解决大数据的问题,只有一个方案就是分片.传统数据库跟非传统数据库的最主要的区别是:谁天生就能进行分片.但是针对分片同时也会有一些事项需要注意,这需要我们在设计的时候考虑cuiyaonan2000@163.com
分库分表是我们解决数据量大,单台数据存储节点瓶颈遇到问题时的解决方案.但是如何分库,如何分表需要根据我们的业务情况进行一个合理的设计,同时也要搞清楚其它的非结构化数据库是怎么分库,分表的这样子才能用的安心顺畅cuiyaonan2000@163.com
巨人的肩膀:
- Sharding-JDBC 实战(史上最全)_架构师-尼恩的博客-CSDN博客_shardingjdbc
- https://www.jianshu.com/p/b208804dce9c
一种是按照 range 来分,就是每个片,一段连续的数据.
这个一般是按比如时间范围/数据范围来的,但是这种一般较少用,因为很容易发生数据倾斜,大量的流量都打在最新的数据上了。这样子 就不能充分利用多个数据节点集群的算力了cuiyaonan2000@163.com
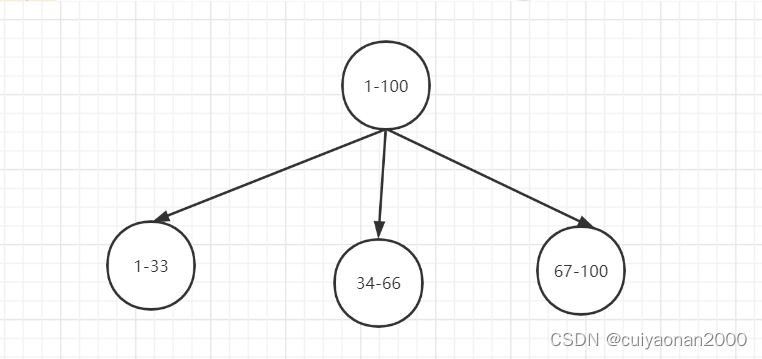
比如,安装数据范围分片,把1到100个数字,要保存在3个节点上
按照顺序分片,把数据平均分配三个节点上
- 1号到33号数据保存到节点1上
- 34号到66号数据保存到节点2上
- 67号到100号数据保存到节点3上
如上range是连续的数据分在一个节点,ID取模则是将记录均匀的分不到不同的节点上.比如ID与节点数进行取模,这样子就会均匀的分不到不同的节点上.这里的ID必然是数字型的ID.同时这样子不适合进行批量查询cuiyaonan2000@163.com
hash 哈希分布(业务常用)使用hash 算法,获取key的哈希结果,再按照规则进行分片,这样可以保证数据被打散,同时保证数据分布的比较均匀
哈希分布方式分为三个分片方式:
- 哈希取余分片
- 一致性哈希分片
- 虚拟槽分片
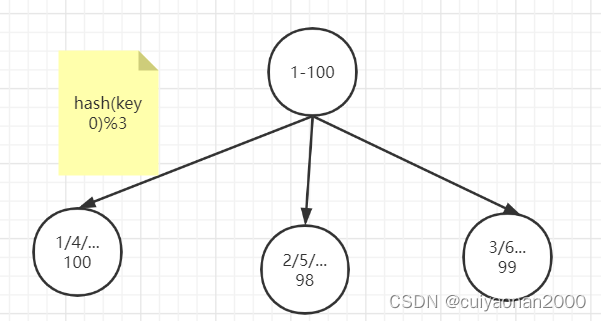
