spring-data系列为众多中间件、数据库的操作提供了极其方便的API,对于elasticsearch也不例外,spring-data-elasticsearch不仅为我们提供了现成的CRUD接口,也提供了简便的各类java client的整合方案
所以今天我们就来讲解,如果在springboot项目中整合spring-data-elasticsearch
1. 环境介绍在真正开始搭建之前,我们需要了解我们的运行环境,以防止大家因为环境的问题产生出各类不易排查的错误或冲突
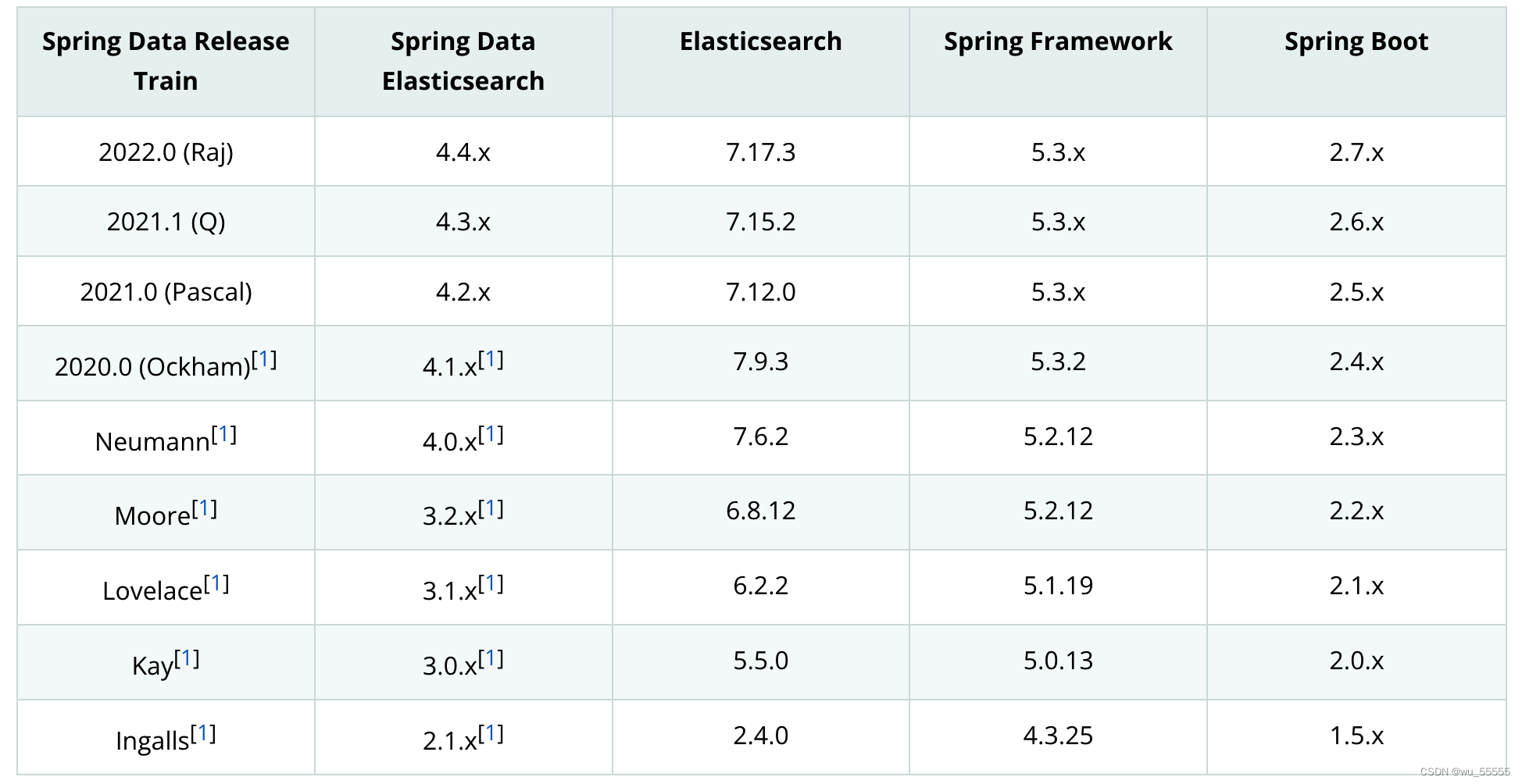
首先要知道spring,spring-data-es,es之间的版本对应关系,我们可以在官网中找到版本对应表
这里我使用的是
java 1.8
spring-data-elasticsearch 3.2.12.RELEASE
springboot 2.2.13.RELEASE
一般来说我们引入spring-data-elasticsearch依赖的版本要与springboot版本保持对应,如上表所示,如果你的elasticsearch版本是7.15,那么对应的springboot版本就是2.6.x,spring-data-elasticsearch版本是4.3.x
这种对应版本时,我们可以通过引入spring-boot-starter-data-elasticsearch依赖,spring-boot-starter依赖会自动根据我们的springboot版本匹配对应的spring-data-elasticsearch版本来引入,就不用我们再去查找版本表来手动声明版本了
org.springframework.boot
spring-boot-starter-data-elasticsearch
比如我创建的项目springboot版本是2.3.7.RELEASE,当我引入spring-boot-starter-data-elasticsearch后,我们点击其pom文件会发现,其对应的spring-data-elasticsearch版本是4.0.6.RELEASE

这种方式是我们更加推荐的,但是实际开发时,会面临一些不如人愿的情形,比如我们是在旧项目中引入spring-data-elasticsearch,旧项目的springboot版本已经固定,不允许修改,但是我们使用的es版本比较新,导致springboot对应的spring-data-elasticsearch和es版本就不匹配了,这种时候,就需要我们根据需要手动声明spring-data-elasticsearch版本
org.springframework.data
spring-data-elasticsearch
3.2.12.RELEASE
同时还要注意,不同的spring-data-elasticsearch版本所支持的方法会有所调整,你可能会发现在网上搜到的一些方法,在你的环境用起来就报错或者达不到想要的效果,这就是版本差异导致的问题。这就需要我们去详细了解不同版本间API的调整
具体可以通过官网查看,但更多的还需要我们自己实践出真知
2. 环境搭建1、首先创建一个springboot项目,并且引入spring web、spring-data-elasticsearch依赖
org.springframework.boot
spring-boot-starter-web
org.springframework.data
spring-data-elasticsearch
3.2.12.RELEASE
