
整个网站的瓶颈是什么?
- 数据量如果太大,一个机器放不下
- 数据的索引(B+Tree),一个机器内存也放不下
- 访问量(读写混合),一个服务器承受不了
只要开始出现以上的三种情况之一,那么就一定要晋级!
- Memcached(缓存) + MySQL + 垂直拆分(数据库读写分离)
网站80%的情况都是在读,每次都要去查询数据库的话十分麻烦,所以说我们希望减轻数据的压力,可以使用缓存来保证效率!
发展过程:优化数据结构和索引–>文件缓存(IO)–>Memcached
- 分库分表 + 水平拆分 + MySQL集群
早些年MyISAM:表锁,十分影响效率,高并发下就会出现严重的锁问题
转战Innodb:行锁
慢慢的就开始使用分库分表来解决写的压力!MySQL在那个年代推出了表分区,但是现在并没有多少公司使用。
MySQL的集群,很好满足那个时代的所有需求!
- 如今的年代
定位数据、音乐数据,热榜数据等,MySQL这样的关系性数据库就不够用了,数据量很多,变化很快!
如果使用MySQL存储一些比较大的文件,如博客和图片等等。数据量很大,效率就低了!如果有一种数据库来专门处理这种数据,MySQL的压力就变得十分小(研究如何处理这类问题)。大数据的IO压力下,表几乎没法更大!
- 为什么要使用NoSQL
用户的个人信息,社交网络,地理位置,用户自己产生的数据,用户日志等等爆发式增长!
这时候我们就需要使用NoSQL数据库的,Nosql可以很好的处理以上的情况
2. 什么是NoSQLNoSQL = Not Only SQL(不仅仅是SQL)
泛指非关系性数据库,随着web2.0互联网的诞生!传统的关系性数据库很难应付,尤其是超大规模的高并发的社区!暴露出来很多难以克服的问题,NoSQL在当今大数据环境下发展的十分迅速,Redis是当下必须掌握的一个技术!
如用户的个人信息,社交网络,地理位置。这些数据类型的存储不需要一个固定的格式!不需要多余的操作就可以横向扩展了。Map 来控制的。
- NoSQL特点
解耦!
- 方便扩展(数据之间没有关系,很好扩展)
- 大数据量高性能(Redis一秒写8万次,读取11万条数据,NoSQL的缓存记录级是一种细粒度的缓存,性能会比较高!)
- 数据类型是多样型的!(不需要事先设计数据库!随取随用,如果是数据库量十分大的表,很多人就无法设计了)
- 传统RDBS(关系型数据库系统)和NoSQL(非关系型数据库系统)
传统的RDBS(关系性数据库)
- 结构化组织
- SQL语言
- 数据和关系都存在单独的表中 row col
- 严格的一致性
- 基础的事务
......
Nosql
- 不仅仅是数据
- 没有固定的查询语言
- 键值对存储,列存储,文档存储,图形数据库(社交关系)
- 最终一致性
- CAP定理 和 BASE(异地多活)
- 高性能,高可用,高可扩展性
......
- 了解:3V + 3高
大数据时代的3V:主要是描述问题的
- 海量Volume
- 多样Variety
- 实时Velocity
大数据时代的3高:主要是对程序的要求
- 高并发
- 高可扩
- 高性能
真正在公司中的实践:NoSQL + RDBMS一起使用
- 架构师:没有什么是加一层解决不了的!
bash
# 1、商品的基本信息
名称、价格、商家信息:
关系性数据库就可以解决了!MySQL / Oracle(淘宝早年就去IOE了! - 王坚:
推荐文章:阿里云的这群疯子)
# 2、商品的描述、评论(文字比较多)
文档型数据库中,Redis / MongoDB
# 3、图片
- 分布式文件系统 FastDFS
- 淘宝的 FTPS
- Google GFS
- Hadoop HDFS
- 阿里云的 oss
# 4、商品的关键字(搜索)
- 搜索引擎 solr elasticsearch
- ISearch 了解多隆大佬
# 5、商品热门的波段信息
- 内存数据库
- Redis Tair、Memache...
# 6、商品的交易,外部的支付接口
- 三方应用
大型互联网应用问题:
- 数据类型太多了
- 数据源繁多,经常重构
- 数据大面积改造
解决办法:
在应用层和数据层之间加一层统一数据服务平台!
