
一、正则表达式详解
正则表达式是一个特殊的字符序列,便于检查一个字符串是否与某种模式匹配。通过定义规则,使得从字符串中把符合规则的字符串提取出来。
正则表达式的作用:
- 在实际开发过程中经常会有查找符合某些复杂规则的字符串的需要,比如:手机号、邮箱、图片地址等,这时候想匹配或者查找符合某些规则的字符串就可以使用正则表达式了;
正则表达式的特点:
- 正则表达式的语法太多,可读性差;
- 正则表达式通用行很强,能够适用于很多编程语言;
正则表达式的应用场景:
- 判断一个字符串是否符合规则;
- 取出制定数据;
- 爬虫岗位较为核心的技术;
- 彩票网站匹配彩票信息;
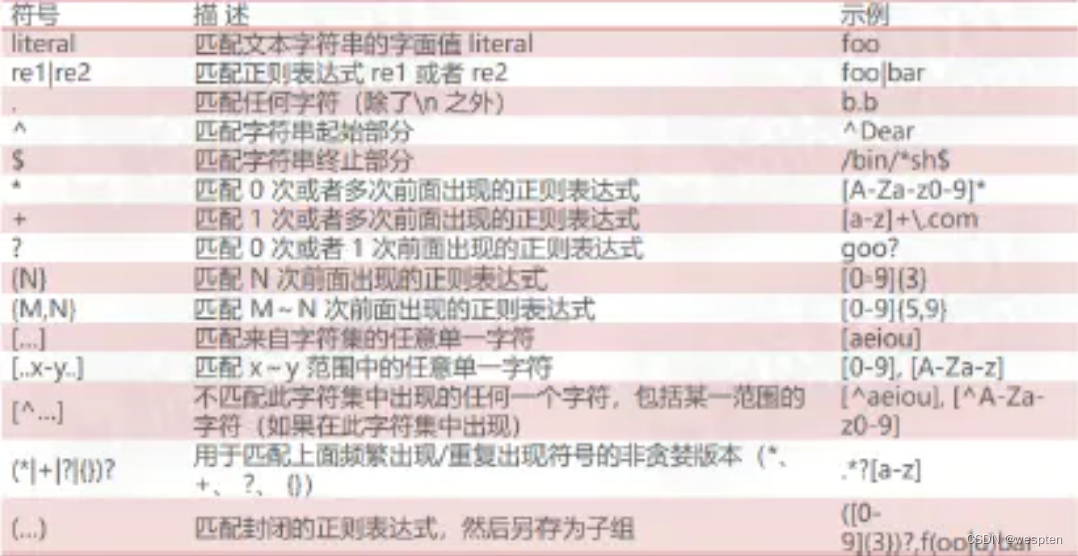
匹配单个字符:
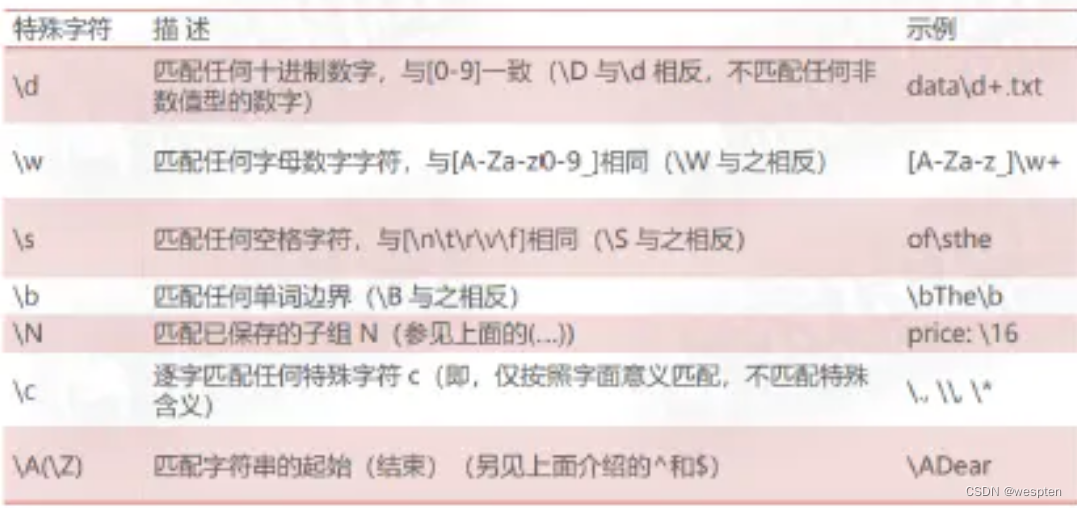
正则表达式中的特殊字符:
正则表达式的扩展表示法:

|是或的关系,只要存在就会被捕获- 匹配到的数据只按字符串顺序返回,而不是按照匹配规则返回
In [18]: data = 'insane@loafer.com'
In [19]: print(re.findall('insane|com|loafer', data))
['insane', 'loafer', 'com']- ^ 等同于 \A
In [20]: print(re.findall('^insane',data))
['insane']
In [21]: print(re.findall('^insane1',data))
[]- $ 等同于 \Z
In [22]: print(re.findall('com$',data))
['com']
In [23]: print(re.findall('net$',data))
[]- * 匹配0次或多次
In [24]: print(re.findall('\w*',data))
['insane', '', 'loafer', '', 'com', '']- + 匹配1次或多次
- w+ 匹配1次或多次数字或字母
- @和.属于0次范围,不会被匹配出来
In [25]: print(re.findall('\w+',data))
['insane', 'loafer', 'com']- {3} 表示对于匹配到的数据只获取3次
In [31]: data = 'insane@loaf.com'
In [32]: print(re.findall('\w{3}',data))
['ins', 'ane', 'loa', 'com']
In [33]: print(re.findall('[a-z]{3}',data))
['ins', 'ane', 'loa', 'com'][a-zA-Z0-9] 基本上等同于 \w。
- {M, N} 表示对于匹配到的数据只获取M~N次
In [34]: data = 'insane@loaf.com'
In [35]: print(re.findall('\w{1,4}',data))
['insa', 'ne', 'loaf', 'com']- 反例:N 和 M 中间不能有空格
In [36]: print(re.findall('\w{1, 4}',data))
[]- [^...] 表示不匹配字符集中的字符
In [37]: data = 'insane@loaf.com'
In [38]: print(re.findall('[^insane]',data))
['@', 'l', 'o', 'f', '.', 'c', 'o', 'm']In [42]: test = 'hello my name is insane'
In [43]: result = re.search('hello (.*) name is (.*)', test)
In [44]: result.groups()
Out[44]: ('my', 'insane')
In [45]: result.groups(1)
Out[45]: ('my', 'insane')
In [46]: result.group(1)
Out[46]: 'my'
In [47]: result.group(2)
Out[47]: 'insane'贪婪与非贪婪
- 0次或多次属于贪婪模式
- 通过?组合变成非贪婪模式
#!/usr/bin/python3