2、修改配置文件application.yml
spring:
elasticsearch:
rest:
uris: http://192.168.244.11:9200 # es地址,多个地址用逗号隔开
username: elastic # es开启了security的需要添加用户名和账户
password: elastic # es开启了security的需要添加用户名和账户
这里需要注意,提前开启好es服务器的9200端口,否则会导致无法连接到es
3、创建索引实体类
这里的实体类也就是我们es索引中所对应的数据结构
比如我们要在es中创建的索引如下所示,注意这里使用了ik分词器,需要提前在es中安装,这里就不再演示安装了,不需要中文分词的可以不用安装
PUT user
{
"mappings": {
"properties": {
"name": {
"type": "text",
"analyzer": "standard"
},
"password":{
"type": "keyword"
},
"sex": {
"type": "integer"
},
"address":{
"type": "text",
"analyzer": "ik_smart"
},
"create_date":{
"type": "date",
"format": "yyyy-MM-dd HH:mm:ss||strict_date_optional_time||epoch_millis"
}
}
}
}
那么对应的实体类就如下所示,因为我这里演示用的es单节点,所以设置主分片数为1,副本分片为0,否则会导致节点状态报黄
其次还需要注意的是,这里声明了type="_doc",type属性在新版本中已经被取消了,默认为“_doc”,这里因为我使用的spring-data-elasticsearch版本还是3.2.x,这个版本中还需要声明type,否则会创建与类名同名的type。但因为es使用的是高版本的,已经默认创建了"_doc"的type,不声明的会就会创建两个type,导致启动报错。
声明后后续启动项目会出现[types removal] Using include_type_name in put mapping requests is deprecated. The parameter will be removed in the next major version报错,不影响使用,但是大家要做了解
import lombok.Data;
import org.springframework.data.annotation.Id;
import org.springframework.data.elasticsearch.annotations.Document;
import org.springframework.data.elasticsearch.annotations.Field;
import org.springframework.data.elasticsearch.annotations.FieldType;
import java.util.Date;
/**
* @author whx
* @date 2022/7/2
*/
@Data
@Document(indexName = "user",replicas = 0,shards = 1, type = "_doc")
public class User implements Serializable {
@Id
private String id;