3. NoSQL的四大分类KV键值对
- 新浪:Redis
- 美团:Redis + Tair
- 阿里,百度:Redis + memcache
文档型数据库(bson格式,和json一样)
- MongoDB(一般必须要掌握)
- MongoDB是一个基于分布式文件存储的数据库,C++编写
- MongoDB是一个介于关系型数据库和非关系型数据库中间的产品!MongoDB是非关系型数据库中功能最丰富,最像关系型数据库的!
- ConthDB
列存储数据库
- HBase
- 分布式文件系统
图关系数据库
- Neo4j
- InfoGrid
Redis是什么?
Redis(Remote Dictionary Server),即远程字典服务。是一个开源的使用ANSI C语言编写、支持网络、可基于内存亦可持久化的日志型、Key-Value数据库,并提供多种语言的API。
免费和开源!是当下最热门的NoSQL技术之一!也被人们称之为结构化数据库!
Redis能干什么?
- 内存存储、持久化
- 效率高,用于高速缓存
- 发布订阅系统
- 地图信息分析
- 计时器、计数器(浏览量)
- …….
特性
- 多样化的数据类型
- 持久化
- 集群
- 事务
学习中需要用到的东西
- 官网:https://redis.io/
- 中文网:http://www.redis.cn/
- 下载地址:官网下载即可
- Windows在Github上下载(不建议),Redis推荐在Linux服务器上搭建
- 下载安装包:redis-6.2.5.tar.gz
- 解压Redis的安装包!程序解压到/opt
bash
sudo mv redis-6.2.5.tar.gz /opt
cd /opt
sudo tar -zxvf redis-6.2.5.tar.gz
# 在解压后的文件中可以看到redis配置文件redis.conf
sudo install gcc-c++
sudo make
# 第一次make编译需要一段时间,第二次make就快了
sudo make
sudo make install
make编译成功
-
redis的默认安装路径为/usr/local/bin
-
将redis配置文件复制到我们当前目录下之后就使用这个配置文件进行启动之后就使用这个配置文件进行启动
bash
sudo mkdir tconfig
sudo cp /opt/redis-6.2.5/redis.conf tconfig/
cd tconfig/
ls
- redis默认不是后台启动的,修改配置文件!
bash
vim redis.conf
# 把daemonize从no改为yes(以后台方式启动)
daemonize yes
# :wq 保存退出
- 启动redis服务
bash
cd /usr/local/bin
# 通过指定的配置文件启动
redis-server tconfig/redis.conf
# 使用redis-cli客户端测试连接
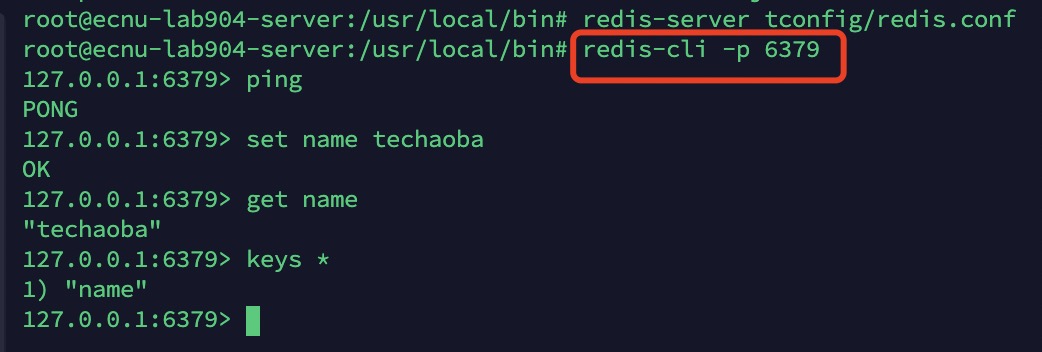
- 查看redis的进程是否开启

- 关闭Redis服务
使用shotdown或者kill
- 后面会使用单机多Redis启动集群测试!
redis-benchmark是官方自带的性能测试工具!
