springMVC是用来负责管理页面和后台的交互的。他就像是一个管家一样。什么事先经过我,我我虽然不能处理,但是我能给你找人处理。这里我把springMVC称为是老管家。
# # 老管家都干了什么事呢?
首先是将前端的请求页面拦截下来,因为我们在前端URL地址栏输入请求地址,是希望后台给我们处理的。不使用框架的话,就直接处理,但是处理起来过程有点麻烦。
- 1. 想要让老管家来管这件事,就要找老管家来:(引入springMVC的相关jar包,或者使用Maven的话,就引入相关的依赖)。于是老管家来了。
老管家干的第一件事是拦截请求,这要怎么做呢?
- 2. 在web.xml文件中加入配置,这样请求就可以给老管家管理了
springServlet
org.springframework.web.servlet.DispatcherServlet
contextConfigLocation
classpath:spring/applicationContext.xml
1
springServlet
/
- 上边的配置文件提到了springMVC的配置文件。这个配置文件是要加载进去的。
application/json;charset=UTF-8
下边再讲 视图解析器是干什么用的。
以上工作做完,老管家能干活了。
至于怎么干活,我举个栗子
请求可以当做是上家,老管家是中间人,真正干活的服务器是下家。请求过来,被老管家发现,然后就要替上家找联系人。
这个过程是通过 控制器完成的:也就是controller类
import org.springframework.stereotype.Controller;
import org.springframework.web.bind.annotation.RequestMapping;
//这个@Controller相当于是暗号,有了这个暗号,才知道这是干什么的。而这个暗号就是说这是
//controller
@Controller
//下边的是明确自己是干什么活处理什么请求的 首先这是包路径
@RequestMapping("user")
public class LoginController {
//下边的是明确自己是干什么活处理什么请求的 首先这也会一个路径。
//到这里为止,可以和上边提到的视图解析器对应起来了
//比方说来了一个请求,老管家是怎么精准的找到下家又不犯错误的呢
// 请求是这样的http://localhost:8080/user/login
//
@RequestMapping("login")
public String login(){
System.out.println("000");
//这个会被老管家拼装起来,这就是视图解析器的作用了,/WEB-INF/views/success.jsp
//要找的就是这个返回页面,经过一些列的操作后,比方说数据的处理呀,完了将这个页面返回去。
//上边说的数据的处理是指一些复杂的服务层调用,服务层再调用数据访问层,最后将数据塞给页面
return "success";
}
}
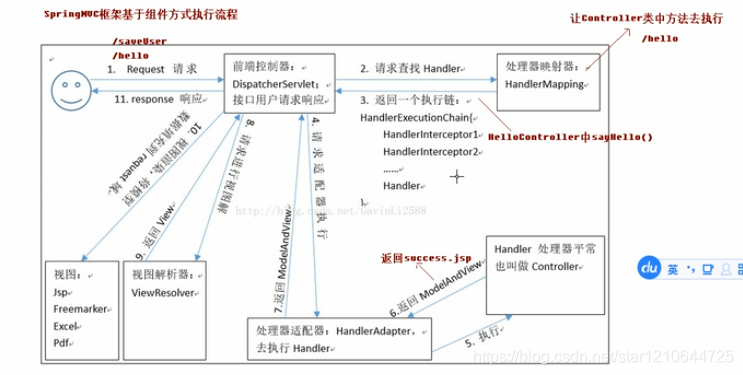
最后再补充一下执行流程把。我觉得这个有帮助我们自己搭环境,也有助于帮助我们理解springMVC,有助于帮助我们排错。
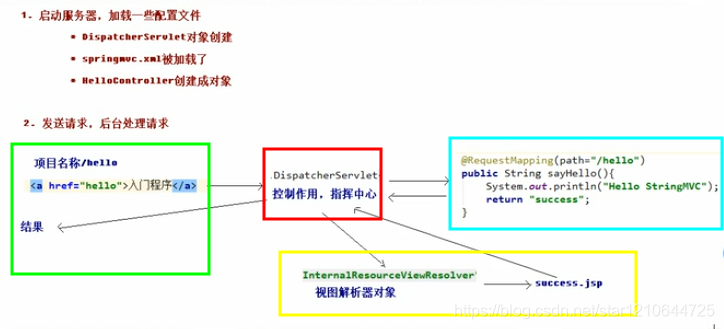
OK我根据框来讲解一下,可以看到四个颜色不同的框,这四个框包括了整个springMVC的流程。
首先,绿色代表的是前端页面,前端请求,和这部分相关的就是返回页面。
然后,红色代表的是控制器,这个是和web.xml配置有关系的,请求能被拦下来,完全是通过web.xml配置来做到的。这部分还和后边的蓝色框有关系,因为在web.xml文件里边加载了和蓝色框相关的配置文件。
然后,蓝色框通过web.xml加载了自己配置文件,配置文件里边包括开启扫描。蓝色框里边完成的是让请求和处理形成以一个一个的映射。蓝色框处理完了将处理结果返回给前端控制器,也就是红色框,红色框知道请求处理完了。
最后,黄色框,里边是返回的页面,蓝色框处理完了以后,会告诉红色框,我处理完了,你去找哪个哪个页面把。这个是由视图解析器来完成的。最后红色框将最终绿色框想要的结果返回,然后由浏览器渲染结果页面。整个结果完成。
更加具体的执行流程,基于组件来讲解: