
- Spring Data ElasticSearch介绍
- 1.1、SpringData介绍
- 1.2、Spring Data Elasticsearch介绍
- 引入依赖、yml配置、实体类
- 继承ElasticsearchRepository接口
- 使用ElasticsearchRestTemplate高级查询操作
- 精确查询(term)
- 全文查询(match)
- 通配符查询(wildcard)
- 模糊查询(fuzzy)
- 排序查询(sort)
- 分页查询(page)
- 方式一: from + size
- 方式二: scroll
- 方式三: search_after
- 范围查询(range)
- 布尔查询(bool)
- queryString查询
- 查询结果过滤 (fetchSource)
- 高亮查询(highlight)
- 聚合查询
官方文档 : https://www.elastic.co/guide/en/elasticsearch/reference/8.3/index.html
Spring Data ElasticSearch介绍 1.1、SpringData介绍Spring Data是一个用于简化数据库、非关系型数据库、索引库访问,并支持云服务的开源框架。其主要目标是使得对数据的访问变得方便快捷,并支持map-reduce框架和云计算数据服务。 Spring Data可以极大的简化JPA(Elasticsearch…)的写法,可以在几乎不用写实现的情况下,实现对数据的访问和操作。除了CRUD外,还包括如分页、排序等一些常用的功能。
1.2、Spring Data Elasticsearch介绍Spring Data ElasticSearch 基于 spring data API 简化 elasticSearch操作,将原始操作elasticSearch的客户端API 进行封装 。Spring Data为Elasticsearch项目提供集成搜索引擎。Spring Data Elasticsearch POJO的关键功能区域为中心的模型与Elastichsearch交互文档和轻松地编写一个存储索引库数据访问层。
SpringDataElasticSearch给我们提供了两个对象来操作文档:
- 继承ElasticsearchRepository接口:这种方式默认提供了对文档的基本增删改查功能,例如:findById()、save()、saveAll()、delete()、deleteById()等。
- ElasticsearchTemplate :ElasticsearchTemplate已经过时了,不建议使用了,推荐使用下面的
ElasticsearchRestTemplate - ElasticsearchRestTemplate:提供了对文档的复杂的操作,例如条件查询、聚合、排序等。
TIPS:spring-data-elasticsearch的底层其实也是否则了elasticsearch-rest-high-level-client的api。所以能使用RestHighLevelClient尽量使用它,为什么不推荐使用 Spring 家族封装的 spring-data-elasticsearch。主要原因是灵活性和更新速度,Spring 将 ElasticSearch 过度封装,让开发者很难跟 ES 的 DSL 查询语句进行关联。再者就是更新速度,ES 的更新速度是非常快,但是 spring-data-elasticsearch 更新速度比较缓慢。并且spring-data-elasticsearch在Elasticsearch6.x和7.x版本上的Java API差距很大,如果升级版本需要花点时间来了解。
引入依赖、yml配置、实体类
org.springframework.boot
spring-boot-starter
org.springframework.boot
spring-boot-starter-data-elasticsearch
org.springframework.boot
spring-boot-starter-test
test
application.yml配置
spring:
# 应用名称
application:
name: elasticsearch-spring-data
elasticsearch:
rest:
# 定位ES的位置
uris: http://127.0.0.1:9200
编写实体类对象,代码如下:
/**
* Goods实体对象
*/
@Data
@Accessors(chain = true) // 链式赋值(连续set方法)
@AllArgsConstructor // 全参构造
@NoArgsConstructor // 无参构造
// 指定当前类对象对应哪个ES中的索引
// 如果索引不存在
@Document(indexName = "goods")
public class Goods {
/**
* 商品编号
*/
@Id
@Field(type = FieldType.Long)
private Long id;
/**
* 商品标题
*/
@Field(type = FieldType.Text, analyzer = "ik_max_word", searchAnalyzer = "ik_smart")
private String title;
/**
* 商品价格
*/
@Field(type = FieldType.Double)
private BigDecimal price;
/**
* 商品库存
*/
@Field(type = FieldType.Integer)
private Integer stock;
/**
* 商品销售数量
*/
@Field(type = FieldType.Integer)
private Integer saleNum;
/**
* 商品分类
*/
@Field(type = FieldType.Keyword)
private String categoryName;
/**
* 商品品牌
*/
@Field(type = FieldType.Keyword)
private String brandName;
/**
* 上下架状态
*/
@Field(type = FieldType.Integer)
private Integer status;
/**
* 商品创建时间
*/
@JsonFormat(pattern = "yyyy-MM-dd HH:mm:ss.SSS")
//@Field(type = FieldType.Date, format = DateFormat.basic_date_time)
@Field(type = FieldType.Date, format = DateFormat.custom, pattern = "yyyy-MM-dd HH:mm:ss")
private Date createTime;
}
Spring Data ES通过注解来声明字段的映射属性,有下面的三个注解:
- @Document 作用在类,标记实体类为文档对象,一般有四个属性
- indexName:对应索引库名称
- shards:分片数量,默认1
- replicas:副本数量,默认1
- @Id 作用在成员变量,标记一个字段作为id主键
- @Field 作用在成员变量,标记为文档的字段,并指定字段映射属性:
- type:字段类型,取值是枚举:FieldType
