
应使用适当的SQL函数来避免为数据串联、比较、ORDER BY或GROUP BY等操作获得不需要的输出。您不应该试图阻止NULL值——相反,以克服其限制的方式编写您的查询。

该NULL值是一种表示未知值的数据类型。它不等同于空字符串或零。假设有一个含有列EmployeeId,Name,ContactNumber和候补联系人号码的employee表。此表有一些强制值列,如EmployeeId,Name和ContactNumber。但是,备用联系号码不是必需的,因此具有未知值。因此,此表中的NULL值表示信息缺失或不足。以下是NULL的其他含义:
- 值未知
- 值不可用
- 属性不适用
在这篇文章中,我们将考虑如何在创建表、查询、字符串操作和函数中使用NULL。
在CREATE TABLE中允许NULL对于表结构,我们需要定义相应的列是否允许为NULL。例如,看看下面的客户表。如列CustomerID,FirstName,LastName不允许为NULL值,而Suffix,CompanyName和SalesPerson列可存储NULL的值。
CREATE TABLE Customers(
CustomerID SERIAL PRIMARY KEY,
FirstName varchar(50) NOT NULL,
MiddleName varchar(50) NULL,
LastName varchar(50) NOT NULL,
Suffix varchar(10) NULL,
CompanyName varchar(128) NULL,
SalesPerson varchar(256) NULL,
EmailAddress varchar(50) NULL
)让我们使用以下脚本向该表中插入几条记录:
INSERT INTO Customers
(FirstName, MiddleName, LastName, Suffix, CompanyName, SalesPerson, EmailAddress)
VALUES
('John',NULL,'Peter',NULL,NULL,NULL,NULL),
('Raj','M','Mohan','Mr','ABC','KRS','raj.mohan@abc.com'),
('Krishna',NULL,'Kumar','MS','XYZ',NULL,'Krishna.kumar@xyz.com')现在,假设您要为那些没有电子邮件地址的客户获取记录。下面的查询工作正常,但它不会给我们一行:
Select * FROM Customers WHERE Emailaddress=NULL
不能使用=查询为NULL的值
在上面的select语句中,表达式定义了“电子邮件地址等于UNKNOWN值的地方”。在SQL标准中,我们不能将值与NULL比较。 相反,您将值引用为IS NULL。
注意:IS和NULL之间有一个空格。如果删除空格,它就变成了一个函数ISNULL()。

通过使用IS NULL而不是equals,您可以查询NULL值。
带NULL的整数、小数和字符串操作同样,假设您声明了一个变量但没有初始化它的值。如果您尝试执行算术运算,它也会返回NULL,因为SQL无法确定变量的正确值,并且它认为是UNKNOWN值。
SELECT 10 * NULL
将整数乘以NULL返回NULL
SELECT 10.0 * NULL
将小数乘以NULL返回NULL
NULL在string串联中也起着重要的作用。假设您需要在单个列中提供customer的全名,并使用管道符号(||) 将它们连接起来。
SELECT Suffix, FirstName, MiddleName, LastName, Suffix,
(Suffix || ' ' || FirstName || ' ' || MiddleName || LastName ) _
AS CustomerFullName FROM Customers
将字符串设置为NULL然后连接它返回NULL
看看结果集——查询返回NULL的级联string,如果的任何部位string都有NULL。例如,第1行中的人没有中间名。它的串联string也是NULL,因为SQL无法验证string包含NULL。
有许多SQL函数可用于克服string串联中的这些NULL值问题。我们将在本文后面介绍它们。
SQL聚合中的NULL值假设你使用聚合函数,例如SUM,AVG或者MIN,MAX对应NULL数值。你认为预期的结果是什么?
