1、是轻量级的java框架,是增强版的JDBC驱动
2、Sharding-JDBC
(1)主要目的是:简化对分库分表之后数据相关操作
Sharding-JDBC是当当网研发的开源分布式数据库中间件,从 3.0 开始Sharding-JDBC被包含在 Sharding-Sphere中,之后该项目进入Apache孵化器,
4.0版本之后的版本为Apache版本。
Sharding-JDBC是ShardingSphere的第一个产品,也是ShardingSphere的前身。 它定位为轻量级Java框架,在Java的JDBC层提供的额外服务。
它使用客户端直连数据库,以jar包形式提供服务,无需额外部署和依赖,可理解为增强版的JDBC驱动,完全兼容JDBC和各种ORM框架。

Sharding-JDBC的核心功能为数据分片和读写分离,通过Sharding-JDBC,应用可以透明的使用jdbc访问已经分库分表、读写分离的多个数据源,
而不用关心数据源的数量以及数据如何分布。
1. 适用于任何基于JDBC的ORM框架,如:JPA, Hibernate, Mybatis, Spring JDBC Template或直接使用JDBC。
2. 支持任何第三方的数据库连接池,如:DBCP, C3P0, BoneCP, Druid, HikariCP等。
3. 支持任意实现JDBC规范的数据库。目前支持MySQL,Oracle,SQLServer,PostgreSQL以及任何遵循SQL92标准的数据库。
二、Sharding-JDBC实现水平分表 2.1 搭建环境Sharding-JDBC-水平分表源码
(1)技术:SpringBoot 2.2.1+ MyBatisPlus + Sharding-JDBC + Druid连接池
(2)创建SpringBoot工程
(3)修改工程SpringBoot版本 2.2.1
(4) 引入需要的依赖
2.1.1 创建SpringBoot工程 




org.springframework.boot
spring-boot-starter
org.springframework.boot
spring-boot-starter-test
com.alibaba
druid-spring-boot-starter
1.1.20
mysql
mysql-connector-java
org.apache.shardingsphere
sharding-jdbc-spring-boot-starter
4.0.0-RC1
com.baomidou
mybatis-plus-boot-starter
3.0.5
org.projectlombok
lombok
1. 创建数据库course_db
2. 在数据库创建两张表course_1和course_2
3. 约定规则:如果添加课程id是偶数把数据添加course_1,如果奇数添加到course_2
1.建表语句
CREATE DATABASE `course_db` CHARACTER SET 'utf8' COLLATE 'utf8_general_ci';
DROP TABLE IF EXISTS `course_1`;
create table course_1 (
cid bigint(20) primary key comment '课程id',
cname varchar(50) not null comment '课程名称',
user_id bigint(20) not null comment '用户',
cstatus varchar(10) not null comment '状态'
)
DROP TABLE IF EXISTS `course_2`;
create table course_2 (
cid bigint(20) primary key comment '课程id',
cname varchar(50) not null comment '课程名称',
user_id bigint(20) not null comment '用户',
cstatus varchar(10) not null comment '状态'
)
1. 创建实体类,mapper


# shardingjdbc分片策略
# 配置数据源,给数据源起名称
spring.shardingsphere.datasource.names=m1
# 配置数据源具体内容,包含连接池,驱动,地址,用户名和密码
spring.shardingsphere.datasource.m1.type=com.alibaba.druid.pool.DruidDataSource
spring.shardingsphere.datasource.m1.driver-class-name=com.mysql.cj.jdbc.Driver
spring.shardingsphere.datasource.m1.url=jdbc:mysql://localhost:3306/course_db?serverTimezone=GMT%2B8
spring.shardingsphere.datasource.m1.username=root
spring.shardingsphere.datasource.m1.password=root
# 指定course表分布情况,配置表在哪个数据库里面,表名称都是什么 m1.course_1, m1.course_2
spring.shardingsphere.sharding.tables.course.actual-data-nodes=m1.course_$->{1..2}
# 指定course表里面主键cid 生成策略 SNOWFLAKE 雪花算法
spring.shardingsphere.sharding.tables.course.key-generator.column=cid
spring.shardingsphere.sharding.tables.course.key-generator.type=SNOWFLAKE
# 指定表分片策略 约定cid值偶数添加到course_1表,如果cid是奇数添加到course_2表
spring.shardingsphere.sharding.tables.course.table-strategy.inline.sharding-column=cid
spring.shardingsphere.sharding.tables.course.table-strategy.inline.algorithm-expression=course_$->{cid % 2 + 1}
# 打开sql输出日志
spring.shardingsphere.props.sql.show=true@SpringBootTest
class ShardingjdbcdemoApplicationTests {
// 注入mapper
@Autowired
private CourseMapper courseMapper;
// 添加课程的方法
@Test
void addCourse() {
for (int i = 0; i {1..2}.course_$->{1..2}
# 指定course表里面主键cid 生成策略 SNOWFLAKE 雪花算法
spring.shardingsphere.sharding.tables.course.key-generator.column=cid
spring.shardingsphere.sharding.tables.course.key-generator.type=SNOWFLAKE
# 指定表分片策略 约定cid值偶数添加到course_1表,如果cid是奇数添加到course_2表
spring.shardingsphere.sharding.tables.course.table-strategy.inline.sharding-column=cid
spring.shardingsphere.sharding.tables.course.table-strategy.inline.algorithm-expression=course_$->{cid % 2 + 1}
# 指定数据库分片策略 约定user_id是偶数添加m1,是奇数添加m2,default默认所有表
#spring.shardingsphere.sharding.default-database-strategy.inline.sharding-column=user_id
#spring.shardingsphere.sharding.default-database-strategy.inline.algorithm-expression=m$->{user_id % 2 + 1}
# 仅针对course表
spring.shardingsphere.sharding.tables.course.database-strategy.inline..sharding-column=user_id
spring.shardingsphere.sharding.tables.course.database-strategy.inline.algorithm-expression=m$->{user_id % 2 + 1}
# 打开sql输出日志
spring.shardingsphere.props.sql.show=true
# 一个实体类对应两张表,覆盖
spring.main.allow-bean-definition-overriding=true
@SpringBootTest
class ShardingjdbcdemoApplicationTests {
// 注入mapper
@Autowired
private CourseMapper courseMapper;
//======================测试水平分库=====================
// 添加操作
@Test
public void addCourseDb() {
Course course = new Course();
course.setCname("javademo1");
//分库根据user_id
course.setUserId(222L);
course.setCstatus("Normal1");
courseMapper.insert(course);
}
// 查询操作
@Test
public void findCourseDb() {
QueryWrapper wrapper = new QueryWrapper();
// 设置userid值
wrapper.eq("user_id",111L);
// 设置cid值
wrapper.eq("cid",636298809789382657L);
Course course = courseMapper.selectOne(wrapper);
System.out.println(course);
}
}
Sharding-JDBC-垂直分库源码
4.1 需求分析
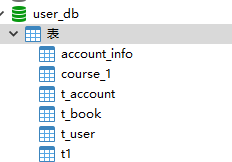
CREATE DATABASE `user_db` CHARACTER SET 'utf8' COLLATE 'utf8_general_ci';
DROP TABLE IF EXISTS `t_user`;
create table t_user (
user_id bigint(20) primary key comment '用户id',
user_name varchar(50) not null comment '用户名字',
ustatus varchar(10) not null comment '用户状态'
);
@Data
@TableName(value = "t_user") // 指定对应表
public class User {
private Long userId;
private String userName;
private String uStatus;
}
 4.3.2 配置垂直分库策略
4.3.2 配置垂直分库策略
* 在application.properties进行配置
# shardingjdbc分片策略
# 配置数据源,给数据源起名称
# 水平分库,配置两个数据源
spring.shardingsphere.datasource.names=m0,m1,m2
# 配置第一个数据源具体内容,包含连接池,驱动,地址,用户名和密码
spring.shardingsphere.datasource.m1.type=com.alibaba.druid.pool.DruidDataSource
spring.shardingsphere.datasource.m1.driver-class-name=com.mysql.cj.jdbc.Driver
spring.shardingsphere.datasource.m1.url=jdbc:mysql://localhost:3306/edu_db_1?serverTimezone=GMT%2B8
spring.shardingsphere.datasource.m1.username=root
spring.shardingsphere.datasource.m1.password=root
# 配置第二个数据源具体内容,包含连接池,驱动,地址,用户名和密码
spring.shardingsphere.datasource.m2.type=com.alibaba.druid.pool.DruidDataSource
spring.shardingsphere.datasource.m2.driver-class-name=com.mysql.cj.jdbc.Driver
spring.shardingsphere.datasource.m2.url=jdbc:mysql://localhost:3306/edu_db_2?serverTimezone=GMT%2B8
spring.shardingsphere.datasource.m2.username=root
spring.shardingsphere.datasource.m2.password=root
#-------------------垂直分库-------------------
# 配置第三个数据源具体内容,包含连接池,驱动,地址,用户名和密码
spring.shardingsphere.datasource.m0.type=com.alibaba.druid.pool.DruidDataSource
spring.shardingsphere.datasource.m0.driver-class-name=com.mysql.cj.jdbc.Driver
spring.shardingsphere.datasource.m0.url=jdbc:mysql://localhost:3306/user_db?serverTimezone=GMT%2B8
spring.shardingsphere.datasource.m0.username=root
spring.shardingsphere.datasource.m0.password=root
# 配置user_db数据库里面t_user 专库专表
# 指定数据库分布情况,数据库里面表分布情况
spring.shardingsphere.sharding.tables.t_user.actual-data-nodes=m$->{0}.t_user
# 指定t_user表里面主键user_id 生成策略 SNOWFLAKE 雪花算法
spring.shardingsphere.sharding.tables.t_user.key-generator.column=user_id
spring.shardingsphere.sharding.tables.t_user.key-generator.type=SNOWFLAKE
# 指定表分片策略 约定user_id值添加到t_user表
spring.shardingsphere.sharding.tables.t_user.table-strategy.inline.sharding-column=user_id
spring.shardingsphere.sharding.tables.t_user.table-strategy.inline.algorithm-expression=t_user
#-------------------水平分库分表-------------------
# 指定数据库分布情况,数据库里面表分布情况
# m1 m2 course_1 course_2
spring.shardingsphere.sharding.tables.course.actual-data-nodes=m$->{1..2}.course_$->{1..2}
# 指定course表里面主键cid 生成策略 SNOWFLAKE 雪花算法
spring.shardingsphere.sharding.tables.course.key-generator.column=cid
spring.shardingsphere.sharding.tables.course.key-generator.type=SNOWFLAKE
# 指定表分片策略 约定cid值偶数添加到course_1表,如果cid是奇数添加到course_2表
spring.shardingsphere.sharding.tables.course.table-strategy.inline.sharding-column=cid
spring.shardingsphere.sharding.tables.course.table-strategy.inline.algorithm-expression=course_$->{cid % 2 + 1}
# 指定数据库分片策略 约定user_id是偶数添加m1,是奇数添加m2,default默认所有表
#spring.shardingsphere.sharding.default-database-strategy.inline.sharding-column=user_id
#spring.shardingsphere.sharding.default-database-strategy.inline.algorithm-expression=m$->{user_id % 2 + 1}
# 仅针对course表
spring.shardingsphere.sharding.tables.course.database-strategy.inline..sharding-column=user_id
spring.shardingsphere.sharding.tables.course.database-strategy.inline.algorithm-expression=m$->{user_id % 2 + 1}
#-------------------公共配置-------------------
# 打开sql输出日志
spring.shardingsphere.props.sql.show=true
# 一个实体类对应两张表,覆盖
spring.main.allow-bean-definition-overriding=true
@SpringBootTest
class ShardingjdbcdemoApplicationTests {
// 注入mapper
@Autowired
private UserMapper userMapper;
//======================测试垂直分库==================
// 添加操作
@Test
public void addUserDb() {
User user = new User();
user.setUserName("lucymary");
user.setUstatus("a");
userMapper.insert(user);
}
// 查询操作
@Test
public void findUserDb() {
QueryWrapper wrapper = new QueryWrapper();
// 设置userid值
wrapper.eq("user_id",465508031619137537L);
User user = userMapper.selectOne(wrapper);
System.out.println(user);
}
}

Sharding-JDBC-公共表源码
5.1 公共表1、公共表
(1)存储固定数据的表,表数据很少发生变化,查询时候经常进行关联
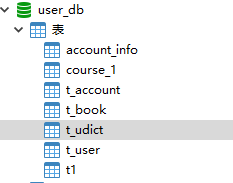
(2)在每个数据库中创建出相同结构公共表
5.2 在多个数据库都创建相同结构公共表DROP TABLE IF EXISTS `t_udict`;
create table t_udict (
dictid bigint(20) primary key comment '字典id',
ustatus varchar(100) not null comment '用户状态',
uvalue varchar(1000) not null comment '值'
);
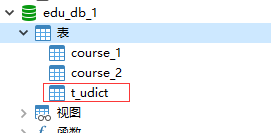
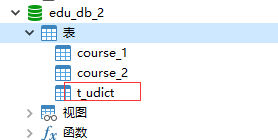
#-------------------公共表-------------------
# 配置公共表
spring.shardingsphere.sharding.broadcast-tables=t_udict
spring.shardingsphere.sharding.tables.t_udict.key-generator.column=dictid
spring.shardingsphere.sharding.tables.t_udict.key-generator.type=SNOWFLAKE(1)创建新实体类和mapper
@Data
@TableName(value = "t_udict")
public class Udict {
private Long dictid;
private String ustatus;
private String uvalue;
}

(2)编写添加和删除方法进行测试
@SpringBootTest
class ShardingjdbcdemoApplicationTests {
// 注入mapper
@Autowired
private UdictMapper udictMapper;
//======================测试公共表===================
// 添加操作
@Test
public void addDict() {
Udict udict = new Udict();
udict.setUstatus("a");
udict.setUvalue("已启用");
udictMapper.insert(udict);
}
// 删除操作
@Test
public void deleteDict() {
QueryWrapper wrapper = new QueryWrapper();
//设置userid值
wrapper.eq("dictid",465191484111454209L);
udictMapper.delete(wrapper);
}
} 

视频教程


