
目录
介绍
Apriori模型
频繁项集
关联规则
结论与分析
可访问 实现机器学习的循序渐进指南系列汇总,获取本系列完成文章列表。
介绍Apriori是一种学习频繁项集和关联规则的算法。Apriori是一种自下而上的方法,它将对象扩展到每次迭代的频繁项集。当没有要扩展的对象时,算法终止。
Apriori模型 频繁项集频繁项集是通常同时发生的一组对象。
传统方法将多次遍历数据集。为了减少计算量,研究人员发现了一种称为Apriori原理的东西。Apriori原理帮助我们减少可能有趣的项目集的数量。Apriori原理说如果一个项集是频繁的,那么它的所有子集都是频繁的。乍一看似乎没用。但是,如果我们将其内部翻出来,它会说如果一个项目集不频繁,那么它的所有超集都是不频繁的。这意味着在自下而上的过程中,如果底部项目集不频繁,我们不需要在顶部处理该集合。例如,存在集合A = {1,2,3,4}。A生成的所有可能项目集如下所示:
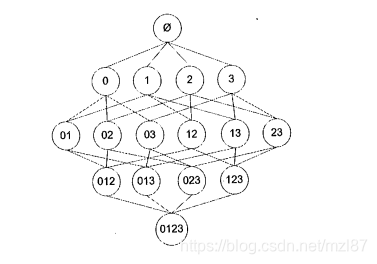
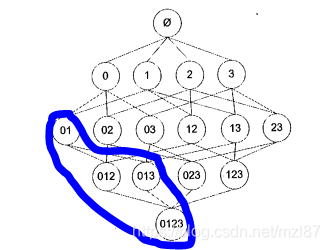
如果项目集{0,1}不频繁,则包含{0,1}的所有项集都不频繁,这意味着我们可以跳过这些以蓝色圆圈标记的项目集。
频繁项集的生成包括以下步骤:
1、首先,计算单例集。所有元素都被视为候选集。
def createSingletonSet(self, data):
singleton_set = []
for record in data:
for item in record:
if [item] not in singleton_set:
singleton_set.append([item])
singleton_set.sort()
singleton_set = list(map(frozenset, singleton_set)) # generate a invariable set
return singleton_set
2、合并单例集以生成更多候选集。
def createCandidateSet(self, frequent_items, k):
candidate_set = []
items_num = len(frequent_items)
# merge the sets which have same front k-2 element
for i in range(items_num):
for j in range(i+1, items_num):
L1 = list(frequent_items[i])[: k-2]
L2 = list(frequent_items[j])[: k-2]
if L1 == L2:
candidate_set.append(frequent_items[i] | frequent_items[j])
return candidate_set
3、计算所有候选集的支持度,并选择支持度大于最小支持度的候选集作为频繁项集。
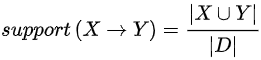
def calculateSupportDegree(self, data, candidate_set):
sample_sum = len(data)
data = map(set, data) # transform data into set
# calculate the frequency of each set in candidate_set appearing in data
frequency = {}
for record in data:
for element in candidate_set:
if element.issubset(record): # elements in record
frequency[element] = frequency.get(element, 0) + 1
# calculate the support degree for each set
support_degree = {}
frequent_items = []
for key in frequency:
support = frequency[key]/sample_sum
if support >= self.min_support:
frequent_items.insert(0, key)
support_degree[key] = support
return frequent_items, support_degree
4、组合以上功能:
def findFrequentItem(self, data):
singleton_set = self.createSingletonSet(data)
sub_frequent_items, sub_support_degree =
self.calculateSupportDegree(data, singleton_set)
frequent_items = [sub_frequent_items]
support_degree = sub_support_degree
k = 2
while len(frequent_items[k-2]) > 0:
candidate_set = self.createCandidateSet(frequent_items[k-2], k)
sub_frequent_items, sub_support_degree =
self.calculateSupportDegree(data, candidate_set)
support_degree.update(sub_support_degree)
if len(sub_frequent_items) == 0:
break
frequent_items.append(sub_frequent_items)
k = k + 1
return frequent_items, support_degree
关联规则
关联规则是发生导致其他事情发生的事情。例如,有一个频繁的项目集{beer, diaper}。可能存在关联规则diaper -> beer,这意味着有人也可以通过beer购买diaper。请注意,规则是单向的,这意味着规则beer ->diaper可能不正确。
关联规则的生成包括以下步骤:
1、计算每个频繁项集的置信度,并选择置信度大于最小置信度的项集。
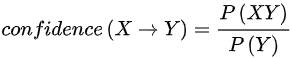
def calculateConfidence(self, frequent_item, support_degree, candidate_set, rule_list):
rule = []
confidence = []
for item in candidate_set:
temp = support_degree[frequent_item]/support_degree[frequent_item - item]
confidence.append(temp)
if temp >= self.min_confidence:
rule_list.append((frequent_item - item, item, temp)) # association rule
rule.append(item)
return rule
2、合并频繁项集以生成更多关联规则:
def mergeFrequentItem(self, frequent_item, support_degree, candidate_set, rule_list):
item_num = len(candidate_set[0])
if len(frequent_item) > item_num + 1:
candidate_set = self.createCandidateSet(candidate_set, item_num+1)
rule = self.calculateConfidence
(frequent_item, support_degree, candidate_set, rule_list)
if len(rule) > 1:
self.mergeFrequentItem(frequent_item, support_degree, rule, rule_list)
3、组合以上功能:
def generateRules(self, frequent_set, support_degree):
rules = []
for i in range(1, len(frequent_set)): # generate rule from sets
# which contain more than two elements
for frequent_item in frequent_set[i]:
candidate_set = [frozenset([item]) for item in frequent_item]
if i > 1:
self.mergeFrequentItem
(frequent_item, support_degree, candidate_set, rules)
else:
self.calculateConfidence
(frequent_item, support_degree, candidate_set, rules)
return rules
结论与分析
Apriori是一种生成频繁项集和关联规则的简单算法。但它更适合sprase数据集。现在,我们有一个数据集如下。让我们看看Apriori的结果。结果是元组为(X,Y,置信度)。


可以在MachineLearning中找到本文中的相关代码和数据集。
有兴趣的小伙伴可以查看上一篇 。
原文地址:https://www.codeproject.com/Articles/5142921/Step-by-Step-Guide-to-Implement-Machine-Learning-9

