- 一、SparkSQL自定义外部数据源
- 1.1、External DataSource
- 1.1、主要两个类为: `BaseRelation` 和 `RelationProvider`
- 1.2、BaseRelation
- 1.2.1、`BaseRelation`是外部数据源的抽象,里面主要存放了`schema`的映射 。
- 1.2.2、从外部数据源加载(读取)数据和保存(写入)数据时,提供不同接口实现
- 1.2.2.1、 加载数据接口
- 1.2.2.2、 保存数据接口
- 1.3、RelationProvider
- 1.2.3、SparkSQL集成Elasticsearch 代码结构:
- 1.2.4、SparkSQL集成Kudu 代码结构:
- 1.4、自定义HBaseRelation
- 1.5、自定义 DefaultSource
- 1.6、测试功能代码
- 1.7、注册数据源
- 二、条件过滤
- 2.1、Hbase Filter
- 2.1.1、从HBase表读取数据时,设置过滤条件:【 `modified < '2019-09-01'` 】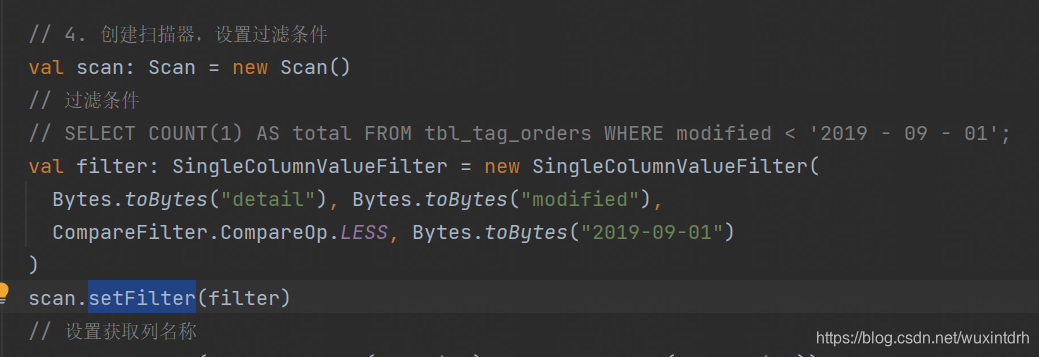
- 2.2、HbaseRelation优化,实现Filter
标签模型编码中需要从HBase表读写数据,编写 HBaseTools 工具类,其中提供 read 和write 方法,传递参数读写表的数据,但是能否实现类似SparkSQL读写MySQL数据库表数据时如下格式:
自从Spark 1.3的发布,Spark SQL开始正式支持外部数据源。Spark SQL开放了一系列接入外部数据源的接口,来让开发者可以实现,接口在 org.apache.spark.sql.sources 包下:interfaces.scala 。 https://github.com/apache/spark/blob/branch-2.2/sql/core/src/main/scala/org/apache/spark/sql/sources/interfaces.scala
BaseRelation 和 RelationProvider
&mesp;如果要实现一个外部数据源,比如hbase数据源,支持Spark SQL操作HBase数据库。那么就必须定义HBaseRelation来继承BaseRelation,同时也要定义DefaultSource实现一个RelationProvider。
- 1)、BaseRelation
- 代表了一个抽象的数据源;
- 该数据源由一行行有着已知schema的数据组成(关系表);
- 展示从DataFrame中产生的底层数据源的关系或者表;
- 定义如何产生schema信息;
- 2)、RelationProvider
- 顾名思义,根据用户提供的参数(parameters)返回一个数据源(BaseRelation)
- 一个Relation的提供者,创建BaseRelation
下图表示从SparkSQL提供 外部数据源(External DataSource)加载数据 时,需要继承的类说明如下:
BaseRelation是外部数据源的抽象,里面主要存放了schema的映射 。
abstract class BaseRelation {
def sqlContext: SQLContext
def schema: StructType
}
// 如果自定义Relation,必须重写schema,就是必须描述对于外部数据源的Schema。
提供4种 Scan 策略,加载数据
默认的Scan为 TableScan ,其中方法 buildScan :定义如何查询外部数据源
其他加载数据Trait的Scan说明
- PrunedScan :列裁剪的,可以传入指定的列,不需要的列不会从外部数据源加载。
- PrunedFilteredScan :列裁剪➕过滤,在列裁剪的基础上,并且加入Filter机制,在加载数据也的时候就进行过滤,而不是在客户端请求返回时做Filter。
- CatalystScan :Catalyst的支持传入expressions来进行Scan,支持列裁剪和Filter。
InsertableRelation :保存数据的Relation
RelationProvider : 获取参数列表,返回一个BaseRelation对象 。要实现这个接口,需要接受 传入的参数 ,来生成对应的·、、External Relation,就是 一个反射生产外部数据源Relation的接口 ,接口Trait定义如下:
上述表示加载数据时构建Relation对象的Provider为RelationProvider,同样保存数据时构建Relation对象的Provider为 CreatableRelationProvider ,代码如下:
按照上述接口说明,实现自定义外部数据源从HBase表读写数据,包【 com.chb.tags 】结构如下:
类的继承结构图,如下所示:
自定义 HBaseRelation 类,继承 BaseRelation 、 TableScan 和InsertableRelation ,此外实现序列化接口 Serializable ,所有类声明如下,其中实现 Serializable 接口为了保证对象可以被序列化和反序列化。
package com.chb.spark.hase
import org.apache.hadoop.conf.Configuration
import org.apache.hadoop.hbase.client.{Put, Result, Scan}
import org.apache.hadoop.hbase.io.ImmutableBytesWritable
import org.apache.hadoop.hbase.mapreduce.{TableInputFormat, TableOutputFormat}
import org.apache.hadoop.hbase.protobuf.ProtobufUtil
import org.apache.hadoop.hbase.util.{Base64, Bytes}
import org.apache.spark.rdd.RDD