# -*- coding: utf-8 -*-
# @Time : 2021/8/28 22:13
# @Author : InsaneLoafer
# @File : re_test2.py
import re
def check_url(url):
"""
判断url是否合法
:param url:
:return:
"""
result = re.findall('[a-zA-Z]{4,5}://\w*\.*\w+\.\w+', url)
if len(result) != 0:
return True
else:
return False
def get_url(url):
"""
通过组获取url中的某一部分
:param url:
:return:
"""
result = re.findall('[https://|http://](\w*\.*\w+\.\w+)', url)
if len(result) != 0:
return result[0]
else:
return ''
def get_email(data):
# result = re.findall('[0-9a-zA-Z_]+@[0-9a-zA-Z]+\.[a-zA-Z]+', data)
result = re.findall('.+@.+\.[a-zA-Z]+', data)
return result
html = (''
'')
def get_html_data(data):
"""
获取style中的display:
使用非贪婪模式
"""
result = re.findall('style="(.*?)"', data)
return result
def get_all_data_html(data):
"""
获取html中所有等号后双引号内的字符
:param data:
:return:
"""
result = re.findall('="(.+?)"', data)
return result
if __name__ == '__main__':
result = check_url('https://www.baidu.com')
print(result)
result = get_url('https://www.baidu.com')
print(result, 'https')
result = get_url('http://www.baidu.com')
print(result, 'http')
result = get_email('insane@163.net')
print(result)
result = get_html_data(html)
print(result)
result = get_all_data_html(html)
print(result)True
www.baidu.com https
www.baidu.com http
['insane@163.net']
['display:none;']
['s-top-nav', 'display:none;', 's-center-box']
Process finished with exit code 0
In [1]: import re
In [2]: data = 'hello insane you are 26 years old'
In [3]: print(re.findall('\d', data))
['2', '6']
In [4]: print(re.findall('\s', data))
[' ', ' ', ' ', ' ', ' ', ' ']
In [5]: data = 'i am insane'
In [6]: print(re.findall('\w', data))
['i', 'a', 'm', 'i', 'n', 's', 'a', 'n', 'e']
In [7]: data = 'i am insane, i am 26'
In [8]: print(re.findall('\w', data))
['i', 'a', 'm', 'i', 'n', 's', 'a', 'n', 'e', 'i', 'a', 'm', '2', '6']
In [9]: data = 'hello insane you are 26 years old'
In [10]: print(re.findall('\Ahello', data))
['hello']
