
1.ES 8.2 版本集群,从10节点扩到20节点(变更,目标替换老的10个节点,先扩容新节点再下掉老节点)
2.挪数据执行exclude API,排除老节点IP,设置迁移速率为800Mb/s,默认40Mb/s
异常1.迁移过程中突然不再recovery,且老节点上依然有数据
2.发现出现一些pending task(node left/挪数据暂停...)
3.节点日志中出现 failed to process cluster event (clear-voting-config-exclusions) within 30s;还有 index not found异常;
4.集群依然是green
5.indices中的doc数量两次请求不一样(猜测脑裂)
6.pending task 30min 依然无法完成,确认无法自动恢复


1.假定脑裂,即需要将部分节点先孤立,再加回集群即可恢复,由于不知道脑裂的哪批节点,只能保留现有的master节点,一个个操作其他节点。
风险评估:如果选择的master节点最终的term周期并不是最大的,可能会有丢数据风险;进入ES的容器可以发现,data目录和write目录都多了个lock文件,加上了锁,保证了数据的安全。此时联系用户停止数据写入(发现用户已经没有任何写入了),此时可以把锁全部干掉,然后任意一个master候选节点成为master都不会丢数据,哪怕term不是最大的。
注:如果有写入,可能会出现master候选节点信息不完全一致(没来得及同步完全),在手动随机选master节点后导致数据丢失。
