
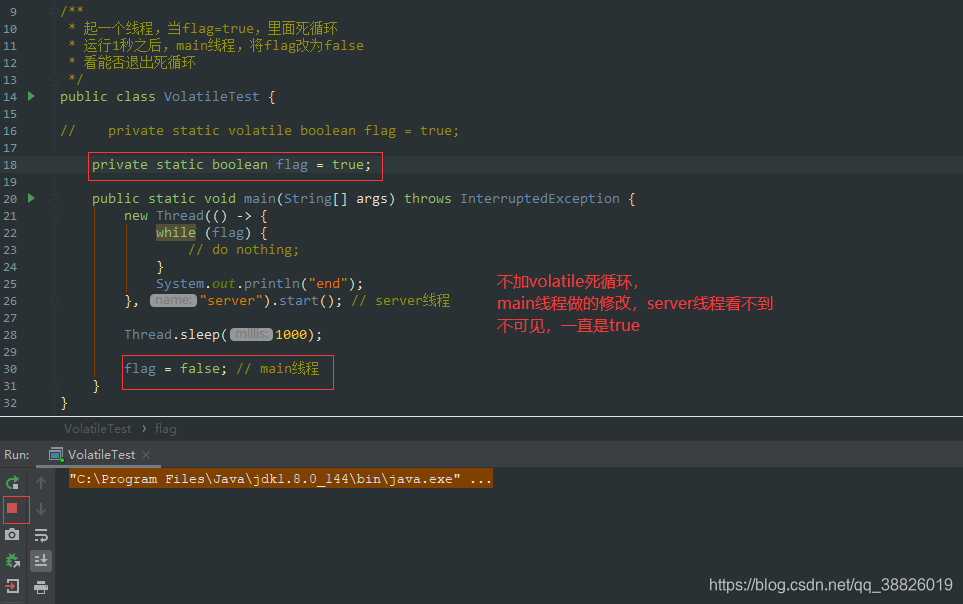
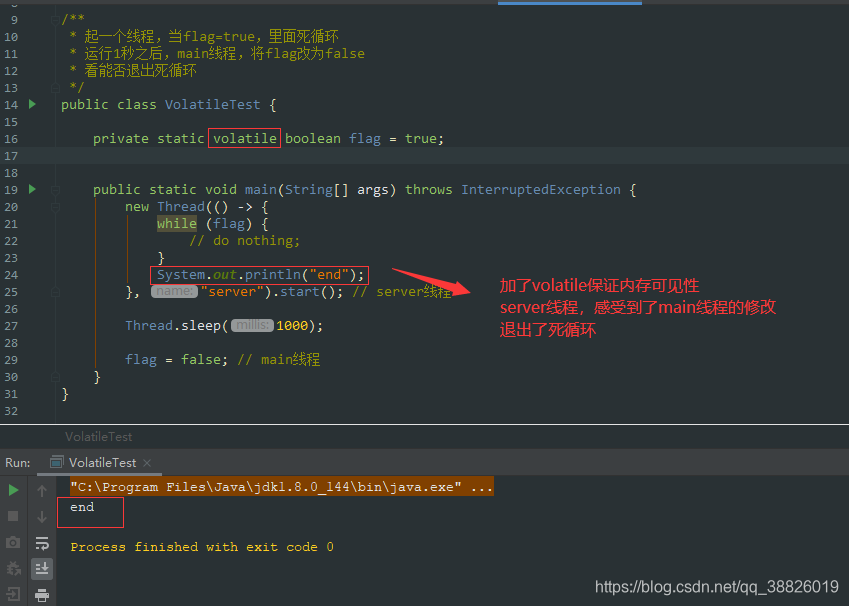
Volatile关键
CPU在进行读等待的同时执行指令,是CPU乱序的根源,不是乱,而是提高效率

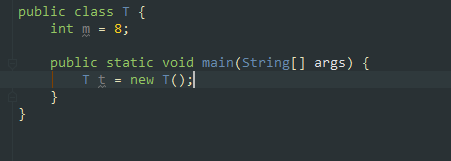
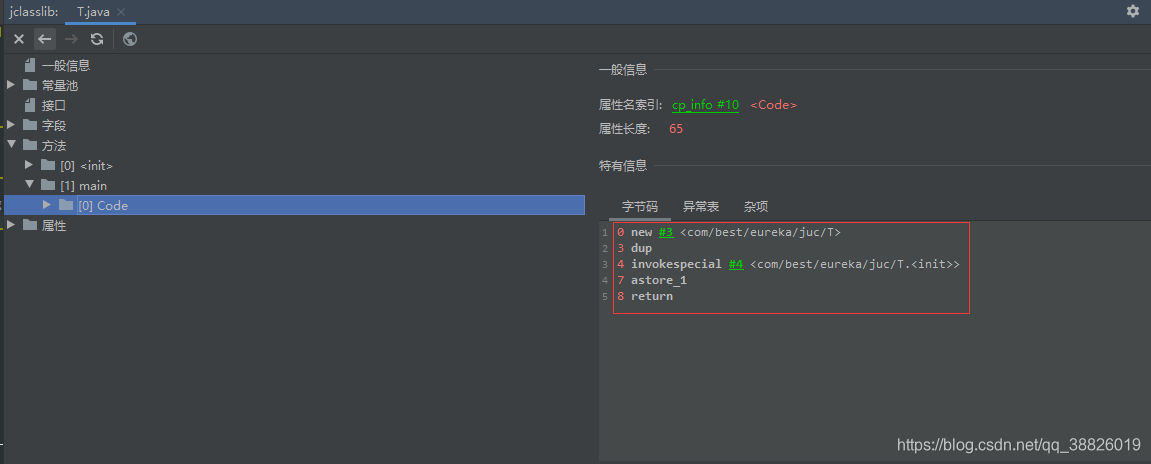
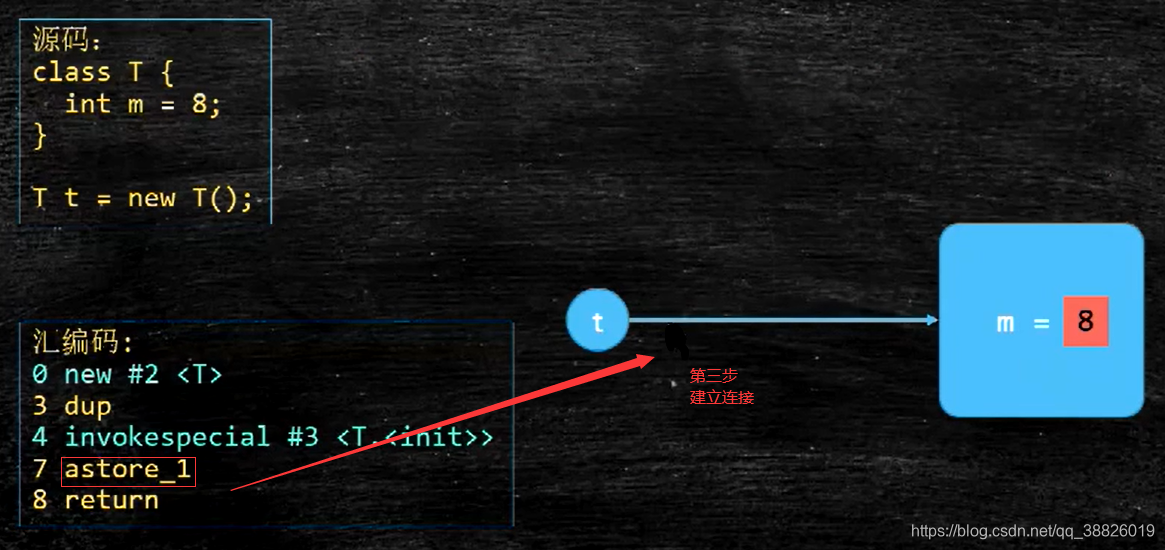
对象的创建过程:
创建->初始化->建立连接
1.先申请内存,赋值默认值0
2.构造方法赋值初始值,8
3.建立连接,t->T


DCL单例模式
public class Singleton {
private volatile static Singleton instance = null;
public static Singleton getInstance() {
if(null == instance) {
synchronized (Singleton.class) {
if(null == instance) {
instance = new Singleton();
}
}
}
return instance;
}
}
synchronized本身就可以支持线程可见
看样子已经达到了要求,除了第一次创建对象之外,其它的访问在第一个if中就返回了,因此不会走到同步块中,已经完美了吗?