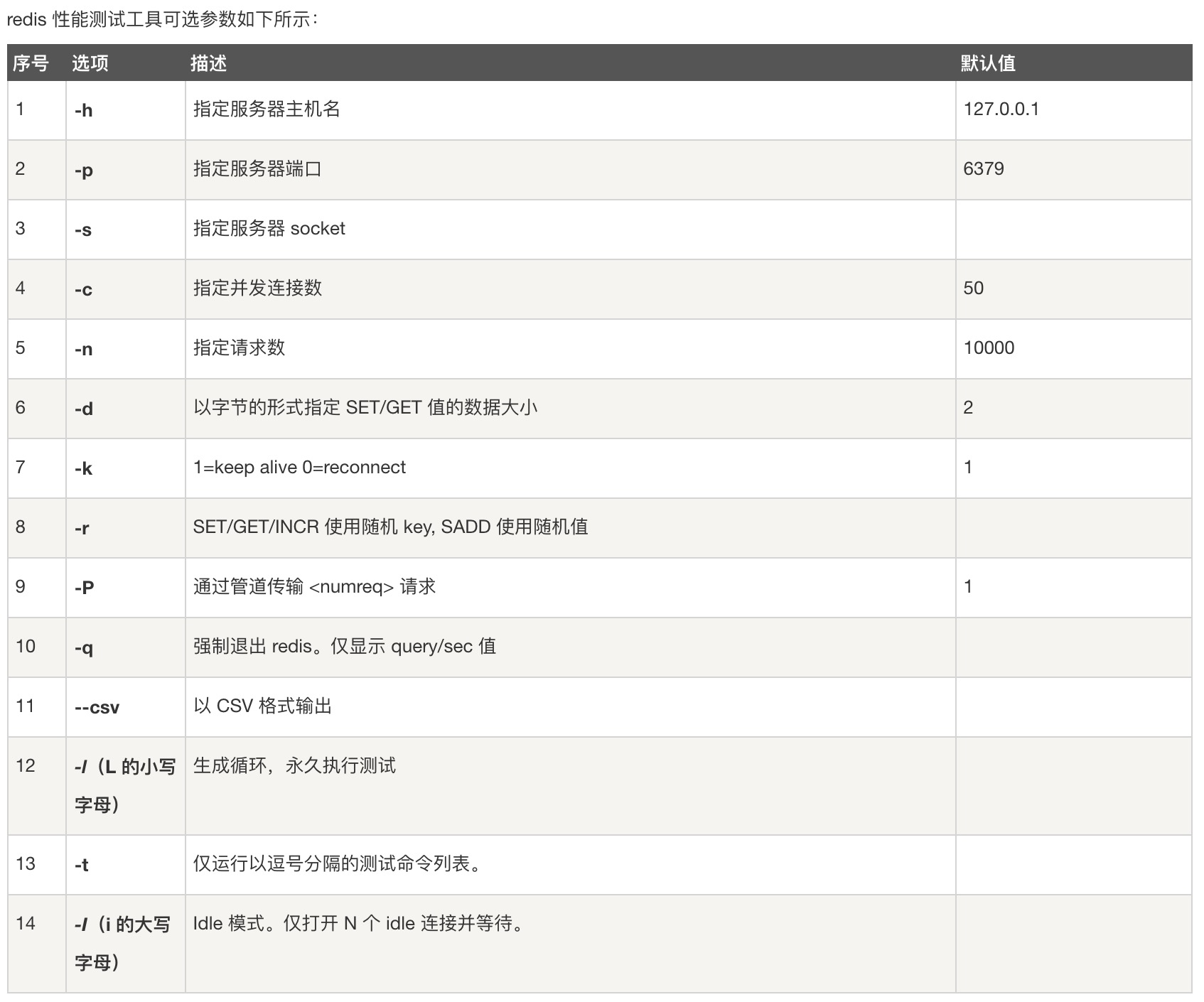
简单测试下:
bash
# 启动
cd /usr/local/bin
redis-server tconfig/redis.conf
redis-cli -p 6379
ping
# 测试:100个并发连接 100000个请求
redis-benchmark -h localhost -p 6379 -c 100 -n 100000
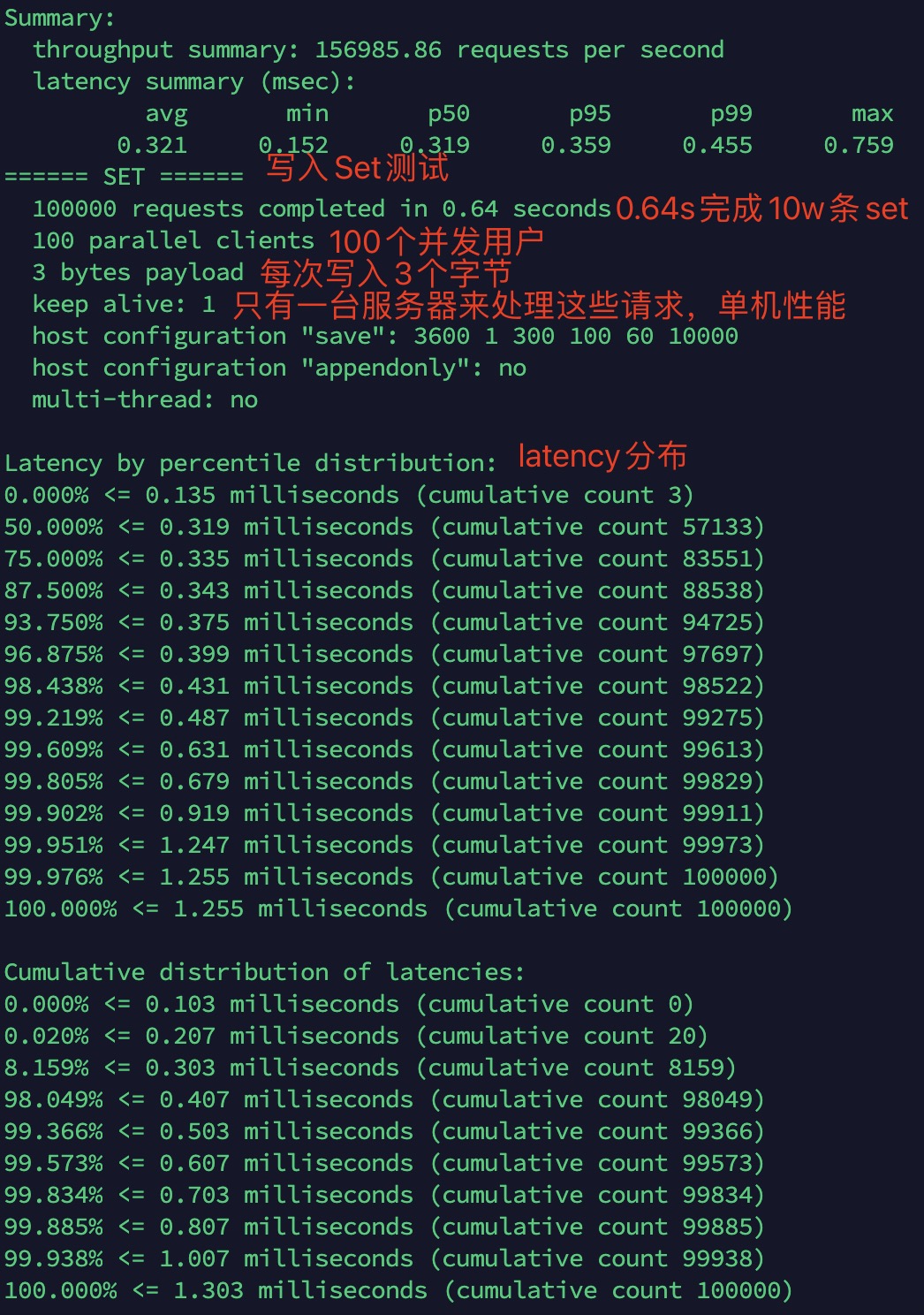
性能测试结果
7. 基础知识redis默认有16个数据库,默认使用第0个数据库(vim redis.conf)
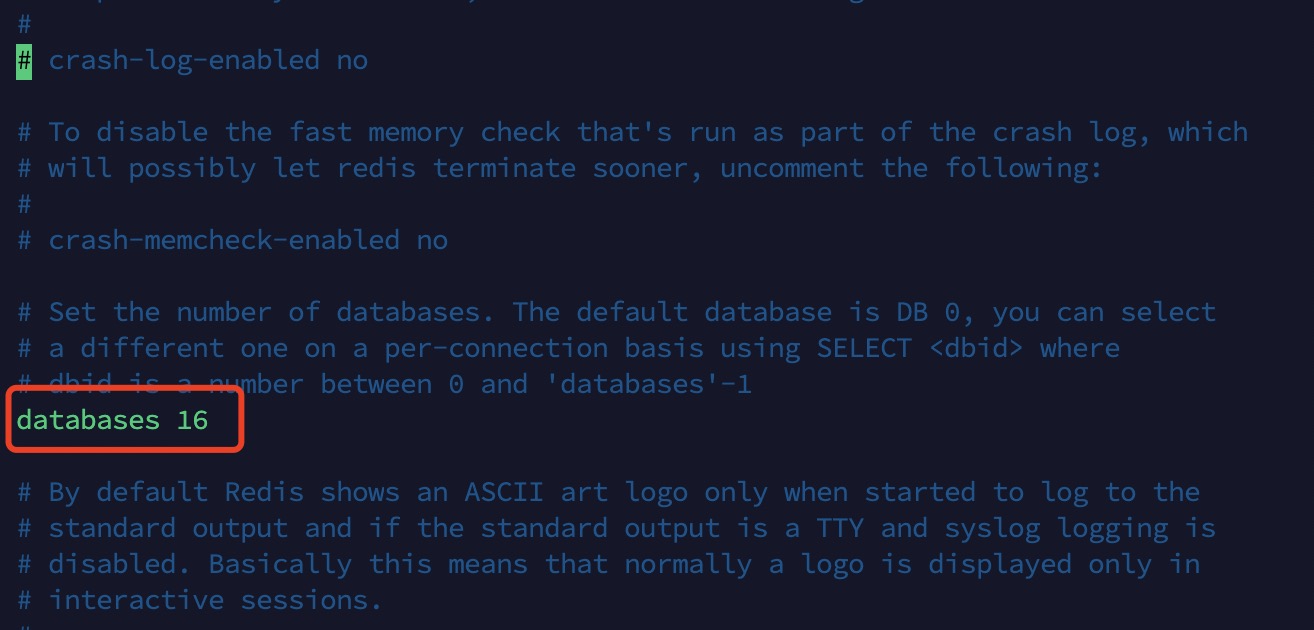
默认有16个数据库
可以使用SELECT切换数据库
DBSIZE查看当前数据库空间
bash
root@ecnu-lab904-server:/usr/local/bin# redis-cli -p 6379
127.0.0.1:6379> ping
PONG
127.0.0.1:6379> SELECT 3
OK
127.0.0.1:6379[3]> DBSIZE
(integer) 0
GET和SET方法
bash
127.0.0.1:6379[3]> SET name techaoba
OK
127.0.0.1:6379[3]> get name
"techaoba"
127.0.0.1:6379[3]> keys *
1) "name"
清除当前数据库(flushdb),清空全部数据库(flushall)
bash
127.0.0.1:6379[3]> keys *
1) "name"
127.0.0.1:6379[3]> flushdb
OK
127.0.0.1:6379[3]> keys *
(empty array)
- EXISTS [key]
- MOVE [key] [db]
- EXPIRE [key] [seconds]
- TTL [key] # 查看当前key的剩余时间
- KEYS * # 查看所有的key
- TYPE [key] # 查看当前key的类型
