
线程池经常用,但是很少自己去创建,程序中一般使用默认的.
默认的线程池可能会让你失望,因为Java默认线程池只有1个,且只要你不在你代码中显示的指定,那都是共享的一个线程池,且线程池内的线程数量就是你当前机器的CPU内核数cuiyaonan2000@163.com
ForkJoinPool.commonPool它的作用范围非常的广大.所有的java程序类默认的线程池,有且只有1个,即大家共享的.
比如他们俩都是默认使用了ForkJoinPool.commonPool作为线程池,当没有指定线程池时cuiyaonan2000@163.com
-
public static CompletableFuture supplyAsync(Supplier supplier, Executor executor)------Java CompletableFuture -
default Stream parallelStream() ---------Java Stream
如下以CompletableFuture.supplyAsync为例


由上可知当不指定CompletableFuture的线程池时,就会使用自带的Java线程池(单例),线程数量就是你当前机器的CUP内核数.如果你的内核数就是1,则直接新建一个线程.
示例(以Java Stream的parallelStream 来说明):
package cui.yao.nan.completablefuture;
import java.util.ArrayList;
import java.util.Collections;
import java.util.List;
import java.util.concurrent.CompletableFuture;
/**
* @Author: cuiyaonan2000@163.com
* @Description: todo
* @Date: Created at 2022-1-13 10:22
*/
public class Test3 {
public static void main(String[] args){
List a = new ArrayList();
a.add("a1");
a.add("a2");
a.add("a3");
a.add("b1");
a.add("b2");
a.add("b3");
a.add("c1");
a.add("c2");
a.add("c3");
a.add("d1");
a.add("d2");
a.add("d3");
a.add("e1");
a.add("e2");
a.add("e3");
a.parallelStream().forEach(object->{
System.out.println(Thread.currentThread().getName() +" 获取到的值为:" + object);
try {
Thread.sleep(2000);
} catch (InterruptedException e) {
e.printStackTrace();
}
});
try {
Thread.sleep(900000000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
展示结果:
(可见我们的线程池是固定的3个线程cuiyaonan2000@163.com)

ForkJoinPool是ExecutorService的实现类,因此是一种特殊的线程池。(Executors提供了几种线程池)
ForkJoinPool forkJoinPool = new ForkJoinPool();
如此就不会使用共享线程池了.
//该线程池中有3个线程,不写数字则默认cpu内核数
ForkJoinPool forkJoinPool = new ForkJoinPool(3);
forkJoinPool.submit(()->{
a.parallelStream().forEach(object->{
System.out.println(Thread.currentThread().getName() +" 获取到的值为:" + object);
try {
Thread.sleep(2000);
} catch (InterruptedException e) {
e.printStackTrace();
}
});
});同理CompletableFuture的使用也很简单
//该线程池中有3个线程,不写数字则默认cpu内核数
ForkJoinPool forkJoinPool = new ForkJoinPool();
for(int i = 0 ; i{
try {
System.out.println(Thread.currentThread().getName());
Thread.sleep(2000);
System.out.println(Thread.currentThread().getName()+" finish");
} catch (InterruptedException e) {
e.printStackTrace();
}
return 1;
},forkJoinPool);
}从JDK1.7开始,Java提供Fork/Join框架用于并行执行任务,它的思想就是讲一个大任务分割成若干小任务,最终汇总每个小任务的结果得到这个大任务的结果。
这种思想和MapReduce很像(input --> split --> map --> reduce --> output)
主要有两步:
- 第一、任务切分;
- 第二、结果合并
它的模型大致是这样的:线程池中的每个线程都有自己的工作队列(PS:这一点和ThreadPoolExecutor不同,ThreadPoolExecutor是所有线程公用一个工作队列,所有线程都从这个工作队列中取任务),当自己队列中的任务都完成以后,会从其它线程的工作队列中偷一个任务执行,这样可以充分利用资源。
任务窃取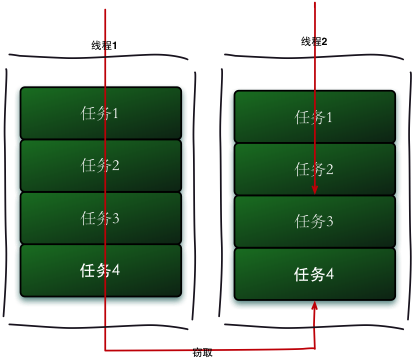
比如A线程负责处理A队列里的任务。但是有的线程会先把自己队列里的任务干完,而其他线程对应的队列里还有任务等待处理。干完活的线程与其等着,不如去帮其他线程干活,于是它就去其他线程的队列里窃取一个任务来执行。而在这时它们会访问同一个队列,所以为了减少窃取任务线程和被窃取任务线程之间的竞争,通常会使用双端队列,被窃取任务线程永远从双端队列的头部拿任务执行,而窃取任务的线程永远从双端队列的尾部拿任务执行。
工作窃取算法的优点是充分利用线程进行并行计算,并减少了线程间的竞争,其缺点是在某些情况下还是存在竞争,比如双端队列里只有一个任务时。并且消耗了更多的系统资源,比如创建多个线程和多个双端队列。
其它的线程池 ExecutorsExecutors并不能直接创建线程池,实际创建线程池的是ThreadPoolExecutor. 通过传入不同的参数来决定线程池的种类cuiyaonan2000@163.com
Java里面线程池的顶级接口是Executor,但是严格意义上讲Executor并不是一个线程池,而只是一个执行线程的工具。真正的线程池接口是ExecutorService。所以它们的关系如下所示:
类名 说明Executor工具类,提供了几种配置的线程池ExecutorService真正的线程池接口ThreadPoolExecutorExecutorService的默认实现ScheduledThreadPoolExecutor继承ThreadPoolExecutor的ScheduledExecutorService接口实现,周期性任务调度的类实现。 newFixedThreadPool创建
ExecutorService newFixThreadPool_1 = Executors.newFixedThreadPool(1);
CompletableFuture future = CompletableFuture.supplyAsync(()->{
return 1;
},newFixThreadPool_1);源代码:

由上可知(其它的亦是如此,因为都是使用ThreadPoolExecutor创建的线程池cuiyaonan2000@163.com):
- 这是一个固定线程的线程池
-
LinkedBlockingQueue用于接收阻塞的任务,当有一条线程处理完任务,就会从里取任务cuiyaonan2000@163.com
创建了一个具有缓冲队列的单线程的线程池。
newCachedThreadPool
线程池内的线程可以是无限大(具体这么大:Integer.MAX_VALUE),当该工作线程超过60秒没有任务后就会注销
由于corePoolSize为0所以任务会放入SynchronousQueue队列中,SynchronousQueue只能存放大小为1,所以会立刻新起线程

支持定时及周期性任务执行的线程池。继承了ThreadPoolExecutor。使用的阻塞队列时DelayQueue

通过Executors创建线程池的源码看到,其实真正做事的是ThreadPoolExecutors,如何设置它的构造函数决定了线程池的特性cuiyaonan2000@163.com
构造方法这个构造方法提供了多个,但是传递的参数才是重点.大同小异.

线程池维护线程的最少数量 。在创建了线程池后,默认情况下,线程池中并没有任何线程,而是等待有任务到来才创建线程去执行任务,除非调用了prestartAllCoreThreads()或者prestartCoreThread()方法,从这2个方法的名字就可以看出,是预创建线程的意思,即在没有任务到来之前就创建corePoolSize个线程或者一个线程。
默认情况下,在创建了线程池后,线程池中的线程数为0,当有任务来之后,就会创建一个线程去执行任务,当线程池中的线程数目达到corePoolSize后,就会把到达的任务放到缓存队列当中;
maximumPoolSize线程池最大线程数,这个参数也是一个非常重要的参数,它表示在线程池中最多能创建多少个线程;keepAliveTime表示线程没有任务执行时最多保持多久时间会终止。默认情况下,只有当线程池中的线程数大于corePoolSize时,keepAliveTime才会起作用,直到线程池中的线程数不大于corePoolSize,即当线程池中的线程数大于corePoolSize时,如果一个线程空闲的时间达到keepAliveTime,则会终止,直到线程池中的线程数不超过corePoolSize。但是如果调用了allowCoreThreadTimeOut(boolean)方法,在线程池中的线程数不大于corePoolSize时,keepAliveTime参数也会起作用,直到线程池中的线程数为0;unit参数keepAliveTime的时间单位,有7种取值,在TimeUnit类中有7种静态属性:
- TimeUnit.DAYS; //天
- TimeUnit.HOURS; //小时
- TimeUnit.MINUTES; //分钟
- TimeUnit.SECONDS; //秒
- TimeUnit.MILLISECONDS; //毫秒
- TimeUnit.MICROSECONDS; //微妙
- TimeUnit.NANOSECONDS; //纳秒
阻塞队列,常用的是:
ArrayBlockingQueue LinkedBlockingQueue SynchronousQueuethreadFactory线程工厂,主要用来创建线程;handler
表示当拒绝处理任务时的策略,有以下四种取值:
ThreadPoolExecutor.AbortPolicy:丢弃任务并抛出RejectedExecutionException异常 ThreadPoolExecutor.DiscardPolicy:也是丢弃任务,但是不抛出异常。 ThreadPoolExecutor.DiscardOldestPolicy:丢弃队列最前面的任务,然后重新尝试执行任务(重复此过程) ThreadPoolExecutor.CallerRunsPolicy:由调用线程处理该任务阻塞队列
构造函数中有个阻塞队列,该队列是用于解决,当运行线程都在执行任务,如何处理新进任务的.很大程度上决定了线程池的特性cuiyaonan2000@163.com
- ArrayBlockingQueue : 数组结构组成的有界阻塞队列。此队列按照先进先出(FIFO)的原则对元素进行排序,但是默认情况下不保证线程公平的访问队列,即如果队列满了,那么被阻塞在外面的线程对队列访问的顺序是不能保证线程公平(即先阻塞,先插入)的。
- LinkedBlockingQueue: 一个由链表结构组成的有界阻塞队列.此队列按照先出先进的原则对元素进行排序
- DelayQueue: 支持延时获取元素的无界阻塞队列,即可以指定多久才能从队列中获取当前元素
- SynchronousQueue: 不存储元素的阻塞队列,每一个put必须等待一个take操作,否则不能继续添加元素。并且他支持公平访问队列。
- PriorityBlockingQueue支持优先级的无界阻塞队列
- LinkedTransferQueue由链表结构组成的无界阻塞TransferQueue队列。
- LinkedBlockingDeque链表结构的双向阻塞队列,优势在于多线程入队时,减少一半的竞争。

