
要对数据进行处理和分析,首先就要拥有数据。在当今这个互联网时代,大量信息以网页作为载体,网页也就成了一个很重要的数据来源。但是,网页的数量非常之多,如果以人工的方式从网页上采集数据,工作量相当巨大。从本章开始就要为大家介绍一个自动采集网页数据的利器——爬虫。
爬虫是指按照一定的规则自动地从网页上抓取数据的代码或脚本,它能模拟浏览器对存储指定网页的服务器发起请求,从而获得网页的源代码,再从源代码中提取出需要的数据。使用爬虫获取数据,具有全天候、无人值守、效率高等优点。
爬虫有什么用:
- 市场分析:电商分析、商圈分析、一二级市场分析等
- 市场监控:电商、新闻、房源监控等
- 商机发现:招投标情报发现、客户资料发掘、企业客户发现等
通用的网络爬虫框架:
-
挑选种子 URL;
-
将这些 URL 放入待抓取的 URL 队列;
-
取出待抓取的 URL,下载并存储进已下载网页库中。此外,将这些 URL 放入已抓取 URL 队列;
-
分析已抓取队列中的 URL,并且将 URL 放入待抓取 URL 队列,从而进入下一循环。

我们平时在浏览器中看到的网页其实是浏览器根据网页的源代码进行渲染后呈现在浏览器窗口中的效果。网页的源代码规定了网页中要显示的文字、图片等信息的内容和格式,我们想要提取的数据就隐藏在源代码中。为了准确地提取数据,需要分析网页的源代码,摸清网页的结构,找到数据的存储位置,从而制定出提取数据的规则,编写出爬虫的代码。因此,下面先来学习网页源代码和网页结构的基础知识。
1. 查看网页的源代码
许多读者可能知道,右击网页的任意空白处,在弹出的快捷菜单中执行“查看页面源代码”命令,就能看到网页的源代码。但是这种查看网页源代码的方式不便于我们分析数据在源代码中所处的位置。这里要介绍的是谷歌浏览器自带的一个数据挖掘利器——开发者工具,它能直观地指示网页内容和源代码的对应关系,帮助我们更快捷地定位数据。
例如,在谷歌浏览器中使用百度搜索引擎搜索“当当”,然后按【F12】键或按快捷键【Shift+Ctrl+I】,即可打开开发者工具,界面如下图所示。
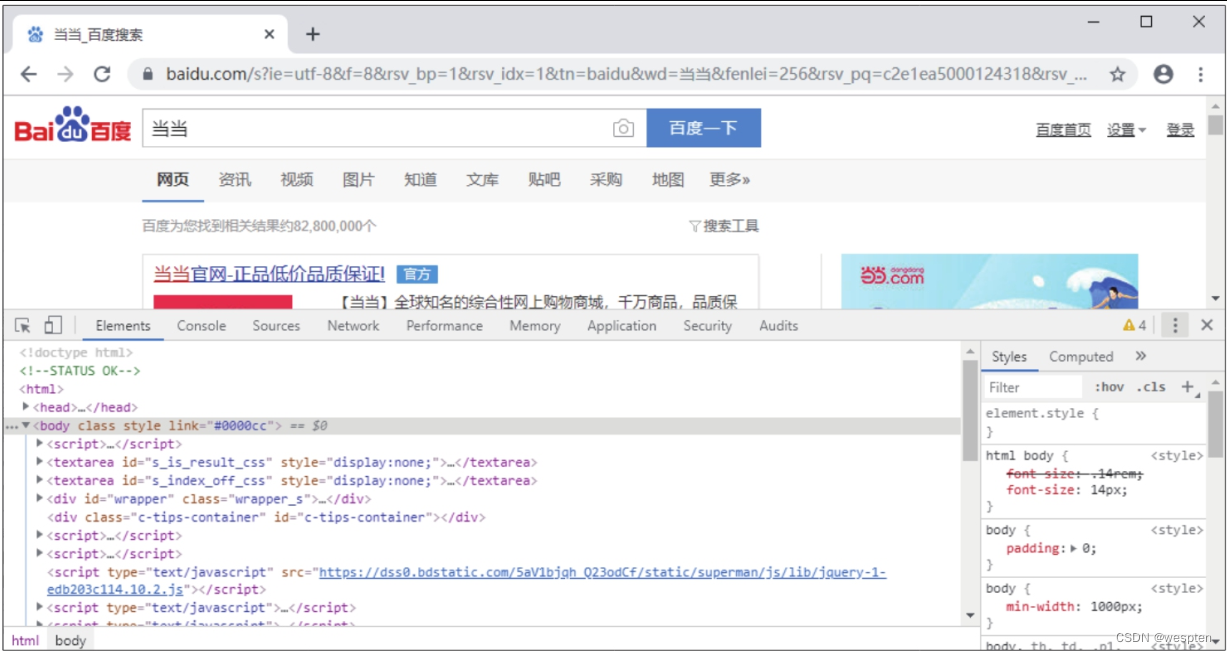
此时窗口的上半部分显示的是网页,下半部分默认显示的是“Elements”选项卡,该选项卡中的内容就是网页源代码。源代码中被“”括起来的文本称为Elements对象或网页元素,我们需要提取的数据就存放在这些Elements对象中。
单击开发者工具左上角的元素选择工具,按钮图标颜色变成蓝色,再将鼠标指针移动到窗口上半部分的任意网页元素上,该元素会被突出显示,单击元素,则窗口下半部分中该元素对应的网页源代码会被选中,同时元素选择工具的按钮图标颜色恢复灰色。
如下图所示为利用元素选择工具选中网页左上角的百度徽标的效果。