- SET [key] [value]
- GET [key]
bash
# 判断是否存在
127.0.0.1:6379> EXISTS age
(integer) 1
# 移动数据到其他数据库
127.0.0.1:6379> MOVE name 1
(integer) 1
127.0.0.1:6379> KEYS *
1) "age"
127.0.0.1:6379> SELECT 1
OK
127.0.0.1:6379[1]> GET name
"techaoba"
# 设置数据的过期时间(ttl 查看剩余时间,-2表示已过期)
127.0.0.1:6379> EXPIRE name 10
(integer) 1
127.0.0.1:6379> ttl name
(integer) 4
127.0.0.1:6379> ttl name
(integer) -2
127.0.0.1:6379> get name
(nil)
127.0.0.1:6379> SET name techaoba
OK
# 查看数据类型 TYPE
127.0.0.1:6379> TYPE name
string
- APPEND [key] [value] # 字符串追加(如果当前key不存在就相当于set)
- STRLEN [key] # 获取字符串长度
bash
127.0.0.1:6379> SET key1 v1
OK
127.0.0.1:6379> get key1
"v1"
127.0.0.1:6379> APPEND key1 hello
(integer) 7
127.0.0.1:6379> get key1
"v1hello"
127.0.0.1:6379> strlen key1
(integer) 7
127.0.0.1:6379> APPEND key1 ", techaoba"
(integer) 17
127.0.0.1:6379> get key1
"v1hello, techaoba"
- INCR [key] # 自增1
- DECR [key] # 自减1
- INCRBY [key] [10] # 自增10
- DECRBY [key] [5] # 自减5