import org.apache.spark.sql.{DataFrame, Row, SQLContext}
import org.apache.spark.sql.sources.{BaseRelation, InsertableRelation, TableScan}
import org.apache.spark.sql.types.StructType
/**
* 自定义外部数据源:从HBase表加载数据和保存数据值HBase表
*/
class HbaseRelation(context: SQLContext,
params: Map[String, String],
userSchema: StructType
) extends BaseRelation with TableScan with InsertableRelation with Serializable {
// 将读写HBase表数据时参数属性定义为常量,方便后续使用:
// 连接HBase数据库的属性名称
val HBASE_ZK_QUORUM_KEY: String = "hbase.zookeeper.quorum"
val HBASE_ZK_QUORUM_VALUE: String = "zkHosts"
val HBASE_ZK_PORT_KEY: String = "hbase.zookeeper.property.clientPort"
val HBASE_ZK_PORT_VALUE: String = "zkPort"
val HBASE_TABLE: String = "hbaseTable"
val HBASE_TABLE_FAMILY: String = "family"
val SPERATOR: String = ","
val HBASE_TABLE_SELECT_FIELDS: String = "selectFields"
val HBASE_TABLE_ROWKEY_NAME: String = "rowKeyColumn"
/**
* SQLContext实例对象
*/
override def sqlContext: SQLContext = context
/**
* DataFrame的Schema信息
*/
override def schema: StructType = userSchema
/**
* 如何从HBase表中读取数据,返回RDD[Row]
*/
override def buildScan(): RDD[Row] = {
// 1. 设置HBase中Zookeeper集群信息
val conf: Configuration = new Configuration()
conf.set(HBASE_ZK_QUORUM_KEY, params(HBASE_ZK_QUORUM_VALUE))
conf.set(HBASE_ZK_PORT_KEY, params(HBASE_ZK_PORT_VALUE))
// 2. 设置读HBase表的名称
conf.set(TableInputFormat.INPUT_TABLE, params(HBASE_TABLE))
// 3. 设置读取列簇和列名称
val scan: Scan = new Scan()
// 3.1. 设置列簇
val familyBytes = Bytes.toBytes(params(HBASE_TABLE_FAMILY))
scan.addFamily(familyBytes)
// 3.2. 设置列名称
val fields = params(HBASE_TABLE_SELECT_FIELDS).split(SPERATOR)
fields.foreach { field =>
scan.addColumn(familyBytes, Bytes.toBytes(field))
}
// 3.3. 设置scan过滤
conf.set(
TableInputFormat.SCAN, //
Base64.encodeBytes(ProtobufUtil.toScan(scan).toByteArray) //
)
// 4. 调用底层API,读取HBase表的数据
val datasRDD: RDD[(ImmutableBytesWritable, Result)] =
sqlContext.sparkContext
.newAPIHadoopRDD(
conf,
classOf[TableInputFormat],
classOf[ImmutableBytesWritable],
classOf[Result]
)
// 5. 转换为RDD[Row]
val rowsRDD: RDD[Row] = datasRDD.map { case (_, result) =>
// 5.1. 列的值
val values: Seq[String] = fields.map { field =>
Bytes.toString(result.getValue(familyBytes,
Bytes.toBytes(field)))
}
// 5.2. 生成Row对象
Row.fromSeq(values)
}
// 6. 返回
rowsRDD
}
/**
* 将数据DataFrame写入到HBase表中
*
* @param data 数据集
* @param overwrite 保存模式
*/
override def insert(data: DataFrame, overwrite: Boolean): Unit = {
// 1. 数据转换
val columns: Array[String] = data.columns
val putsRDD: RDD[(ImmutableBytesWritable, Put)] = data.rdd.map {
row =>
// 获取RowKey
val rowKey: String = row.getAs[String](params(HBASE_TABLE_ROWKEY_NAME))
// 构建Put对象
val put = new Put(Bytes.toBytes(rowKey))
// 将每列数据加入Put对象中
val familyBytes = Bytes.toBytes(params(HBASE_TABLE_FAMILY))
