
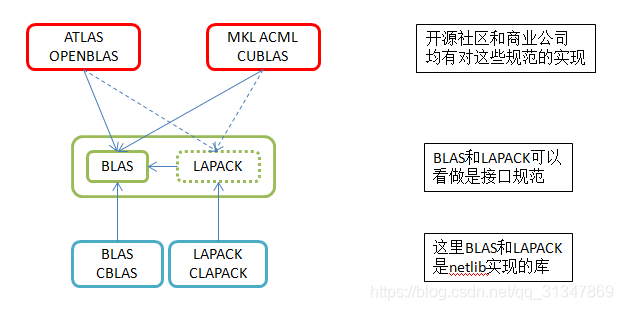
BLAS的全称是Basic Linear Algebra Subprograms,中文可以叫做基础线性代数子程序。它定义了一组应用程序接口(API)标准,是一系列初级操作的规范,如向量之间的乘法、矩阵之间的乘法等。许多数值计算软件库都实现了这一核心。
BALS是用Fortran语言开发的,Netlib实现了BLAS的这些API接口,得到的库也叫做BLAS。Netlib只是一般性地实现了基本功能,并没有对运算做过多的优化。
LAPACKLAPACK (linear algebra package),是著名的线性代数库,也是Netlib用fortran语言编写的。其底层是BLAS,在此基础上定义了很多矩阵和向量高级运算的函数,如矩阵分解、求逆和求奇异值等。该库的运行效率比BLAS库高。 从某个角度讲,LAPACK也可以称作是一组科学计算(矩阵运算)的接口规范。Netlib实现了这一组规范的功能,得到的这个库叫做LAPACK库。
Linear Algebra Package,线性代数包,底层使用BLAS,使用Fortran语言编写。在BLAS的基础上定义很多矩阵和向量高级运算的函数,如矩阵分解、求逆和求奇异值等。该库的运行效率比BLAS库高。为了进行C语言的开发,开发了CBLAS和CLAPACK。
CBALS & CLAPACK前面BLAS和LAPACK的实现均是用的Fortran语言。为了方便c程序的调用,Netlib开发了CBLAS和CLAPACK。其本质是在BLAS和LAPACK的基础上,增加了c的调用方式。
ATLAS上面提到,可以将BLAS和LAPACK看做是接口规范,那么其他的组织、个人和公司,就可以根据此规范,实现自己的科学计算库。
开源社区实现的科学计算(矩阵计算)库中,比较著名的两个就是atlas和openblas。它们都实现了BLAS的全部功能,以及LAPACK的部分功能,并且他们都对计算过程进行了优化。
Atlas (Automatically Tuned Linear Algebra Software)能根据硬件,在运行时,自动调整运行参数。
Automatically Tuned Linear Algebra Software,自动化调节线性代数软件。可以根据硬件,在运行时,自动调整运行参数。
OpenBLASOpenblas在编译时根据目标硬件进行优化,生成运行效率很高的程序或者库。Openblas的优化是在编译时进行的,所以其运行效率一般比atlas要高。但这也决定了openblas对硬件依赖性高,换了机器,可能就要重新编译了。(例如A和B两台机器cpu架构、指令集不一样,操作系统一样,在A下编译的openblas库,在B下无法运行,会出现“非法指令”这样的错误)
Intel MKL英特尔数学核心函数库,Intel Math Kernel Library
Intel的MKL和AMD的ACML都是在BLAS的基础上,针对自己特定的CPU平台进行针对性的优化加速。以及NVIDIA针对GPU开发的cuBLAS。
商业公司对BLAS和LAPACK的实现,有Intel的MKL和AMD的ACML。他们对自己的cpu架构,进行了相关计算过程的优化,实现算法效率也很高。 NVIDIA针对其GPU,也推出了cuBLAS,用以在GPU上做矩阵运行。
对于机器学习的很多问题来说,计算的瓶颈往往在于大规模以及频繁的矩阵运算,主要在于以下两方面:
- (Dense/Sparse) Matrix – Vector product (稠密/稀疏)矩阵 - 向量 产品
- (Dense/Sparse) Matrix – Dense Matrix product
如何使机器学习算法运行更高效摆在我们面前,很多人都会在代码中直接采用一个比较成熟的矩阵运算数学库,面对繁多的数学库,选择一个合适的库往往会令人头疼,这既跟你的运算环境有关,也跟你的运算需求有关,不是每个库都能完胜的。
这篇文章的主要目的就是比较几个常见的BLAS库的矩阵运算性能,分别是
