
Field属性
Field是文档中的域,包括Field名和Field值两部分,一个文档可以包括多个Field,Document只是Field 的一个承载体,Field值即为要索引的内容,也是要搜索的内容。
- 是否分词(tokenized) 是:作分词处理,即将Field值进行分词,分词的目的是为了索引。 比如:商品名称、商品描述等,这些内容用户要输入关键字搜索,由于搜索的内容格式大、内容多需要 分词后将语汇单元建立索引 否:不作分词处理 比如:商品id、订单号、身份证号等
- 是否索引(indexed) 是:进行索引。将Field分词后的词或整个Field值进行索引,存储到索引域,索引的目的是为了搜索。 比如:商品名称、商品描述分析后进行索引,订单号、身份证号不用分词但也要索引,这些将来都要作 为查询条件。 否:不索引。 比如:图片路径、文件路径等,不用作为查询条件的不用索引。
- 是否存储(stored) 是:将Field值存储在文档域中,存储在文档域中的Field才可以从Document中获取。 比如:商品名称、订单号,凡是将来要从Document中获取的Field都要存储。 否:不存储Field值 比如:商品描述,内容较大不用存储。如果要向用户展示商品描述可以从系统的关系数据库中获取。
下边列出了开发中常用 的Filed类型,注意Field的属性,根据需求选择: 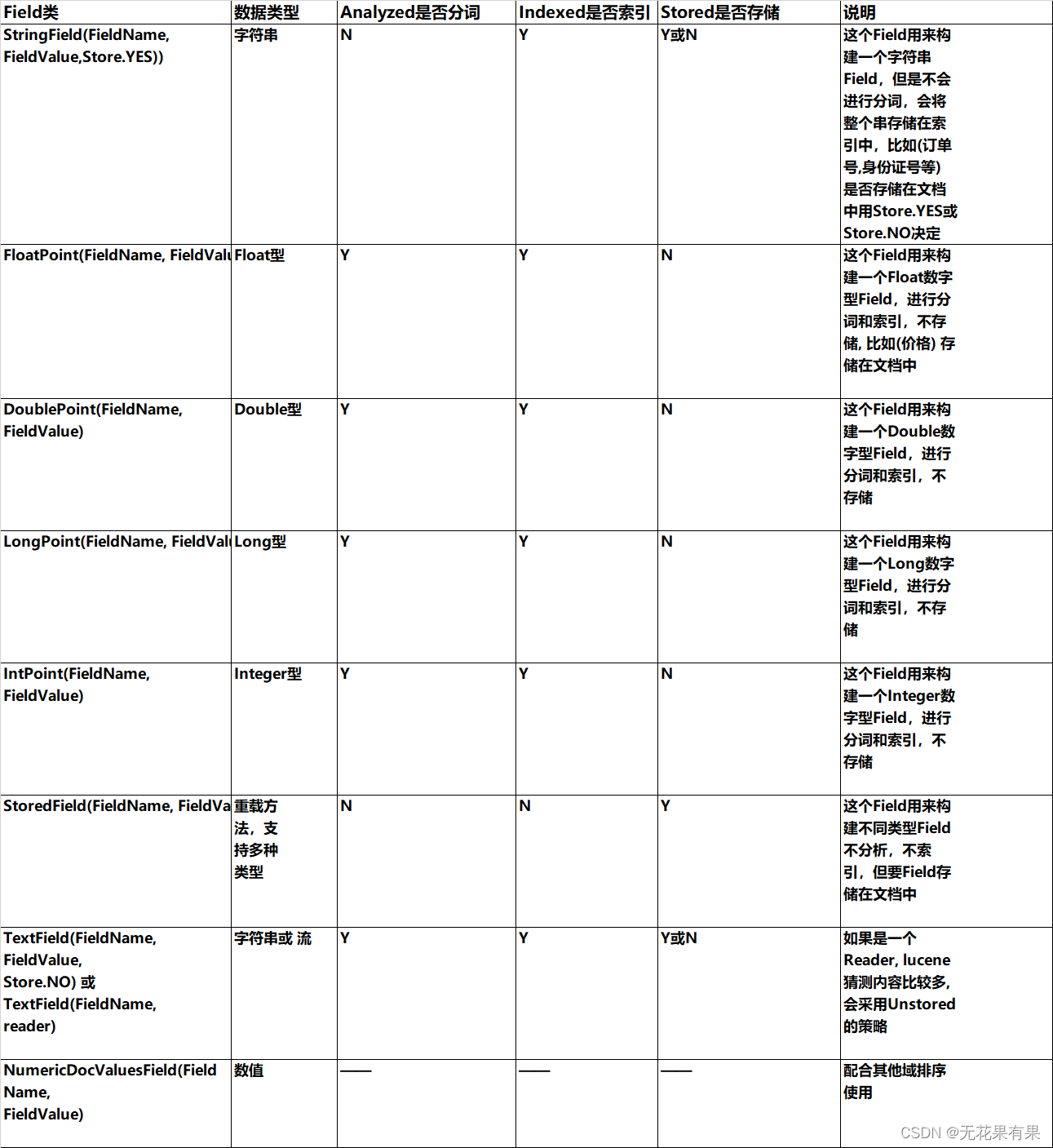
public Boolean parseContent(String keywords) throws IOException {
//1.采集数据
List contents = htmlParseUtil.parseJd(keywords);
if(contents.size()>0){
List documentList =new ArrayList();
for(Content content:contents){
//2.创建文档对象
Document document =new Document();
//创建域对象并且放入文档对象中
/**
* 是否分词:是,因为标题字段需要查询,并且分词后有意义所以需要分词
* 是否索引:是,因为需要根据标题字段查询
* 是否存储:是,因为页面需要展示标题字段,所以需要存储
*/
document.add(new TextField("title",content.getTitle(), Field.Store.YES));
/**
* 是否分词:否,因为不查询,所以不索引,因为不索引所以不分词
* 是否索引:否,因为不需要根据图片地址路径查询
* 是否存储:是,因为页面需要展示图片
*/
document.add(new StoredField("img",content.getImg()));
document.add(new StringField("price",content.getPrice(), Field.Store.YES));
//将文档对象放入到文档集合中
documentList.add(document);
}
//3.创建分词器,StandardAnalyzer标准分词器,对英文分词效果好,对中文是单词分词,也就是一个字就认为是一个词。
Analyzer analyzer =new StandardAnalyzer();
//4.创建Directory目录对象,目录对象表示索引库的位置
Directory dir = FSDirectory.open(Paths.get("E:\\luceneJdDir"));
//5.创建IndexWriterConfig对象,这个对象中指定切分词使用的分词器
IndexWriterConfig indexWriterConfig = new IndexWriterConfig(analyzer);
//6.创建IndexWriter输出流对象,指定输出的位置和使用的config初始化对象
IndexWriter indexWriter = new IndexWriter(dir,indexWriterConfig);
//7.写入文档到索引库
for(Document doc: documentList){
indexWriter.addDocument(doc);
}
//8.释放资源
indexWriter.close();
return true;
}
return false;
}

