使得到的汇编代码与源代码尽可能的对应,否则编译器优化将会使我们很难看出汇编代码与源代码的关系。
然而,这样的到的汇编代码不够简洁和整齐。我们将使用下面的方法得到汇编代码:
首先编译源代码得到目标文件hello.o:
gcc -c -Og hello.c然后用反汇编命令:
objdump -d hello.o汇编代码就显示出来了。

比刚才的代码更整洁。
下面正式开始实战。
例1首先从最简单的代码开始:
void foo(){
return;
}一个什么也没有做的函数,没有参数也没有返回值。让我们看看它的汇编代码是什么:
0000000000000000 :
0: 55 pushq %rbp
1: 48 89 e5 movq %rsp, %rbp
4: 5d popq %rbp
5: c3 retq先看第一行:

这一行分为两部分,第一部分是16个0。注意,这个0可不是简单的0,它是16进制的0,所以这些0其实是64个0。而系统是64位的……所以你能猜到了吧,它是这个函数所在的虚拟地址。第二部分是,_foo是函数名,是这个函数的标记用,当其它函数要调用此函数时就需要用到函数名。汇编的函数名是原来的函数名前加上"_"前缀而生成的。
下面就是函数体。显然,它由4条指令构成。
我们先看第一列:

这个是各指令的地址,也是16进制的。因为第二条指令有3个字节(48 89 e5),所以第3条指令与第2条指令的地址相差3。
而地址冒号后面就是指令的机器码了:

再后面就是汇编代码:

这四行汇编代码,我们一行一行的分析:
- 第一行代码:
pushq %rbp通过前面的讲解,我们已经知道,这一行是将%rbp的值压入栈中。为什么要这样做?因为寄存器有“调用者保存”和“被调用者”保存的规则。待我细细道来。
16个寄存器,除了%rsp要存储栈顶指针外,一般来说剩下的15个都可以用作存储变量。但是当涉及函数调用时,部分寄存器的功能就用限制了:%rax将被用作存储返回值;%rdi, %rsi, % rdx, %rcx, %r8, %r9这六个寄存器将被用来保存参数;剩下8个仍然可以保存任何数值。但问题是,寄存器只有一套, 现在要两个函数(父函数和子函数)来使用,势必产生冲突,那怎么办呢?答案是在子函数使用之前将这些寄存器的值保存在栈中,待子函数使用完成后,再将栈中保存的值还给寄存器。根据谁负责保存这些寄存器,可以把它们分为两类:“调用者保存”和“被调用者保存”。“调用者保存”(caller-saved):即在调用子函数之前,将父函数用过的寄存器压栈;“被调用者保存”:即在子函数内,对即将使用的寄存器压栈。下面总结了哪些是调用者保存寄存器,和被调用者保存寄存器。
调用者保存寄存器被调用者保存寄存器%r10,%r11%rbx, %rbp, %r12-15回到这行代码,显而易见,我们将%rbp压栈是因为第二行代码改变了%rbp的值,而%rbp是被调用者保存寄存器。
2. 第2行代码
movq %rsp, %rbp这行代码是将%rsp的值赋值给%rbp。这行代码在这里显得比较多余(但在后面的例子中将看到它的作用),它的作用是让%rbp成为基指针,后续函数(多于6个)的参数,中间变量等等保存的地址就是以%rbp所指向的地址的偏移。
3. 第3行代码
popq %rbp将栈顶的数据弹出,并赋给%rbp。这与pushq %rbp相对应,旨在恢复%rbp以前的值。
4. 第4行代码
retq被调用者执行完毕,返回调用者。
例2我们在例1的基础上,增加返回值。
int foo(){
return 0;
}生成相应的汇编代码:
0000000000000000 :
0: 55 pushq %rbp
1: 48 89 e5 movq %rsp, %rbp
4: 31 c0 xorl %eax, %eax
6: 5d popq %rbp
7: c3 retq我们看到与例1区别就是多了这一行。

这是将%eax与自身作按位异或,其结果是%eax的值变为0(而且是int类型)。而%eax恰好是保存返回值的。
例3我们在例2的基础上增加两个参数:
int foo(int a, int b){
return a + b;
}生成的汇编代码:
0000000000000000 :
0: 55 pushq %rbp
1: 48 89 e5 movq %rsp, %rbp
4: 8d 04 37 leal (%rdi,%rsi), %eax
7: 5d popq %rbp
8: c3 retq注意这一行:

源代码中,两个参数相加并返回被编译成这一行汇编代码。先看看leal的作用,它将%rdi和%rdi的值相加,赋给%eax。在例1已经进行说明,%rdi和%rsi分别储存第一个和第二个参数,%eax储存返回变量。所以这行代码完美对应源代码。
不过......等等,有没有发现一个问题:寄存器文件中只有6个寄存器用于传递参数,但如果有7或更多个参数怎么办呢?我们为此进行下一个实验。
例4将参数改为8个。
int foo(int a1, int a2, int a3, int a4, int a5, int a6, int a7, int a8){
return a1 + a2 + a3 + a4 + a5 + a6 + a7 + a8;
}这是它的汇编代码:
0000000000000000 :
0: 55 pushq %rbp
1: 48 89 e5 movq %rsp, %rbp
4: 8d 04 37 leal (%rdi,%rsi), %eax
7: 01 d0 addl %edx, %eax
9: 01 c8 addl %ecx, %eax
b: 44 01 c0 addl %r8d, %eax
e: 44 01 c8 addl %r9d, %eax
11: 03 45 10 addl 16(%rbp), %eax
14: 03 45 18 addl 24(%rbp), %eax
17: 5d popq %rbp
18: c3 retq请见下面红框内的代码:

6个参数传递的寄存器%rdi, %rsi, %edx, %ecx, %r8d, %r9d依次出现,再次验证了前6个参数确实保存在这些寄存器内。而红框内最后两行则是将%rbp上面第16字节和24字节的doubleword型数据加到%eax上,说明第7、8个参数存储在这两个地方。看来若多余6个参数的话,多余的参数会保存在栈中来进行传递。
但是,为什么是%rbp偏移16、24个字节呢?为了看清楚为什么第7、8个参数会被保存在这个位置,我们继续进行下面的实验。
例5增加调用者函数caller,且为了对应(对不起我有强迫症),函数名foo改名为callee。
int callee(int a1, int a2, int a3, int a4, int a5, int a6, int a7, int a8){
return a1 + a2 + a3 + a4 + a5 + a6 + a7 + a8;
}
int caller(){
return callee(1, 2, 3, 4, 5, 6, 7, 8) + 9;
}其汇编代码是:
0000000000000000 :
0: 55 pushq %rbp
1: 48 89 e5 movq %rsp, %rbp
4: 8d 04 37 leal (%rdi,%rsi), %eax
7: 01 d0 addl %edx, %eax
9: 01 c8 addl %ecx, %eax
b: 44 01 c0 addl %r8d, %eax
e: 44 01 c8 addl %r9d, %eax
11: 03 45 10 addl 16(%rbp), %eax
14: 03 45 18 addl 24(%rbp), %eax
17: 5d popq %rbp
18: c3 retq
19: 0f 1f 80 00 00 00 00 nopl (%rax)
0000000000000020 :
20: 55 pushq %rbp
21: 48 89 e5 movq %rsp, %rbp
24: bf 01 00 00 00 movl $1, %edi
29: be 02 00 00 00 movl $2, %esi
2e: ba 03 00 00 00 movl $3, %edx
33: b9 04 00 00 00 movl $4, %ecx
38: 41 b8 05 00 00 00 movl $5, %r8d
3e: 41 b9 06 00 00 00 movl $6, %r9d
44: 6a 08 pushq $8
46: 6a 07 pushq $7
48: e8 00 00 00 00 callq 0x4d
4d: 48 83 c4 10 addq $16, %rsp
51: 83 c0 09 addl $9, %eax
54: 5d popq %rbp
55: c3 retq我们发现代码将立即数$1~6分别按顺序装入对应寄存器,这没问题。之后,先后将立即数$8和$7压栈,%rsp在这个过程中隐式地减少了8+8=16个字节(因为装下一个quadword需要8个字节)。从这儿我们可以看到多出的参数是从后往前依次压栈的。所以例4中16(%rbp)中保存着$7,24(%rbp)保存着$8。
接下来,来看调用命令:

我们都知道这条指令是调用callee函数,然而,callq 后的操作数0x4d 并不是callee的地址,因为我展示的程序是未链接的,callq并不知道callee的地址。链接之后的汇编代码是这样的:
0000000100003f60 :
100003f60: 55 pushq %rbp
100003f61: 48 89 e5 movq %rsp, %rbp
100003f64: 8d 04 37 leal (%rdi,%rsi), %eax
100003f67: 01 d0 addl %edx, %eax
100003f69: 01 c8 addl %ecx, %eax
100003f6b: 44 01 c0 addl %r8d, %eax
100003f6e: 44 01 c8 addl %r9d, %eax
100003f71: 03 45 10 addl 16(%rbp), %eax
100003f74: 03 45 18 addl 24(%rbp), %eax
100003f77: 5d popq %rbp
100003f78: c3 retq
100003f79: 0f 1f 80 00 00 00 00 nopl (%rax)
0000000100003f80 :
100003f80: 55 pushq %rbp
100003f81: 48 89 e5 movq %rsp, %rbp
100003f84: bf 01 00 00 00 movl $1, %edi
100003f89: be 02 00 00 00 movl $2, %esi
100003f8e: ba 03 00 00 00 movl $3, %edx
100003f93: b9 04 00 00 00 movl $4, %ecx
100003f98: 41 b8 05 00 00 00 movl $5, %r8d
100003f9e: 41 b9 06 00 00 00 movl $6, %r9d
100003fa4: 6a 08 pushq $8
100003fa6: 6a 07 pushq $7
100003fa8: e8 b3 ff ff ff callq 0x100003f60
100003fad: 48 83 c4 10 addq $16, %rsp
100003fb1: 83 c0 09 addl $9, %eax
100003fb4: 5d popq %rbp
100003fb5: c3 retq注意看,callq的操作数0x100003f60 正是callee的地址。
不管怎样,我们已经确定了这行指令是调用函数callee,而这个过程隐式地发生了如下事件:
- 将“返回地址”压栈。所谓返回地址就是调用指令的下一条指令的地址,如这里(链接后的程序)的返回地址是100003fad。将返回地址压栈的目的是使子函数执行完毕后能继续执行下一条执行。再次提醒,压栈意味着%rsp将减少8个字节。
- 将PC寄存器设置为被调用函数的地址,这里是0x100003f60。前面已经说过,PC寄存器是指挥棒,它指向哪条指令,CPU下一步就执行哪一条。所以执行callq指令后,下一步就将开始执行callee的指令。
还记得我们的问题吗:为何参数7与%rbp的地址相差16个字节?参数8与%rbp的地址相差24字节。这是因为参数7的地址与%rbp隔着"返回地址"和“%rbp的旧值”两个值,共16个字节,而参数8除了隔着这16字节,还隔着参数所占的8字节。
铺垫了这么多,是时候展示这张图了(来自CSAPP)!

栈帧的结构
现在来好好解读这张图。途中function P是一个调用者函数,function Q则是一个被调用者。
我们在前文说过,在程序执行过程中,栈被分为多个“栈帧”,如上图所展示的。不同的过程都有自己所属的栈帧,正在执行的过程的栈帧处于栈的最“顶”部。
栈帧是过程调用中传递参数,储存返回信息、寄存器和局部变量的区域。相信通过前面的例子,我们已经见识到了栈帧的厉害。我们这里将过程调用的整个流程梳理一遍,其中涉及栈帧的我将用粗体标记:
- 在调用者中,将所需参数保存在6个寄存器中;如果参数多于6个,则将多余的参数从后往前依次压栈,注意参数的大小要扩充为8的倍数。
- 将返回地址压栈
- 将被调用者的地址传递给PC寄存器%rip
- 将被调用者保存寄存器压栈
- 为局部变量分配内存空间
- 执行被调用者的指令
- 将返回值保存在%rax中
- 增加%rsp的值以销毁当前栈帧
- 执行retq指令。这条指令将返回地址赋给PC寄存器
PS:若返回值不能用寄存器保存,也将储存在栈帧中。
图中展示的栈帧的结构是普遍意义上的,但是在很多情况下,有些单元并不是必须的。如在例1~例3中,函数的参数不超过6个,也就没有分配内存来存储第7到n个参数。

再如,Local variables区域是用来存储临时变量的,但有些函数并不需要临时变量。

看到这儿了先休息一下吧。我们马上开始下一个例子,这次将由从简单例子开始。