bash
127.0.0.1:6379> set views 0
OK
127.0.0.1:6379> get views
"0"
127.0.0.1:6379> incr views
(integer) 1
127.0.0.1:6379> incr views
(integer) 2
127.0.0.1:6379> get views
"2"
127.0.0.1:6379> decr views
(integer) 1
127.0.0.1:6379> decr views
(integer) 0
127.0.0.1:6379> decr views
(integer) -1
127.0.0.1:6379> INCRBY views 10
(integer) 9
127.0.0.1:6379> DECRBY views 5
(integer) 4
- GETRANGE [key] [startIndex] [endIndex] # 获取字符串范围
bash
127.0.0.1:6379> set key1 "hello, techaoba"
OK
127.0.0.1:6379> get key1
"hello, techaoba"
127.0.0.1:6379> GETRANGE key1 1 5
"ello,"
127.0.0.1:6379> GETRANGE key1 3 -1 # -1表示最后
"lo, techaoba"
- SETRANGE [key] [startIndex] [value] # 从startIndex开始Set
bash
127.0.0.1:6379> SET key2 abcdefg
OK
127.0.0.1:6379> get key2
"abcdefg"
127.0.0.1:6379> SETRANGE key2 1 xx
(integer) 7
127.0.0.1:6379> get key2
"axxdefg"
127.0.0.1:6379> SETRANGE key2 6 xxxxxx
(integer) 12
127.0.0.1:6379> get key2
"axxdefxxxxxx"