- index:是否索引,布尔类型,默认是true
- store:是否存储,布尔类型,默认是false
- analyzer:分词器名称:ik_max_word
注意:如果我们没有手动去创建ES索引的话,那ES就会根据实体类上的注解来自动映射字段并且按照注解中的规则来定义字段的类型
继承ElasticsearchRepository接口Spring Data 的强大之处,就在于你不用写任何DAO处理,自动根据方法名或类的信息进行CRUD操作。只要你定义一个接口,然后继承Repository提供的一些子接口,就能具备各种基本的CRUD功能。这种方式默认提供了对文档的基本增删改查功能,例如:findById()、save()、saveAll()、delete()、deleteById()等,如果你用过mybatis-plus或者spring data jpa应该会非常的熟悉,下面看下简单的增删改操作示例:
编写 GoodsRepository并且继承ElasticsearchRepository
@Repository
public interface GoodsRepository extends ElasticsearchRepository {
}
从DB中导入一些测试数据
/**
* ElasticsearchTest测试
*/
@SpringBootTest
@RunWith(SpringRunner.class)
public class ElasticsearchRepositoryTest {
@Autowired
private GoodsMapper goodsMapper;
@Autowired
private GoodsRepository goodsRepository;
/**
* 导入测试数据,从mysql中导入测试数据至es
*/
@Test
public void importAllData() {
// 查询所有数据
List lists = goodsMapper.findAll();
// 保存所有数据只ES中
goodsRepository.saveAll(lists);
System.out.println("ok");
}
}
简单的CRUD操作
/**
* ElasticsearchTest简单的CRUD
*/
@SpringBootTest
@RunWith(SpringRunner.class)
public class ElasticsearchRepositoryTest {
@Autowired
private GoodsMapper goodsMapper;
@Autowired
private GoodsRepository goodsRepository;
/**
* 导入测试数据,从mysql中导入测试数据至es
*/
@Test
public void importAllData() {
// 查询所有数据
List lists = goodsMapper.findAll();
// 保存所有数据只ES中
goodsRepository.saveAll(lists);
System.out.println("ok");
}
/**
* 添加文档
*/
@Test
public void save() {
Goods goods = new Goods(1L, "Apple iPhone 13 ProMax 5G全网通手机", new BigDecimal(8999), 100, 1, "手机", "Apple", 0, new Date());
goodsRepository.save(goods);
}
/**
* 批量添加数据
*/
@Test
public void saveAll() {
List goodsList = new ArrayList();
goodsList.add(new Goods(2L, "title2", new BigDecimal(12), 1, 1, "category2", "brandName2", 0, new Date()));
goodsList.add(new Goods(3L, "title3", new BigDecimal(12), 1, 1, "category3", "brandName3", 0, new Date()));
goodsList.add(new Goods(4L, "title4", new BigDecimal(12), 1, 1, "category4", "brandName4", 0, new Date()));
goodsRepository.saveAll(goodsList);
}
/**
* 根据编号查询
*/
@Test
public void findById() {
Optional optional = goodsRepository.findById(536563L);
System.out.println(optional.orElse(null));
}
/**
* 查询所有
*/
@Test
public void findAll() {
Iterable list = goodsRepository.findAll();
for (Goods item : list) {
System.out.println(item);
}
}
/**
* 分页查询
*/
@Test
public void findAllByPage() {
// 数据太多了分页查询
PageRequest pageRequest = PageRequest.of(0, 10);
Iterable list = goodsRepository.findAll(pageRequest);
for (Goods item : list) {
System.out.println(item);
}
}
/**
* 排序查询
*/
@Test
public void findAllBySort() {
Iterable list = goodsRepository.findAll(Sort.by(Sort.Direction.DESC, "price"));
for (Goods item : list) {
System.out.println(item);
}
}
/**
* 根据ID批量查询
*/
@Test
public void findAllById() {
List asList = Arrays.asList(536563L, 562379L, 605616L, 635906L);
Iterable list = goodsRepository.findAllById(asList);
for (Goods item : list) {
System.out.println(item);
}
}
/**
* 统计数量
*/
@Test
public void count() {
System.out.println(goodsRepository.count());
}
/**
* 根据编号判断文档是否存在
*/
@Test
public void existsById() {
System.out.println(goodsRepository.existsById(536563L));
}
/**
* 删除文档
*/
@Test
public void delete() {
goodsRepository.findById(1L).ifPresent(goods -> goodsRepository.delete(goods));
