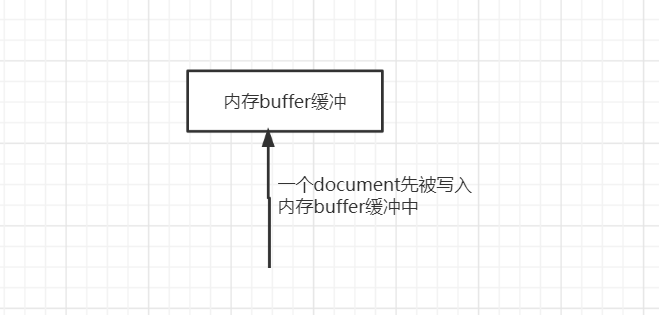
(1)数据写入buffer
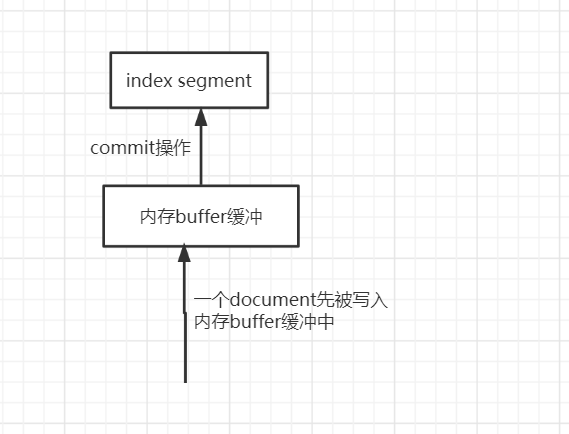
(2)达到一定条件、或者每隔一段时间会执行commit point (3)buffer中的数据写入新的index segment
在es底层,用的是lucene,lucene底层的index是分为多个segment的,每个segment都会存放部分数据。
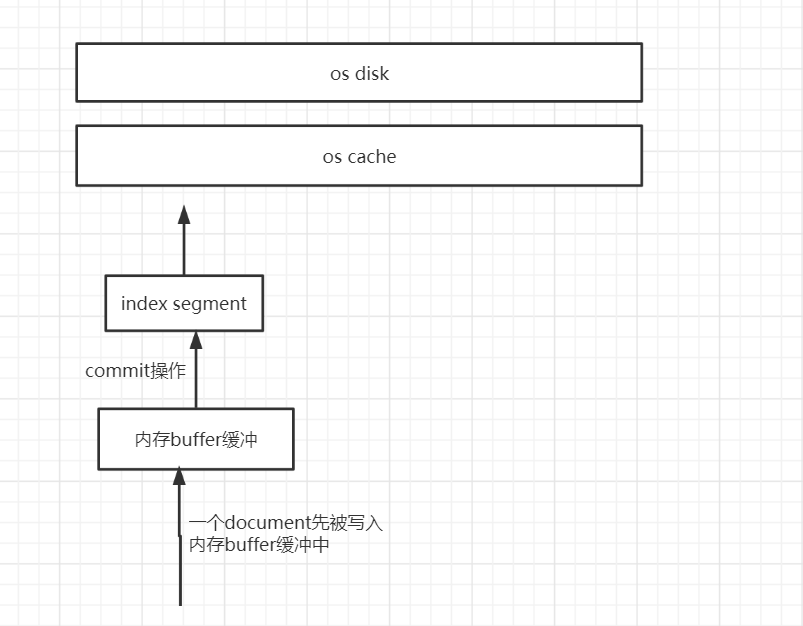
(4)等待在os cache中的index segment被fsync强制刷到磁盘上
首先会写入os cache缓存中,然后fsync强制刷新cache到disk
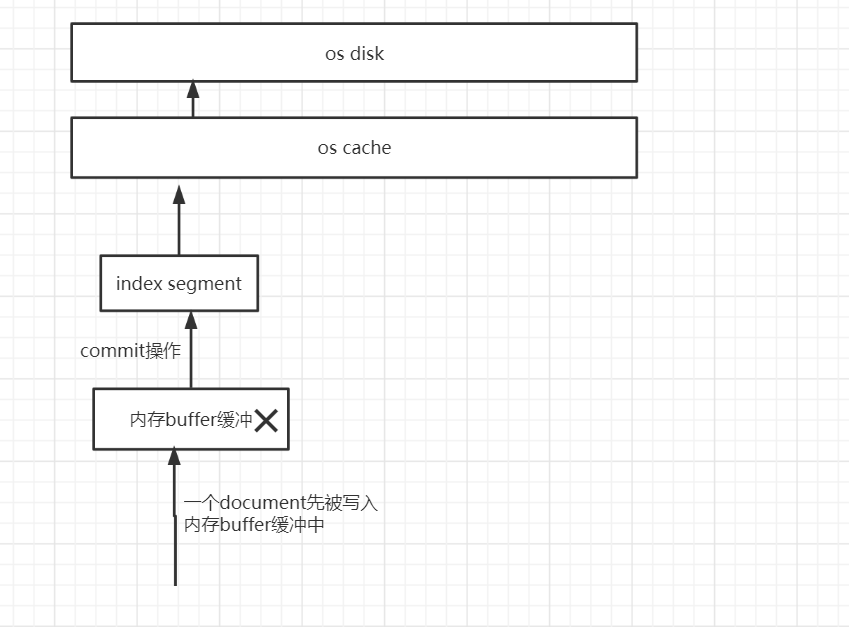
