
- 还有视频讲解在我的B站-宝哥chbxw, 希望大家可以支持一下,谢谢。
- 前言
- 一、TableEnvironment
- 二、Table API
- 2.1、创建表
- 2.1.1、从文件中创建 Table(静态表)
- 2.1.2、从 DataStream 中创建 Table(动态表)
- 2.2、修改字段名
- 2.3、查询和过滤
- 2.4、分组聚合
- 2.5、UDF 自定义的函数
- 2.5.1、案例:使用 Table 完成基于流的 WordCount
- 2.6、Window
- 2.6.1、案例:统计最近 5 秒钟,每个基站的呼叫数量
- 三、Flink中**SQL**的Window
- 3.1、执行SQL
- 3.1.1、纯粹的SQL执行
- 3.1.2、TableAPI和sql混用
- 3.2、SQL中的Window
- 3.2.1、案例:统计最近每 5 秒中内,每个基站的通话成功时间总和
- 3.2.1.1、滚动窗口
- 3.2.1.2、滑动窗口
- 返回总目录
- 关注我的公众号【宝哥大数据】,更多干货
在 Spark 中有 DataFrame 这样的关系型编程接口,因其强大且灵活的表达能力,能够让用户通过非常丰富的接口对数据进行处理,有效降低了用户的使用成本。Flink 也提供了关系型编程接口 Table API 以及基于 Table API 的 SQL API,让用户能够通过使用结构化编程接口高效地构建 Flink 应用。同时 Table API 以及 SQL 能够统一处理批量和实时计算业务,无须切换修改任何应用代码就能够基于同一套 API 编写流式应用和批量应用,从而达到真正意义的批流统一。 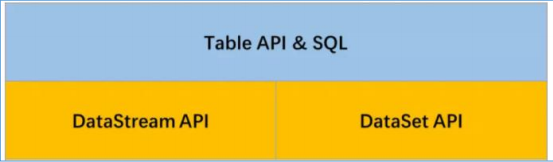 在Flink1.8架构里,如果用户需要同时流计算、批处理的场景下,用户需要维护两套代码,开发人员也要维护两套技术栈,非常繁琐。Flink社区很早就想将批数据看错一个有界的流数据,将批处理看作流计算的一个特例,从而实现流批统一,阿里巴巴的Blink在这方面做了大量工作,已经实现了Table API&SQL层的流批统一。并将Blink开源回馈给Flink社区。
在Flink1.8架构里,如果用户需要同时流计算、批处理的场景下,用户需要维护两套代码,开发人员也要维护两套技术栈,非常繁琐。Flink社区很早就想将批数据看错一个有界的流数据,将批处理看作流计算的一个特例,从而实现流批统一,阿里巴巴的Blink在这方面做了大量工作,已经实现了Table API&SQL层的流批统一。并将Blink开源回馈给Flink社区。
Blink架构如下图: 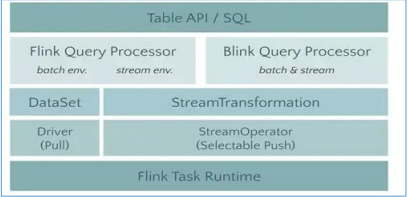
和 DataStream API 一样,Table API 和 SQL 中具有相同的基本编程模型。首先需要构建对应的 TableEnviroment 创建关系型编程环境,才能够在程序中使用 Table API 和 SQL来编写应用程序,另外 Table API 和 SQL 接口可以在应用中同时使用,Flink SQL 基于 Apache Calcite 框架实现了 SQL 标准协议,是构建在 Table API 之上的更高级接口。首先需要在环境中创建 TableEnvironment 对象,TableEnvironment 中提供了注册内部表、执行 Flink SQL 语句、注册自定义函数等功能。根据应用类型的不同,TableEnvironment创建方式也有所不同,但是都是通过调用 create()方法创建。流计算环境下创建 TableEnviroment:
//初始化Flink的Streaming(流计算)上下文执行环境
val streamEnv: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment
//初始化Table API的上下文环境
val tableEvn =StreamTableEnvironment.create(streamEnv)
在 Flink1.9 之后由于引入了 Blink Planner,还可以为:
val bsSettings = EnvironmentSettings.newInstance().useOldPlanner().inStreamingMode().build()
val bsTableEnv = StreamTableEnvironment.create(streamEnv, bsSettings)
注意:Flink 社区完整保留原有 Flink Planner (Old Planner),同时又引入了新的Blink Planner,用户可以自行选择使用 Old Planner 还是 Blink Planner。官方推荐暂时使用 Old Planner。
二、Table API依赖
org.apache.flink
flink-table-planner_2.11
1.10.1
org.apache.flink
flink-table-api-scala-bridge_2.11
1.10.1
在 Flink 中创建一张表有两种方法:
- 从一个文件中导入表结构(Structure)(常用于批计算)(静态)
- 从 DataStream 或者 DataSet 转换成 Table (动态)
Flink允许用户从本地或者分布式文件系统中读取和写入数据,在 Table API 中可以通过 CsvTableSource 类来创建,只需指定相应的参数即可。但是文件格式必须是 CSV 格式的。其 他 文 件 格 式 也 支 持 ( 在 Flink 还 有 Connector 的 来 支 持 其 他 格 式 或 者 自 定 义 TableSource)。
//读取数据
val tableSource = new CsvTableSource("/station.log",
Array[String]("f1", "f2", "f3", "f4", "f5", "f6"),
Array(Types.STRING, Types.STRING, Types.STRING, Types.STRING, Types.LONG, Types.LONG)
)
//注册一张表,方法没有返回值
tableEnv.registerTableSource("t_station_log", tableSource)
//可以使用SQL API
//打印表结构,或者使用Table API。需要得到Table对象
val table: Table = tableEnv.scan("t_station_log")
table.printSchema() //打印表结构
//注意:本案例的最后面不要 streamEnv.execute(),否则报错。因为没有其他流计算逻辑
前面已经知道 Table API 是构建在 DataStream API 和 DataSet API 之上的一层更高级的抽象,因此用户可以灵活地使用 Table API 将 Table 转换成 DataStream 或 DataSet 数据集,也可以将DataSteam或 DataSet数据集转换成 Table,这和 Spark 中的DataFrame和RDD的关系类似。
package com.chb.flink.table
import com.chb.flink.source.StationLog