columns.foreach { column =>
put.addColumn(
familyBytes, Bytes.toBytes(column), //
Bytes.toBytes(row.getAs[String](column)) //
)
}
// 返回二元组
(new ImmutableBytesWritable(put.getRow), put)
}
// 2. 设置HBase中Zookeeper集群信息
val conf: Configuration = new Configuration()
conf.set(HBASE_ZK_QUORUM_KEY, params(HBASE_ZK_QUORUM_VALUE))
conf.set(HBASE_ZK_PORT_KEY, params(HBASE_ZK_PORT_VALUE))
// 3. 设置读HBase表的名称
conf.set(TableOutputFormat.OUTPUT_TABLE, params(HBASE_TABLE))
// 4. 保存数据到表
putsRDD.saveAsNewAPIHadoopFile(
s"/apps/hbase/${params(HBASE_TABLE)}-" +
System.currentTimeMillis(),
classOf[ImmutableBytesWritable], //
classOf[Put], //
classOf[TableOutputFormat[ImmutableBytesWritable]], //
conf //
)
}
}
自定义类 DefaultSource,继承 RelationProvider 、CreatableRelationProvider 便于读写数据,此外继承 Serializable为了更好序列化和反序列化对象
package com.chb.spark.hase
import org.apache.spark.sql.{DataFrame, SQLContext, SaveMode}
import org.apache.spark.sql.sources.{BaseRelation, CreatableRelationProvider, RelationProvider}
import org.apache.spark.sql.types.{StringType, StructField, StructType}
/**
* 自定义外部数据源HBase,提供BaseRelation对象,用于加载数据和保存数据
*/
class DefaultSource extends RelationProvider with CreatableRelationProvider with Serializable {
// 参数信息
val HBASE_TABLE_SELECT_FIELDS: String = "selectFields"
val SPERATOR: String = ","
/**
* 返回BaseRelation实例对象,提供加载数据功能
*
* @param sqlContext SQLContext实例对象
* @param parameters 参数信息
* @return
*/
override def createRelation(sqlContext: SQLContext, parameters: Map[String, String]):
BaseRelation = {
// 1. 定义Schema信息
val schema: StructType = StructType(
parameters(HBASE_TABLE_SELECT_FIELDS)
.split(SPERATOR)
.map { field =>
StructField(field, StringType, nullable = true)
}
)
// 2. 创建HBaseRelation对象
val relation = new HbaseRelation(sqlContext, parameters, schema)
// 3. 返回对象
relation
}
/**
* 返回BaseRelation实例对象,提供保存数据功能
*
* @param sqlContext SQLContext实例对象
* @param mode 保存模式
* @param parameters 参数
* @param data 数据集
* @return
*/
override def createRelation(sqlContext: SQLContext, mode: SaveMode, parameters: Map[String, String], data: DataFrame): BaseRelation = {
// 1. 创建HBaseRelation对象
val relation = new HbaseRelation(sqlContext, parameters,
data.schema)
// 2. 插入数据
relation.insert(data, overwrite = true)
// 3. 返回对象
relation
}
}
package com.chb.tags.test.hbase
import org.apache.spark.sql.{DataFrame, SaveMode, SparkSession}
/**
* 测试自定义外部数据源实现从HBase表读写数据接口
*/
object HBaseSQLTest {
def main(args: Array[String]): Unit = {
val spark = SparkSession.builder()
.appName(this.getClass.getSimpleName.stripSuffix("$"))
.master("local[4]")
.config("spark.serializer", "org.apache.spark.serializer.KryoSerializer")
.getOrCreate()
import spark.implicits._
// 读取数据
val usersDF: DataFrame = spark.read
