

关注我,每天分享软件测试技术干货、面试经验,想要领取测试资料、进入软件测试学习交流群的可以直接私信我哦~~
appium原理调用 Android adb 完成基本的系统操作
向 Android 上部署 BootStrap.jar
BootStrap.jar Forward Android 的 4723 端口到 PC 机器上
PC 上监听端口接收请求,使用 webdriver 协议
分析命令并通过 forward 端口发给 BootStrap.jar
BootStrap.jar 接收请求并把命令发给 UIAutoMator
UIAutoMator 执行命令
脚本请求->4723端口appium server->解析参数给pc端4724端口->发送给设备4724端口->通过设备4724端口发送给bootstrap.jar->bootstrap.jar把命令发给uiautomator
1、脚本请求->4723端口appium server
开启appium server,默认监听4723端口,基于WebDriver协议。
脚本与appium server通信实际上是一个HTTP request请求给appium server,在请求的body中,会以WebDriver Wire协议规定的JSON格式的字符串来告诉appium服务我们希望设备接下来做什么事情。
desired capabilities :key-value对象,告诉server本次测试的上下文。进行浏览器测试还是移动端测试,若是移动端测试是android还是ios,及app指定等设置信息
2、解析参数给pc端4724端口->发送给设备4724端口->通过设备4724端口发给bootstrap.jar->bootstrap.jar把命令发给uiautomator
selenium原理运行用 Python 写好的 Selenium 脚本,它会像 Web Service 中发送一个 HTTP 请求;
浏览器驱动中的 Web Service 会根据这个请求生成对应的 JS 脚本,因为不同的浏览器,相同的操作生成的 JS 脚本会有所不同,因此不同的浏览器要有不同的驱动;
JS 脚本驱动浏览器,产生各种操作,并返回给 Web Service;
Web Service 将结果通过 HTTP 响应的形式返回给客户端;
selenium的定位方式ID定位:driver.find_element_by_id(“kw”)
name定位:driver.find_element_by_name(“wd”)
class name定位:driver.find_element_by_class_name(“s_ipt”)
tage name定位:元素的标签名,比如input标签 driver.find_element_by_tag_name()
link_text和partial_link_text:link_text和partial_link_text是作用于链接a标签的,link_text用于全部匹配文本值,partial_link_text用于部分匹配文本值。
css定位:通过组合的方式进行定位 driver.find_element_by_css_selector(css表达式)
xpath定位:find_element_by_xpath(xpath表达式)
绝对定位 (/):严格按照路径、同级元素的位置来定位
相对定位(//):有一个参照物 不考虑路径和位置,只考虑:有还是没有!! 以//开头 //标签名[@属性名称=值]
UI 自动化测试中,如何做集群?
Selenium Grid,分布式执行用例
Appium 使用 STF 管理多设备
Docker+K8S 管理集群
测试理论:隐藏得比较深的bug、影响比较大的bug、处理过程比较曲折的bug。根据自己的经验描述:如何发现的、如何处理、影响、结果、反思。
举例说明:如升级版本兼容性问题、接口安全性问题、数据库安全性问题、服务器资源占用溢出问题、代码逻辑问题等
app兼容性:系统兼容(ios、安卓)、机型兼容(iPhone、华为、小米、三星、vivo、OPPO)、分辨率兼容、软件本身向前向后兼容
web端测试和app端测试差异:系统结构方面
Web 项目,b/s架构,基于浏览器的;Web 测试只要更新了服务器端,客户端就会同步会更新;
App 项目,c/s结构的,必须要有客户端;App 修改了服务端,则客户端用户所有核心版本都需要进行回归测试一遍;
兼容方面