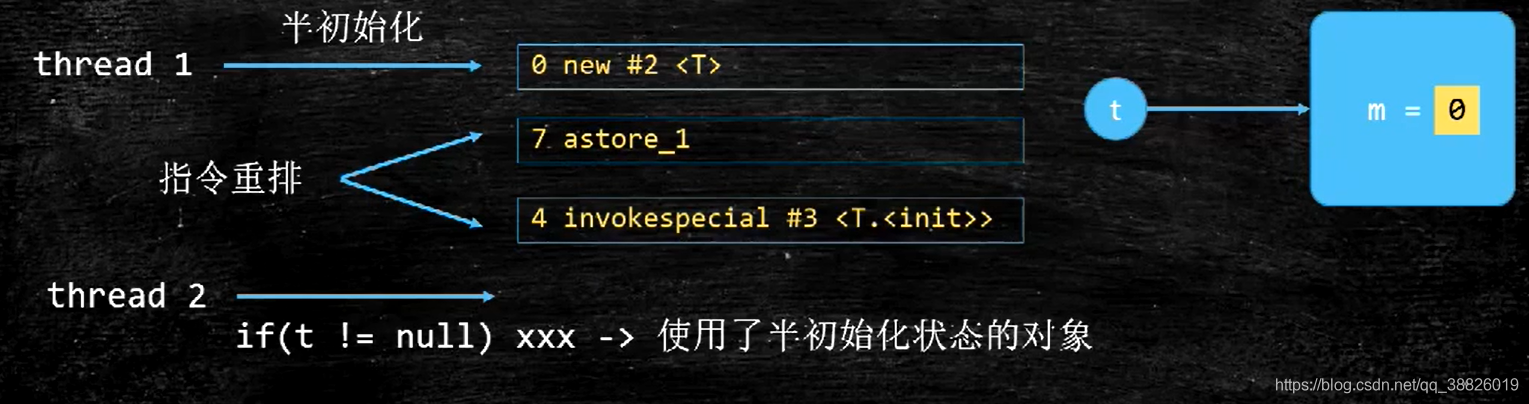
如上代码段中的注释:假设线程一执行到instance = new Singleton()这句,这里看起来是一句话,但实际上其被编译后在JVM执行的对应会变代码就发现,这句话被编译成8条汇编指令,大致做了三件事情:
1)给instance实例分配内存;
2)初始化instance的构造器;
3)将instance对象指向分配的内存空间(注意到这步时instance就非null了)
如果指令按照顺序执行倒也无妨,但JVM为了优化指令,提高程序运行效率,允许指令重排序。如此,在程序真正运行时以上指令执行顺序可能是这样的:
a)给instance实例分配内存;
b)将instance对象指向分配的内存空间;
c)初始化instance的构造器;
