

![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-FP1BrsZN-1632495287987)(C:\Users\LENOVO-LX\AppData\Roaming\Typora\typora-user-images\image-20210902084552072.png)]](https://img-blog.csdnimg.cn/2fc03919d35c4450aa039e4e12e8bd3a.png?x-oss-process=image/watermark,type_ZHJvaWRzYW5zZmFsbGJhY2s,shadow_50,text_Q1NETiBA5aSn5Yir5bGx56CB5bCG,size_20,color_FFFFFF,t_70,g_se,x_16)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-gdST05tK-1632495287998)(C:\Users\LENOVO-LX\AppData\Roaming\Typora\typora-user-images\image-20210902084641756.png)]](https://img-blog.csdnimg.cn/b1b094ba93914693b541d54dd3d0f3ba.png?x-oss-process=image/watermark,type_ZHJvaWRzYW5zZmFsbGJhY2s,shadow_50,text_Q1NETiBA5aSn5Yir5bGx56CB5bCG,size_20,color_FFFFFF,t_70,g_se,x_16)
List (对付顺序的好帮⼿): 是一个有序容器,存储的元素是有序的、可重复的,允许多个null元素
常用的实现类有 ArrayList、LinkedList 和 Vector。ArrayList 最为流行,它提供了使用索引的随意访问,向ArrayList中插入与删除元素的速度慢。 当ArrayList中的元素个数超过数组大小时,会进行1.5倍扩容;而 LinkedList 则对于经常需要从 List 中添加或删除元素的场合更为合适。
Set (注重独⼀⽆⼆的性质): 无序容器,存储的元素是⽆序的、不可重复的, 只允许一个 null 元素
Set 接口最流行的几个实现类是 HashSet、LinkedHashSet 以及 TreeSet。最流行的是HashSet,HashSet按照哈希算法来存取集合中的对象,存取速度比较快。当HashSet中的元素个数超过数组大小(默认值为0.75)时,就会进行近似两倍扩容;TreeSet 实现了 SortedSet 接口,因此 TreeSet 是一个根据其 compare() 和 compareTo() 的定义进行集合中对象的排序
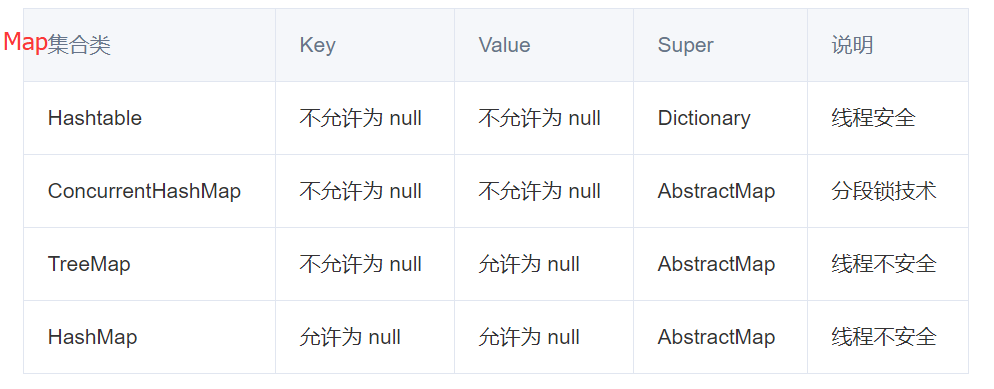
Map (⽤ Key 来搜索的专家): 是一种把键对象和值对象映射的集合,使⽤键值对(kye-value)存储,Key 是⽆序的、不可重复的,value 是⽆序的、可重复的,每个键最多映射到⼀个值。
1.Map不是collection的子接口或者实现类。Map是一个接口。
2.TreeMap 也通过 Comparator 或者 Comparable 维护了一个排序顺序。
3.Map 里你可以拥有随意个 null 值但最多只能有一个 null 键。
4.Map 接口最流行的几个实现类是 HashMap、LinkedHashMap、Hashtable 和 TreeMap。(HashMap、TreeMap最常用)
面试题:什么场景下使用list,set,map呢?