- EIGEN : Eigen 是一个线性算术的C++模板库。功能强大、快速、优雅以及支持多平台,可以使用该库来方便处理一些矩阵的操作,达到类似matlab那样的快捷。 需要定义 EIGEN_NO_DEBUG 阻止运行时assertion。编译单线程版本需要开启 -DEIGEN_DONT_PARALLELIZE. 在试验中,我们采用 EIGEN 原生 BLAS 实现。
- Intel MKL : 英特尔数学核心函数库是一套经过高度优化和广泛线程化的数学例程,专为需要极致性能的科学、工程及金融等领域的应用而设计。它可以为当前及下一代英特尔处理器提供性能优化,包括更出色地与 Microsoft Visual Studio、Eclipse和XCode相集成。英特尔 MKL 支持完全集成英特尔兼容性 OpenMP 运行时库,以实现更出色的 Windows/Linux 跨平台兼容性。在试验中的多线程版本需要链接到 mkl_gnu_thread,而不是 mkl_intel_thread,单线程版本需要链接到 mkl_sequential_thread。
- OpenBLAS: OpenBLAS是高性能多核BLAS库,是GotoBLAS2 1.13 BSD版本的衍生版。OpenBLAS 的编译依赖系统环境,并且没有原生单线程版本,在实验这哦那个,通过设置 OMP_NUM_THREADS=1 来模拟单线程版本,可能会带来一点点的性能下降。
每个测试程序的编译都采用 ”-O4 -msse2 -msse3 -msse4″, 通过设置 OMP_NUM_THREADS 来控制程序使用的线程数量. 除了 OpenBLAS,其他两个库的测试程序都分别有单线程和多线程的编译版本。
- 单线程版本
我在实验中进行了一系列的非稀疏矩阵相乘运算,矩阵规模也逐渐增大,单线程的运行时间如下表所示,其中采用的测试轮数为5轮,其中红色表示性能最好的一组实验结果。
Matrix-DimensionEigenMKLOpenBLAS5000.041590.031220.0305810000.317890.243390.2373015001.045890.814450.7986920002.375671.920361.8710225004.682663.785693.6454830008.280736.426306.29797350013.0747010.250969.98417400019.3455015.2193114.87500450027.5276721.4502421.18227500037.67552 29.3163129.07229
从图中可以看出,OpenBLAS的性能最好,MKL的表现也很不错,而EIGEN的表现却很糟糕。
- 多线程版本
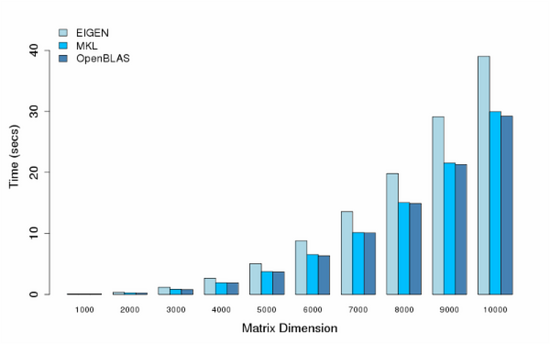
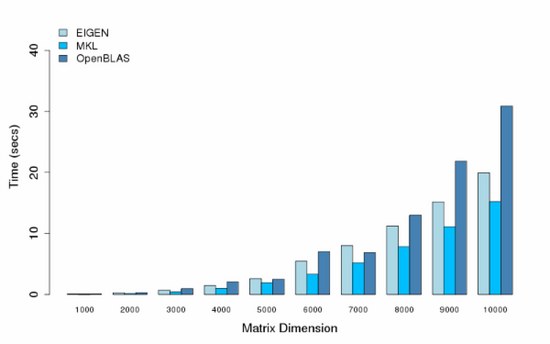
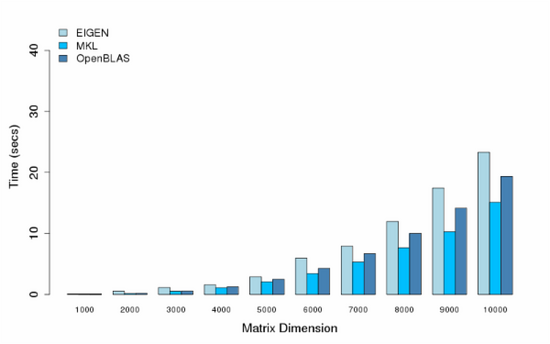
在多线程的测试中,我们采用多个CPU核心来做矩阵乘法运算,所有的结果也同样采用5轮训练,我们采用的CPU核数分别是8,16,32,48。
- Cores = 8
- Cores = 16
- Cores = 32
- Cores = 40
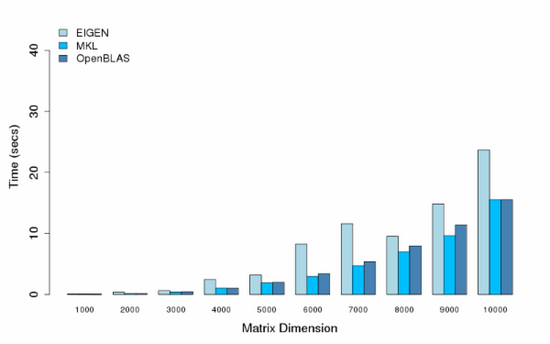
- Cores = 48
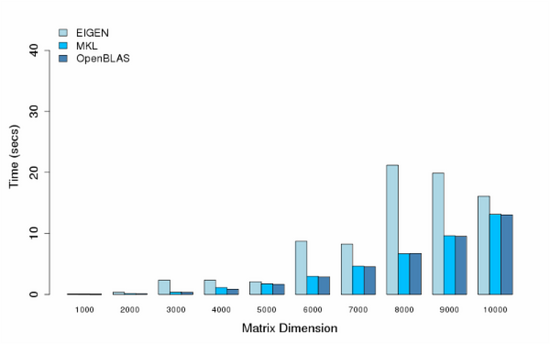
可以看出,MKL和OpenBLAS都提供了比较好的性能,MKL性能还更好一点,在各别多线程条件下了,可能某些原因或者我机器设置的问题,出现了各别性能异常,比如小矩阵运算时间反倒比大矩阵运算长,或者更多的线程却不能提供更好的性能。这些情况后面可能还需要查一查。
- 伸缩性
另外,我也测试了使用不同的cpu核数对性能的影响,下面两个图描述了把cpu从1增加到20的条件下,5000×5000的矩阵相乘的时间开销和加速比。
- 结论
就我的测试环境而言,Intel MKL 和 OpenBLAS 似乎是矩阵相乘运算方面性能最佳的 BLAS 库,在多核以及不同规模的矩阵方面都具有较好的伸展性和稳定性,而对于单线程情况,OpenBLAS相比 MKL 在性能上有一定提升。