}
/**
* 删除所有文档
*/
@Test
public void deleteAll() {
goodsRepository.deleteAll();
}
/**
* 根据编号批量删除文档
*/
@Test
public void deleteAllByIds() {
goodsRepository.deleteAll(goodsRepository.findAllById(Arrays.asList(1L, 2L, 3L)));
}
/**
* 根据编号删除文档
*/
@Test
public void deleteById() {
goodsRepository.deleteById(4L);
}
}
自定义方法:
Spring Data 的另一个强大功能,是根据方法名称自动实现功能。比如:你的方法名叫做:findByTitle,那么它就知道你是根据title查询,然后自动帮你完成,无需写实现类。当然,方法名称要符合一定的约定:
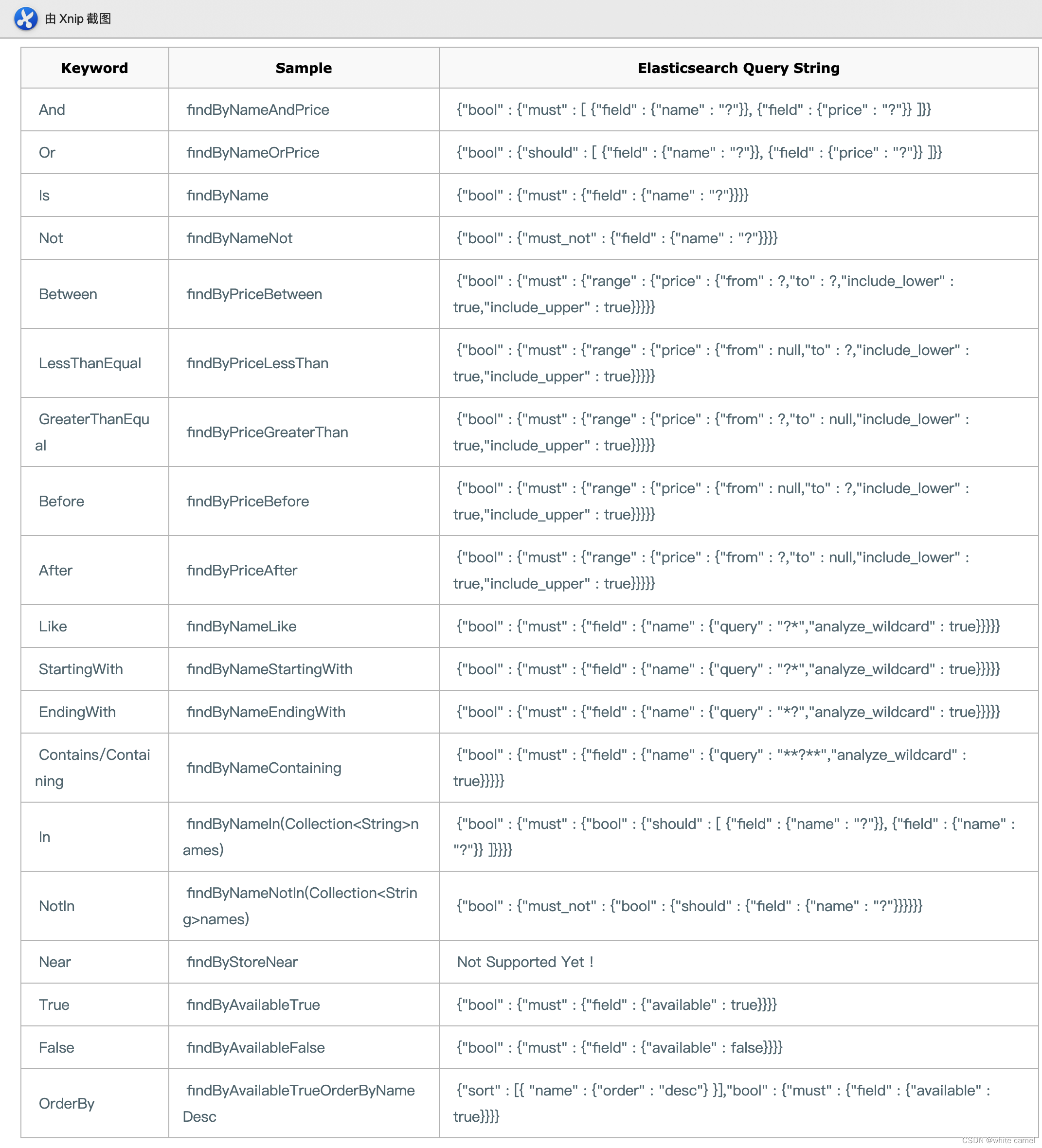 例如下面定义这样的两个方法:
例如下面定义这样的两个方法:
@Repository
public interface GoodsRepository extends ElasticsearchRepository {
/**
* @param title 标题
* @return
*/
List findByTitle(String title);
/**
* @param price1 价格1
* @param price2 价格2
* @return
*/
List findByPriceBetween(BigDecimal price1, BigDecimal price2);
}
/**
* 自定义方法:根据标题查询
*/
@Test
public void findByTitle() {
goodsRepository.findByTitle("华为").forEach(System.out::println);
}
/**
* 自定义方法:根据价格区间查询
*/
@Test
public void findByPriceBetween() {
goodsRepository.findByPriceBetween(new BigDecimal("3000"), new BigDecimal("5000")).forEach(System.out::println);
}
运行 根据价格区间查询 示例返回的结果如下: 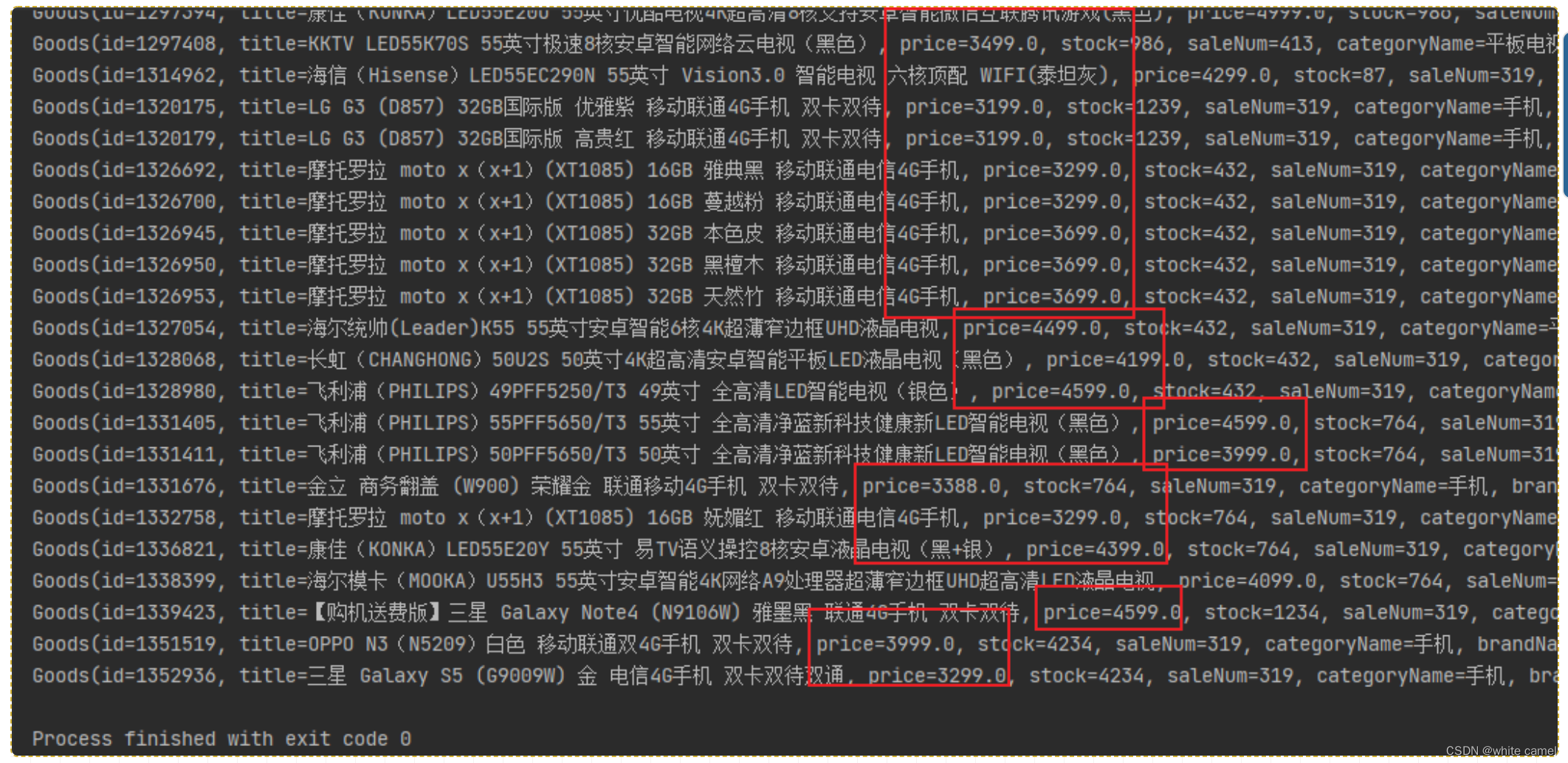
-
term查询:不会分析查询条件,只有当词条和查询字符串完全匹配时才匹配,也就是精确查找,比如数字,日期,布尔值或 not_analyzed 的字符串(未经分析的文本数据类型)
-
terms查询:terms 跟 term 有点类似,但 terms 允许指定多个匹配条件。 如果某个字段指定了多个值,那么文档需要一起去 做匹配:
/**
* 精确查询(termQuery)
*/
@Test
public void termQuery() {
//查询条件(词条查询:对应ES query里的term)
TermQueryBuilder termQueryBuilder = QueryBuilders.termQuery("categoryName", "手机");
//创建查询条件构建器SearchSourceBuilder(对应ES外面的大括号)
NativeSearchQuery nativeSearchQuery = new NativeSearchQueryBuilder().withQuery(termQueryBuilder).build();
//查询,获取查询结果
SearchHits searchHits = elasticsearchRestTemplate.search(nativeSearchQuery, Goods.class);
//获取总记录数
long totalHits = searchHits.getTotalHits();
System.out.println("totalHits = " + totalHits);
//获取值返回
searchHits.getSearchHits().stream().map(SearchHit::getContent).forEach(System.out::println);
}
/**
* terms:多个查询内容在一个字段中进行查询
*/
@Test
public void termsQuery() {
//查询条件(词条查询:对应ES query里的terms)
TermsQueryBuilder termsQueryBuilder = QueryBuilders.termsQuery("categoryName", "手机", "平板电视");
//创建查询条件构建器SearchSourceBuilder(对应ES外面的大括号)
NativeSearchQuery nativeSearchQuery = new NativeSearchQueryBuilder().withQuery(termsQueryBuilder).build();
//查询,获取查询结果
SearchHits searchHits = elasticsearchRestTemplate.search(nativeSearchQuery, Goods.class);
//获取总记录数
long totalHits = searchHits.getTotalHits();
System.out.println("totalHits = " + totalHits);
//获取值返回
searchHits.getSearchHits().stream().map(SearchHit::getContent).forEach(System.out::println);
}
全文查询会分析查询条件,先将查询条件进行分词,然后查询,求并集。
term和match的区别是:match是经过analyer的(进行分词),也就是说,文档首先被分析器给处理了。根据不同的分析器,分析的结果也稍显不同,然后再根据分词结果进行匹配。term则不经过分词,它是直接去倒排索引中查找了精确的值了。
match 查询语法汇总:
- match_all:查询全部。
- match:返回所有匹配的分词。
- match_phrase:短语查询,在match的基础上进一步查询词组,可以指定slop分词间隔。
- match_phrase_prefix:前缀查询,根据短语中最后一个词组做前缀匹配,可以应用于搜索提示,但注意和max_expanions搭配。其实默认是50…
- multi_match:多字段查询,使用相当的灵活,可以完成match_phrase和match_phrase_prefix的工作。
@Test
public void matchQuery() {
//查询条件(词条查询:对应ES query里的match)
MatchQueryBuilder matchQueryBuilder = QueryBuilders.matchQuery("title", "Apple IPhone 白色").analyzer("ik_smart").operator(Operator.AND);
//创建查询条件构建器SearchSourceBuilder(对应ES外面的大括号)
