
循环神经网络RNN是专门用于处理序列数据而生,其在处理序列数据方面存在天然优势。
- 一、RNN基本结构及数学推导
- 二、RNN的缺陷及改进方法
- 三、长短期记忆网络(LSTM)
- 四、门控循环单元(GRU)
- 4.1 GRU的前向传播
- 4.2 GRU的训练过程
- 4.3 GRU的优势
RNN基本结构如下:  其中各参数含义如下:
其中各参数含义如下:
U——输入层到隐藏层的权重矩阵; V——隐藏层到输出层的权重矩阵;
x是一个向量,它表示输入层的值; s是一个向量,它表示隐藏层的值; o也是一个向量,它表示输出层的值;
循环神经网络的隐藏层的值s不仅仅取决于当前这次的输入x,还取决于上一次隐藏层的值s。权重矩阵W就是隐藏层上一次的值作为这一次的输入的权重。  那么我们将第二个公式一直代入到第一个公式后,就会有下面推导:
那么我们将第二个公式一直代入到第一个公式后,就会有下面推导:  从上图可以看出,当前时刻确实包含了历史信息,这也就说明了循环神经网络(RNN)为什么能够记忆历史信息,在很多任务上也确实需要用到这样的特性。
从上图可以看出,当前时刻确实包含了历史信息,这也就说明了循环神经网络(RNN)为什么能够记忆历史信息,在很多任务上也确实需要用到这样的特性。
注意:
- 这里的W,U,V在每个时刻都是相等的**(权重共享)**
- 隐藏状态可以理解为: S=f(现有的输入+过去记忆总结)
前面我们介绍了RNN的算法, 它处理时间序列的问题的效果很好, 但是仍然存在着一些问题, 其中较为严重的是容易出现梯度消失或者梯度爆炸的问题(BP算法和长时间依赖造成的). 注意: 这里的梯度消失和BP的不一样,这里主要指由于时间过长而造成记忆值较小的现象。
因此, 就出现了一系列的改进的算法, 其中最重要的两种算法分别是LSTM和GRU。
LSTM 和 GRU对于梯度消失或者梯度爆炸的问题处理方法主要是:
- 对于梯度消失:由于它们都有特殊的方式存储”记忆”,那么以前梯度比较大的”记忆”不会像简单的RNN一样马上被抹除,因此可以一定程度上克服梯度消失问题。
- 对于梯度爆炸:用来克服梯度爆炸的问题就是gradient clipping,也就是当你计算的梯度超过阈值c或者小于阈值-c的时候,便把此时的梯度设置成c或-c。
长短期记忆(Long short-term memory, LSTM)是一种特殊的RNN,主要是为了解决长序列训练过程中的梯度消失和梯度爆炸问题。简单来说,就是相比普通的RNN,LSTM能够在更长的序列中有更好的表现。
公式及理论推导略。有需要详细了解的可以参考其他LSTM文章。
四、门控循环单元(GRU)GRU(Gate Recurrent Unit)是循环神经网络(Recurrent Neural Network, RNN)的一种。和LSTM(Long-Short Term Memory)一样,也是为了解决长期记忆和反向传播中的梯度等问题而提出来的。GRU于2014年提出。 GRU和LSTM在很多情况下实际表现上相差无几,那么为什么我们要使用新人GRU(2014年提出)而不是相对经受了更多考验的LSTM(1997提出)呢? 选择GRU是因为它的实验效果与LSTM相似,但是更易于计算。
与普通RNN相比,GRU增加了两个结构:
- 重置门:用于控制哪些信息需要遗忘;
- 更新门:用于控制哪些信息需要注意; 激活函数为sigmoid,值域为(0,1),0表示遗忘,1表示保留。
GRU基本结构如下图所示:  图中的
Z
t
Z_t
Zt和
R
t
R_t
Rt分别表示更新门和重置门。 更新门用于控制前一时刻的状态信息被带入到当前状态中的程度,更新门的值越大说明前一时刻的状态信息带入越多; 重置门用于控制前一状态有多少信息被写入到当前的候选集上,重置门越小,前一状态的信息被写入的越少;
图中的
Z
t
Z_t
Zt和
R
t
R_t
Rt分别表示更新门和重置门。 更新门用于控制前一时刻的状态信息被带入到当前状态中的程度,更新门的值越大说明前一时刻的状态信息带入越多; 重置门用于控制前一状态有多少信息被写入到当前的候选集上,重置门越小,前一状态的信息被写入的越少;
根据上面的GRU的模型图,我们来看看网络的前向传播公式:  其中[]表示两个向量相连。
其中[]表示两个向量相连。
从上述公式可以看出,Zt越大,Ht中 H ~ t \tilde{H}_t H~t的比例就越大。 这也意味着更新门决定了隐藏状态信息对于最终输出的重要性。这也符合了生物记忆机制,即过去发生的一切都无需全部记住。需要记住一些更为“重要”的信息,而其他信息将在一定程度上被遗忘。
4.2 GRU的训练过程从前向传播过程中的公式可以看出要学习的参数有Wr、Wz、Wh、Wo。其中前三个参数都是拼接的(因为后先的向量也是拼接的),所以在训练的过程中需要将他们分割出来: 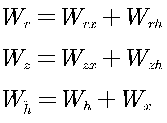 即重置门和更新门也可以写成:
即重置门和更新门也可以写成: 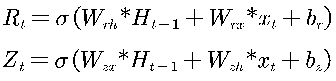 其中,
x
t
x_t
xt表示当前时刻的输入向量,
H
t
−
1
H_{t-1}
Ht−1表示前一时刻模型的输出向量,
W
r
h
W_{rh}
Wrh,
W
r
x
,
W_{rx},
Wrx,W_{zx},
W
z
h
W_{zh}
Wzh表示权值矩阵,
R
t
R_t
Rt表示重置门的输出,
Z
t
Z_t
Zt表示更新门的输出,σ作为控制门,表示标准的sigmoid函数。
其中,
x
t
x_t
xt表示当前时刻的输入向量,
H
t
−
1
H_{t-1}
Ht−1表示前一时刻模型的输出向量,
W
r
h
W_{rh}
Wrh,
W
r
x
,
W_{rx},
Wrx,W_{zx},
W
z
h
W_{zh}
Wzh表示权值矩阵,
R
t
R_t
Rt表示重置门的输出,
Z
t
Z_t
Zt表示更新门的输出,σ作为控制门,表示标准的sigmoid函数。
作为 RNN 的一种变体,GRU 不仅能够有效解决 RNN 时间序列预测中的梯度消失和梯度爆炸问题,而且比 LSTM 训练花费的时间更少。因此建议所有循环神经网络 均使用GRU或LSTM代替RNN构建。
参考: 【1】一文搞懂RNN(循环神经网络)基础篇 【2】深度学习之GRU网络