例如1到100个数字,对每个数字进行哈希运算,然后对每个数的哈希结果除以节点数进行取余,余数为1则保存在第1个节点上,余数为2则保存在第2个节点上,余数为0则保存在第3个节点,这样可以保证数据被打散,同时保证数据分布的比较均匀
比如有100个数据,对每个数据进行hash运算之后,与节点数进行取余运算,根据余数不同保存在不同的节点上------类似于ID取模分片cuiyaonan2000@163.com
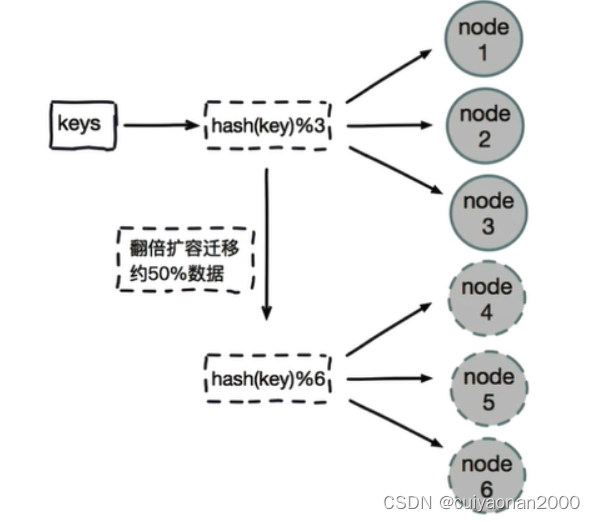
如此这般,当我们要增加存储节点或者减少存储节点的时候必然会产生数据的移动,针对哈希取模分片的最优方案就是:哈希取余分片,建议使用多倍扩容的方式,例如以前用3个节点保存数据,扩容为比以前多一倍的节点即6个节点来保存数据,这样只需要适移50%的数据。
哈希取余分片优点:
- 配置简单:对数据进行哈希,然后取余
哈希取余分片缺点:
- 数据节点伸缩时,导致数据迁移
- 迁移数量和添加节点数据有关,建议翻倍扩容
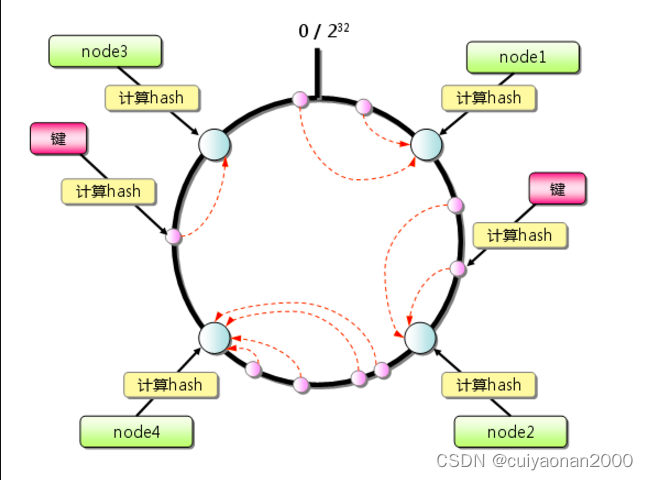
一致性hash是一个0-2^32的闭合圆,(拥有2^23个桶空间,每个桶里面可以存储很多数据,可以理解为s3的存储桶)所有节点存储的数据都是不一样的。计算一致性哈希是采用的是如下步骤:
- 对节点进行hash,通常使用其节点的ip或者是具有唯一标示的数据进行hash(ip),将其值分布在这个闭合圆上。------首先根据计算把数据节点均匀的分布到这个圆环上cuiyaonan2000@163.com
- 将存储的key进行hash(key),然后将其值要分布在这个闭合圆上。----在根据数据相关信息,计算该条记录在该圆环的那个位置
- 从hash(key)在圆上映射的位置开始顺时针方向找到的一个节点即为存储key的节点。如果到圆上的0处都未找到节点,那么0位置后的顺时针方向的第一个节点就是key的存储节点。---最后计算该记录属于哪个节点
关于它的数据迁移问题要比哈希取模的迁移数据量小很多.适合于大数据量情况下的数据迁移.