import org.apache.flink.api.scala.typeutils.Types
import org.apache.flink.streaming.api.scala.{DataStream, StreamExecutionEnvironment}
import org.apache.flink.table.api.scala.StreamTableEnvironment
import org.apache.flink.table.api.{EnvironmentSettings, Table}
import org.apache.flink.table.sources.CsvTableSource
import org.apache.flink.types.Row
object TestCreateTableByDataStream {
def main(args: Array[String]): Unit = {
//使用Flink原生的代码创建TableEnvironment
//先初始化流计算的上下文
val streamEnv: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment
val settings: EnvironmentSettings = EnvironmentSettings.newInstance().useOldPlanner().inStreamingMode().build()
val tableEnv: StreamTableEnvironment = StreamTableEnvironment.create(streamEnv, settings)
// 隐式转换
import org.apache.flink.streaming.api.scala._
val stream: DataStream[StationLog] = streamEnv.socketTextStream("10.0.0.201", 8888)
.map(line => {
val arr = line.split(",")
new StationLog(arr(0).trim, arr(1).trim, arr(2).trim, arr(3).trim, arr(4).trim.toLong, arr(5).trim.toLong)
})
// 注册表
tableEnv.registerDataStream("t_stream", stream)
// 使用TableApi获取table对象
val table = tableEnv.scan("t_stream")
table.printSchema()
}
}
root
|-- sid: STRING
|-- callOut: STRING
|-- callIn: STRING
|-- callType: STRING
|-- callTime: BIGINT
|-- duration: BIGINT
// 修改字段名
import org.apache.flink.table.api.scala._ // 第二个隐式转换
val table = tableEnv.fromDataStream(stream, 'field1, 'field2, 'field3) // 注意格式
table.printSchema()
// 此处只会显示三个字段,
root
|-- field1: STRING
|-- field2: STRING
|-- field3: STRING
在 Table 对象上使用 select 操作符查询需要获取的指定字段,也可以使用filter或where方法过滤字段和检索条件,将需要的数据检索出来。
其中 toAppendStream 函数是把 Table 对象转换成 DataStream 对象。
val table = tableEnv.fromDataStream(stream)
//查询
tableEnv.toAppendStream[Row](
table.select('sid, 'callType as 'type, 'callTime, 'callOut))
.print()
// 过滤
tableEnv.toAppendStream[Row](
table.filter('callType === "success") //filter
.where('callType === "success")) //where
.print()
// 分组聚合
tableEnv.toRetractStream[Row](
table.groupBy("sid").select('sid, 'sid.count as 'logNum)
)
.filter(_._1 == true) 返回的如果是true才是Insert的数据
.print()
在代码中可以看出,使用 toAppendStream 和 toRetractStream 方法将 Table转换为DataStream[T]数据集,T 可以是 Flink 自定义的数据格式类型 Row,也可以是用户指定的数据 格 式 类 型 。 在 使 用 toRetractStream 方 法 时 , 返 回 的 数 据 类 型 结 果 为DataStream[(Boolean,T)],Boolean 类型代表数据更新类型,True 对应 INSERT 操作更新的数据,False 对应 DELETE 操作更新的数据。
用户可以在 Table API 中自定义函数类,常见的抽象类和接口是:
- ScalarFunction: 标量函数,是指返回一个值的函数。标量函数是实现将0,1,或者多个标量值转化为一个新值。
- TableFunction: 与标量函数相似之处是输入可以0,1,或者多个参数,但是不同之处可以输出任意数目的行数。返回的行也可以包含一个或者多个列。
- AggregateFunction: 用户自定义聚合函数聚合一张表(一行或者多行,一行有一个或者多个属性)为一个标量的值。
- TableAggregateFunction
用户自定义函数是非常重要的一个特征,因为他极大地扩展了查询的表达能力。 在大多数场景下,用户自定义函数在使用之前是必须要注册的。对于Scala的Table API,udf是不需要注册的。 调用TableEnvironment的registerFunction()方法来实现注册。Udf注册成功之后,会被插入TableEnvironment的function catalog,这样table API和sql就能解析他了。
2.5.1、案例:使用 Table 完成基于流的 WordCountpackage com.chb.flink.table
import org.apache.flink.api.common.typeinfo.TypeInformation
import org.apache.flink.streaming.api.scala.StreamExecutionEnvironment
import org.apache.flink.table.api.{EnvironmentSettings, Table, Types}
import org.apache.flink.table.api.scala.StreamTableEnvironment
import org.apache.flink.table.functions.TableFunction