这时候,当线程一执行b)完毕,在执行c)之前,被切换到线程二上,这时候instance判断为非空,此时线程二直接来到return instance语句,拿走instance然后使用,接着就顺理成章地报错(对象尚未初始化)。
具体来说就是synchronized虽然保证了线程的原子性(即synchronized块中的语句要么全部执行,要么一条也不执行),但单条语句编译后形成的指令并不是一个原子操作(即可能该条语句的部分指令未得到执行,就被切换到另一个线程了)。
根据以上分析可知,解决这个问题的方法是:禁止指令重排序优化,即使用volatile变量。
将变量instance使用volatile修饰即可实现单例模式的线程安全。
五、内存屏障 5.1 CPU层面如何禁止重排序内存屏障
对某部分内存做操作时前后添加的屏障,屏障前后的操作不可以乱序执行


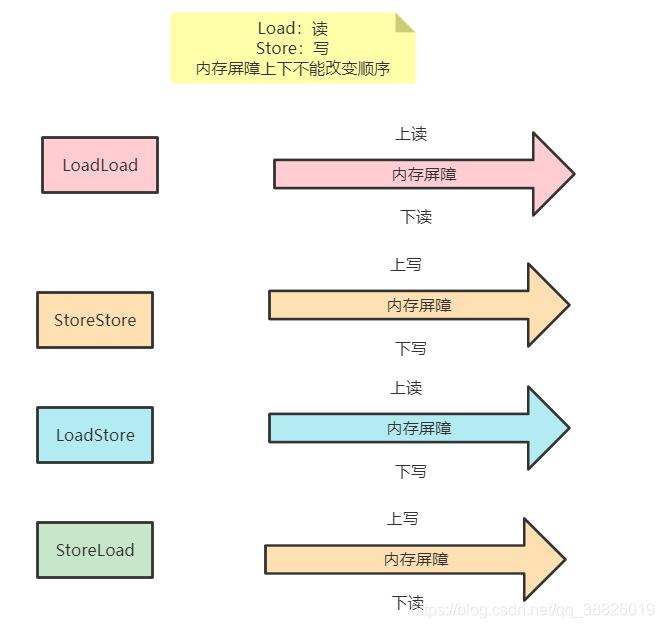