一致性哈希分片优点:
- 一致性哈希算法解决了分布式下数据分布问题。比如在缓存系统中,通过一致性哈希算法把缓存键映射到不同的节点上,由于算法中虚拟节点的存在,哈希结果一般情况下比较均匀。
- 节点伸缩时,只影响邻近节点,但是还是有数据迁移
一致性哈希分片缺点:
- 一致性哈希在大批量的数据场景下负载更加均衡,但是在数据规模小的场景下,会出现单位时间内某个节点完全空闲的情况出现。----即在小数据量的情况下没有充分用到集群的算力cuiyaonan2000@163.com
如下图所示在node2 和node4 之间新增加一个节点,则会涉及到数据的迁移情况
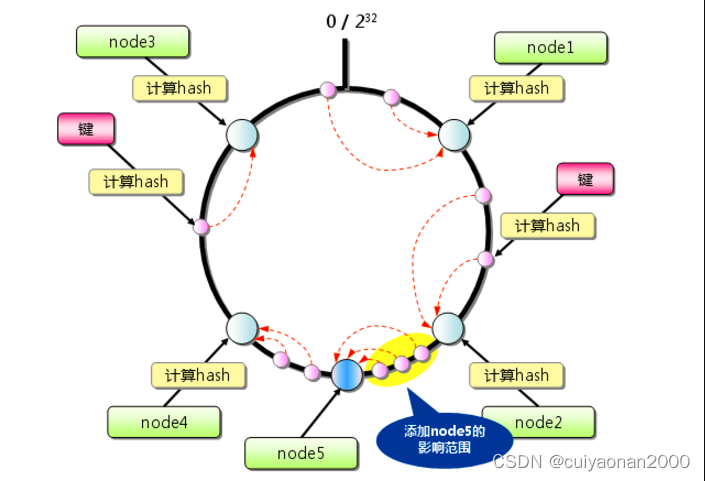
虚拟节点 为了解决雪崩现象和数据倾斜现象,提出了虚拟节点这个概念。就是将真实节点计算多个哈希形成多个虚拟节点并放置到哈希环上,定位算法不变,只是多了一步虚拟节点到真实节点映射的过程
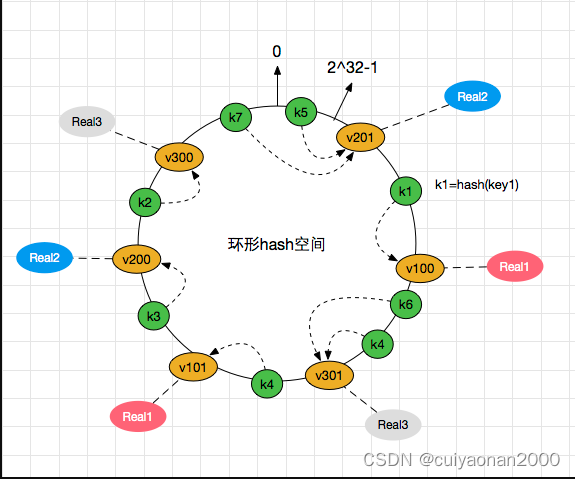
如下图所示,真实节点并不分布在圆环上,而是通过创建多个虚拟节点的方式分布在这个圆环上(比如Real2 关联了v201和v200 2个节点,real1关联了v100和v101这两个虚拟节点).当real1物理机挂掉后,v100 和v101都会挂掉,但是real1上的数据不会只转存到real2一台物理机上,而是被real2和real3瓜分了.如此这般解决雪崩问题和数据倾斜问题cuiyaonan2000@163.com
虚拟槽分片 (范围分片的变种)
虚拟槽分片是Redis Cluster采用的分片方式.
虚拟槽分片 ,可以理解为范围分片的变种, hash取模分片+范围分片, 把hash值取余数分为n段,一个段给一个节点负责------这个跟一致性哈希分片的区别是,一个是要求数据能行程一个闭环,一个是非闭环
代表索引分片,es可以把一个完整的索引分成多个分片,这样的好处是可以把一个大的索引拆分成多个,分布到不同的节点上。构成分布式搜索。并且索引创建后不能更改
片配置建议:每个分片大小不要超过30G,硬盘条件好的话,不建议超过100G.(官方推荐,每个shard的数据量应该在20GB - 50GB)。
每个分片都是一个Lucene实例,当查询请求打到ES后,ES会把请求转发到每个shard上分别进行查询,最终进行汇总。这时候,shard越少,产生的额外开销越少
一条数据是如何落地到对应的shard上的?
es的路由过程是根据下面这个算法决定的(ES不具自动迁移数据的能力否则,分片就可以动态的进行修改cuiyaonan2000@163.com):
shard_num = hash(_routing) % num_primary_shards
其中 _routing是一个可变值,默认是文档的 _id 的值 ,也可以设置成一个自定义的值。Elasticsearch文档的ID(类似于关系数据库中的自增ID),
_routing 通过 hash 函数生成一个数字,然后这个数字再除以 num_of_primary_shards (主分片的数量)后得到余数 。
这个分布在 0 到 number_of_primary_shards-1 之间的余数,就是我们所寻求的文档所在分片的位置。
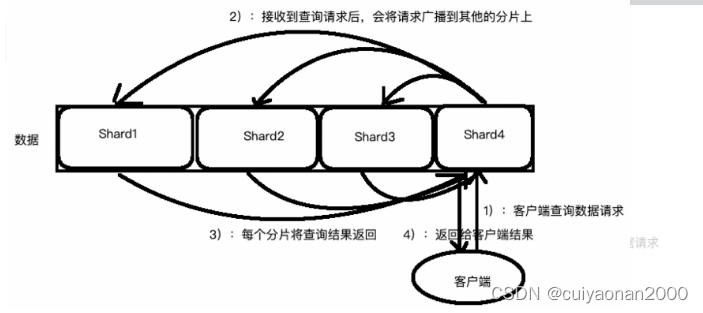
- 这个搜索的请求会被发送到一个节点
- 接收到这个请求的节点,将这个查询广播到这个索引的每个分片上(可能是主分片,也可能是复本分片)
- 每个分片执行这个搜索查询并返回结果
- 结果在通道节点上合并、排序并返回给用户
Redis Cluster在设计中没有使用一致性哈希(Consistency Hashing),而是使用数据分片引入哈希槽(hash slot)来实现;
虚拟槽分片是Redis Cluster采用的分片方式.