@Field(type = FieldType.Text, name = "name",analyzer = "standard")
private String name;
@Field(type = FieldType.Keyword, name = "password")
private String password;
@Field(type = FieldType.Integer, name = "sex")
private Integer sex;
@Field(type = FieldType.Text, name = "address", analyzer = "ik_smart")
private String address;
@Field(type = FieldType.Date, name = "create_date", format = DateFormat.custom, pattern="yyyy-MM-dd HH:mm:ss||strict_date_optional_time||epoch_millis")
private Date createDate;
}
大家可以看到其属性是一一对应的。其中日期类型如果不声明format的话,默认是strict_date_optional_time||epoch_millis,其类型说明可参考官方文档介绍
当然这种实体类是比较简单的,一般我们使用es索引时都会有比较复杂的嵌套结构,比如索引中有子数据,即基础数组数据,或者json数组数据
所谓基础数组就是数组中承装的是基础类型,而json数组就是承装的是一个子类
在es索引中的定义为
// 基础数组
"role_ids": {
"type": "long"
},
// json数组
"department_list":{
"type": "nested",
"properties": {
"id": {
"type": "long"
},
"name": {
"type": "keyword"
}
}
}
那么到实体类中定义也类似,可以看到基础类型的数组直接申明为元素的数据类型即可,而json型数组是需要声明为Nested类型的,这也是es的基础知识,这里就不做展开,大家了解即可
@Field(type = FieldType.Long, name = "role_ids")
private List roleIds;
@Field(type = FieldType.Nested, name = "department_list")
private List departmentList;
@Data
public class Department implements Serializable {
@Field(type = FieldType.Long, name = "id")
private Long id;
@Field(type = FieldType.Keyword, name = "name")
private String name;
}
4、创建Repository接口,实现简单的增删改查方法
spring-data-elasticsearch提供了ElasticsearchCrudRepository接口,来让我们快速实现简单的增删改查方法,使用也很简单,只需要继承ElasticsearchCrudRepository类即可,该类的第一个参数是我们的索引实体类,第二个参数是id字段数据类型
import com.example.estest.entity.User;