- setex [key] [seconds] [value](set with expire) # 设置过期时间
- setnx [key] [value](set if not exist) # 不存在设置(在分布式锁中会常常使用)
bash
# 设置key3的过期时间为30秒
127.0.0.1:6379> setex key3 30 "hello"
OK
127.0.0.1:6379> TTL key3
(integer) 24
127.0.0.1:6379> setnx mykey "redis"
(integer) 1
127.0.0.1:6379> keys *
1) "mykey"
127.0.0.1:6379> TTL key3
(integer) -2
# 由于mykey已经有值了,所以setnx mykey会设置失败
127.0.0.1:6379> setnx mykey "MongoDB"
(integer) 0
127.0.0.1:6379> get mykey
"redis"
- mset [key1] [value1] [key2] [value2] … # 批量设置值
- mget [key1 key2 …] # 批量获取值
- mset[key1] [value1] [key2] [value2] … # 批量不存在设置值具有原子性具有原子性
bash
# 批量设置
127.0.0.1:6379> mset k1 v1 k2 v2 k3 v3
OK
127.0.0.1:6379> keys *
1) "k1"
2) "k3"
3) "k2"
# 批量获取值
127.0.0.1:6379> mget k1 k2 k3
1) "v1"
2) "v2"
3) "v3"
# msetnx具有原子性操作,由于k1已经存在,k4也会设置失败
127.0.0.1:6379> msetnx k1 v100 k4 v4
(integer) 0
127.0.0.1:6379> get k4
(nil)
- 对象
bash
set user:1 {name:zhangsan,age:3} # 设置一个user:1对象 值为json字符来保存一个对象!