SELECT Sum(values) AS sum
,avg(values) as Avg
,Min(Values) as MinValue
,Max(Values) as MaxValue
FROM (VALUES (1), (2), (3),(4), (NULL)) AS a (values);
在聚合函数中,NULL被忽略。
看上图:它计算了所有聚合函数的值。除了COUNT()和GROUP BY()之外, SQL会忽略聚合函数中的NULL。如果我们尝试对所有NULL值使用聚合函数,您会收到一条错误消息。
SELECT
Sum(values) AS sum
,avg(values) as Avg
,Min(Values) as MinValue
,Max(Values) as MaxValue
FROM (VALUES (NULL), (NULL), (NULL),(NULL), (NULL)) AS a (values);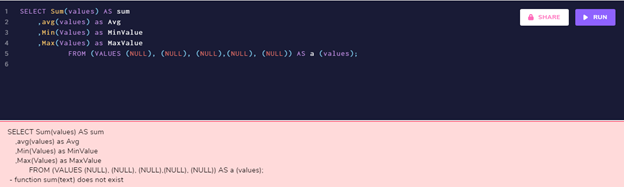
聚合所有NULL值会导致错误。
ORDER BY和GROUP BY为NULLSQL将NULL值视为UNKNOWN值。因此,如果我们对NULL值列使用ORDER By和GROUP by子句,它会平等对待它们并对其进行排序、分组。例如,在我们的customer表中,MilddleName列中有NULL。如果我们使用此列对数据进行排序,它会在最后列出NULL值,如下所示:
SELECT Suffix, FirstName, MiddleName, LastName, Suffix,
(Suffix || ' ' || FirstName || ' ' || MiddleName || LastName )
AS CustomerFullName
FROM Customers
Order BY MiddleName
NULL值最后出现在ORDER BY中
在我们使用之前GROUP BY,让我们在表中再插入一条记录。它在大多数列中都有NULL值,如下所示:
INSERT INTO Customers (FirstName,MiddleName,LastName,Suffix,CompanyName,
SalesPerson,EmailAddress)
values('Sant',NULL,'Joseph',NULL,NULL,NULL,NULL);现在,使用GROUP BY子句根据后缀对记录进行分组。
SELECT count(*) as Customercount , suffix
FROM Customers
Group BY Suffix
GROUP BY确实平等地对待所有NULL值。
如上所示,SQL平等对待这些NULL值并将它们分组。对于customers表中没有指定任何后缀的记录,您将获得两个customer计数。
处理NULL的有用函数我们探讨了SQL如何处理不同操作中的NULL值。在本节中,我们将探索一些有价值的函数,以避免由于获得不想要的值NULL。
在Postgres和MySQL中使用NULLIF该NULLIF()函数比较两个输入值。
- 如果两个值相等,则返回NULL。
- 在不匹配的情况下,它返回第一个值作为输出。
例如,查看以下NULLIF()函数的输出。
SELECT NULLIF (1, 1); 
如果两个值相等,则 NULLIF返回NULL
SELECT NULLIF (100,0); 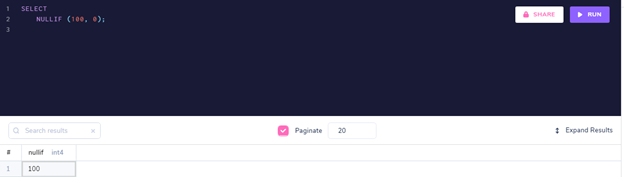
如果值不相等,则NULLIF返回第一个值。
SELECT NULLIF ('A', 'Z'); 
NULLIF返回字符串比较中的第一个字符串。
COALESCE函数该COALESCE()函数接受多个输入值并返回第一个非NULL值。我们可以在单个COALESCE()函数中指定各种数据类型并返回高优先级数据类型。
SELECT COALESCE (NULL, 2, 5) AS NULLRESPONSE;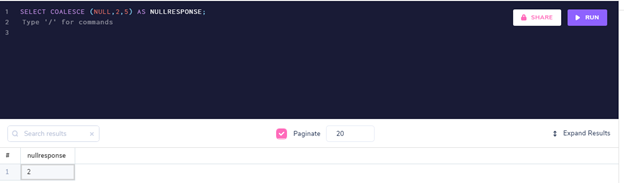 COALESCE返回列表中的第一个非NULL数据类型。
COALESCE返回列表中的第一个非NULL数据类型。
SELECT coalesce(null, null, 8, 2, 3, null, 4);
在关系数据库中NULL值类型是必需的,以表示一个未知的或丢失的值。您需要使用适当的SQL函数来避免在数据串联、比较ORDER BY 或GROUP BY。您不应该试图阻止NULL值——相反,以克服其局限性的方式编写查询。这样,你就会学会去爱NULL。
https://www.codeproject.com/Articles/5300621/How-I-Learned-to-Stop-Worrying-and-Love-NULL-in-SQ