import org.springframework.data.elasticsearch.repository.ElasticsearchCrudRepository;
/**
* @author whx
* @date 2022/7/2
*/
public interface UserRepository extends ElasticsearchCrudRepository {
}
该接口提供了常见的增删改查方法,同时也支持我们自定义方法,可以通过如下两种方法定义一些简单的CRUD方法:
- 通过spring data自带的语法来自动生成衍生方法
如:根据名称来查询
public interface UserRepository extends ElasticsearchCrudRepository {
User findByName(String name);
}
支持的语法有

- 通过@Query自定义查询
query中的就是查询的DSL语句,?0表示第一个参数
@Query("{\"term\": {\"name\": {\"value\": \"?0\"}}}")
User queryByName(String name);
如果需要分页的话,也可以添加Pageable来实现分页
Page findByName(String name, Pageable pageable);
@Query("{\"term\": {\"name\": {\"value\": \"?0\"}}}")
Page queryByName(String name,Pageable pageable);
此外我们再添加几个不同类型的查询方法来方便测试:
public interface UserRepository extends ElasticsearchCrudRepository {
User findByName(String name);
List findAllByName(String name);
Page findAllByName(String name, Pageable pageable);
@Query("{\"term\": {\"name\": {\"value\": \"?0\"}}}")
User queryByName(String name);
}
5、创建controller
import com.example.estest.entity.User;
import com.example.estest.repository.UserRepository;
import lombok.AllArgsConstructor;
import org.springframework.data.domain.Page;
import org.springframework.data.domain.PageRequest;
import org.springframework.web.bind.annotation.*;
import java.util.List;
/**
* @author whx
* @date 2022/7/2
*/
@RestController
@RequestMapping("user")
@AllArgsConstructor
public class UserController {
private final UserRepository userRepository;
@GetMapping("getByName")
public User getByName(String name){
return userRepository.findByName(name);