Web项目:a. 浏览器(火狐、谷歌、IE等)b. 操作系统(Windows7、Windows10、Linux等)
App项目:a. 设备系统: iOS(ipad、iphone)、Android(三星、华为、联想等) 、Windows(Win7、Win8)、OSX(Mac)b. 手机设备可根据 手机型号、分辨率不同
性能方面
web项目 需监测 响应时间、CPU、Memory
app项目 除了监测 响应时间、CPU、Memory外,还需监测流量、电量等
相对于 Web 项目,APP有专项测试
干扰测试:中断,来电,短信,关机,重启等
弱网络测试(模拟2g、3g、4g,wifi网络状态以及丢包情况);网络切换测试(网络断开后重连、3g切换到4g/wifi 等)
安装、更新、卸载
安装:需考虑安装时的中断、弱网、安装后删除安装文件等情况
卸载:需考虑 卸载后是否删除 App 相关的文件
更新:分强制更新、非强制更新、增量包更新、断点续传、弱网状态下更新
界面操作:关于手机端测试,需注意手势,横竖屏切换,多点触控,前后台切换
安全测试:安装包是否可反编译代码、安装包是否签名、权限设置,例如访问通讯录等
边界测试:可用存储空间少、没有SD卡/双SD卡、飞行模式、系统时间有误、第三方依赖(QQ、微信登录)等
权限测试:设置某个 App 是否可以获取该权限,例如是否可访问通讯录、相册、照相机等
测试用例: 登录界面:功能测试:正确输入、为空输入、字符类型校验、长度校验、密码是否加密显示、大写提示、跳转页面是否成功、登出后用另一个账号登录
UI:界面布局合理、风格统一、界面文字简洁好理解、没有错别字
性能测试:打开登录页面需要几秒、点击登录跳转首页需要几秒、多次点击、多人点击
安全性:用户名和密码是否加密发送给服务器、错误登录的次数限制(防止暴力破解)、一台机器登录多个用户、一个用户多方登录、检查元素能否看到密码
兼容性测试:不同浏览器、不同的平台(Windows、Mac)、移动设备能否工作
易用性:输入框可否tab键切换、回车能否登录等
linux打印第5行
sed -n ‘5p’ 1.txt
打印空行的行号
awk ‘if {NF==0} print NR’ 1.txt
sed -n ‘/^$/=’ 1.txt -n 对匹配行处理 =打印匹配行的行号 p打印匹配到的内容
删除空行
sed ‘/^$/ d’ 1.txt
sed ‘/^#/ d’ employee.txt 删除所有注释行
打印不含this的行内容
sed ‘/this/ d’ 1.txt
打印非空行的内容
sed -n '/[^$]/p’1.txt
[^ ] 代 表 以 后 面 跟 着 的 字 符 为 开 头 , ] ^代表以后面跟着的字符为开头, ]代表以后面跟着的字符为开头,代表以前面的字符为结尾;
^$联合使用,中间不加任何字符数字,代表匹配空行;
[ ] 在shell正则中表示取反
输出0到500中7的倍数
seq 0 7 500 seq 尾数 seq 首数 尾数 seq 首数 增量 尾数
统计文件的行数
awk ‘END{print NR}’1.txt
sed -n ‘$=’ 1.txt
打印文档中单词数小于8的内容
cat 1.txt| awk ‘{for (i=1;i> b
覆盖写入
append模式写入
任务调度crontab
查看当前用户下有哪些作业:crontab -l
添加、编辑:crontab -e
禁用:加#
常用的linux命令有哪些?
ls mkdir rm cp mv touch cat
top
top命令是Linux下常用的性能分析工具,能够实时显示系统中各个进程的资源占用状况,类似于Windows的任务管理器
tail
tail -f 1.log 实时查看日志
tail -n 5 1.log 显示倒数5行
tail -n +5 1.log 从第5行开始显示
scp
命令用于 Linux 之间复制文件和目录
scp /root/test.txt root@192.168.1.10:/root/ 将 /root/test.txt 拷贝到 192.168.1.10 的 /root/ 目录下,文件名还是 text.txt,使用 root 用户,此时会提示输入远程 root 用户的密码。
scp -r /root/test/ root@192.168.1.10:/root/ 将整个目录 /root/test/ 复制到 192.168.1.10 的 /root/ 下,即递归的复制,使用 root 用户,此时会提示输入远程 root 用户的密码
