- 邻接矩阵存储图的广度优先遍历过程分析
- C语言实现队列编程
- 程序中加入图的处理函数
- 结果的再次分析
- C#语言实现图的广度优先遍历、并显示广度优先遍历生成树
- JavaScript语言实现图的广度优先遍历、并显示广度优先遍历生成树
对图1这样的无向图,要写成邻接矩阵,则就是下面的式子 
 一般要计算这样的问题,画成表格来处理是相当方便的事情,实际中计算机处理问题,也根本不知道所谓矩阵是什么,所以画成表格很容易帮助我们完成后面的编程任务。在我们前面介绍的内容中,有不少是借助着表格完成计算任务的,如Huffman树。
一般要计算这样的问题,画成表格来处理是相当方便的事情,实际中计算机处理问题,也根本不知道所谓矩阵是什么,所以画成表格很容易帮助我们完成后面的编程任务。在我们前面介绍的内容中,有不少是借助着表格完成计算任务的,如Huffman树。
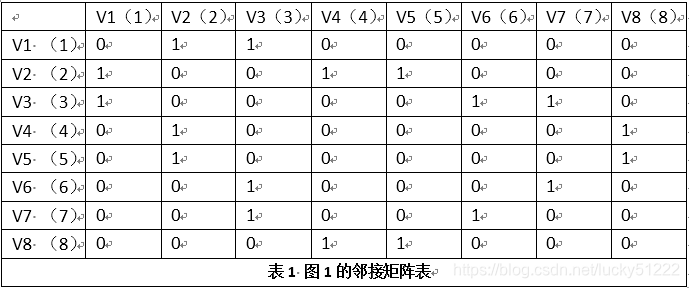 为了记录那些顶点是已经走过的,还要设计一个表来标记已经走过的顶点,在开始,我们假设未走过的是0,走过的是1,于是有:
为了记录那些顶点是已经走过的,还要设计一个表来标记已经走过的顶点,在开始,我们假设未走过的是0,走过的是1,于是有:
 对广度优先遍历,还需要补充一个队列、来记录一个顶点可以抵达到的其他顶点。
对广度优先遍历,还需要补充一个队列、来记录一个顶点可以抵达到的其他顶点。
广度优先遍历过程如下:
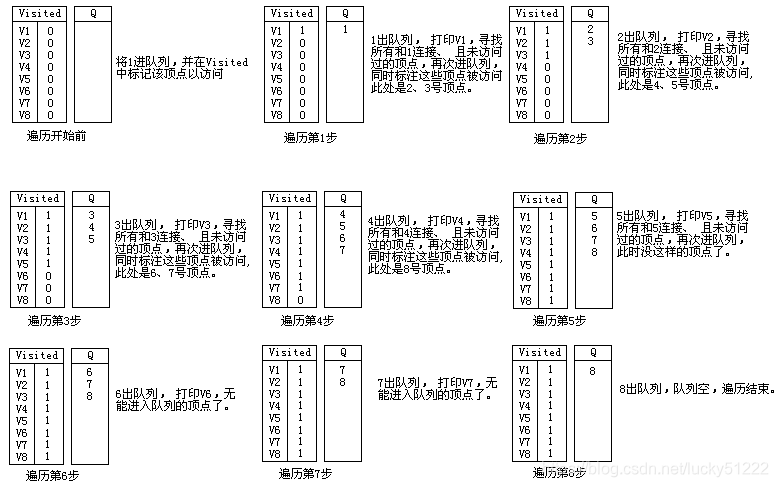 结果分析
结果分析
从上面的过程可以看出:仅仅就顶点访问到的次序而言,图1的广度优先遍历结果是:
V1->V2->V3>V4->V5->V6->7->V8
但实际执行过程中我们可以发现:所谓图的广度优先遍历、其结果应该是一个树:
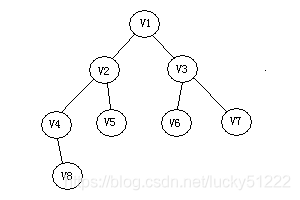 在C语言中,显示这个结果并不容易,所以大多C语言的教材中并不会给出这样的结果。
在C语言中,显示这个结果并不容易,所以大多C语言的教材中并不会给出这样的结果。
根据上面的分析,我们可以知道:要广度优先遍历图,首先要一个队列系统。
队列在C语言上只能自己构造,好在我们前面有链表、有顺序表,我们可以复制过来一个链表程序构造一个队列,于是从链表程序中复制过来b5.c或者b6.c即可,我们分析队列的ADT可知,最需要的队列功能需求是:
QueueInit()、EnQueue、DeQueue()、QueueEmpty()这4个函数,于是有以下队列定义:
struct Queue
{
struct LinkedList * LinkQueue;
int Count;
};
由于我们已经确定使用链表做队列,所以队列实际就是链表的换名包装,所以我们可以理解为队列就是链表的另一种应用,表3的程序就是这样的做法,所以对队列的初始化,就是:
struct Queue * QueueInit()
{
struct Queue *q;
q=(struct Queue *)malloc(sizeof(struct Queue));
q->LinkQueue=LinkedListInit();
q->Count=0;
return q;
}
有了队列的初始化,则进入队列、实际相当于给这个链表追加一条记录,就是Append()的另类包装:
int EnQueue(struct Queue *Q,struct ElemType *E)
{
if(Q==NULL) return -1;
if(E==NULL) return -2;
Append(Q->LinkQueue,E);
Q->Count++;
return 0;
}
注意数据出队列,出队列总是把链表中第一个结点的数据给出来、并删除第一个结点,所以出队列就是:
int DeQueue(struct Queue *Q,struct ElemType *E)
{
struct ElemType *pE;
if(Q==NULL) return -1;