}
@GetMapping("getAllByName")
public List getAllByName(String name){
return userRepository.findAllByName(name);
}
@GetMapping("pageAllByName")
public Page pageAllByName(String name,int page,int size){
return userRepository.findAllByName(name,PageRequest.of(page,size));
}
@GetMapping("queryByName")
public User queryByName(String name){
return userRepository.queryByName(name);
}
@PostMapping("save")
public String add(@RequestBody User user){
try{
userRepository.save(user);
return "保存成功";
}catch (Exception e){
e.printStackTrace();
return "保存失败";
}
}
}
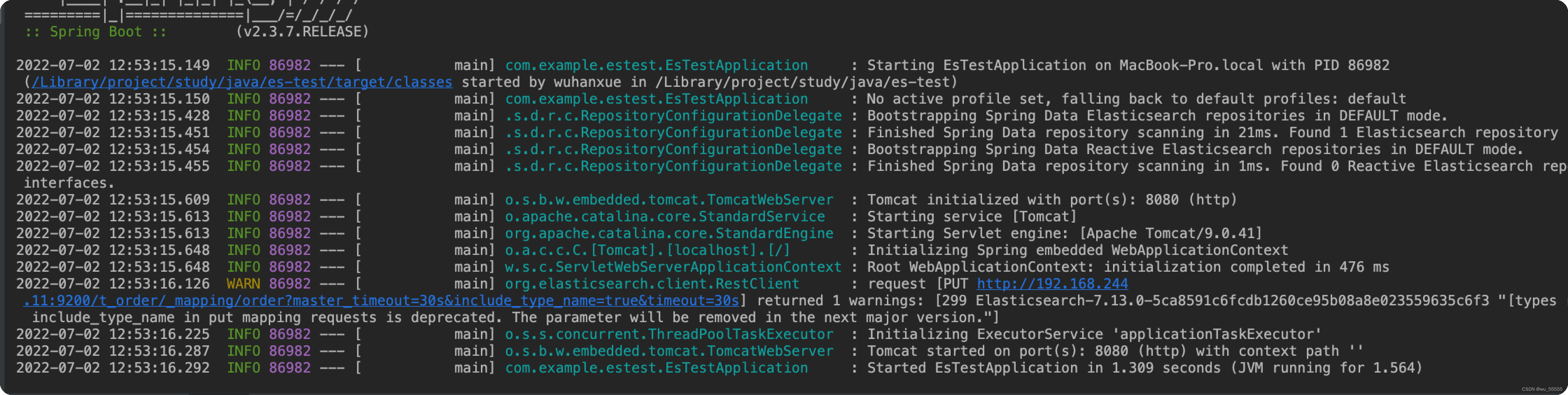
6、启动项目
如果这里启动失败的话,请检查下配置文件中填写的es地址是否正确,或者根据报错内容进行排错
 7、调用save接口,新增数据测试
7、调用save接口,新增数据测试
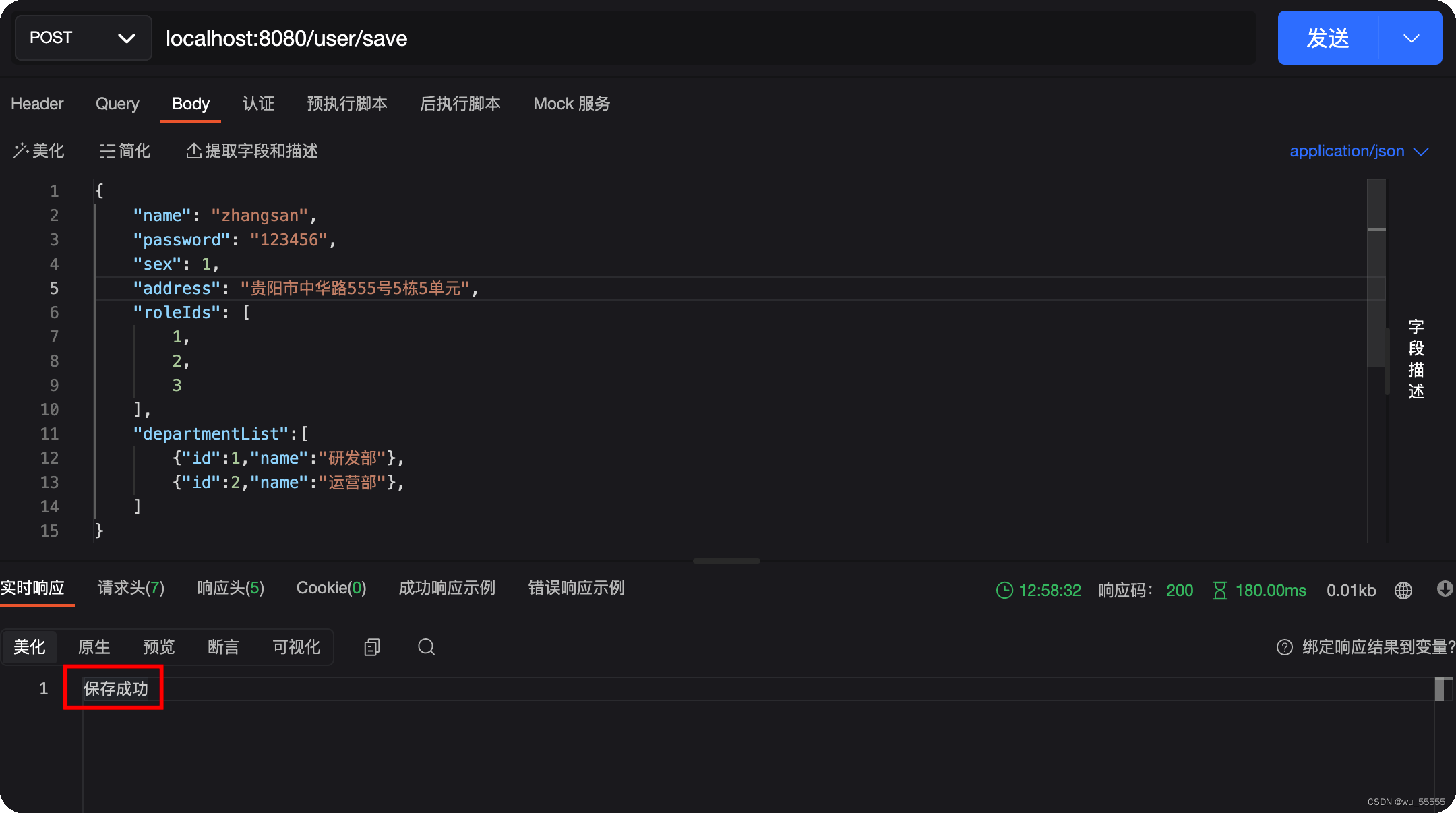
保存成功,在kibana中查询数据,发现也已经添加成功了
这里可以看到,新增数据的时候如果不声明id值的话,会默认给我们一个随机ID
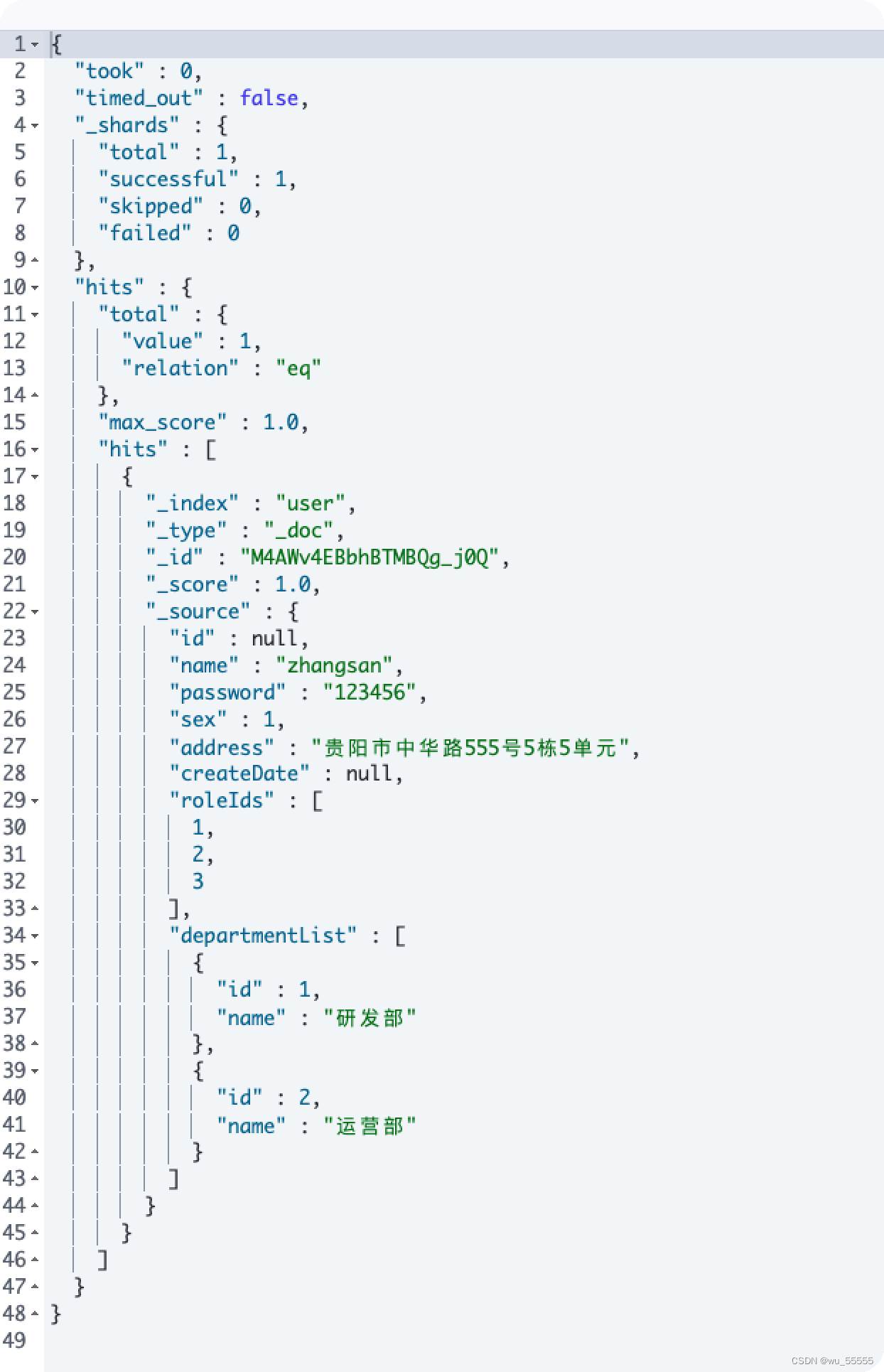
8、调用查询接口
getByName
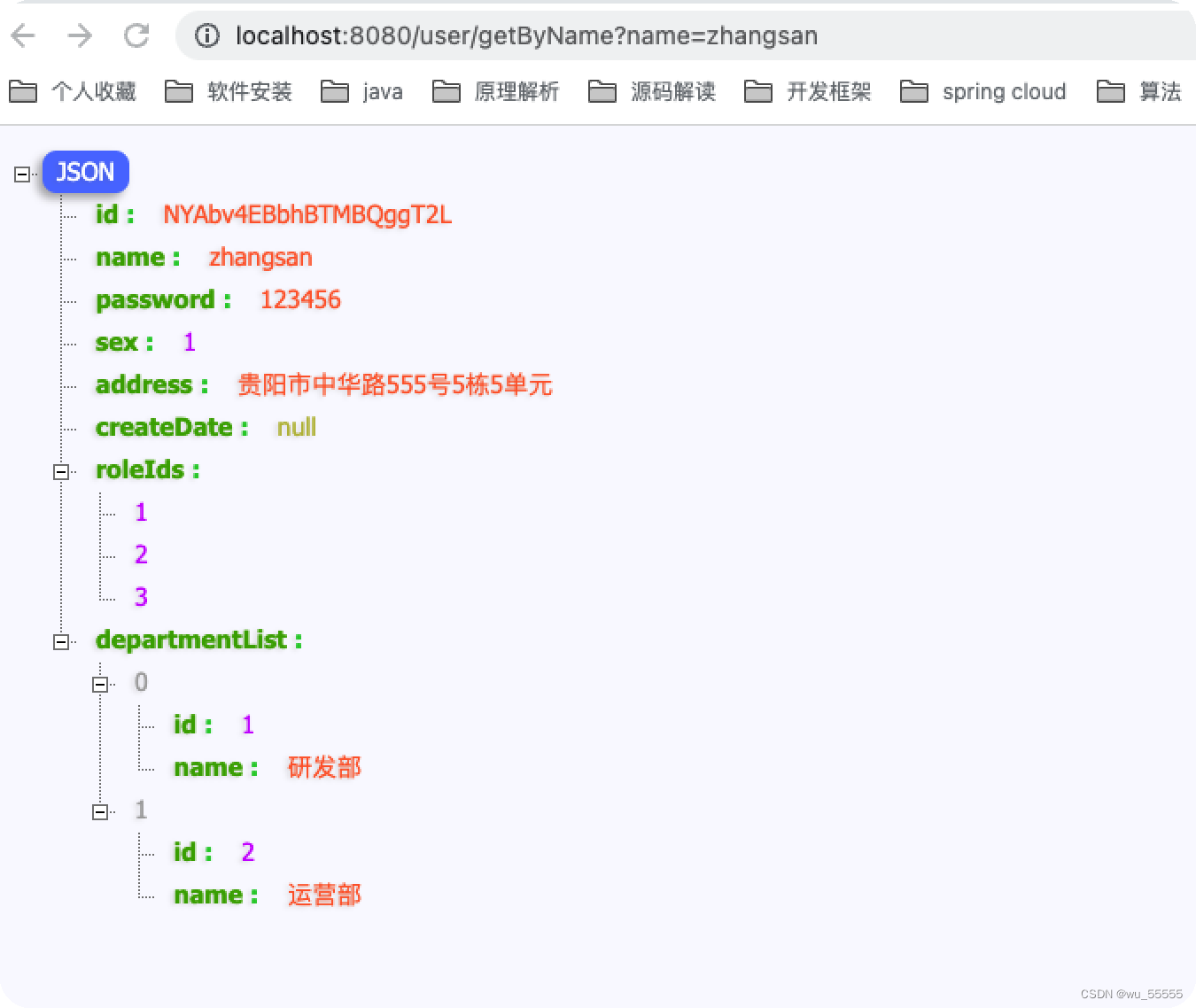
queryByName

getAllByName

pageAllByName
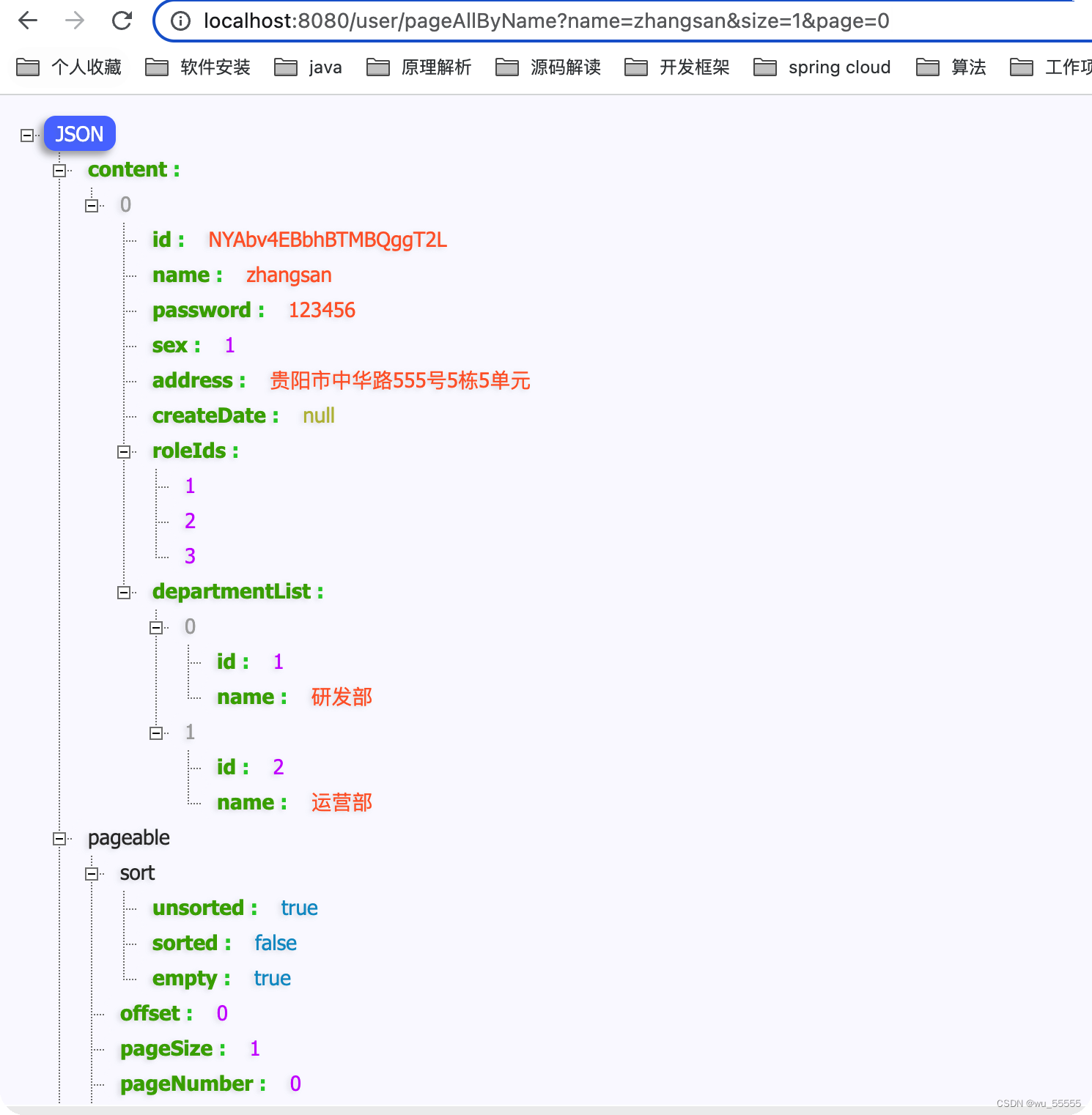
查询成功
这里可能会产生的一个错误是: NoSuchMethodError: org.elasticsearch.search.SearchHits.getTotalHits()
这是因为es7.x版本时要求springboot版本得是2.3.x。反之如果你的springboot版本是2.3.x那么spring-data-elasticsearch对应的版本得是4.0.x+。如我所用的spring-data-elasticsearch版本为3.2.12,则springboot版本不能是2.3+。可以结合上文的版本表对应版本
至此我们的基础环境就搭建成功了,但是要深入使用还需要以下额外配置
3. 配置RestHighLevelClient上述提供的ElasticsearchCrudRepository仅仅只能实现简单的CRUD,我们很多场景下是需要进行复杂的查询或聚合操作的
这个时候就需要使用其他的java client来补充操作了,比如HighLevelRestClient,不过大家要了解的是es官方已经不推荐使用Rest Client和Transport Client了,并且会在es8.x时废除。更加推荐使用Java Client,但是因为学习成本、使用习惯以及很多公司仍然在使用6.x或更早版本的es,所以在es7.x版本或更早,HighLevelRestClient依旧是不错的选择