-
如果你经常对容器中的元素进行访问,那么 List 是你的正确的选择。如果你已经知道索引了的话,那么 List 的实现类比如 ArrayList 可以提供更快速的访问,如果经常添加删除元素的,那么肯定要选择LinkedList。
-
如果你想容器中的元素能够按照它们插入的次序进行有序存储,那么还是 List,因为 List 是一个有序容器,它按照插入顺序进行存储。
-
如果你想保证插入元素的唯一性,也就是你不想有重复值的出现,那么可以选择一个 Set 的实现类,比如 HashSet、LinkedHashSet 或者 TreeSet。所有 Set 的实现类都遵循了统一约束比如唯一性,而且还提供了额外的特性比如 TreeSet 还是一个 SortedSet,所有存储于 TreeSet 中的元素可以使用 Java 里的 Comparator 或者 Comparable 进行排序。LinkedHashSet 也按照元素的插入顺序对它们进行存储。
-
如果你以键和值的形式进行数据存储那么 Map 是你正确的选择。你可以根据你的后续需要从 Hashtable、HashMap、TreeMap 中进行选择。
-
是否保证线程安全: ArrayList 和 LinkedList 都是不同步的,也就是不保证线程安全;
-
底层数据结构: Arraylist 底层使⽤的是 Object 数组; LinkedList 底层使⽤的是 双向链表 数据结构(JDK1.6 之前为双向循环链表,JDK1.7 为双向链表)
-
插⼊和删除是否受元素位置的影响: ① ArrayList采⽤数组存储,数组天然⽀持随机访
问,时间复杂度为 O(1),所以插⼊和删除元素的时间复杂度受元素位置的影响。②LinkedList 采⽤链表存储,链表不支持随机访问,需要遍历到特定位置才能访问特定位置的元素,时间复杂度为 O(n),所以插⼊,删除元素时间复杂度不受元素位置的影响,近似 O(1)
-
是否⽀持快速随机访问: LinkedList 不⽀持⾼效的随机元素访问,⽽ ArrayList ⽀持。
-
内存空间占⽤: ArrayList 的空 间浪费主要体现在在 list 列表的结尾会预留⼀定的容量空间,LinkedList 比 ArrayList 更占内存,因为 LinkedList 为每一个节点存储了两个引用节点,一个指向前一个元素,一个指向下一个元素。
-
扩容问题:ArrayList 使用数组实现,无参构造函数默认初始化长度为 10,数组扩容是会将原数组中的元素重新拷贝到新数组中,长度为原来的 1.5 倍(扩容代价高);LinkedList 不存在扩容问题,新增元素放到集合尾部,修改相应的指针节点即可。
线程安全:Vector 使用了 Synchronized 来实现线程同步,是线程安全的,而 ArrayList 是非线程安全的。(因为线程安全的问题, 在不需要保证线程安全时,ArrayList⽐ Vector 效率⾼) 性能:ArrayList 在性能方面要优于 Vector。 扩容:ArrayList 和 Vector 都会根据实际的需要动态的调整容量,只不过在 Vector 扩容每次增加 1 倍,而 ArrayList 增加 1.5倍。
说说ArrayList扩容机制打开idea中ArrayList类的源码,ArrayList中有两个属性,size:表示ArrayList的长度,elementData数组:用来存储数据的数组。 在Arraylist扩容时,调用Add方法,
- 方法中会首先判断得到最小扩容量,如果你构造的ArrayList是用无参构造,即你创建ArrayList时没有确定它的长度,最小扩容量就为10和size+1当中的最大值,
- 然后再判断是否需要扩容,如果最小扩容量大于elementData.length,就需要扩容,然后调用grow()方法,其中旧容量为elementData.length,新容量为elementData.length的1.5倍(new=old+old>>1),
- 若新容量大于size+1,最小需要容量就为新容量,
- 若新容量小于size+1,最小需要容量就为size+1,之后再将原来的数组用Arrays.copyOf方法复制到新数组,使新数组的长度为最小需要容量。
package data.test;
import java.util.Arrays;