(5)新的index sgement被打开,供search使用
当index sgement被fsync强制刷到磁盘上以后,就会被打开,供search使用,而且执行fsync以后,还会降buffer清空
(6)buffer被清空
当index segment被打开以后,search操作就可以到index segment中去搜索了

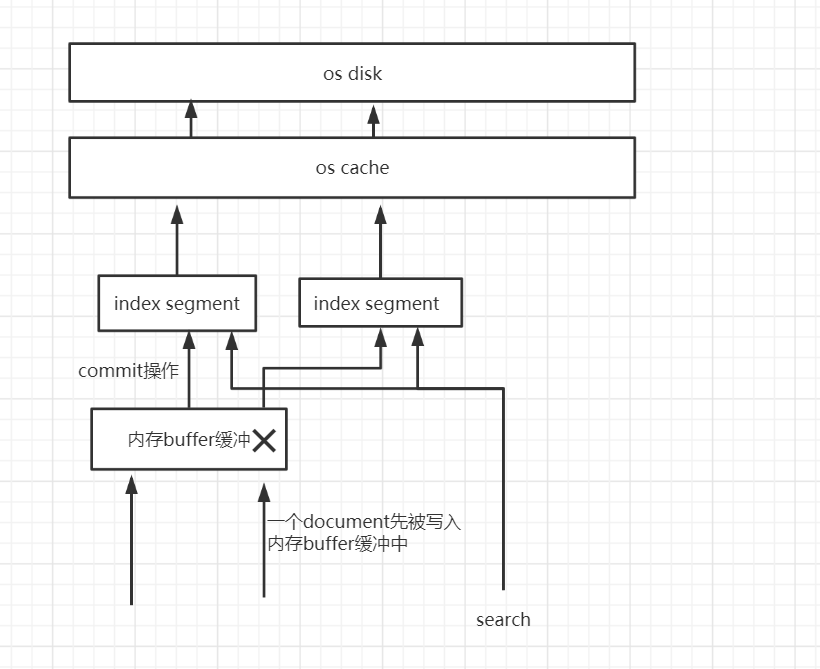
当内存buffer缓冲再次被写满时,会写到一个新的index segment中,再次执行之前的操作,直到执行fsync以后,将buffer清空
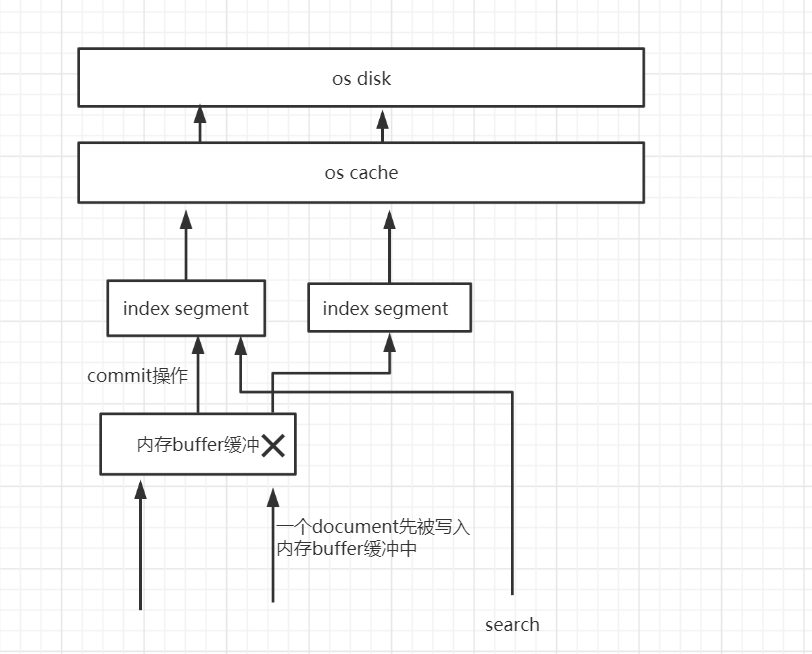
当新的index segment被打开以后,search操作就可以到新index segment中去搜索了