查看进程ps 查看所有进程长格式ps -ef
打印当前文件夹文件 ls -al a所有文件 l详细信息
软链接 ln -s a target 硬链接 ln
创建目录 mkdir
修改权限 chmod
查看文件:
移动文件mv 也可以重命名
复制文件cp
删除文件 rm -r 递归删除 -f删除只读文件
通配符?单个字符,*多个字符,[a-z]字符集
grep 正则搜索 显示行号-n 查询个数-c 反选-v
查看指定进程 ps -ef | grep pid
查看命令历史 history
查看磁盘空间df -hl
查看文件大小du
查找文件 find [目录] 以名字查找-name “h*”以h开头
终止一个进程 kill -9 pid
如何防止新人误操作rm -rf
找进程号为199的进程 ls -ef|grep 199
某文件中含关键词的行数 grep -c “key” ./file
该目录下以.log结尾的文件中包含关键词a但不包含关键词b的行数 grep “a” ./file | grep -cv “b”
数据库 索引是表的目录,在查找内容之前可以先在目录中查找索引位置,以此快速定位查询数据。对于索引,会保存在额外的文件中。
作用:提高查询速度、确保数据的唯一性、加速表和表之间的连接等
优点:
索引的优点是可以提高检索数据的速度
缺点:
索引的缺点是创建和维护索引需要耗费时间
当增加索引时,会提高检索性能,但是会降低修改性能。当减少索引时,会提高修改性能
索引可以提高查询速度,会减慢写入速度
分类:
主键索引(PRIMARY KEY)唯一索引(UNIQUE)常规索引(INDEX)全文索引(FULLTEXT)
主键索引和唯一索引都是间接创建索引
1、主键索引
create table student1 (gradeID int(11) auto_increment primary key)
特性:
最常见的索引
确保数据记录的唯一性
确保特定数据记录在数据库中的位置
2、唯一索引
create table student1
(gradeID int(11) auto_increment primary key,gradename varchar(20) not null unique)
特性:
避免同一个表中某数据列中的值重复
与主键索引的区别,一个表只能有一个主键索引,唯一索引可以用多个
3、常规索引
作用:快速定位特定数据
4、全文索引
只能用于MyISAM类型的数据表
只能用于char、varchar、text数据列类型
使用大型数据集
连接左外连接:select … from table(left) left join table(right) on …,以table(left)为基准,将table(left)的所有数据展出,table(right)有对应数据则显示,没有则显示NULL。
右外连接:select … from table(left) right join table(right) on …,以table(right)为基准,将table(right)的所有数据展出,table(left)有对应数据则显示,没有则显示NULL。
内连接:select … from table(left) inner join table(right) on …,将table(left)和table(right)共有的数据(左右都不为NULL)展出。
全连接:全外连接是左外连接和右外连接的组合。简单说就是将左外连接和右外连接同时做多一次。做在mysql中没有全连接运算,但是根据全连接的定义,我们可以写成左外连接和右外连接组合起来。
union 和union all:union默认去除重复数据 union distinct union不出去重复数据

笛卡尔积:对于A中的每一个元素,都有对于在B中的所有元素做连接运算 。可以见得对于两个元组分别为m,n的表。笛卡尔积后得到的元组个数为m x n个元组。而对于mysql来说,默认的连接就是笛卡尔积
导致数据库性能差的可能原因有哪些?
硬件环境问题,如磁盘IO
查询语句问题,如join、子查询、没建索引
索引失效,建了索引,查询的时候没用上
查询关联了太多的join
服务器关联缓存,线程数等
表中存在冗余字段,在生成笛卡尔积时耗费多余的时间