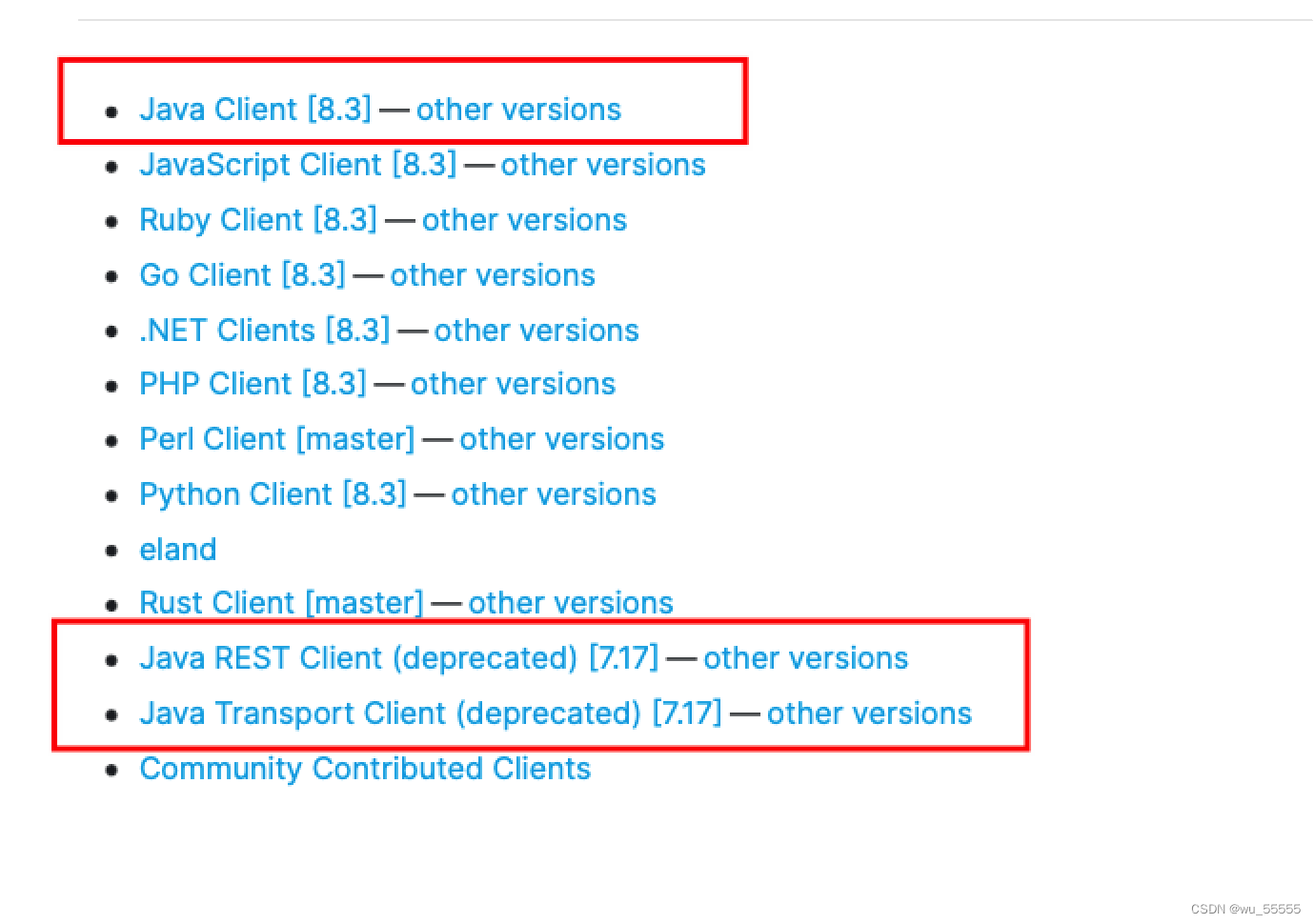
要配置也很简单,只需要添加配置类
@Configuration
@EnableElasticsearchRepositories(basePackages = "com.example.estest")
public class ElasticRestClientConfig extends AbstractElasticsearchConfiguration {
@Value("${spring.elasticsearch.rest.uris}")
private String url;
@Value("${spring.elasticsearch.rest.username}")
private String username;
@Value("${spring.elasticsearch.rest.password}")
private String password;
@Override
@Bean
public RestHighLevelClient elasticsearchClient() {
url = url.replace("http://","");
String[] urlArr = url.split(",");
HttpHost[] httpPostArr = new HttpHost[urlArr.length];
for (int i = 0; i {
// 账号密码登录
httpClientBuilder.setDefaultCredentialsProvider(credentialsProvider);
// httpclient连接数配置
httpClientBuilder.setMaxConnTotal(30);
httpClientBuilder.setMaxConnPerRoute(10);
// httpclient保活策略
httpClientBuilder.setKeepAliveStrategy(((response, context) -> Duration.ofMinutes(5).toMillis()));
return httpClientBuilder;
});
return new RestHighLevelClient(builder);
}
@Bean
public ElasticsearchRestTemplate elasticsearchRestTemplate(RestHighLevelClient elasticsearchClient, EntityMapper entityMapper){
return new ElasticsearchRestTemplate(elasticsearchClient,entityMapper);
}
}
关于利用RestHighLevelClient实现更加复杂的es查询、聚合操作,可以参考专栏的其他文章,这里就不再深入了。
如上所示的演示操作中,有一点不知道大家发现没有,我们在添加数据时,是没有添加日期类型的字段createDate的。那么我们现在来添加试试看
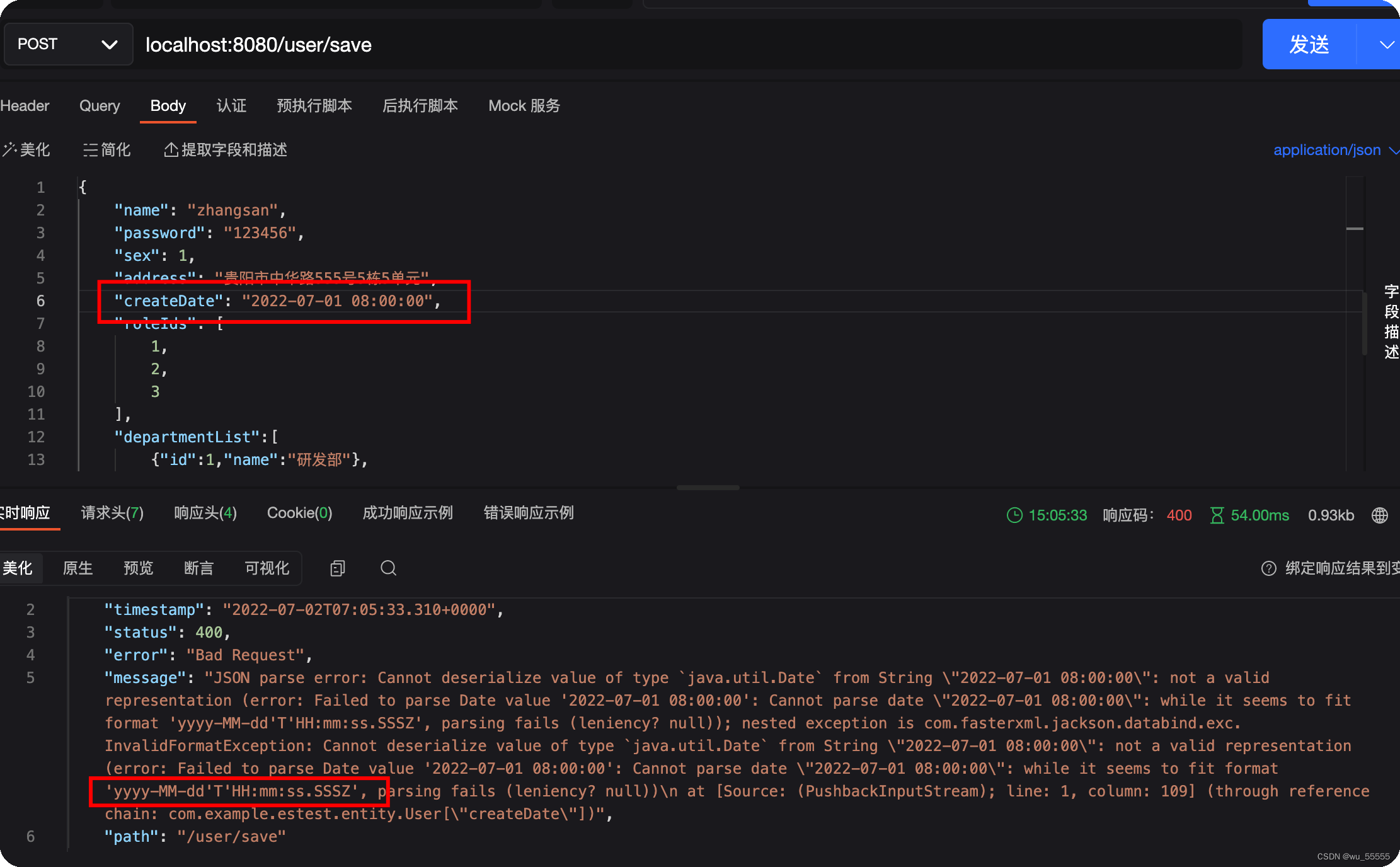
结果出现报错,根据报错内容来看,是因为es默认的时间类型格式是yyyy-MM-dd'T'HH:mm:ss.SSSZ,但我们更倾向于使用yyyy-MM-dd HH:mm:ss的日期格式
那么我们要如何改变这个日期格式呢?