总之,volatile读写前后,都加屏障
5.4 hanppens-before原则 则
则
JVM规定重排序必须遵守的规则,下面的几种,必须加屏障,禁止指令重排
5.5 as if serial不管如何重排序,单线程执行结果不会改变,不影响数据的最终一致性
六、volatile如何解决指令重排序1: volatile i
2: ACC_VOLATILE
3: JVM的内存屏障:屏障两边的指令不可以重排,保障有序。
4:hotspot实现
bytecodeinterpreter.cpp
int field_offset = cache‐>f2_as_index();
if (cache‐>is_volatile()) {
if (support_IRIW_for_not_multiple_copy_atomic_cpu) {
OrderAccess::fence(); // fence屏障
}orderaccess_linux_x86.inline.hpp
inline void OrderAccess::fence() {
if (os::is_MP()) {
// always use locked addl since mfence is sometimes expensive
#ifdef AMD64
__asm__ volatile ("lock; addl $0,0(%%rsp)" : : : "cc", "memory");
#else
__asm__ volatile ("lock; addl $0,0(%%esp)" : : : "cc", "memory");
#endif
}
}lock addl
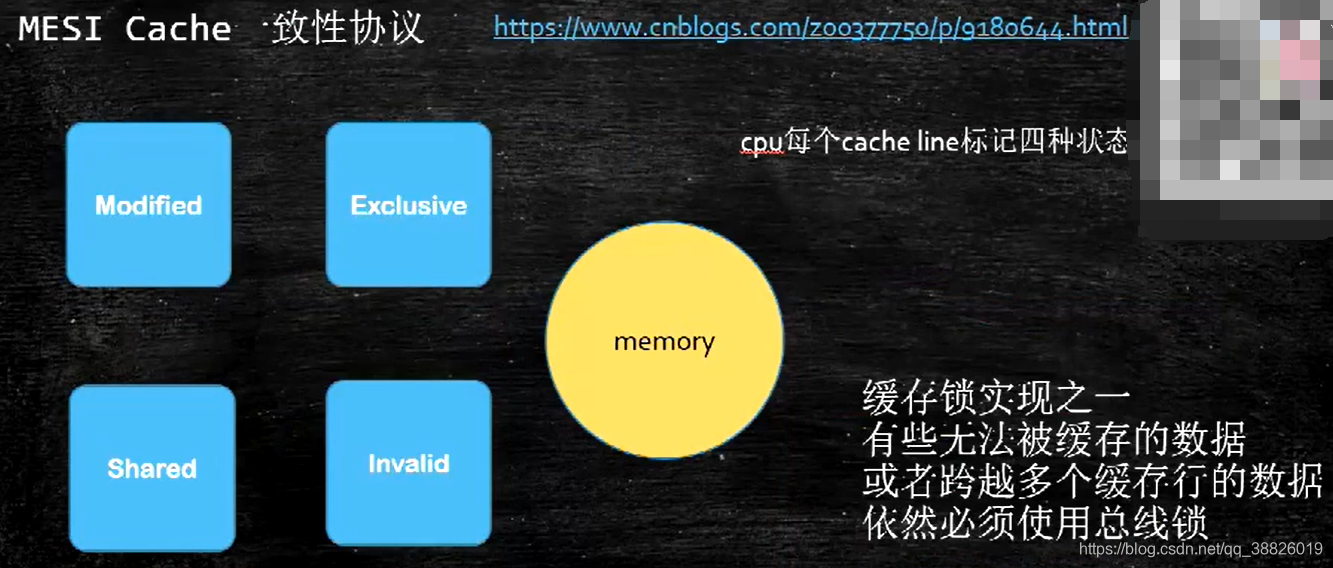
LOCK用于在多处理器中执行指令时对共享内存的独占使用。