在该分片方式中:
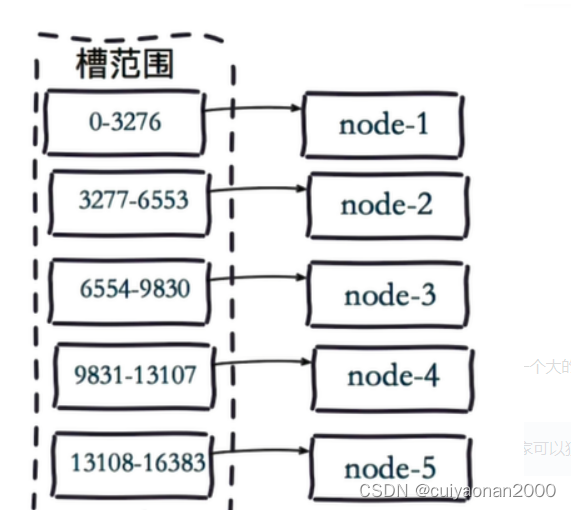
- 首先 预设虚拟槽,每个槽为一个hash值,每个node负责一定槽范围。
- 每一个值都是key的hash值取余,每个槽映射一个数据子集,一般比节点数大
Redis Cluster中预设虚拟槽的范围为0到16383
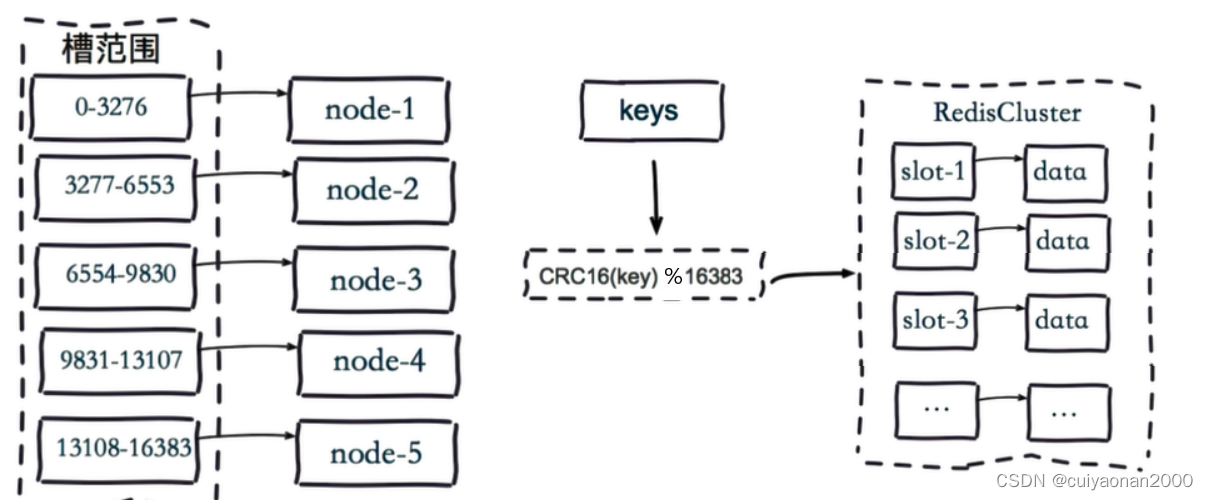
需要注意的是:Redis Cluster的节点之间会共享消息,每个节点都会知道是哪个节点负责哪个范围内的数据槽.当节点扩容或者缩容时,会自动对数据进行迁移,所以我们可以动态增加节点,增加虚拟槽的数量。