public class MyArrayList {
//保存数据的数组
private Object [] elementData;
private static final Object[] DEFAULTCAPACITY_EMPTY_ELEMENTDATA = {};
//数组的长度
private Integer size;
public MyArrayList(){
elementData=DEFAULTCAPACITY_EMPTY_ELEMENTDATA;
}
public MyArrayList(Integer num){elementData=new Object[num];}
public boolean add(Object o){
Integer mincapity;
if(elementData==DEFAULTCAPACITY_EMPTY_ELEMENTDATA){
mincapity=Math.max(10,size+1);
}
else {
mincapity=size+1;
}
need(mincapity);
elementData[size++]=o;
return true;
}
public void need(Integer mincapity){
if(mincapity>1);
Integer needCapity;
if(size+1>newcapity){
needCapity=size+1;
}
else {
needCapity=newcapity;
}
Arrays.copyOf(elementData,needCapity);
}
}
- 线程是否安全: **HashMap 是⾮线程安全的, HashTable 是线程安全的,**因为 HashTable 内部的⽅法基本都经过 synchronized 修饰。(如果你要保证线程安全的话就使⽤ConcurrentHashMap 吧!);
- 效率: 因为线程安全的问题, HashMap 要⽐ HashTable 效率⾼
- 对 Null key 和 Null value 的⽀持: **HashMap 允许有 null 键和 null 值;**HashTable 不允许有 null 键和 null 值,否则会抛出NullPointerException 。
- 初始容量⼤⼩和每次扩充容量⼤⼩的不同 : ① 创建时如果不指定容量初始值, Hashtable默认的初始⼤⼩为 11,之后每次扩充,容量变为原来的 2n+1。 HashMap 默认的初始化⼤⼩为 16。之后每次扩充,容量变为原来的 2 倍。② 创建时如果给定了容量初始值,那么Hashtable 会直接使⽤你给定的⼤⼩,⽽ HashMap 会将其扩充为 2 的幂次⽅⼤⼩
- 底层数据结构: JDK1.8 以后的 HashMap 在解决哈希冲突时有了较⼤的变化,当链表⻓度⼤于阈值(默认为 8)(将链表转换成红⿊树前会判断,如果当前数组的⻓度⼩于 64,那么会选择先进⾏数组扩容,⽽不是转换为红⿊树)时,将链表转化为红⿊树,以减少搜索时间。Hashtable 没有这样的机制
- 是否有 contains 方法:HashMap 没有 contains 方法;Hashtable 包含 contains 方法,类似于 containsValue。
- 父类不同:HashMap 继承自 AbstractMap;Hashtable 继承自 Dictionary。
如果你看过 HashSet 源码的话就应该知道: HashSet 底层就是基于 HashMap 实现的。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-mtWkehz9-1632495288000)(C:\Users\LENOVO-LX\AppData\Roaming\Typora\typora-user-images\image-20210902102656030.png)]
HashSet如何检查重复存储的元素是⽆序的、不可重复的
以下内容摘⾃我的 Java 启蒙书《Head fist java》第⼆版:
当你把对象加⼊ HashSet 时, HashSet 会先计算对象的 hashcode 值来(当运用 hashCode() 时,判断是否有相同元素的代价,只是一次哈希计算,时间复杂度为O(1),equals() 方法时间复杂度为 O(n) ,这极大地提高了数据的存储性能。)**判断对象加⼊的位置,同时也会与其他加⼊的对象的 hashcode 值作⽐较,**如果没有相符的 hashcode , HashSet 会假设对象没有重复出现。但是如果发现有相同 hashcode 值的对象,这时会调⽤ equals() ⽅法来检查hashcode 相等的对象是否真的相同。如果两者相同, HashSet 就不会让加⼊操作成功。
hashCode() 与 equals() 的相关规定:
-
如果两个对象相等,则 hashcode ⼀定也是相同的;两个对象的hashcode值相同,equals值不一定相同
-
两个对象相等,对两个 equals() ⽅法返回 true
-
hashCode() 的默认⾏为是对堆上的对象产⽣独特值。如果没有重写 hashCode() ,则该class 的两个对象⽆论如何都不会相等(即使这两个对象指向相同的数据)。
数组优劣势,链表优劣势,整合这两种数据结构的优势:散列表,
散列表:数组+链表,数组中保存的数据是链表,整合了数组的快速索引index和链表的动态扩容;有散列表就必须要有哈希,hash基本原理是把任意长度的输入,通过hash算法变成固定长度的输出。从原始数据映射后的二进制串就是哈希值。
hash的特点:
- 从hash值不可以反向推导出原始的数据
- 输入的数据的微小变化会得到完全不同的hash值,相同的数据会得到相同的值
- hash算法的执行效率要高效,长的文本也能快速的计算出哈希值
- hash算法的冲突概率要小(hash冲突可以联想抽屉原理)
16
10000
&01111
hashmap:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-g163dZR8-1632495288002)(C:\Users\LENOVO-LX\AppData\Roaming\Typora\typora-user-images\image-20210913110449863.png)]
发生冲突时会形成链表,当某个链表的长度超过8达到9,并且数组长度超过64个时,那么这个链表就会树化成红黑树。所以hashmap底层结构其实是数组+链表+红黑树
出现红黑树就是为了解决出现碰撞时链化链得很长的问题(当元素越来越多的时候,hashMap的查找速度就从O(1)升到O(n),导致链化严重),提高查找效率,红黑树是一个自平衡的二叉查找树
发生冲突时会形成链表,当某个链表的长度超过8达到9,而数组长度并未超过64个时就选择对数组进行扩容,hashmap扩容原理:数组默认长度为16,为了解决哈希冲突导致的链化严重从而导致查找效率低的问题,我们提供了扩容机制,把数组长度扩大,桶位多了,每个桶位存放的链表长度就减少了,那么查询的效率就会提升;
让key的hash值高16位也参与路由运算hash&(length-1)=index(路由寻址的下标),当length很小时,让高16位参与运算的原因,当数组的长度很短时,只有低位数的hashcode值能参与运算。而让高16位参与运算可以更好的均匀散列,减少碰撞,进一步降低hash冲突的几率。并且使得高16位和低16位的信息都被保留了。 然后有不少博客提到了因为int是4个字节,所以右移16位。原因大家可以打开hashmap的源码,找到hash方法,按住ctrl点击方法里的hashcode,跳转到Object类,然后可以看到hashcode的数据类型是int。int为4个字节,1个字节8个比特位,就是32个比特位,所以16很可能是因为32对半的结果,也就是让高的那一半也来参与运算
HashMap基于Map接口实现,元素以键值对的方式存储,并且允许使用null 建和null值,因为key不允许重复,因此只能有一个键为null,另外HashMap不能保证放入元素的顺序,它是无序的,和放入的顺序并不能相同。HashMap是线程不安全的。多线程环境中推荐ConcurrentHashMap。
JDK1.8之前:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-vAGqldPy-1632495288006)(C:\Users\LENOVO-LX\AppData\Roaming\Typora\typora-user-images\image-20210902110043071.png)]