如果是删除操作,每次commit point时,会有一个.del文件,标记了哪些segment中的哪些document被标记为deleted了
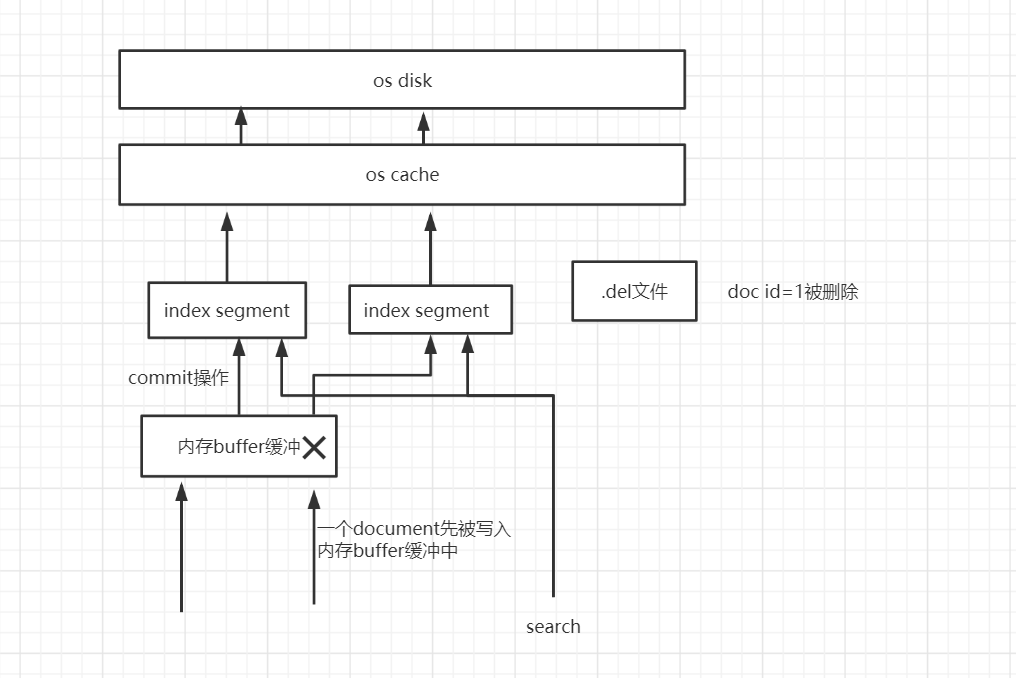
如果搜索请求过来,在index segment中,匹配到了id=1的doc,此时会发现再.del文件中已经被标识为deleted了,这种数据就会被过滤掉,不会作为搜索结果返回,
更新document的过程如果是更新操作,实际上是将现有的doc标记为deleted,然后将新的document写入新的index segment中,下次search时可能会匹配到一个document的多个版本,但是之前的版本已经被标记为deleted了,所以只会返回最新版本的doc
一个document的多个版本,但是之前的版本已经被标记为deleted了,所以只会返回最新版本的doc