In [11]: print(re.findall('\Ahellos', data))
[]
In [12]: print(re.findall('old\Z', data))
['old']
In [13]: print(re.findall('aold\Z', data))
[]
In [14]: print(re.findall('.', data))
['h', 'e', 'l', 'l', 'o', ' ', 'i', 'n', 's', 'a', 'n', 'e', ' ', 'y', 'o', 'u', ' ', 'a', 'r', 'e', ' ', '2', '6', ' ', 'y', 'e', 'a', 'r', 's', ' ', 'o', 'l', 'd']
实战
#!/usr/bin/python3
# -*- coding: utf-8 -*-
# @Time : 2021/8/28 19:52
# @Author : InsaneLoafer
# @File : re_test1.py
import re
def had_number(data):
result = re.findall('\d', data)
print(result)
for i in result:
return True
return False
def remove_number(data):
result = re.findall('\D', data)
print(result)
return ''.join(result)
def startswith(sub, data):
_sub = '\A%s' % sub
result = re.findall(_sub, data)
for i in result:
return True
return False
def endswith(sub, data):
_sub = '%s\Z' % sub
result = re.findall(_sub, data)
if len(result) != 0:
return True
else:
return False
def real_len(data):
"""
去掉字符串空格,判断真实长度
:param data:
:return:
"""
result = re.findall('\S', data)
print(result)
return len(result)
if __name__ == '__main__':
data = 'i am insane, i am 26'
result = had_number(data)
print(result)
result = remove_number(data)
print(result)
data = 'hello insane, i am loafer. i am 26 year\'s old'
print(re.findall('\W', data))
result = startswith('hello', data)
print(result)
result = endswith('old', data)
print(result)
print(len(data))
result = real_len(data)
print(result)['2', '6']
True
['i', ' ', 'a', 'm', ' ', 'i', 'n', 's', 'a', 'n', 'e', ',', ' ', 'i', ' ', 'a', 'm', ' ']
i am insane, i am
[' ', ',', ' ', ' ', ' ', '.', ' ', ' ', ' ', ' ', "'", ' ']
True
True
45
['h', 'e', 'l', 'l', 'o', 'i', 'n', 's', 'a', 'n', 'e', ',', 'i', 'a', 'm', 'l', 'o', 'a', 'f', 'e', 'r', '.', 'i', 'a', 'm', '2', '6', 'y', 'e', 'a', 'r', "'", 's', 'o', 'l', 'd']
36
Process finished with exit code 0import re
str_data = 'hello insane, this is a good day!'