JDK1.8 之前 HashMap 底层是 数组和链表 结合在⼀起使⽤也就是 链表散列**。从上图我们可以发现数据结构由数组+链表组成,一个长度为16的数组中,每个元素存储的是一个链表的头结点。判断当前元素存放的位置一般情况是通过hash(key.hashCode())%length获得,也就是元素的key的哈希值对数组长度取模得到或者hash&(length-1)**。(比如上述哈希表中,12%16=12,28%16=12,108%16=12,140%16=12。所以12、28、108以及140都存储在数组下标为12的位置。)
计算Hash值得算法,实际就是取模,hash%length,
计算机中直接求余效率不如位移运算,源码中做了优化hash&(length-1)
要想保证hash%length==hash&(length-1)
那么length必须是2的n次方;
素与要存⼊的元素的 hash 值以及 key是否相同,如果相同的话,直接覆盖,不相同就通过拉链法解决冲突。(所谓 “拉链法” 就是:创建⼀个链表数组,数组中每⼀格就是⼀个链表。若遇到哈希冲突,则将冲突的值加到链表中即可。**)
- HashMap 基于 Hash 算法实现,通过 put(key,value) 存储,get(key) 来获取 value
- 当传入 key 时,HashMap 会根据 key,调用 hash(Object key) 方法,计算出 hash 值,根据 hash 值将 value 保存在 Node 对象里,Node 对象保存在数组里
- 当计算出的 hash 值相同时,称之为 hash 冲突,HashMap 的做法是用链表和红黑树存储相同 hash 值的 value
- 当 hash 冲突的个数:小于等于 8 使用链表;大于 8 且 tab length 大于等于 64 时,使用红黑树解决链表查询慢的问题
JDK1.8之后:
JDK1.8 之后HashMap采用数组+链表+红黑树实现 ,在解决哈希冲突时有了较⼤的变化,当链表⻓度⼤于阈值(默认为 8)(将链表转换成红⿊树前会判断,如果当前数组的⻓度⼩于 64,那么会选择先进⾏数组扩容,⽽不是转换为红⿊树)时,将链表转化为红⿊树,以减少搜索时间。
TreeMap、TreeSet 以及 JDK1.8 之后的 HashMap 底层都⽤到了红⿊树。红⿊树就是为了解决⼆叉查找树的缺陷,因为⼆叉查找树在某些情况下会退化成⼀个线性结构。
HashMap的长度为什么是2的幂次方为了能让 HashMap 存取⾼效,尽量较少碰撞,也就是要尽量把数据分配均匀。Hash 值的范围值-2147483648到2147483647,前后加起来⼤概40亿的映射空间,只要哈希函数映射得⽐较均匀松散,⼀般应⽤是很难出现碰撞的。如果是⼀个40亿⻓度的数组,内存是放不下的。所以这个散列值是不能直接拿来⽤的。⽤之前还要先做对数组的⻓度取模运算,得到的余数才能⽤来要存放的位置也就是对应的数组下标。
实际中通过 **hash&(length - 1) **而不用hash%length判断当前元素存放的位置,因为当取余(%)操作中如果除数是2的幂次,则等价于与其除数减⼀的与(&)操作(也就是说 hash%length==hash&(length-1)的前提是 length是2的n 次⽅;)。” 而这时采⽤⼆进制位操作 &,相对于%能够提⾼运算效率,这就解释了 HashMap 的⻓度为什么是2的幂次⽅。
HashMap多线程操作导致死循环问题主要原因是多线程情况下数组进行put操作,如果数组的长度不够, 那么这时候HashMap就会进行Rehash操作,两个线程在这个时候很有可能同时触发了rehash操作,造成元素之间会形成⼀个循环链表。不过,jdk 1.8 后解决了这个问题,但是还是不建议在多线程下使⽤ HashMap,因为多线程下使⽤ HashMap 还是会存在其他问题⽐如数据丢失。所以为什么并发环境下推荐使⽤ ConcurrentHashMap 。
ConcurrentHashMap和HashTable区别ConcurrentHashMap 和 Hashtable 的区别主要体现在实现线程安全的⽅式上不同。