ACID事务的四大特性你用支付宝去去超市买东西,100块钱转给超市,其实这是两步:第一步,在支付宝数据库中你的账户减去100;第二步,在超市的支付宝账户上加上100元,交易完成;但是如果第一步完成了,还没执行第二步的时候,停电了会发生什么呢?会发生,你的账户减少了100块,超市的账户金额没变,这不就出现问题了,不得打架了吗?为了解决这个数据一致性问题,数据库事务应运而生。
数据库事务是指一个逻辑单元执行的一系列操作,一个逻辑工作单元必须有四个属性,称为 ACID(原子性、一致性、隔离性和持久性)属性
原子性(Atomicity):事务作为一个整体被执行,包含在其中的对数据库的操作要么全部被执行,要么都不执行。
一致性(Consistency):事务应确保数据库的状态从一个一致状态转变为另一个一致状态。
一致状态的含义是数据库中的数据应满足完整性约束。
隔离性(Isolation):多个事务并发执行时,一个事务的执行不应影响其他事务的执行。
持久性(Durability):已被提交的事务对数据库的修改应该永久保存在数据库中
四种隔离数据库管理系统采用锁机制来实现事务的隔离性,当多个事务同时更新数据库中的相同数据时,只允许持有锁的事务能更新该数据,其他事务必须等待,直到前一个事务释放了锁,其他事务才有机会更新该数据库。 
读未提交:就是一个事务可以读取另一个未提交事务的数据。这种隔离级别的一致性是最差的,可能会产生“脏读”、“不可重复读”、“幻读”。如无特殊情况,基本是不会使用这种隔离级别的。读提交,能解决脏读问题
读提交:就是只能读到已经提交了的内容;有事务对数据进行更新(UPDATE)操作时,读操作事务要等待这个更新操作事务提交后才能读取数据,可以解决脏读问题。但在这个事例中,出现了一个事务范围内两个相同的查询却返回了不同数据,这就是不可重复读,这是各种系统中最常用的一种隔离级别,也是SQL Server和Oracle的默认隔离级别。这种隔离级别能够有效的避免脏读
可重复读:专门针对“不可重复读”这种情况而制定的隔离级别,自然,它就可以有效的避免“不可重复读”。而它也是MySql的默认隔离级别
序列化 Serializable:这是数据库最高的隔离级别,这种级别下,事务“串行化顺序执行”,也就是一个一个排队执行。这种级别下,“脏读”、“不可重复读”、“幻读”都可以被避免,但是执行效率奇差,性能开销也最大,所以基本没人会用
在关系型数据库中,事务的隔离性分为四个隔离级别,先介绍几个关于读数据的概念
1、脏读:所谓脏读就是对脏数据的读取,而脏数据所指的就是未提交的数据。也就是说,一个事务正在对一条记录做修改,在这个事务完成并提交之前,这条数据是出于待定状态的(可能提交也可能回滚),这时,第二个事务来读取这条没有提交的数据,并据此做进一步的处理,就会产生未提交的数据依赖关系,这种现象被称为脏读。
2、不可重复读:一个事务先后读取同一条记录,但两次读取的数据不同,我们称之为不可复读。也就是说,这个事务在两次读取之间该数据被其他事务所修改
3、幻读:一个事务按相同的查询条件重新读取以前检索过得数据,却发现其他事务插入了满足其查询条件的新数据,这个现象就被称为幻读
4、串行读:完全的串行话读,所有SELECT语句都被隐式的转换成SELECT…LOCK IN SHARE MODE,即读取使用表级共享锁,读写相互都会堵塞,隔离级别最高。
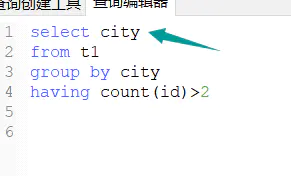
根据city分类,人数大于2的城市
一个登录信息表,查询指定时间段登录次数超过3次的用户
select username from table where time between ‘2017-1-1 00:00:00’ and ‘2018-1-1 00:00:00’
group by username
having count(username)>3
求3班同学的平均分
student:id,name,class_id
score:id,student_id,score
select avg(score.score) from score,student where score.student_id=student.id
and class_id=3
操作系统 进程和线程的区别:根本区别:进程是操作系统资源分配的基本单位,线程是任务调度和执行的基本单位
开销方面:每个进程都有独立的代码和数据空间,程序之间的切换会有较大的开销。
线程可以看做轻量级的进程,同一类线程共享代码和数据空间,每个线程都有自己独立的运行栈和程序计数器,线程之间切换的开销小