127.0.0.1:6379> get user:1
"{name:zhangsan,age:3}"
127.0.0.1:6379> mset user:2:name lisi user:2:age 2
OK
127.0.0.1:6379> mget user:2:name user:2:age
1) "lisi"
2) "2"
- getset # 先get再set
bash
# 开始没有值,输出nil
127.0.0.1:6379> getset db redis
(nil)
127.0.0.1:6379> get db
"redis"
# 开始值是redis,get完后设置为MongDB
127.0.0.1:6379> getset db MongDB
"redis"
127.0.0.1:6379> get db
"MongDB"
String类似的使用场景:value除了是字符串还可以是数字
- 计数器
- 统计多单位数量 uid:958285378:follow 19032 bilibili里面uid下的粉丝数量bilibili里面uid下的粉丝数量
在Redis里面,可以把List完成栈、队列、阻塞队列
所有的List命令都是用l开头的
- LPUSH [key] [value] # 将一个或者多个值插入到列表的头部(左)
- RPUSH [key] [value] # 将一个或者多个值插入到列表的尾部(右)
- LPOP [key] # 从左边弹出
- RPOP [key] # 从右边弹出
- LRANGE [key] [startIndex] [endIndex] # 从左边查看值
bash
# LPUSH 将一个或者多个值插入到列表的头部(左)
127.0.0.1:6379> LPUSH list one
(integer) 1
127.0.0.1:6379> LPUSH list tuo
(integer) 2
127.0.0.1:6379> LPOP list # 从左边弹出
"tuo"
127.0.0.1:6379> LPUSH list two
(integer) 2
127.0.0.1:6379> LPUSH list three
(integer) 3
127.0.0.1:6379> LRANGE list 0 -1 # 从左边查看值
1) "three"
2) "two"
3) "one"
127.0.0.1:6379> LRANGE list 0 1 # 从左边查看值
1) "three"
2) "two"
# 将一个或者多个值插入到列表的尾部(右)
127.0.0.1:6379> RPUSH list right
(integer) 4
127.0.0.1:6379> LRANGE list 0 -1
1) "three"
2) "two"
3) "one"
4) "right"
- LINDEX [key] [index] # 通过下表获得list中的某一个值
- LLEN [key] # 获取list的长度
bash
127.0.0.1:6379> LRANGE list 0 -1
1) "three"
2) "two"
3) "one"
4) "right"
127.0.0.1:6379> LINDEX list 1 # 通过下标获得list中的某一个值
"two"
127.0.0.1:6379> LINDEX list -1 # 通过下标获得list中的某一个值
"right"
127.0.0.1:6379> LLEN list # 获取list的长度
(integer) 4
- LREM [list] [count] [key] # 移除list集合中指定个数的value,精确匹配
bash
127.0.0.1:6379> LPUSH list three
(integer) 5
127.0.0.1:6379> LREM list 1 one # 从左开始移除一个one
(integer) 1
127.0.0.1:6379> LRANGE list 0 -1
1) "three"
2) "three"
3) "two"
4) "right"
127.0.0.1:6379> LREM list 2 three # 从左开始移除两个three
(integer) 2
127.0.0.1:6379> LRANGE list 0 -1
1) "two"
2) "right"
- ltrim [list] [startIndex] [endIndex] 修剪,list已经被改变了
bash
127.0.0.1:6379> RPUSH mylist "hello"
(integer) 1
127.0.0.1:6379> RPUSH mylist "hello1"
(integer) 2
127.0.0.1:6379> RPUSH mylist "hello2"
(integer) 3
127.0.0.1:6379> RPUSH mylist "hello3"
(integer) 4
127.0.0.1:6379> ltrim mylist 1 2
OK
127.0.0.1:6379> LRANGE mylist 0 -1
1) "hello1"
2) "hello2"
- RPOPLPUSH [sourceList] [targetList] # 移除列表的最后一个元素,移动到新列表中
bash
127.0.0.1:6379> RPUSH mylist "hello"
(integer) 1
127.0.0.1:6379> RPUSH mylist "hello1"
(integer) 2
127.0.0.1:6379> RPUSH mylist "hello2"
(integer) 3
127.0.0.1:6379> RPOPLPUSH mylist myotherlist
"hello2"
127.0.0.1:6379> LRANGE mylist 0 -1
1) "hello"
2) "hello1"
127.0.0.1:6379> LRANGE myotherlist 0 -1
1) "hello2"
- LSET [list] [index] [value] # 更新list元素
bash
127.0.0.1:6379> LPUSH list value1
(integer) 1
127.0.0.1:6379> LRANGE list 0 -1
1) "value1"
127.0.0.1:6379> LSET list 0 item
OK
127.0.0.1:6379> LRANGE list 0 -1
1) "item"
- LINSERT [list] before [value] [newValue]
- LINSERT [list] after [value] [newValue]
bash
127.0.0.1:6379> RPUSH mylist "hello"
(integer) 1
127.0.0.1:6379> RPUSH mylist "world"
(integer) 2
# 在world前插入other
127.0.0.1:6379> LINSERT mylist before "world" "other"
(integer) 3
127.0.0.1:6379> LRANGE mylist 0 -1
1) "hello"
2) "other"
3) "world"
# 在world后插入一个new
127.0.0.1:6379> LINSERT mylist after "world" "new"
(integer) 4
127.0.0.1:6379> LRANGE mylist 0 -1
1) "hello"
2) "other"
3) "world"
4) "new"
set中的值不能重复!