import org.apache.flink.types.Row
/**
* UDF 自定义的函数
* 案例:使用 Table 完成基于流的 WordCount
*/
object TestUDFByWordCount {
//使用tableAPI实现WordCount
def main(args: Array[String]): Unit = {
//使用Flink原生的代码创建TableEnvironment
//先初始化流计算的上下文
val streamEnv: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment
val settings: EnvironmentSettings = EnvironmentSettings.newInstance().useOldPlanner().inStreamingMode().build()
val tableEnv: StreamTableEnvironment = StreamTableEnvironment.create(streamEnv, settings)
//两个隐式转换
import org.apache.flink.streaming.api.scala._
import org.apache.flink.table.api.scala._
//读取数据源
val stream: DataStream[String] = streamEnv.socketTextStream("10.0.0.201", 8888)
val table: Table = tableEnv.fromDataStream(stream, 'line)
//使用TableAPI切割单词,需要自定义一个切割单词的函数
val my_func = new MyFlatMapFunction //创建一个UDF
val result: Table = table.flatMap(my_func('line)).as('word, 'word_c)
.groupBy('word)
.select('word, 'word_c.sum as 'c)
tableEnv.toRetractStream[Row](result).filter(_._1 == true).print()
tableEnv.execute("table_api")
}
//自定义UDF
class MyFlatMapFunction extends TableFunction[Row] {
//定义函数处理之后的返回类型,输出单词和1
override def getResultType: TypeInformation[Row] = Types.ROW(Types.STRING(), Types.INT())
//函数主体
def eval(str: String): Unit = {
str.trim.split(" ").foreach(word => {
var row = new Row(2)
row.setField(0, word)
row.setField(1, 1)
collect(row)
})
}
}
}
Flink 支持 ProcessTime、EventTime 和 IngestionTime 三种时间概念,针对每种时间概念,Flink Table API 中使用 Schema 中单独的字段来表示时间属性,当时间字段被指定后,就可以在基于时间的操作算子中使用相应的时间属性。 在 Table API 中通过使用.rowtime来定义 EventTime字段,在ProcessTime时间字段名后使用.proctime后缀来指定 ProcessTime 时间属性
案例: 每隔5秒钟统计,每个基站的通话数量,假设数据是乱序。最多延迟3秒,需要水位线
package com.chb.flink.table
import com.chb.flink.source.StationLog
import org.apache.flink.streaming.api.TimeCharacteristic
import org.apache.flink.streaming.api.functions.timestamps.BoundedOutOfOrdernessTimestampExtractor
import org.apache.flink.streaming.api.scala.StreamExecutionEnvironment
import org.apache.flink.streaming.api.windowing.time.Time
import org.apache.flink.table.api.{EnvironmentSettings, Slide, Table, Tumble}
import org.apache.flink.table.api.scala.StreamTableEnvironment
import org.apache.flink.types.Row
object TestWindowByTableAPI {
//每隔5秒钟统计,每个基站的通话数量,假设数据是乱序。最多延迟3秒,需要水位线
def main(args: Array[String]): Unit = {
//使用Flink原生的代码创建TableEnvironment
//先初始化流计算的上下文
val streamEnv: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment
//定义采用EventTime作为时间语义
streamEnv.setStreamTimeCharacteristic(TimeCharacteristic.EventTime)
streamEnv.setParallelism(1)
val settings: EnvironmentSettings = EnvironmentSettings.newInstance().useOldPlanner().inStreamingMode().build()
val tableEnv: StreamTableEnvironment = StreamTableEnvironment.create(streamEnv, settings)
streamEnv.setStreamTimeCharacteristic(TimeCharacteristic.EventTime)
//两个隐式转换
import org.apache.flink.streaming.api.scala._
//读取数据源
val stream: DataStream[StationLog] = streamEnv.socketTextStream("10.0.0.201", 8888)
.map(line => {
var arr = line.split(",")
new StationLog(arr(0).trim, arr(1).trim, arr(2).trim, arr(3).trim, arr(4).trim.toLong, arr(5).trim.toLong)
})
//引入Watermark,让窗口延迟触发
.assignTimestampsAndWatermarks(new BoundedOutOfOrdernessTimestampExtractor[StationLog](Time.seconds(3)) {