NativeSearchQuery nativeSearchQuery = new NativeSearchQueryBuilder().withQuery(matchQueryBuilder).build();
//查询,获取查询结果
SearchHits search = elasticsearchRestTemplate.search(nativeSearchQuery, Goods.class);
//获取总记录数
long totalHits = search.getTotalHits();
System.out.println("totalHits = " + totalHits);
//获取值返回
search.getSearchHits().stream().map(SearchHit::getContent).forEach(System.out::println);
}
/**
* match_all:查询全部。
* 默认查询10条
*/
@Test
public void matchAllQuery() {
//查询条件(词条查询:对应ES query里的match)
MatchAllQueryBuilder matchAllQueryBuilder = QueryBuilders.matchAllQuery();
//创建查询条件构建器SearchSourceBuilder(对应ES外面的大括号)
NativeSearchQuery nativeSearchQuery = new NativeSearchQueryBuilder().withQuery(matchAllQueryBuilder).build();
//查询,获取查询结果
SearchHits search = elasticsearchRestTemplate.search(nativeSearchQuery, Goods.class);
//获取总记录数
long totalHits = search.getTotalHits();
System.out.println("totalHits = " + totalHits);
//获取值返回
search.getSearchHits().stream().map(SearchHit::getContent).forEach(System.out::println);
}
/**
* match_phrase:短语查询,在match的基础上进一步查询词组,可以指定slop分词间隔。
* 默认查询10条
*/
@Test
public void matchPhraseQuery() {
//查询条件(词条查询:对应ES query里的match_all)
MatchPhraseQueryBuilder matchPhraseQueryBuilder = QueryBuilders.matchPhraseQuery("title", "华为");
//创建查询条件构建器SearchSourceBuilder(对应ES外面的大括号)
NativeSearchQuery nativeSearchQuery = new NativeSearchQueryBuilder().withQuery(matchPhraseQueryBuilder).build();
//查询,获取查询结果
SearchHits search = elasticsearchRestTemplate.search(nativeSearchQuery, Goods.class);
//获取总记录数
long totalHits = search.getTotalHits();
System.out.println("totalHits = " + totalHits);
//获取值返回
search.getSearchHits().stream().map(SearchHit::getContent).forEach(System.out::println);
}
/**
* multi_match:多字段查询,使用相当的灵活,可以完成match_phrase和match_phrase_prefix的工作。
*/
@Test
public void multiMatchQuery() {
//查询条件(词条查询:对应ES query里的multi_match)
MultiMatchQueryBuilder multiMatchQueryBuilder = QueryBuilders.multiMatchQuery("华为和Apple", "title", "categoryName").analyzer("ik_smart");
//创建查询条件构建器SearchSourceBuilder(对应ES外面的大括号)
NativeSearchQuery nativeSearchQuery = new NativeSearchQueryBuilder().withQuery(multiMatchQueryBuilder).build();
//查询,获取查询结果
SearchHits search = elasticsearchRestTemplate.search(nativeSearchQuery, Goods.class);
//获取总记录数
long totalHits = search.getTotalHits();
System.out.println("totalHits = " + totalHits);
//获取值返回
search.getSearchHits().stream().map(SearchHit::getContent).forEach(System.out::println);
}
wildcard查询:会对查询条件进行分词。还可以使用通配符 ?(任意单个字符) 和 * (0个或多个字符)
/**
* 通配符查询
*
* *:表示多个字符(0个或多个字符)
* ?:表示单个字符
*/
@Test
public void wildcardQuery() {
//查询条件
WildcardQueryBuilder wildcardQueryBuilder = QueryBuilders.wildcardQuery("华为*", "title");
//创建查询条件构建器SearchSourceBuilder(对应ES外面的大括号)
NativeSearchQuery nativeSearchQuery = new NativeSearchQueryBuilder().withQuery(wildcardQueryBuilder).build();
//查询,获取查询结果
SearchHits search = elasticsearchRestTemplate.search(nativeSearchQuery, Goods.class);
//获取总记录数
long totalHits = search.getTotalHits();
System.out.println("totalHits = " + totalHits);
//获取值返回
search.getSearchHits().stream().map(SearchHit::getContent).forEach(System.out::println);
}
fuzzy 模糊查询 最大模糊错误 必须在0-2之间 搜索关键词长度为 2 不允许存在模糊 0 搜索关键词长度为3-5 允许一次模糊 0 1 搜索关键词长度大于5 允许最大2模糊
/**
* 模糊查询所有以 “三” 结尾的商品信息
*/
@Test