问题出在前端向后端接口传送日期数据时jackson无法转换,只需要在配置文件中申明
spring:
jackson:
date-format: yyyy-MM-dd HH:mm:ss
或者在对应字段上添加注解
@DateTimeFormat(pattern = "yyyy-MM-dd HH:mm:ss")
@JsonFormat(pattern = "yyyy-MM-dd HH:mm:ss", timezone = "GMT+08:00")
新增数据,执行成功 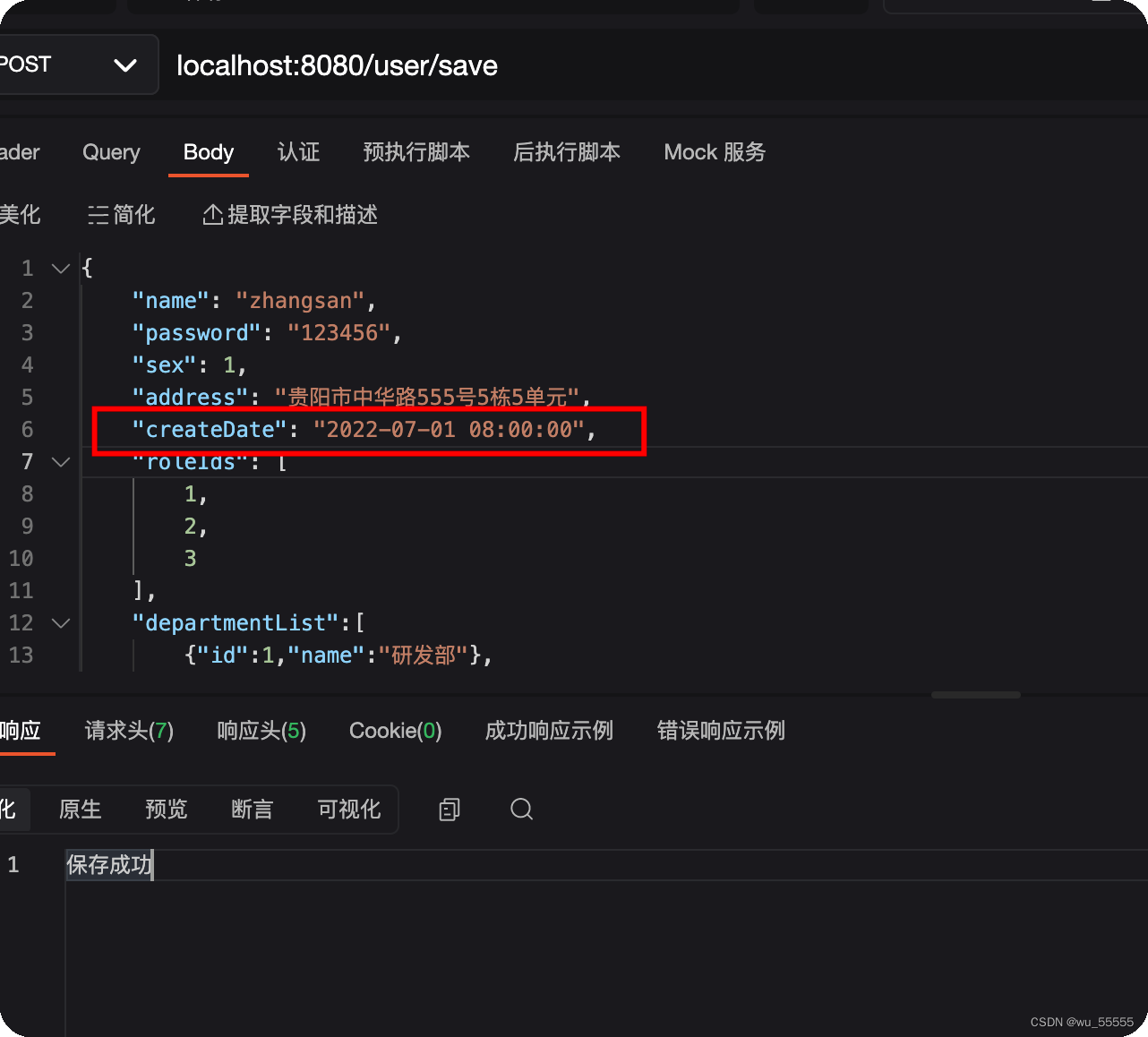
日期类型数据的问题解决了,但是我们在kibana中查询数据发现,我们在实体类中设置了字段的大小写命名转换为下划线的,如实体类中createDate映射到es中为create_date,但实际并没有如我们所愿进行转换,这就是我们下一步需要继续配置的
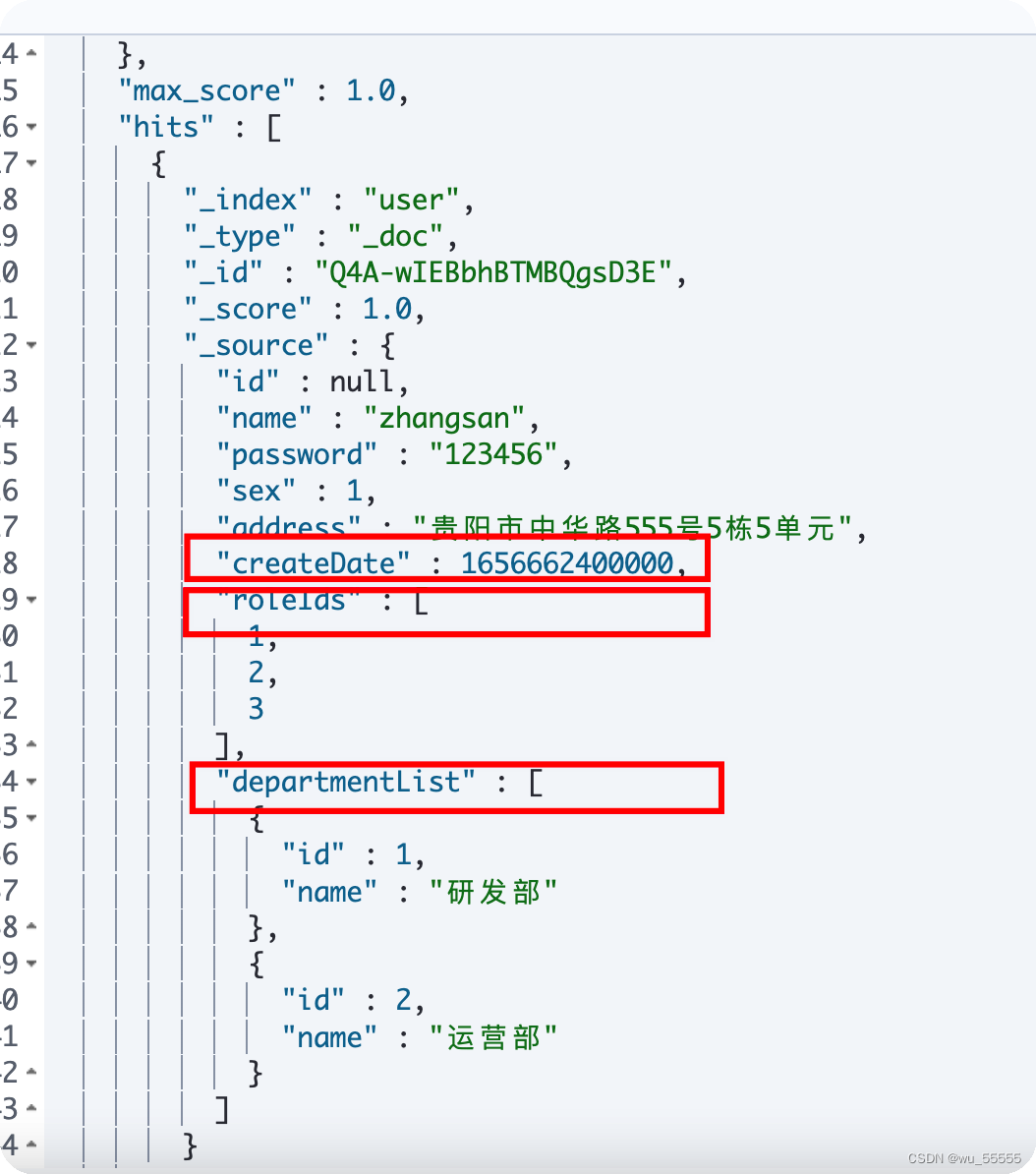
如上所示,实体类中的字段并没有对应上es索引中的字段。spring-data-es的字段映射是在EntityMapper类中实现的
我们可以看到EntityMapper接口下有两个实现类,默认采用的是第一个,这个实现类中并没有识别@Field注解,导致了没有对应上。

具体的源码分析,有兴趣的同学可以查看我另一篇博客:
Elastic实战:彻底解决spring-data-elasticsearch查询结果size大于0但显示为空问题
我们只需要在ElasticRestClientConfig配置类中声明EntityMapper为ElasticsearchEntityMapper即可
/**
* 指定EntityMapper为ElasticsearchEntityMapper
* 解决es mapper映射实体类问题
* @return
*/
@Bean
@Override
public EntityMapper entityMapper() {
ElasticsearchEntityMapper entityMapper = new ElasticsearchEntityMapper(elasticsearchMappingContext(), new DefaultConversionService());
entityMapper.setConversions(elasticsearchCustomConversions());
return entityMapper;
}
再次新增,数据正常
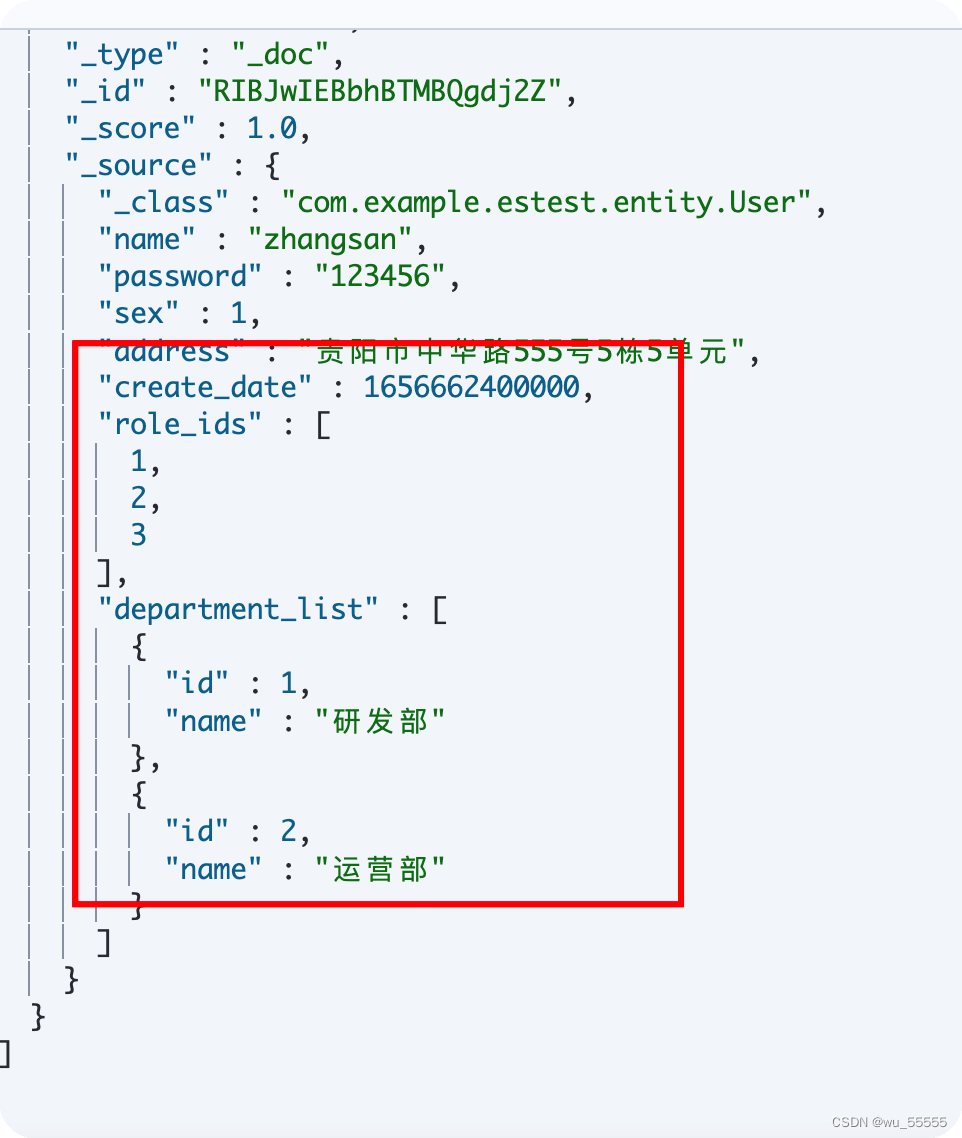
至此,我们的环境就搭建完成了,当然进阶使用还有更多的配置需要操作,我们将在后续进行讲解
关注公众号 Elasticsearch之家,回复‘springboot整合’,获取文中项目demo源码