override def extractTimestamp(element: StationLog) = {
element.callTime
}
})
// 第二个隐式转换, Table
import org.apache.flink.table.api.scala._
//从DataStream中创建动态的Table,并且可以指定EventTime是哪个字段
// .rowtime 设置EventTime, .proctime 设置ProcessTime,
var table: Table = tableEnv.fromDataStream(stream, 'sid, 'callOut, 'callInt, 'callType, 'callTime.rowtime)
//开窗,滚动窗口,第一种写法
// table.window(Tumble.over("5.second").on("callTime").as("window")) // 面向对象的开窗方法
//第二种写法
val result: Table = table.window(Tumble over 5.second on 'callTime as 'window)
.groupBy('window, 'sid) //必须使用两个字段分组,分别是窗口和基站ID
.select('sid, 'window.start, 'window.end, 'sid.count) //聚会计算
//打印结果
tableEnv.toRetractStream[Row](result)
.filter(_._1 == true)
.print()
tableEnv.execute("sql")
//如果是滑动窗口
// table.window(Slide over 10.second every 5.second on 'callTime as 'window)
// table.window(Slide.over("10.second").every("5.second").on("callTime").as("window"))
}
}
//读取数据
val tableSource = new CsvTableSource("D:\\Project\\MyProject\\FlinkProject\\src\\main\\resources\\station.log",
Array[String]("sid", "call_out", "call_in", "call_type", "call_time", "duration"),
Array(Types.STRING, Types.STRING, Types.STRING, Types.STRING, Types.LONG, Types.LONG)
)
//使用纯粹的SQL
//注册表
tableEnv.registerTableSource("t_station_log", tableSource)
//执行sql
val result: Table = tableEnv.sqlQuery("select sid,sum(duration) as d_c " +
"from t_station_log where call_type='success' group by sid")
//TableAPI和sql混用
val stream: DataStream[StationLog] = streamEnv.readTextFile(getClass.getResource("/station.log").getPath)
.map(line => {
val arr: Array[String] = line.split(",")
new StationLog(arr(0).trim, arr(1).trim, arr(2).trim, arr(3).trim, arr(4).trim.toLong, arr(5).trim.toLong)
})
val table: Table = tableEnv.fromDataStream(stream)
//执行sql
val result: Table = tableEnv.sqlQuery(s"select sid,sum(duration) as d_c from $table where callType='success' group by sid")
Flink SQL 也支持三种窗口类型,分别为 Tumble Windows、HOP Windows 和 Session Windows,其中 HOP Windows 对应 Table API 中的 Sliding Window,同时每种窗口分别有相应的使用场景和方法。
package com.chb.flink.table
import com.chb.flink.source.StationLog
import org.apache.flink.streaming.api.TimeCharacteristic
import org.apache.flink.streaming.api.functions.timestamps.BoundedOutOfOrdernessTimestampExtractor
import org.apache.flink.streaming.api.scala.StreamExecutionEnvironment
import org.apache.flink.streaming.api.windowing.time.Time
import org.apache.flink.table.api.scala.StreamTableEnvironment
import org.apache.flink.table.api.{EnvironmentSettings, Table, Tumble}
import org.apache.flink.types.Row
object TestTumbleWindowBySQL {
//每隔5秒钟统计,每个基站的通话数量,假设数据是乱序。最多延迟3秒,需要水位线
def main(args: Array[String]): Unit = {
//使用Flink原生的代码创建TableEnvironment
//先初始化流计算的上下文
val streamEnv: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment
//定义采用EventTime作为时间语义
streamEnv.setStreamTimeCharacteristic(TimeCharacteristic.EventTime)
streamEnv.setParallelism(1)
val settings: EnvironmentSettings = EnvironmentSettings.newInstance().useOldPlanner().inStreamingMode().build()
val tableEnv: StreamTableEnvironment = StreamTableEnvironment.create(streamEnv, settings)
//两个隐式转换
import org.apache.flink.streaming.api.scala._