public void fuzzyQuery() {
//查询条件
FuzzyQueryBuilder fuzzyQueryBuilder = QueryBuilders.fuzzyQuery("title", "三").fuzziness(Fuzziness.AUTO);
//创建查询条件构建器SearchSourceBuilder(对应ES外面的大括号)
NativeSearchQuery nativeSearchQuery = new NativeSearchQueryBuilder().withQuery(fuzzyQueryBuilder).build();
//查询,获取查询结果
SearchHits search = elasticsearchRestTemplate.search(nativeSearchQuery, Goods.class);
//获取总记录数
long totalHits = search.getTotalHits();
System.out.println("totalHits = " + totalHits);
//获取值返回
search.getSearchHits().stream().map(SearchHit::getContent).forEach(System.out::println);
}
注意:需要分词的字段不可以直接排序,比如:text类型,如果想要对这类字段进行排序,需要特别设置:对字段索引两次,一次索引分词(用于搜索)一次索引不分词(用于排序),es默认生成的text类型字段就是通过这样的方法实现可排序的。
/**
* 排序查询(sort)
* 匹配查询符合条件的所有数据,并设置分页
*/
@Test
public void sort() {
//查询条件(词条查询:对应ES query里的match)
MatchAllQueryBuilder matchAllQueryBuilder = QueryBuilders.matchAllQuery();
FieldSortBuilder fieldSortBuilder = SortBuilders.fieldSort("price").order(SortOrder.DESC);
//创建查询条件构建器SearchSourceBuilder(对应ES外面的大括号)
NativeSearchQuery nativeSearchQuery = new NativeSearchQueryBuilder()
.withQuery(matchAllQueryBuilder)
.withSort(fieldSortBuilder)
.build();
//查询,获取查询结果
SearchHits search = elasticsearchRestTemplate.search(nativeSearchQuery, Goods.class);
//获取总记录数
System.out.println("totalHits = " + search.getTotalHits());
//获取值返回
search.getSearchHits().stream().map(SearchHit::getContent).forEach(System.out::println);
}
Elasticsearchde 的分页查询和 SQL 使用 LIMIT 关键字返回只有一页的结果一样,Elasticsearch 接受 from 和 size 参数:
- size: 结果数,默认10
- from: 跳过开始的结果数,即从哪一行开始获取数据,默认0
这种方式分页查询如果需要深度分页,那么这种方式性能不太好。
深度分页: 建议使用 scroll滚动查询 和 search_after滚动查询
方式一: from + size实现原理
- es是通过协调节点从每个shard(分片)中都获取from+size条数据返回给协调节点后,由协调节点汇总排序,然后查找[from , frome+size] 之间的数据,并返回给前端。
存在的问题
- 该搜索请求占用的堆内存和时间与from+size大小成正比,值越大,性能越差、效率越低,一般用于浅分页中。 查询的值超过默认(10000)时会报错 :
from+size > max_result_window时,会报错。
Kibana中测试示例
GET /book/_search
{
"from" : 100 , "size" : 10,
"query" : {
"match" : { "title" : "区块链" }
}
}
详细代码
/**
* 分页查询(page)
*/
@Test
public void pageQuery() {
//查询条件
MatchAllQueryBuilder matchAllQueryBuilder = QueryBuilders.matchAllQuery();
FieldSortBuilder fieldSortBuilder = SortBuilders.fieldSort("price").order(SortOrder.DESC);
// 分页数据
PageRequest pageRequest = PageRequest.of(0, 10);
//创建查询条件构建器SearchSourceBuilder(对应ES外面的大括号)
NativeSearchQuery nativeSearchQuery = new NativeSearchQueryBuilder()
.withQuery(matchAllQueryBuilder)
.withSort(fieldSortBuilder)
.withPageable(pageRequest)
.build();
//查询,获取查询结果
SearchHits search = elasticsearchRestTemplate.search(nativeSearchQuery, Goods.class);
//获取总记录数,当前页,每页大小
System.out.println("totalHits = " + search.getTotalHits());
System.out.println("pageNumber = " + pageRequest.getPageNumber());
System.out.println("pageSize = " + pageRequest.getPageSize());
//获取值返回
search.getSearchHits().stream().map(SearchHit::getContent).forEach(System.out::println);
}
实现原理
- scroll API可用于从单个搜索请求中检索大量结果(甚至所有结果),其方式与在传统数据库上使用光标的方式大致相同。
- 第一次查询时,会生产当时查询的快照,后续的查询只要携带上次返回的
scroll_id即可(类似数据库游标) 。
特点
- 可以深查询(甚至全部数据),性能、效率优于from+size方式。
- 快照查询,在scroll查询期间 ,外部对索引内的数据进行增删改查等操作不会影响到这个快照的结果。
Kibana中测试示例
第一次查询 ,并设置上下文scroll_id存活时间为1分钟。
POST book/_search?scroll=1m
{
"size": 10,
"query": {
"match" : {
"name": "明朝的那些事"
}
}
}
响应
{
"_scroll_id":"DXF1ZXJ5QW5kRmV0Y2gBAAAAAAD1K-0WdzM3OF9WRVFUcXk3bFNDcjZKZ1pZdw==",