底层数据结构: JDK1.7 的 ConcurrentHashMap 底层采⽤ 分段的数组+链表 实现,JDK1.8采⽤数组+链表/红⿊树。 Hashtable 和JDK1.8 之前的 HashMap 的底层数据结构类似都是采⽤ 数组+链表的形式,数组是HashMap 的主体,链表则是主要为了解决哈希冲突⽽存在的;
实现线程安全的⽅式(重要):
① 在 JDK1.7的时候,ConcurrentHashMap (分段锁)
对整个桶数组进⾏了分割分段( Segment ),每⼀把锁只锁容器其中⼀部分数据,多线程访问容器⾥不同数据段的数据,就不会存在锁竞争,提⾼并发访问率。 到了JDK1.8的时候已经摒弃了Segment的概念,⽽是直接⽤ Node 数组+链表+红⿊树的数据结构来实现,并发控制使⽤ synchronized 和 CAS 来操作。
② Hashtable (同⼀把锁) :使⽤ synchronized 来保证线程安全,效率⾮常低下。当⼀个线程访问同步⽅法时,其他线程也访问同步⽅法,可能会进⼊阻塞或轮询状态,如使⽤ put 添加元素,另⼀个线程不能使⽤ put 添加元素,也不能使⽤ get,竞争会越来越激烈效率越低。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-WRjlVAJ9-1632495288008)(C:\Users\LENOVO-LX\AppData\Roaming\Typora\typora-user-images\image-20210902125353656.png)]
ConcurrentHashMap线程安全的具体实现(底层实现)[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-sltfs1be-1632495288009)(C:\Users\LENOVO-LX\AppData\Roaming\Typora\typora-user-images\image-20210902125331698.png)]
JDK1.7:
⾸先将数据分为⼀段⼀段的存储,然后给每⼀段数据配⼀把锁,当⼀个线程占⽤锁访问其中⼀个段数据时,其他段的数据也能被其他线程访问。ConcurrentHashMap 是由 Segment 数组结构和HashEntry 数组结构组成。Segment 实现了 ReentrantLock ,所以 Segment 是⼀种可重⼊锁,扮演锁的⻆⾊。 HashEntry ⽤于存储键值对数据
⼀个 ConcurrentHashMap ⾥包含⼀个 Segment 数组。 Segment 的结构和 HashMap 类似,是⼀种数组和链表结构,⼀个 Segment 包含⼀个 HashEntry 数组,每个 HashEntry 是⼀个链表结构的元素,每个 Segment 守护着⼀个 HashEntry 数组⾥的元素,当对 HashEntry 数组的数据进⾏修改时,必须⾸先获得对应的 Segment 的锁。
JDK1.8:
ConcurrentHashMap 取消了 Segment 分段锁,采⽤ CAS 和 synchronized 来保证并发安全。数据结构跟 HashMap1.8 的结构类似,数组+链表/红⿊⼆叉树。Java 8 在链表⻓度超过⼀定阈值(8)时将链表(寻址时间复杂度为 O(N))转换为**红⿊树(寻址时间复杂度为 O(log(N)))**synchronized 只锁定当前链表或红⿊⼆叉树的⾸节点,这样只要 hash 不冲突,就不会产⽣并发,效率⼜提升 N 倍。
比较HashSet,LinkedHashSet和TreeSet三者异同HashSet 是 Set 接⼝的主要实现类 , HashSet 的底层是 HashMap ,HashSet 的⼦类是LinkedHashSet
HashSet:
1.HashSet中不能有相同的元素,可以有一个Null元素,存入的元素是无序的。
2.HashSet如何保证唯一性?
-
HashSet底层数据结构是哈希表,哈希表就是存储唯一系列的表,而哈希值是由对象的hashCode()方法生成。
-
确保唯一性的两个方法:hashCode()和equals()方法。
-
添加、删除操作时间复杂度都是O(1)。
-
非线程安全
LinkedHashSet:
1.LinkedHashSet中不能有相同元素,可以有一个Null元素,元素严格按照放入的顺序排列。
2.LinkedHashSet如何保证有序和唯一性?