2. 网页结构的组成
前面利用开发者工具查看了网页的源代码和存放数据的网页元素,大家对网页源代码应该有了初步的认识。将通过搭建一个简单的网页来帮助大家进一步认识网页结构的基本组成。
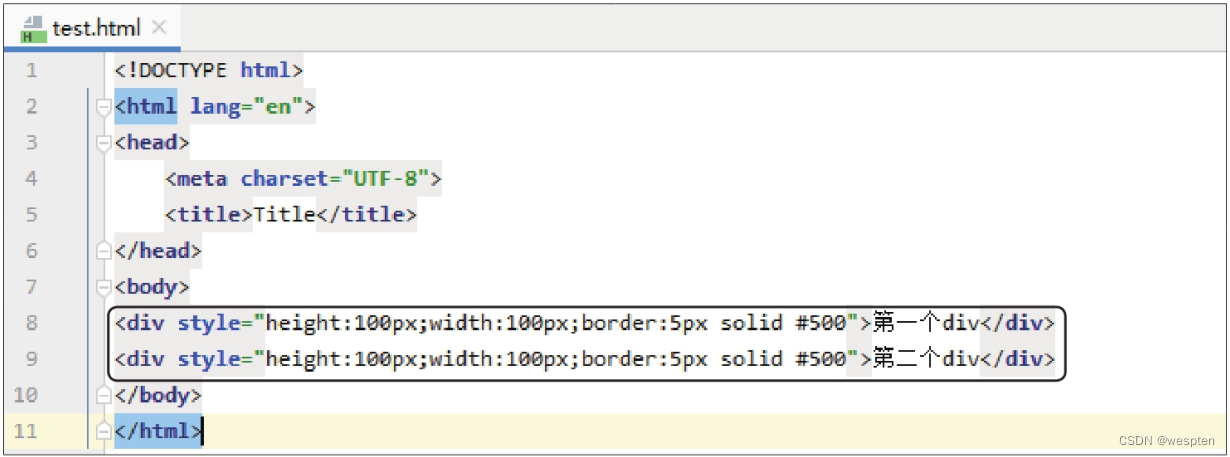
先使用PyCharm编辑器创建一个HTML文档。启动PyCharm,执行“File>New”菜单命令,在弹出的界面中单击“HTML File”,再在弹出的界面中输入文件名“test”,按【Enter】键,PyCharm会自动补全文件的扩展名,得到一个名为“test.html”的HTML文档。
该HTML文档的内容并不是空白的,PyCharm会自动生成一些网页源代码,搭建出一个HTML文档的基本框架,如下图所示。