- SADD [set] [value] # set添加元素
- SMEMBERS [set] # 查看set成员
- SISMEMBER [set] [value] # 判断set是否有某成员
- SCARD [set] # 查看set成员个数
- SREM [set] [value] # 移除成员
- SRANDMEMBER [set] [[count]] # 随机挑选set中的一个元素,可指定个数
- SPOP [set] # 随机移除一个set元素
bash
127.0.0.1:6379> SADD myset "hello" # set添加元素
(integer) 1
127.0.0.1:6379> SADD myset "techaoba"
(integer) 1
127.0.0.1:6379> SADD myset "lovetechaoba"
(integer) 1
127.0.0.1:6379> SMEMBERS myset # 查看set成员
1) "hello"
2) "lovetechaoba"
3) "techaoba"
127.0.0.1:6379> SISMEMBER myset techaoba # 判断set是否有某成员
(integer) 1
127.0.0.1:6379> SISMEMBER myset techaoba0
(integer) 0
127.0.0.1:6379> SCARD myset # 查看set成员个数
(integer) 3
127.0.0.1:6379> SADD myset "lovetechaoba2"
(integer) 1
127.0.0.1:6379> SCARD myset
(integer) 4
127.0.0.1:6379> SADD myset "lovetechaoba2" # 插入重复成员会失败
(integer) 0
127.0.0.1:6379> SREM myset "hello" # 移除hello元素
(integer) 1
127.0.0.1:6379> SMEMBERS myset
1) "lovetechaoba2"
2) "lovetechaoba"
3) "techaoba"
127.0.0.1:6379> SRANDMEMBER myset # 随机挑选set中的一个元素
"lovetechaoba2"
127.0.0.1:6379> SRANDMEMBER myset
"lovetechaoba"
127.0.0.1:6379> SRANDMEMBER myset
"techaoba"
127.0.0.1:6379> SRANDMEMBER myset
"lovetechaoba"
127.0.0.1:6379> SRANDMEMBER myset 2 # 随机挑选set中的两个元素
1) "lovetechaoba2"
2) "techaoba"
127.0.0.1:6379> SPOP myset # 随机移除一个set元素
"lovetechaoba2"
127.0.0.1:6379> SPOP myset
"lovetechaoba"
127.0.0.1:6379> SMEMBERS myset
1) "techaoba"
- SMOVE [set] [set2] [value]
bash
127.0.0.1:6379> SADD myset "hello"
(integer) 1
127.0.0.1:6379> SADD myset "world"
(integer) 1
127.0.0.1:6379> SADD myset "techaoba"
(integer) 1
127.0.0.1:6379> SADD myset2 "set2"
(integer) 1
127.0.0.1:6379> SMOVE myset myset2 "techaoba" # 移动set元素到另一个set中
(integer) 1
127.0.0.1:6379> SMEMBERS myset
1) "hello"
2) "world"
127.0.0.1:6379> SMEMBERS myset2
1) "set2"
2) "techaoba"
微博和B站中有共同关注!(交集)
数字集合类:
- 差集 SDIFF [set1] [set2] …
- 交集 SINTER [set1] [set2] …
- 并集 SUNION [set1] [set2] …
bash
127.0.0.1:6379> SADD key1 a
(integer) 1
127.0.0.1:6379> SADD key1 b
(integer) 1
127.0.0.1:6379> SADD key1 c
(integer) 1
127.0.0.1:6379> SADD key2 c
(integer) 1
127.0.0.1:6379> SADD key2 d
(integer) 1
127.0.0.1:6379> SADD key2 e
(integer) 1
127.0.0.1:6379> SDIFF key1 key2 # 差集
1) "b"
2) "a"
127.0.0.1:6379> SINTER key1 key2 # 交集
1) "c"
127.0.0.1:6379> SUNION key1 key2 # 并集
1) "a"
2) "c"
3) "b"
4) "e"
5) "d"