所处环境:在操作系统中能同时运行多个进程(程序),而在同一个进程(程序)中有多个线程同时执行(通过cpu调度,在每个时间片中只有一个线程执行)
内存分配:系统在运行的时候为每个进程分配不同的内存空间;对线程而言,除了cpu外,系统不会为线程分配内存(线程所使用的的资源来自其所属进程的资源),线程组之间只能共享资源
包含关系:只有一个线程的进程可以看做是单线程的,如果一个进程内有多个线程,则执行过程不是一条线的,而是多条线共同完成的,线程是进程的一部分,所以线程也被称为轻量级进程
进程的三种状态及转换就绪状态:等待cpu资源
运行状态:已经拿到cpu资源,在运行
阻塞状态:运行状态的进程因为某些事件而暂时无法继续执行,放弃cpu,进入阻塞状态,引起阻塞的有:等待I/O完成,申请缓冲区不能满足,等到信号等
(1) 就绪→执行 处于就绪状态的进程,当进程调度程序为之分配了处理机后,该进程便由就绪状态转变成执行状态。 (2) 执行→就绪 处于执行状态的进程在其执行过程中,因分配给它的一个时间片已用完而不得不让出处理机,于是进程从执行状态转变成就绪状态。 (3) 执行→阻塞 正在执行的进程因等待某种事件发生而无法继续执行时,便从执行状态变成阻塞状态。 (4) 阻塞→就绪 处于阻塞状态的进程,若其等待的事件已经发生,于是进程由阻塞状态转变为就绪状态。
进程调度的方式先到先服务:先到的进程或者作业就先服务
先到的作业为他分配内存,创建PCB,放入就绪队列中
先到的进程就为他分配处理机(处理机=cpu+主存储器+IO设备)
短作业优先:以作业或进程要求的运行时间的长短来衡量
优先级调度:以作业或进程的优先级来判断
静态:执行前就定好的优先级,不会随运行状态的改变而改变
动态:会随着执行状态的改变而改变,更灵活,科学
时间片轮转法:用于分时系统的调度,将作业或进程放在一个队列上,cpu拿出第一个进程运行一个时间片后,放到队尾轮询执行
进程间的通讯方式管道:无名管道
半双工,数据只能在一个方向流动
只能用于亲缘关系的进程间
只存在于内存中
FIFO:命名管道 是一种文件类型
可以在无关进程中交换数据
有路径名与之相关联 以一种特殊设备文件存储在文件系统中
消息队列:消息的链接表,存放在内核中。一个消息队列由一个标识符来标识
面向记录的,消息具有特定格式及特定优先级
独立于发送与接收进程,进程终止时,消息队列及其内容并不会被删除
消息队列可以实现消息的随机查询,消息不一定要以先进先出的次序读取,也可以按消息类型读取
信号量:是一个计数器,用于实现进程间的互斥与同步,而不是用于存储进程间通信数据
用于进程间同步,若要在进程间传递数据需要结合共享内存
基于操作系统的pv操作,程序对信号量的操作都是原子操作
每次对信号量的pv操作不仅限于对信号量值加一或减一,而且可以加减任意正整数
支持信号量组
共享内存:两个或多个进程共享一个给定的存储区
最快的一种IPC,进程直接对内存进行存取
多个进程可以同时操作,需要进行同步
信号量+共享内存通常结合在一起使用,信号量用来同步对共享内存的访问
总结:
管道:速度慢、容量有限、只有父子进程能通讯
FIFO:任何进程间都能通讯,但速度慢
消息队列:容量受系统限制,第一次读的时候,要考虑上一次没有读完数据的问题
信号量:不能传递复杂消息,只能用来同步
共享内存:能够很容易控制容量,速度快,但要保持同步,比如一个进程再写的时候,另一个进程要注意读写的问题,相当于线程中的线程安全
线程间的同步方式线程同步:通过特定的设置,如互斥量、事件对象、临界区,来控制线程间的执行顺序
线程互斥:对于共享的进程系统资源,在各单个线程访问时的排他性,当有若干个线程都要使用某一共享资源时,任何时刻最多只允许一个线程去使用,其他要使用该资源的线程必须等待,直到占用资源者释放该资源。线程互斥可以看成是一种特殊的线程同步
临界区、互斥对象:用于互斥控制,都具有拥有权的控制方法,只有拥有该对象的线程才能执行任务,所以拥有,执行完任务后一定要释放该对象
临界区:当多个线程访问一个独占性共享资源的时候,可以使用临界区对象,拥有临界区的线程可以访问被保护起来的资源或代码段,其他线程若想访问,则被挂起,直到拥有临界区的线程放弃临界区为止
互斥对象:互斥对象临界区对象非常相似,只是其允许在进程间使用,而临界区只限制与同一进程的各个线程之间使用
信号量:需要一个计数器来限制可以使用共享资源的线程数目时。内核对象,允许多个线程在同一时刻访问同一资源,但是需要限制在同一时刻访问次资源的最大线程数目