"took":22,
"timed_out":false,
"_shards":{
"total":1,
"successful":1,
"skipped":0,
"failed":0
},
"hits":{
"total":1302017,
"max_score":2.5815613,
"hits":Array[10]
}
}
后续查询,使用前一个scroll_id即可:
POST _search/scroll
{
"scroll":"1m",
"scroll_id":"DXF1ZXJ5QW5kRmV0Y2gBAAAAAAD1K-0WdzM3OF9WRVFUcXk3bFNDcjZKZ1pZdw=="
}
详细代码
/**
* 滚动查询所有数据
*/
@Test
public void scrollQuery1() {
// 设置每页数据量
int pageSize = 10;
MatchAllQueryBuilder queryBuilder = QueryBuilders.matchAllQuery();//条件
FieldSortBuilder sortBuilder = new FieldSortBuilder("id").order(SortOrder.ASC);//排序
NativeSearchQuery nativeSearchQuery = new NativeSearchQueryBuilder().withQuery(queryBuilder).withSort(sortBuilder).build();
nativeSearchQuery.setMaxResults(pageSize);// 设置每页数据量
long scrollTimeInMillis = 60 * 1000;//设置缓存内数据的保留时间,不要把缓存时时间设置太长,否则占用内存。
// 缓存第一页符合搜索条件的数据
SearchScrollHits searchScrollHits = elasticsearchRestTemplate.searchScrollStart(scrollTimeInMillis, nativeSearchQuery, Goods.class, IndexCoordinates.of("goods"));
String scrollId = searchScrollHits.getScrollId();
int scrollTime = 1;
while (searchScrollHits.hasSearchHits()) {// 判断searchScrollHits中是否有命中数据,如果为空,则表示已将符合查询条件的数据全部遍历完毕
System.out.println("第" + scrollTime + "页数据,数据总数:" + searchScrollHits.getSearchHits().size());
for (SearchHit searchHit : searchScrollHits.getSearchHits()) {// 从缓存中读取数据
Goods goods = searchHit.getContent();
System.out.println(goods);
}
// 根据上次搜索结果scroll_id进入下一页数据搜索
searchScrollHits = elasticsearchRestTemplate.searchScrollContinue(scrollId, scrollTimeInMillis, Goods.class, IndexCoordinates.of("goods"));//该方法执行后将重新刷新快照保留时间
scrollId = searchScrollHits.getScrollId();
scrollTime = scrollTime + 1;
}
List scrollIds = new ArrayList();
scrollIds.add(scrollId);
elasticsearchRestTemplate.searchScrollClear(scrollIds);// 清除 scroll
}
/**
* 根据查询条件滚动查询
* 可以用来解决深度分页查询问题
*/
@Test
public void scrollQuery2() {
// 假设用户想获取第70页数据,其中每页10条
int pageNo = 70;
int pageSize = 10;
// 构建查询条件
MatchAllQueryBuilder queryBuilder = QueryBuilders.matchAllQuery();
FieldSortBuilder sortBuilder = new FieldSortBuilder("id").order(SortOrder.ASC);//排序
NativeSearchQuery nativeSearchQuery = new NativeSearchQueryBuilder()
.withQuery(queryBuilder)
.withSort(sortBuilder)
.build();
nativeSearchQuery.setMaxResults(pageSize);// 设置每页数据量
long scrollTimeInMillis = 60 * 1000;//设置缓存内数据的保留时间
//1、缓存第一页符合搜索条件的数据
SearchScrollHits searchScrollHits = elasticsearchRestTemplate.searchScrollStart(scrollTimeInMillis, nativeSearchQuery, Goods.class, IndexCoordinates.of("goods"));
String scrollId = searchScrollHits.getScrollId();
int scrollTime = 1;
// 判断searchScrollHits中是否有命中数据,如果为空,则表示已将符合查询条件的数据全部遍历完毕
while (searchScrollHits.hasSearchHits() && scrollTime 。gte:大于等于,相当于关系型数据库中的 >=。 lt:小于,相当于关系型数据库中的 {
//获得结果实体
Goods goods = searchHit.getContent();
//所有高亮结果
Map highlightFields = searchHit.getHighlightFields();
//遍历高亮结果
for (Map.Entry stringListEntry : highlightFields.entrySet()) {
String key = stringListEntry.getKey();
//获取实体反射类
Class aClass = goods.getClass();
try {
//获取该实体属性
Field declaredField = aClass.getDeclaredField(key);
//权限为私的 解除!
declaredField.setAccessible(true);
//替换,把高亮字段替换到这个实体对应的属性值上
declaredField.set(goods, stringListEntry.getValue().get(0));
} catch (NoSuchFieldException | IllegalAccessException e) {