.format("com.chb.tags.spark.hbase")
.option("zkHosts", "ch1")
.option("zkPort", "2181")
.option("hbaseTable", "tbl_tag_users")
.option("family", "detail")
.option("selectFields", "id,gender")
.load()
usersDF.printSchema()
usersDF.cache()
usersDF.show(10, truncate = false)
// 保存数据
usersDF.write
.mode(SaveMode.Overwrite)
.format("com.chb.tags.spark.hbase")
.option("zkHosts", "chb")
.option("zkPort", "2181")
.option("hbaseTable", "tbl_users")
.option("family", "info")
.option("rowKeyColumn", "id")
.save()
spark.stop()
}
}
在SparkSQL提供外部数据源接口中提供 DataSourceRegister 类,实现 shortName 方法,方便调用函数使用简写名称:
trait DataSourceRegister {
/**
* The string that represents the format that this data source provider
uses. This is
* overridden by children to provide a nice alias for the data source.
For example:
*
* {{{
* override def shortName(): String = "parquet"
* }}}
*
* @since 1.5.0
*/
def shortName(): String
}
默认数据源类 DefaultSource ,继承 DataSourceRegister ,实现其中 shortame 方法,核心代码:
/**
* 自定义外部数据源HBase,提供BaseRelation对象,用于加载数据和保存数据
*/
class DefaultSource extends RelationProvider
with CreatableRelationProvider with DataSourceRegister with
Serializable{
/**
* 数据源使用简短名称
*/
override def shortName(): String = "hbase"
}
需要进行相关配置,实现如下方式加载与保存数据至HBase:
将实现SparkSQL外部数据源接口类: DefaultSource 进行注册,方便开发使用,首先看看SparkSQL与Kafka集成时注册方式如下:
所以在项目【 resources 】目录下创建库目录【 META-INF/services 】,并且创建文件【 org.apache.spark.sql.sources.DataSourceRegister】,内容为数据源主类【 com.chb.tags.spark.hbase.DefaultSource 】,如下图:
注意:在资源文件目录 resources 下创建目录【 META-INF/services 】为两层目录,不要写错。
二、条件过滤在开发 商业属性(消费特征)标签 时,每个标签计算时处理【 最近半年内订单数据 】,需要如下图所示:
所以在从数据源中读取数据时,需要先设置过滤条件(filter)再读取(read)数据。
在【订单表】数据中字段【modified】标识了数据最后修改时间,可以以此作为数据所属时间范围的判断。
需要修改SparkSQL外部数据源HBase开发接口实现类代码,完成设置过滤条件筛选数据的功能。
2.1、Hbase Filter 在HBase中提供 过滤器 ,在读取扫描数据时进行过滤,其中SingleColumnValueFilter 针对 某个字段的值进行比较过滤 获取数据,支持如下几种比较操作 CompareOp :
public enum CompareOp {
/** less than */
LESS,
/** less than or equal to */
LESS_OR_EQUAL,
/** equals */
EQUAL,
/** not equal */
NOT_EQUAL,
/** greater than or equal to */
GREATER_OR_EQUAL,
/** greater than */
GREATER,
/** no operation */
NO_OP,
}
枚举比较器 CompareOp 中各个枚举的含义:
构建 SingleColumnValueFilter 实例对象,构造方法如下:
在MySQL数据库中针对订单表【 tbl_tag_orders 】数据进行如下查询统计。
SELECT MIN(modified) AS min_date, MAX(modified) AS max_date FROM
tbl_tag_orders ;
/*
+---------------------+---------------------+
| min_date | max_date |
+---------------------+---------------------+
| 2019-07-19 00:56:42 | 2019-09-25 22:40:55 |
+---------------------+---------------------+
*/
SELECT COUNT(1) AS total FROM tbl_tag_orders WHERE modified >= '2019-09-01'
;
/*
+--------+
| total |
+--------+
| 113735 |
+--------+
*/
SELECT COUNT(1) AS total FROM tbl_tag_orders WHERE modified
关注
打赏