事件对象:允许一个线程在处理完一个任务后,主动唤醒另一个线程执行任务。通过通知操作的方式来保持线程的同步,还可以方便实现对多个线程的优先级比较的操作
死锁死锁是指两个或两个以上的进程(线程)在运行过程中因争夺资源而造成的一种僵局(Deadly-Embrace) ) ,若无外力作用,这些进程(线程)都将无法向前推进。
死锁条件:
互斥条件:进程要求对所分配的资源(如打印机)进行排他性控制,即在一段时间内某资源仅为一个进程所占有。此时若有其他进程请求该资源,则请求进程只能等待。
不可剥夺条件:进程所获得的资源在未使用完毕之前,不能被其他进程强行夺走,即只能由获得该资源的进程自己来释放(只能是主动释放)。
请求与保持条件:进程已经保持了至少一个资源,但又提出了新的资源请求,而该资源已被其他进程占有,此时请求进程被阻塞,但对自己已获得的资源保持不放。
循环等待条件:存在一种进程资源的循环等待链,链中每一个进程已获得的资源同时被 链中下一个进程所请求。即存在一个处于等待状态的进程集合{Pl, P2, …, pn},其中Pi等 待的资源被P(i+1)占有(i=0, 1, …, n-1),Pn等待的资源被P0占有,如图2-15所示。
直观上看,循环等待条件似乎和死锁的定义一样,其实不然。按死锁定义构成等待环所 要求的条件更严,它要求Pi等待的资源必须由P(i+1)来满足,而循环等待条件则无此限制。
以上这四个条件是死锁的必要条件,只要系统发生死锁,这些条件必然成立,而只要上述条件之一不满足,就不会发生死锁。
预防死锁破坏“互斥”条件:就是在系统里取消互斥。若资源不被一个进程独占使用,那么死锁是肯定不会发生的。但一般来说在所列的四个条件中,“互斥”条件是无法破坏的。因此,在死锁预防里主要是破坏其他几个必要条件,而不去涉及破坏“互斥”条件破坏“占有并等待”条件:
破坏“占有并等待”条件,就是在系统中不允许进程在已获得某种资源的情况下,申请其他资源。即要想出一个办法,阻止进程在持有资源的同时申请其他资源。
方法一:创建进程时,要求它申请所需的全部资源,系统或满足其所有要求,或什么也不给它。这是所谓的 “ 一次性分配”方案。
方法二:要求每个进程提出新的资源申请前,释放它所占有的资源。这样,一个进程在需要资源S时,须先把它先前占有的资源R释放掉,然后才能提出对S的申请,即使它可能很快又要用到资源R。
破坏“不可抢占”条件:破坏“不可抢占”条件就是允许对资源实行抢夺。
方法一:如果占有某些资源的一个进程进行进一步资源请求被拒绝,则该进程必须释放它最初占有的资源,如果有必要,可再次请求这些资源和另外的资源。
方法二:如果一个进程请求当前被另一个进程占有的一个资源,则操作系统可以抢占另一个进程,要求它释放资源。只有在任意两个进程的优先级都不相同的条件下,方法二才能预防死锁。
破坏“循环等待”条件:破坏“循环等待”条件的一种方法,是将系统中的所有资源统一编号,进程可在任何时刻提出资源申请,但所有申请必须按照资源的编号顺序(升序)提出。这样做就能保证系统不出现死锁。
避免死锁预防死锁是设法至少破坏产生死锁的四个必要条件之一,严格的防止死锁的出现,而避免死锁则不那么严格的限制产生死锁的必要条件的存在,因为即使死锁的必要条件存在,也不一定发生死锁。避免死锁是在系统运行过程中注意避免死锁的最终发生。
有序资源分配法:这种算法资源按某种规则系统中的所有资源统一编号(例如打印机为1、磁带机为2、磁盘为3、等等),申请时必须以上升的次序
银行家算法:安全序列是指对当前申请资源的进程排出一个序列,保证按照这个序列分配资源完成进程,不会发生“酱油和醋”的尴尬问题。
我们假设有进程P1,P2,…Pn 则安全序列要求满足:Pi(1
最近更新
- 深拷贝和浅拷贝的区别(重点)
- 【Vue】走进Vue框架世界
- 【云服务器】项目部署—搭建网站—vue电商后台管理系统
- 【React介绍】 一文带你深入React
- 【React】React组件实例的三大属性之state,props,refs(你学废了吗)
- 【脚手架VueCLI】从零开始,创建一个VUE项目
- 【React】深入理解React组件生命周期----图文详解(含代码)
- 【React】DOM的Diffing算法是什么?以及DOM中key的作用----经典面试题
- 【React】1_使用React脚手架创建项目步骤--------详解(含项目结构说明)
- 【React】2_如何使用react脚手架写一个简单的页面?