它的作用是能够将当前处理器对应缓存的内容刷新到内存,并使其他处理器对应的缓存失效。另外还提供了有序的指令无法越过这个内存屏障的作用。
七、缓存 7.1 计算机的组成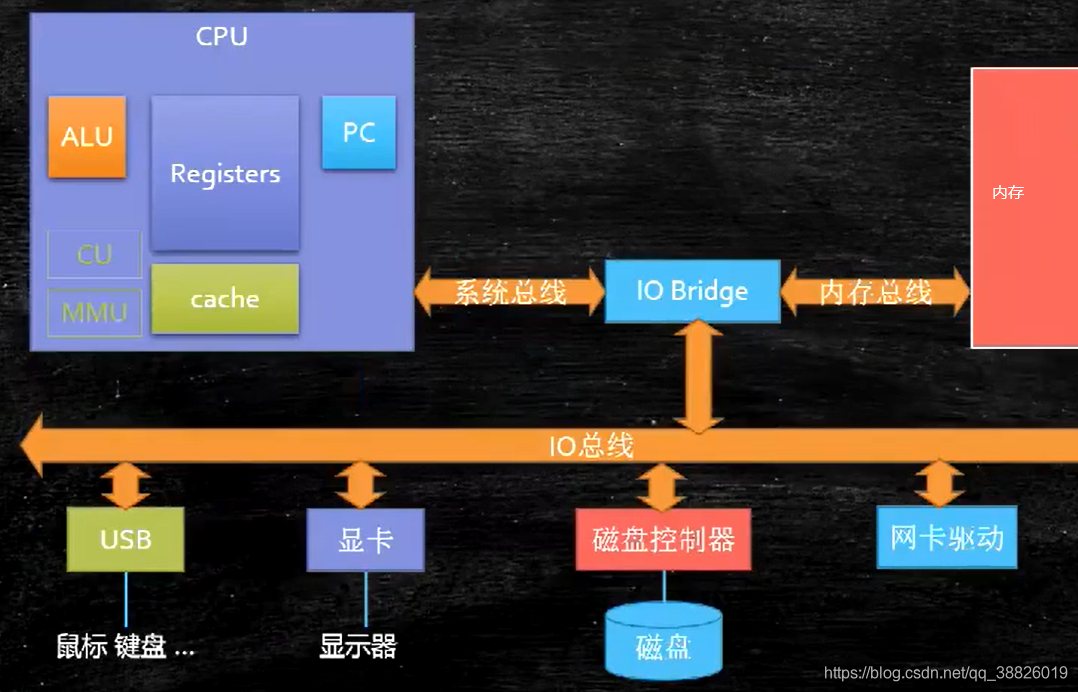
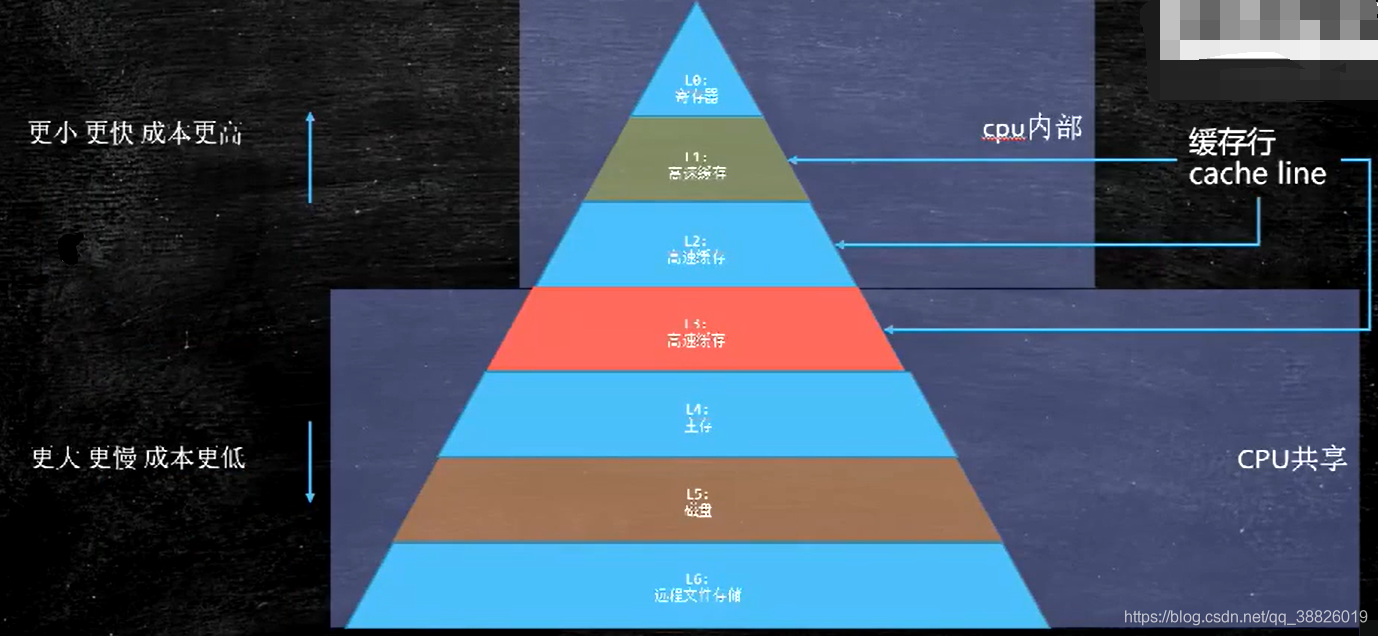

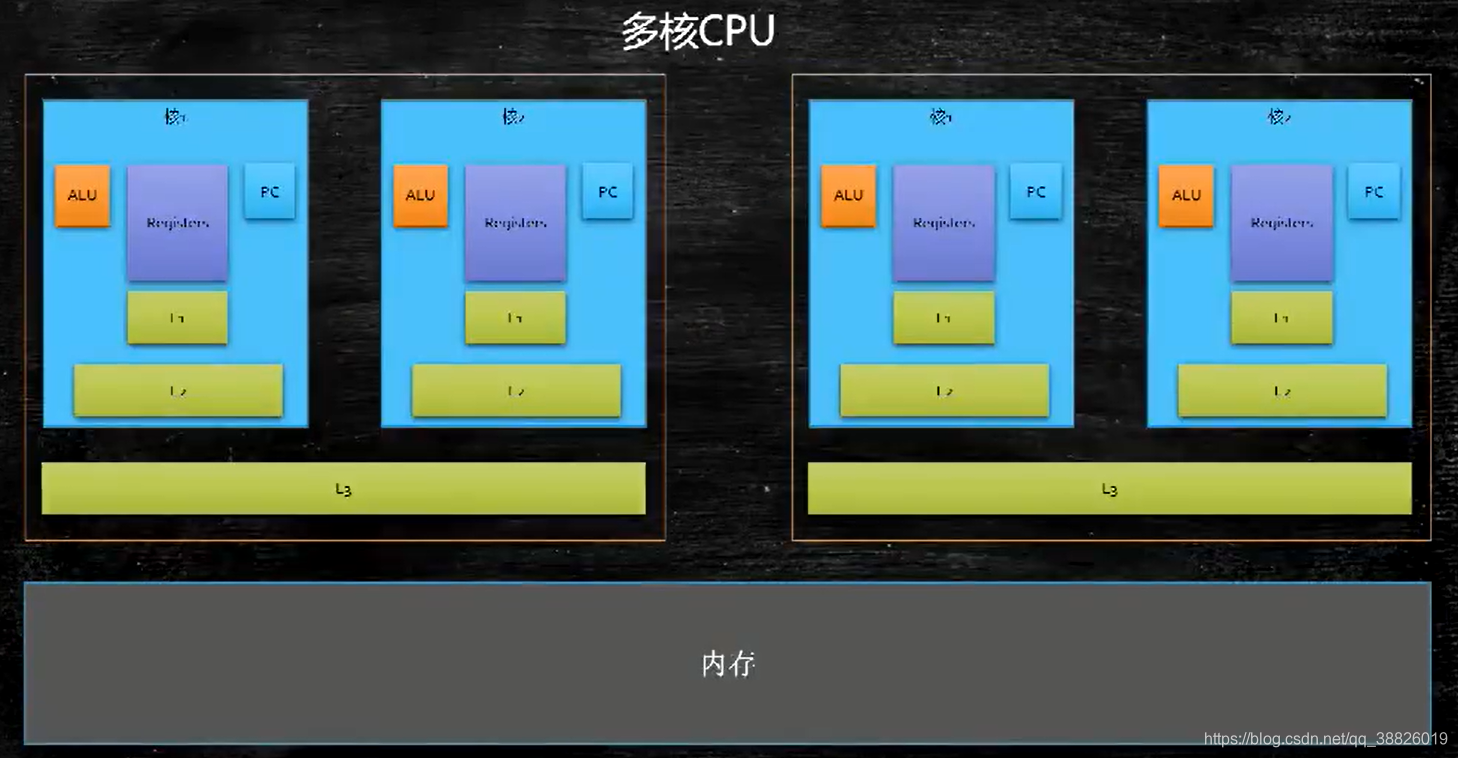
按块读取,程序局部性原理,可以提高效率,充分发挥总线CPU针脚等一次性读取更多数据的能力。
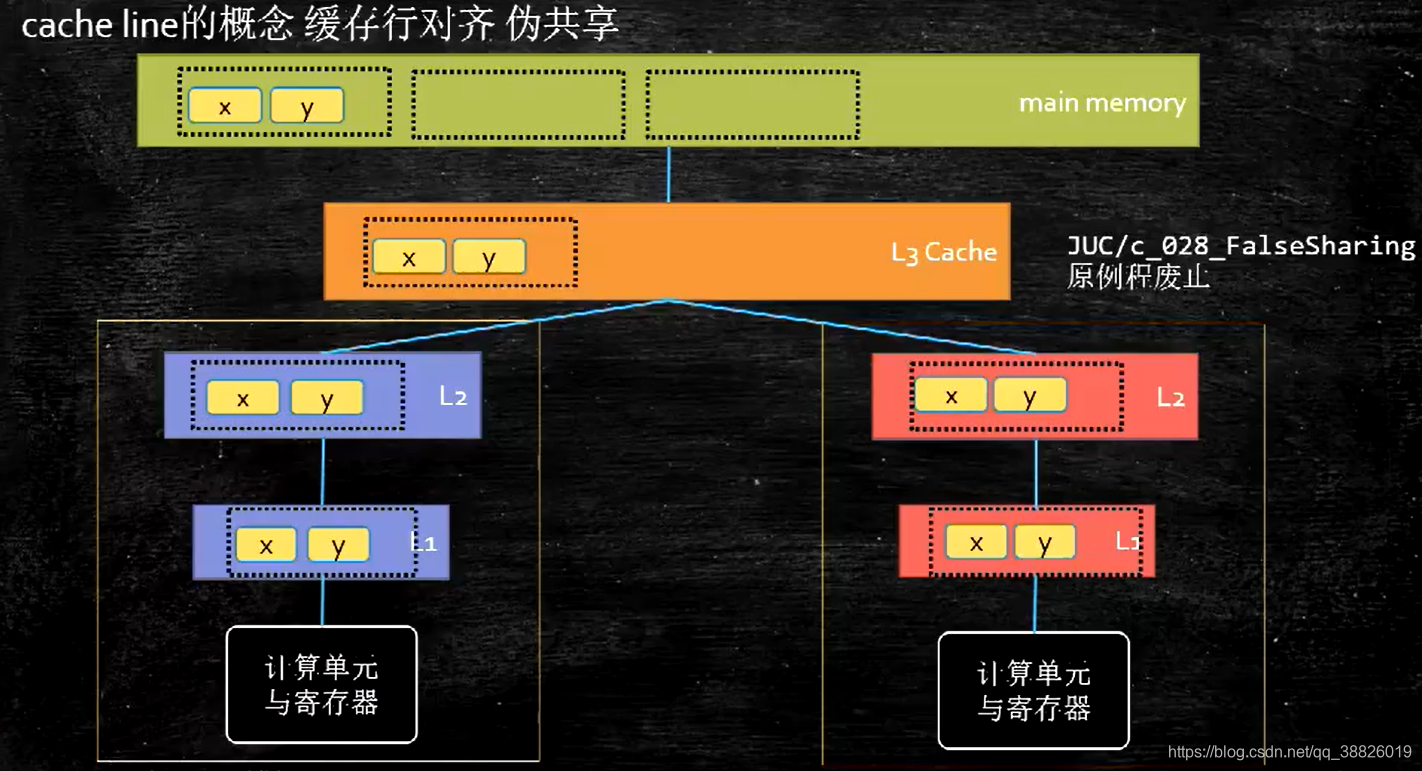
缓存行:
缓存行越大,局部性空间效率越高,但读取时间慢缓存行越小,局部性空间效率越低,但读取时间快取一个折中值,目前多用:64字节
Volatile关键、视频教程