e.printStackTrace();
}
}
return goods;
}).forEach(System.out::println);
}
我们平时在使用Elasticsearch时,更多会用到聚合操作,它类似SQL中的group by操作。ES的聚合查询一定是先查出结果,然后对结果使用聚合函数做处理,常用的操作有:avg:求平均、max:最大值、min:最小值、sum:求和等。
在ES中聚合分为指标聚合和分桶聚合:
- Metric 指标聚合:指标聚合对一个数据集求最大、最小、和、平均值等
- Bucket 分桶聚合:除了有上面的聚合函数外,还可以对查询出的数据进行分组group by,再在组上进行游标聚合。
Metric 指标聚合分析
/**
* 案例:分别获取最贵的商品和获取最便宜的商品
*/
@Test
public void aggMetric() {
NativeSearchQueryBuilder queryBuilder = new NativeSearchQueryBuilder();
// 聚合条件
queryBuilder.addAggregation(AggregationBuilders.max("maxPrice").field("price"));
queryBuilder.addAggregation(AggregationBuilders.min("minPrice").field("price"));
queryBuilder.withSourceFilter(new FetchSourceFilterBuilder().build());
//查询,获取查询结果
SearchHits searchHits = elasticsearchRestTemplate.search(queryBuilder.build(), Goods.class, IndexCoordinates.of("goods"));
//获取聚合结果
Aggregations aggregations = searchHits.getAggregations();
assert aggregations != null;
//打印聚合结果
ParsedMax max = aggregations.get("maxPrice");
System.out.println("最贵的价格:" + max.getValue());
ParsedMin min = aggregations.get("minPrice");
System.out.println("最便宜的价格:" + min.getValue());
}
Bucket 分桶聚合分析
/**
* 根据商品分类聚合查询
*/
@Test
public void aggBucket() {
NativeSearchQueryBuilder queryBuilder = new NativeSearchQueryBuilder();
// 聚合条件
queryBuilder.addAggregation(AggregationBuilders.terms("aggCategoryName").field("categoryName").size(10));
queryBuilder.withSourceFilter(new FetchSourceFilterBuilder().build());
//查询,获取查询结果
SearchHits searchHits = elasticsearchRestTemplate.search(queryBuilder.build(), Goods.class, IndexCoordinates.of("goods"));
//获取聚合结果
Aggregations aggregations = searchHits.getAggregations();
assert aggregations != null;
ParsedStringTerms aggCategoryName = aggregations.get("aggCategoryName");
//打印聚合结果
System.out.println(aggCategoryName.getBuckets());
for (Terms.Bucket bucket : aggCategoryName.getBuckets()) {
System.out.println(bucket.getKeyAsString() + "====" + bucket.getDocCount());
}
}
/**
* 根据价格区间分组查询
*/
@Test
public void aggRange() {
NativeSearchQueryBuilder queryBuilder = new NativeSearchQueryBuilder();
queryBuilder.addAggregation(AggregationBuilders.range("priceRange").field("price").addUnboundedTo(1000).addRange(1000, 3000).addUnboundedFrom(3000));
queryBuilder.withSourceFilter(new FetchSourceFilterBuilder().build());
SearchHits searchHits = elasticsearchRestTemplate.search(queryBuilder.build(), Goods.class, IndexCoordinates.of("goods"));
// 获取聚合信息
Aggregations aggregations = searchHits.getAggregations();
assert aggregations != null;
ParsedRange priceRange = aggregations.get("priceRange");
//获取总记录数
System.out.println("totalHits = " + searchHits.getTotalHits());
//获取值返回
for (Range.Bucket bucket : priceRange.getBuckets()) {
System.out.println(bucket.getKeyAsString() + "====" + bucket.getDocCount());
}
}
/**
* 根据日期分组查询出商品创建日期在"2017-09" - "2017-10" 之间的数据
*/
@Test
public void aggDateRange() {
NativeSearchQueryBuilder queryBuilder = new NativeSearchQueryBuilder();
// range查询包左不包右,即:[1,10)
queryBuilder.addAggregation(AggregationBuilders.dateRange("dateRange").field("createTime").format("yyy-MM").addRange("2017-09", "2017-10"));
queryBuilder.withSourceFilter(new FetchSourceFilterBuilder().build());
