
PaddleOCR旨在打造一套丰富、领先、且实用的OCR工具库,助力开发者训练出更好的模型,并应用落地。
特征- PP-OCR系列高质量预训练模型,准确的识别效果
- 超轻量PP-OCRv2系列:检测(3.1M)(detection,det)+ 方向分类器(1.4M)(direction classifier,cls)+ 识别(8.5M)(recognition,rec)= 13.0M
- 超轻量PP-OCR mobile移动端系列:检测(3.0M)+方向分类器(1.4M)+ 识别(5.0M)= 9.4M
- 通用PPOCR server系列:检测(47.1M)+方向分类器(1.4M)+ 识别(94.9M)= 143.4M
- 支持中英文数字组合识别、竖排文本识别、长文本识别
- 支持多语言识别:韩语、日语、德语、法语等约80种语言
- PP-Structure文档结构化系统
- 支持版面分析与表格识别(含Excel导出)
- 支持关键信息提取任务
- 支持DocVQA任务
- 丰富易用的OCR相关工具组件
- 半自动数据标注工具PPOCRLabel:支持快速高效的数据标注
- 数据合成工具Style-Text:批量合成大量与目标场景类似的图像
- 支持用户自定义训练,提供丰富的预测推理部署方案
- 支持PIP快速安装使用
- 可运行于Linux、Windows、MacOS等多种系统
- 在线网站体验:超轻量PP-OCR mobile模型体验地址:https://www.paddlepaddle.org.cn/hub/scene/ocr
- 移动端:安装包DEMO下载地址(基于EasyEdge和Paddle-Lite, 支持iOS和Android系统)
推理: inference,训练:train,预训练:pre-train
模型简介模型名称推荐场景检测模型方向分类器识别模型中英文超轻量PP-OCRv2模型(13.0M)ch_PP-OCRv2_xx移动端&服务器端推理模型 / 训练模型推理模型 / 预训练模型推理模型 / 训练模型中英文超轻量PP-OCR mobile模型(9.4M)ch_ppocr_mobile_v2.0_xx移动端&服务器端推理模型 / 预训练模型推理模型 / 预训练模型推理模型 / 预训练模型中英文通用PP-OCR server模型(143.4M)ch_ppocr_server_v2.0_xx服务器端推理模型 / 预训练模型推理模型 / 预训练模型推理模型 / 预训练模型更多模型下载(包括多语言),可以参考PP-OCR 系列模型下载
PP-OCRv2 Pipeline(管道、传递、管线、可视化流水线)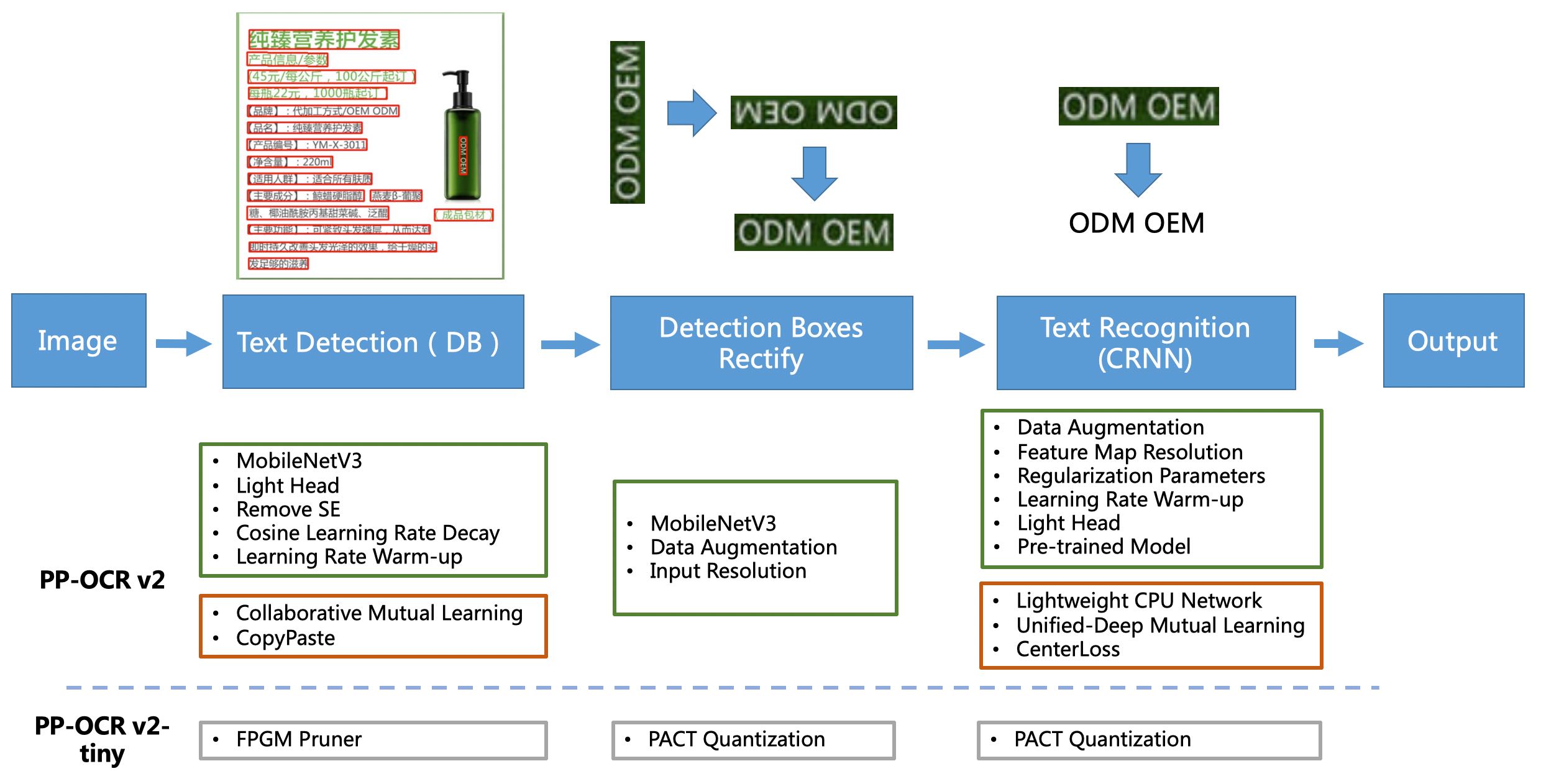
[1] PP-OCR是一个实用的超轻量OCR系统。主要由DB文本检测、检测框矫正和CRNN文本识别三部分组成。该系统从骨干网络选择和调整、预测头部的设计、数据增强、学习率变换策略、正则化参数选择、预训练模型使用以及模型自动裁剪量化8个方面,采用19个有效策略,对各个模块的模型进行效果调优和瘦身(如绿框所示),最终得到整体大小为3.5M的超轻量中英文OCR和2.8M的英文数字OCR。更多细节请参考PP-OCR技术方案 https://arxiv.org/abs/2009.09941
[2] PP-OCRv2在PP-OCR的基础上,进一步在5个方面重点优化,检测模型采用CML协同互学习知识蒸馏策略和CopyPaste数据增广策略;识别模型采用LCNet轻量级骨干网络、UDML 改进知识蒸馏策略和Enhanced CTC loss损失函数改进(如上图红框所示),进一步在推理速度和预测效果上取得明显提升。更多细节请参考PP-OCRv2技术报告。
效果展示 more- 中文模型


- 英文模型

- 其他语言模型