import org.apache.flink.table.api.scala._
//读取数据源
val stream: DataStream[StationLog] = streamEnv.socketTextStream("10.0.0.201", 8888)
.map(line => {
var arr = line.split(",")
new StationLog(arr(0).trim, arr(1).trim, arr(2).trim, arr(3).trim, arr(4).trim.toLong, arr(5).trim.toLong)
})
//引入Watermark,让窗口延迟触发
.assignTimestampsAndWatermarks(new BoundedOutOfOrdernessTimestampExtractor[StationLog](Time.seconds(3)) {
override def extractTimestamp(element: StationLog) = {
element.callTime
}
})
//滚动窗口,窗口大小是5秒,需求:统计每5秒内,每个基站的成功通话时长总和
//注册一张表,并且指定EventTime是哪个字段
tableEnv.registerDataStream("t_station_log", stream, 'sid, 'callOut, 'callInt, 'callType, 'callTime.rowtime, 'duration)
val result: Table = tableEnv.sqlQuery("select sid,sum(duration) as sd " +
"from t_station_log " +
"where callType='success' " +
"group by tumble(callTime,interval '5' second),sid")
//打印结果
tableEnv.toRetractStream[Row](result)
.filter(_._1 == true)
.print()
tableEnv.execute("sql")
}
}
package com.chb.flink.table
import com.chb.flink.source.StationLog
import org.apache.flink.streaming.api.TimeCharacteristic
import org.apache.flink.streaming.api.functions.timestamps.BoundedOutOfOrdernessTimestampExtractor
import org.apache.flink.streaming.api.scala.StreamExecutionEnvironment
import org.apache.flink.streaming.api.windowing.time.Time
import org.apache.flink.table.api.scala.StreamTableEnvironment
import org.apache.flink.table.api.{EnvironmentSettings, Table}
import org.apache.flink.types.Row
object TestSlidingWindowBySQL {
//每隔5秒钟统计,每个基站的通话数量,假设数据是乱序。最多延迟3秒,需要水位线
def main(args: Array[String]): Unit = {
//使用Flink原生的代码创建TableEnvironment
//先初始化流计算的上下文
val streamEnv: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment
//定义采用EventTime作为时间语义
streamEnv.setStreamTimeCharacteristic(TimeCharacteristic.EventTime)
streamEnv.setParallelism(1)
val settings: EnvironmentSettings = EnvironmentSettings.newInstance().useOldPlanner().inStreamingMode().build()
val tableEnv: StreamTableEnvironment = StreamTableEnvironment.create(streamEnv, settings)
//两个隐式转换
import org.apache.flink.streaming.api.scala._
import org.apache.flink.table.api.scala._
//读取数据源
val stream: DataStream[StationLog] = streamEnv.socketTextStream("10.0.0.201", 8888)
.map(line => {
var arr = line.split(",")
new StationLog(arr(0).trim, arr(1).trim, arr(2).trim, arr(3).trim, arr(4).trim.toLong, arr(5).trim.toLong)
})
//引入Watermark,让窗口延迟触发
.assignTimestampsAndWatermarks(new BoundedOutOfOrdernessTimestampExtractor[StationLog](Time.seconds(3)) {
override def extractTimestamp(element: StationLog) = {
element.callTime
}
})
//滑动窗口,窗口大小是10秒,滑动步长是5秒,需求:每隔5秒,统计10秒内,每个基站的成功通话时长总和
//注册一张表,并且指定EventTime是哪个字段
tableEnv.registerDataStream("t_station_log", stream, 'sid, 'callOut, 'callInt, 'callType, 'callTime.rowtime, 'duration)
val result: Table = tableEnv.sqlQuery("select sid, hop_start(callTime,interval '5' second,interval '10' second),hop_end(callTime,interval '5' second,interval '10' second)" +
",sum(duration) " +
"from t_station_log " +
"where callType='success' " +
"group by hop(callTime,interval '5' second,interval '10' second),sid")
//打印结果
tableEnv.toRetractStream[Row](result)
.filter(_._1 == true)
.print()
tableEnv.execute("sql")
}
}