SearchHits searchHits = elasticsearchRestTemplate.search(queryBuilder.build(), Goods.class, IndexCoordinates.of("goods"));
// 获取聚合信息
Aggregations aggregations = searchHits.getAggregations();
assert aggregations != null;
ParsedDateRange priceRange = aggregations.get("dateRange");
//获取总记录数
System.out.println("totalHits = " + searchHits.getTotalHits());
//获取值返回
for (Range.Bucket bucket : priceRange.getBuckets()) {
System.out.println(bucket.getKeyAsString() + "====" + bucket.getDocCount());
}
}
/**
* 根据品牌聚合获取出每个品牌的平均价格
*/
@Test
public void subAgg() {
NativeSearchQueryBuilder queryBuilder = new NativeSearchQueryBuilder();
queryBuilder.addAggregation(AggregationBuilders.terms("brandNameAgg").field("brandName")
.subAggregation(AggregationBuilders.avg("avgPrice").field("price")));
SearchHits searchHits = elasticsearchRestTemplate.search(queryBuilder.build(), Goods.class, IndexCoordinates.of("goods"));
// 获取聚合信息
Aggregations aggregations = searchHits.getAggregations();
assert aggregations != null;
ParsedStringTerms brandeNameAgg = aggregations.get("brandNameAgg");
//获取总记录数
System.out.println("totalHits = " + searchHits.getTotalHits());
//获取值返回
for (Terms.Bucket bucket : brandeNameAgg.getBuckets()) {
// 获取聚合后的品牌名称
String brandName = bucket.getKeyAsString();
// 获取聚合命中的文档数量
long docCount = bucket.getDocCount();
// 获取聚合后的品牌的平均价格,注意返回值不是Aggregation对象,而是指定的ParsedAvg对象
ParsedAvg avgPrice = bucket.getAggregations().get("avgPrice");
System.out.println(brandName + "======" + avgPrice.getValue() + "======" + docCount);
}
}
综合聚合查询
/**
* 根据商品分类聚合,获取每个商品类的平均价格,并且在商品分类聚合之上子聚合每个品牌的平均价格
*/
@Test
public void subSubAgg() {
NativeSearchQueryBuilder queryBuilder = new NativeSearchQueryBuilder();
// 注意这里聚合写的位置不要写错,很容易搞混,错一个括号就不对了
queryBuilder.addAggregation(
AggregationBuilders.terms("categoryNameAgg").field("categoryName")
.subAggregation(AggregationBuilders.avg("categoryNameAvgPrice").field("price"))
.subAggregation(AggregationBuilders.terms("brandNameAgg").field("brandName")
.subAggregation(AggregationBuilders.avg("brandNameAvgPrice").field("price"))));
SearchHits searchHits = elasticsearchRestTemplate.search(queryBuilder.build(), Goods.class, IndexCoordinates.of("goods"));
// 获取聚合信息
Aggregations aggregations = searchHits.getAggregations();
assert aggregations != null;
ParsedStringTerms categoryNameAgg = aggregations.get("categoryNameAgg");
//获取总记录数
System.out.println("totalHits = " + searchHits.getTotalHits());
//获取值返回
for (Terms.Bucket bucket : categoryNameAgg.getBuckets()) {
// 获取聚合后的分类名称
String categoryName = bucket.getKeyAsString();
// 获取聚合命中的文档数量
long docCount = bucket.getDocCount();
// 获取聚合后的分类的平均价格,注意返回值不是Aggregation对象,而是指定的ParsedAvg对象
ParsedAvg avgPrice = bucket.getAggregations().get("categoryNameAvgPrice");
System.out.println(categoryName + "======" + avgPrice.getValue() + "======" + docCount);
ParsedStringTerms brandNameAgg = bucket.getAggregations().get("brandNameAgg");
for (Terms.Bucket brandeNameAggBucket : brandNameAgg.getBuckets()) {
// 获取聚合后的品牌名称
String brandName = brandeNameAggBucket.getKeyAsString();
// 获取聚合后的品牌的平均价格,注意返回值不是Aggregation对象,而是指定的ParsedAvg对象
ParsedAvg brandNameAvgPrice = brandeNameAggBucket.getAggregations().get("brandNameAvgPrice");
System.out.println(" " + brandName + "======" + brandNameAvgPrice.getValue());
}
}
}