if(E==NULL) return -2;
pE=LinkedListGet(Q->LinkQueue,1);
ElemCopy(pE,E);
LinkedListDel(Q->LinkQueue,1);
Q->Count--;
return 0;
}
出队列函数总是把第一个结点删除掉,注意队列完全可能数据出完后再次有数据进入队列,则原来的结点删除函数有Bug,这在程序开发中很正常,修改后就是:
int LinkedListDel(struct LinkedList *L,int n)
{
int i;
struct Node *p0,*p1;
if(L==NULL) return -1;
if(nL->Count) return -2;
p0=L->Head;
for(i=0;inext;
p1=p0->next;
p0->next=p1->next;
free(p1);
L->Count--;
if(L->Count==0) L->Tail=L->Head;
return 0;
}
修改的这个链表结点函数、仅仅加了第14行,在过去,所以结点删除后,最后的尾巴结点指针Tail所指的存储空间被释放,导致这个指针变量不可用,现在在结点个数为0的情况下,再次让尾结点指向头结点,保证下次进入链表的数据依然正确。
而判断队列是否为空则相对简单的多,就是:
int QueueEmpty(struct Queue *Q)
{
if(Q==NULL) return -1;
return !(Q->Count);
}
补充main()函数,测试多批次进入队列、出队列,全部程序见B0.c
在我们的图遍历应用中,我们对队列的数据仅仅要求一个整数即可,而这个程序进出队列的数据有三列数据,为加强该程序可靠行,修改ElemType(),就是:
void ElemCopy(struct ElemType *s,struct ElemType *d)
{
d->sNo=s->sNo;
//strcpy(d->sName,s->sName);
//d->sAge=s->sAge;
}
在一个系统中,类似这样的修改很正常,使用已有的程序完成自己的工作,会大大加快编程的进度,使得编程工作更加流畅。 而这一切都需要自己有足够的积累,有这个积累后完成这样的工作才有基础,所谓技术水平,就是不断积累的过程。
下面,在图的处理中会再次体现这样的过程。
程序中加入图的处理函数我们的队列系统完成后,记着再复制一个文件,加入图的邻接矩阵读数据程序,我们这里这个程序名称是b1.c。对邻接矩阵数据的读取、并构造图的过程,在深度优先遍历程序中已完成,所以直接复制过来即可,回顾广度优先遍历算法,就是把第一个顶点先无条件装进队列,所以编写遍历BFSM函数如下:
四、程序中加入图的处理函数
我们的队列系统完成后,记着再复制一个文件,加入图的邻接矩阵读数据程序,我们这里这个程序名称是b1.c。对邻接矩阵数据的读取、并构造图的过程,在深度优先遍历程序中已完成,所以直接复制过来即可,回顾广度优先遍历算法,就是把第一个顶点先无条件装进队列,所以编写遍历BFSM函数如下:
void BFSM(struct Graph *G)
{
int i,n;
struct Queue *Q;
struct ElemType *p,E,e;
Q=QueueInit();
E.sNo=0; // 设置0进队列
EnQueue(Q,&E);
G->Visited[0]=1; // 设置0号顶点已被访问
p=&e;
while(!QueueEmpty(Q))
{
//待补充
}
}
从第11行开始,则进入真正的遍历。
有这么个函数后,我们可以补充main()的测试函数就是:
main()
{
struct Graph *G;
G=GraphCreat("p176G719.txt");
BFSM(G);
}
main()很短,也很简单,如有不明白的回顾下深度优先遍历函数。
回顾一下:就是队列Q里出队列,然后找与该顶点相连的所有顶点、在进队列,就是:
void BFSM(struct Graph *G)
{
int i,n;
struct Queue *Q;
struct ElemType *p,E,e;
Q=QueueInit();
E.sNo=0;
EnQueue(Q,&E);
G->Visited[0]=1;
p=&e;
while(!QueueEmpty(Q))
{
DeQueue(Q,p);
n=p->sNo;
printf("%s\n",G->pV[n]);
for(i=0;inum;i++)
if(G->pA[n][i]==1&&G->Visited[i]==0)
{
G->Visited[i]=1;
E.sNo=i;
EnQueue(Q,&E);
}
}
}
运行这个程序、就会打印出这个图的广度优先遍历结果。
结果的再次分析有了这个函数后,构造main()开始从第0个顶点遍历图1,就是:
进一步测试该函数,按图1的数据仔细分析下它的执行过程,如有图的连接分量不为1,则会在第一个连接分量遍历完成后终止。如下图4,在B1.C中是无法全部遍历完成的。这个图的文件在G4.TXT,修改表23中第5行,从G4.TXT中读数据,则会发现这个程序仅仅遍历了A、B、C、D,而没有到达过E、F、G这三个顶点。
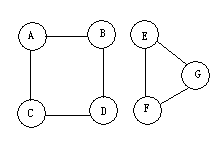 这个图该如何遍历呢?请同学们自己修改程序,完成这个图的遍历。 广度优先遍历到此结束。
这个图该如何遍历呢?请同学们自己修改程序,完成这个图的遍历。 广度优先遍历到此结束。
在C#文件夹中可以找到“Graph0.cs”,这个文件中包含着深度优先遍历、广度优先遍历等程序中的所有图类程序,现在,我们就要在这个类中补充新的方法。 首先复制这个类到Graph.cs,然后用C#建立一个Windows应用程序,然后在资源管理器中添加这个类,这个类和在深度优先遍历中的类完全一致,但去掉了命名空间说明,这样,这个类就可以使用在其他工程中了。
首先是再次熟悉这个类中的变量定义:
private int[,] A //邻接矩阵
private string[] V //顶点矩阵
private int[] Visited //顶点访问表
private TreeNode[] T //遍历生成树
private int num //顶点个数
private int ConnComp //连通分量
找到这个类中的最后一个方法:DSFTraverse(),然后开始在这个方法后补充新方法:DFS(),由于算法和C语言完全一致,此处算法问题不在介绍。
private void BFS(int N)
{
int n;
Queue Q = new Queue();
Q.Enqueue(N);
Visited[N] = 1;
while (Q.Count != 0)
{
n = Q.Dequeue();
for (int i = 0; i 0)
{
n = Q.DeQueue();
for (i = 0; i
关注
打赏

- 【ArcGIS风暴】ArcGIS标注和注记的区别及用法案例详解
- 【GIS风暴】什么是EPSG?常见坐标系对应的EPSG代号、经度范围、中央经线是多少?
- 【GlobalMapper精品教程】008:如何根据指定区域(shp、kml、cad)下载卫星影像?
- 【MapGIS精品教程】005:MapGIS中间件的配置与使用
- Win7+Win10双系统安装全攻略
- 【ArcGIS Pro微课1000例】0021:Win10系统ArcGIS Pro3.0.1安装教程(附ArcGIS Pro下载)
- 【测绘程序设计】Excel度(°)转换度分秒(° ‘ “)模板附代码超实用版
- 【GlobalMapper精品教程】006:Excel等表格(.xls)或文本(.txt .csv)坐标文件生成矢量点
- 【GlobalMapper精品教程】005:影像拼接与裁切(分幅)作业案例教程
- 【GlobalMapper精品教程】002:GlobalMapper中文版安装后的基本设置