-
底层数据结构由哈希表和链表组成。
-
链表保证了元素的有序即存储和取出一致,哈希表保证了元素的唯一性。
-
添加、删除操作时间复杂度都是O(1)。
-
非线程安全
TreeSet:
TreeSet是中不能有相同元素,不可以有Null元素,根据元素的自然顺序进行排序。
TreeSet如何保证元素的排序和唯一性?
-
底层的数据结构是红黑树(一种自平衡二叉查找树)
-
添加、删除操作时间复杂度都是O(log(n))
-
非线程安全
总体而言:
如果你需要一个访问快速的Set,你应该使用HashSet;
当你需要一个排序的Set,你应该使用TreeSet;
当你需要记录下插入时的顺序时,你应该使用LinedHashSet。
如何选用集合?主要根据集合的特点来选⽤,⽐如我们需要根据键值获取到元素值时就选⽤ Map 接⼝下的集合,需要排序时选择 TreeMap ,不需要排序时就选择 HashMap ,需要保证线程安全就选⽤ConcurrentHashMap 。
当我们只需要存放元素值时,就选择实现 Collection 接⼝的集合,需要保证元素唯⼀时选择实现Set 接⼝的集合⽐如 TreeSet 或 HashSet ,不需要就选择实现 List 接⼝的⽐如 ArrayList 或LinkedList ,然后再根据实现这些接⼝的集合的特点来选⽤。
Collection和Collections有什么区别? Array和ArrayList有何区别Array是数组,定义一个 Array 时,必须指定数组的数据类型及数组长度,即数组中存放的元素个数固定并且类型相同。
ArrayList 是动态数组,长度动态可变,会自动扩容。不使用泛型的时候,可以添加不同类型元素。
Queue的add()和offer()方法有什么区别-
Queue 中 add() 和 offer() 都是用来向队列添加一个元素。
-
在容量已满的情况下,add() 方法会抛出IllegalStateException异常,offer() 方法只会返回 false 。
-
Queue 中 remove() 和 poll() 都是用来从队列头部删除一个元素。
-
在队列元素为空的情况下,remove() 方法会抛出NoSuchElementException异常,poll() 方法只会返回 null 。
-
Queue 中 element() 和 peek() 都是用来返回队列的头元素,不删除。
-
在队列元素为空的情况下,element() 方法会抛出NoSuchElementException异常,peek() 方法只会返回 null。
- 迭代器是 Java 中常用的设计模式之一,它是一个对象。是一种通用的顺序遍历集合元素的接口,无需知道集合对象的底层实现。迭代器通常被称为“轻量级”对象,因为创建它的代价小。
- Iterator 是可以遍历集合的对象,为各种容器提供了公共的操作接口,隔离对容器的遍历操作和底层实现,从而解耦。
- 缺点是增加新的集合类需要对应增加新的迭代器类,迭代器类与集合类成对增加
Iterator怎么使用,Iterator 接口源码中的方法:
- java.lang.Iterable 接口被 java.util.Collection 接口继承,java.util.Collection 接口的 iterator() 方法返回一个 Iterator 对象
- next() 方法获得集合中的下一个元素
- hasNext() 检查集合中是否还有元素
- remove() 方法将迭代器新返回的元素删除
- forEachRemaining(Consumer
关注打赏
最近更新
- 深拷贝和浅拷贝的区别(重点)
- 【Vue】走进Vue框架世界
- 【云服务器】项目部署—搭建网站—vue电商后台管理系统
- 【React介绍】 一文带你深入React
- 【React】React组件实例的三大属性之state,props,refs(你学废了吗)
- 【脚手架VueCLI】从零开始,创建一个VUE项目
- 【React】深入理解React组件生命周期----图文详解(含代码)
- 【React】DOM的Diffing算法是什么?以及DOM中key的作用----经典面试题
- 【React】1_使用React脚手架创建项目步骤--------详解(含项目结构说明)
- 【React】2_如何使用react脚手架写一个简单的页面?