2.参考官方文档:elasticsearch-node | Elasticsearch Guide [8.2] | Elastic
执行unsafe查看term任期,降低风险,还是尽量选最大的;
执行detach,将节点孤立;
重启节点(pod)重新加入集群;
小插曲怀疑是由于master候选节点是双数导致了master vote列表出现小于一半的情况,导致节点加入集群异常;
尝试加一个node,从20-->21
结论:节点无法加入集群,测试失败,无法快速恢复
处理1.执行 执行 ./elasticsearch-node unsafe-bootstrap

删掉 /usr/share/elasticsearch/data/node.lock
继续执行 ./elasticsearch-node unsafe-bootstrap
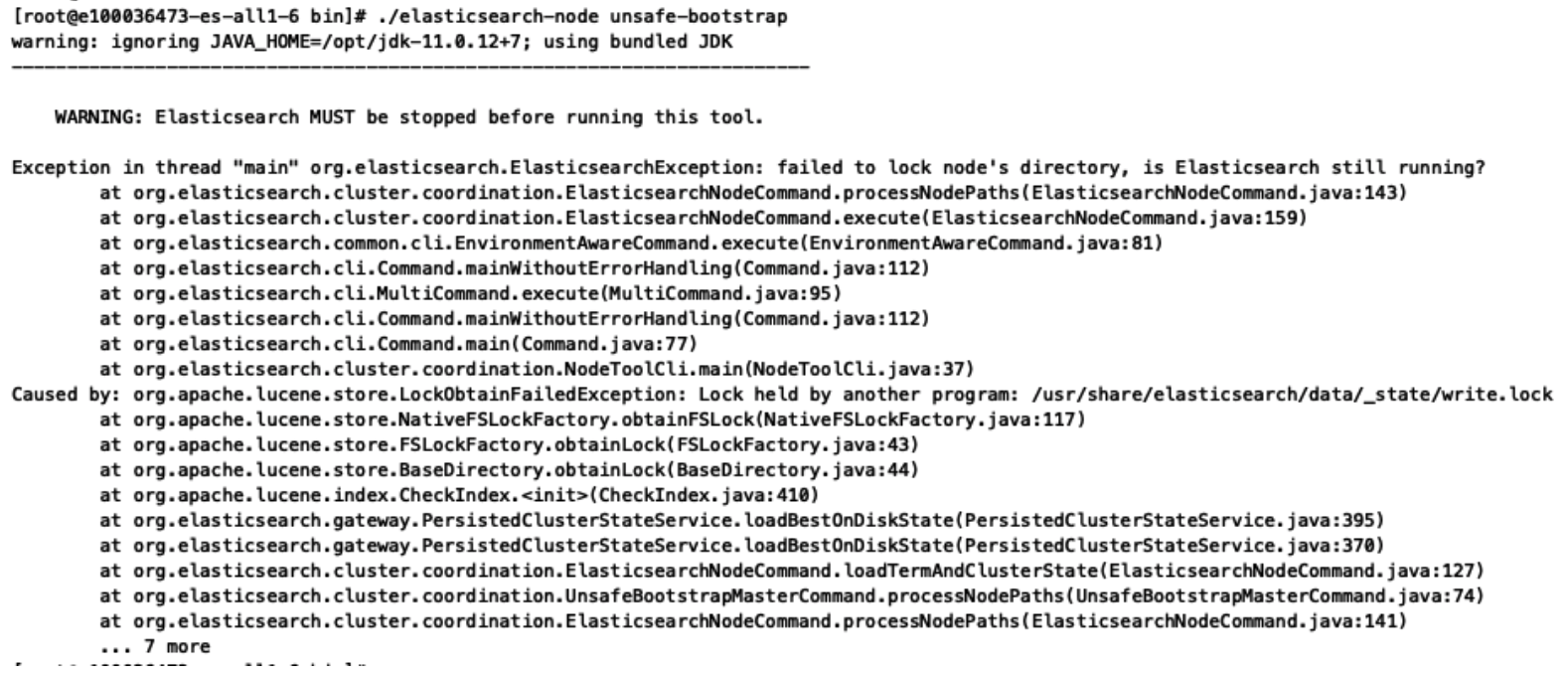
继续删 /usr/share/elasticsearch/data/_state/write.lock
继续执行 ./elasticsearch-node unsafe-bootstrap
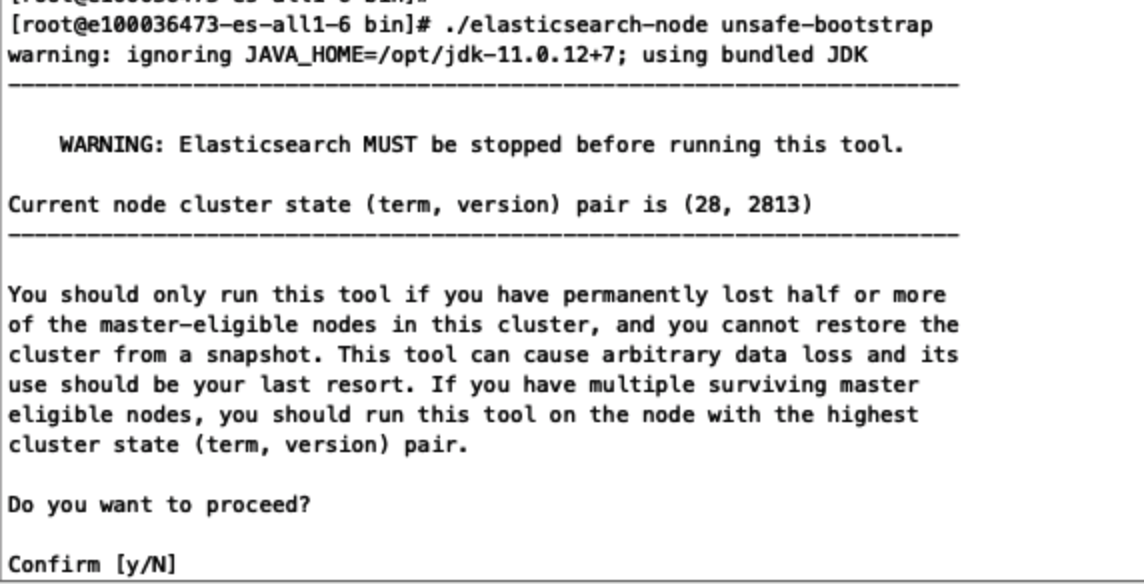
选择N
找到term最大的再选择y
2.节点逐一 ./bin/elasticsearch-node detach-cluster (不包括master节点),detach之后重启节点,观察,节点会加入集群。
原理分析// TODO