result = re.search('h([a-zA-Z])s', str_data)
print(result.groups())
>>> ('i',)- search()只匹配一次
import re
str_data = '本期彩票结果为: 10, 20, 1, 5, 7, 21, 22'
result = re.findall('(\d+, \d+, \d+, \d+, \d+, \d+, \d+)', str_data)
print(result)
>>> ['10, 20, 1, 5, 7, 21, 22']- \d:匹配数字
- +:匹配一个或多个
1)findall()的使用
findall(pattern , string, [flags])- 查找字符串中所有(非重复)出现的正则表达式模式,并返回一个匹配列表
2)search()的使用
search(pattern , string , flags=0)- 使用可选标记搜索字符串中第一次出现的正则表达式模式。如果匹配成功,则返回匹配对象如果失败,则返回None
3)group()与groups()
- group(num)返回整个匹配对象,或者编号为num的特定子组
- groups():返回一个包含所有匹配子组的元组(如果没有成功匹配,则返回一个空元组)
In [1]: test = 'hello my name is insane'
In [2]: import re
In [3]: result = re.search('hello (.*) name is (.*)', test)
In [4]: result.groups()
Out[4]: ('my', 'insane')
In [5]: result.group(1)
Out[5]: 'my'
In [6]: result.group(2)
Out[6]: 'insane'4)split()正则替换
split(pattern, string , max=0)- 根据正则表达式的模式分隔符,split 函数将字符串分割为列表,然后返回成功匹配的列表,分隔最多操作max 次(默认分割所有匹配成功的位置)
In [7]: data = 'hello world'
In [8]: print(re.split('\W', data))
['hello', 'world']5)re模块-match
match(pattern , string , flags=0)- 尝试使用带有可选的标记的正则表达式的模式来匹配字符串。如果匹配成功,就返回匹配对象;如果失败,就返回None。
- match只会匹配字符串从头开始的信息,如果匹配成功,就返回匹配对象;如果失败,就返回None。
- match返回的对象也可以使用
group函数调用
In [10]: result = re.match('hello', data)
In [11]: result.groups()
Out[11]: ()
In [12]: result.group()
Out[12]: 'hello'6)re模块-compile
compile(pattern, flags=0)- 定义一个匹配规则的对象
In [13]: data='hello my email is insane@loaf.com i like python'
In [14]: re_obj = re.compile('email is (.*?) i')
In [15]: result = re_obj.findall(data)
In [16]: result
Out[16]: ['insane@loaf.com']7)re的额外匹配要求
#!/usr/bin/python3
# -*- coding: utf-8 -*-
# @Time : 2021/8/28 22:13
# @Author : InsaneLoafer
# @File : re_test2.py
import re
def check_url(url):
"""
判断url是否合法
:param url:
:return:
"""
re_g = re.compile('[a-zA-Z]{4,5}://\w*\.*\w+\.\w+')
print(re_g)
result = re_g.findall(url)
if len(result) != 0:
return True
else:
return False
def get_url(url):
"""
通过组获取url中的某一部分
:param url:
:return:
"""
re_g = re.compile('[https://|http://](\w*\.*\w+\.\w+)')
result = re_g.findall(url)
if len(result) != 0:
return result[0]
else:
return ''
def get_email(data):
# result = re.findall('[0-9a-zA-Z_]+@[0-9a-zA-Z]+\.[a-zA-Z]+', data)
re_g = re.compile('.+@.+\.[a-zA-Z]+')
result = re_g.findall(data)
return result
html = (''
'')
def get_html_data(data):
"""
获取style中的display:
使用非贪婪模式
"""
re_g = re.compile('style="(.*?)"')
result = re_g.findall(data)
return result
def get_all_data_html(data):
"""
获取html中所有等号后双引号内的字符
:param data:
:return:
"""
re_g = re.compile('="(.+?)"')
result = re_g.findall(data)
return result
if __name__ == '__main__':
result = check_url('https://www.baidu.com')
print(result)
result = get_url('https://www.baidu.com')
print(result, 'https')
result = get_url('http://www.baidu.com')
print(result, 'http')
result = get_email('insane@163.net')
print(result)
result = get_html_data(html)
print(result)
result = get_all_data_html(html)
print(result)
re_g = re.compile('\s')
result = re_g.split(html)
print(result)
re_g = re.compile('
关注
打赏
最近更新
- 深拷贝和浅拷贝的区别(重点)
- 【Vue】走进Vue框架世界
- 【云服务器】项目部署—搭建网站—vue电商后台管理系统
- 【React介绍】 一文带你深入React
- 【React】React组件实例的三大属性之state,props,refs(你学废了吗)
- 【脚手架VueCLI】从零开始,创建一个VUE项目
- 【React】深入理解React组件生命周期----图文详解(含代码)
- 【React】DOM的Diffing算法是什么?以及DOM中key的作用----经典面试题
- 【React】1_使用React脚手架创建项目步骤--------详解(含项目结构说明)
- 【React】2_如何使用react脚手架写一个简单的页面?