单击代码编辑区右上方的浏览器图标,如下图所示,就能用对应的浏览器打开该HTML文档。

从网页源代码可以看出,大部分网页元素是由格式类似“文本内容”的源代码来定义的,这些“”称为HTML标签。在PyCharm自动生成的网页源代码的基础上,我们可以继续添加HTML标签来充实HTML文档的内容。下面就来介绍一些常用的HTML标签。
1)
添加的

2)
- 标签、
- 标签
- 标签和
- 标签位于
- 标签或
- 标签表示列表中的一项。无序列表中的
- 标签在网页中默认显示为小圆点格式的项目符号;有序列表中的
- 标签在网页中默认显示为数字序号。
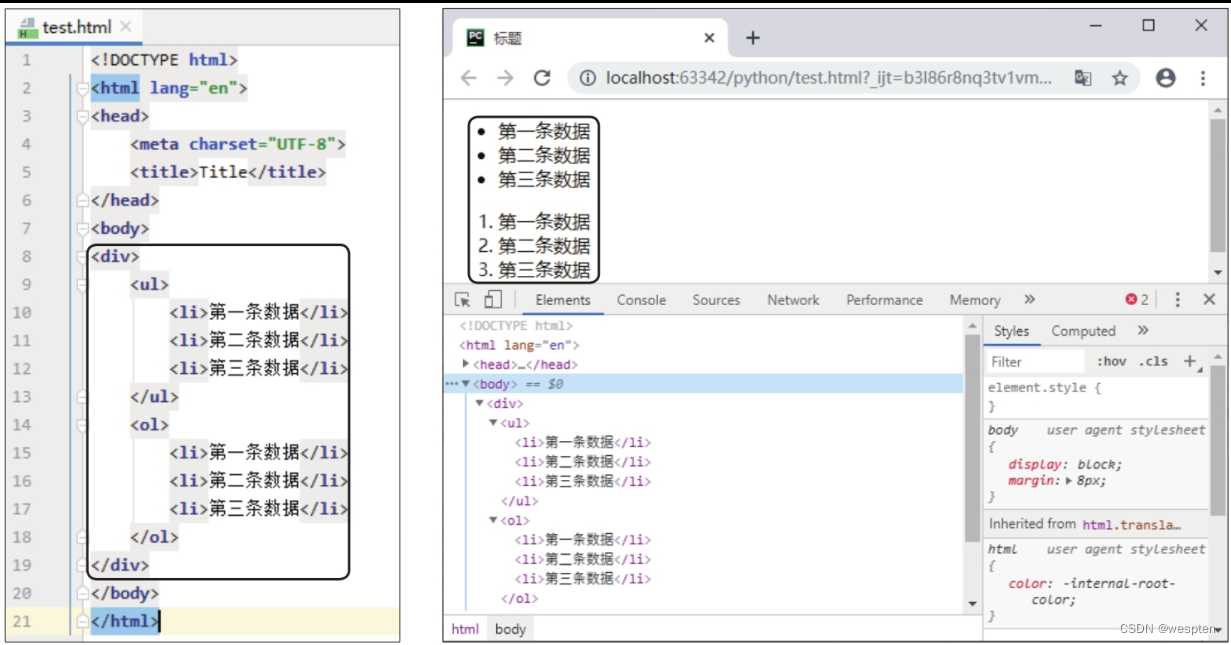
在标签下添加一个
标签,再在标签下添加- 、
- 标签,如下左图所示。使用谷歌浏览器打开修改后的网页,效果如下右图所示。
3)标签
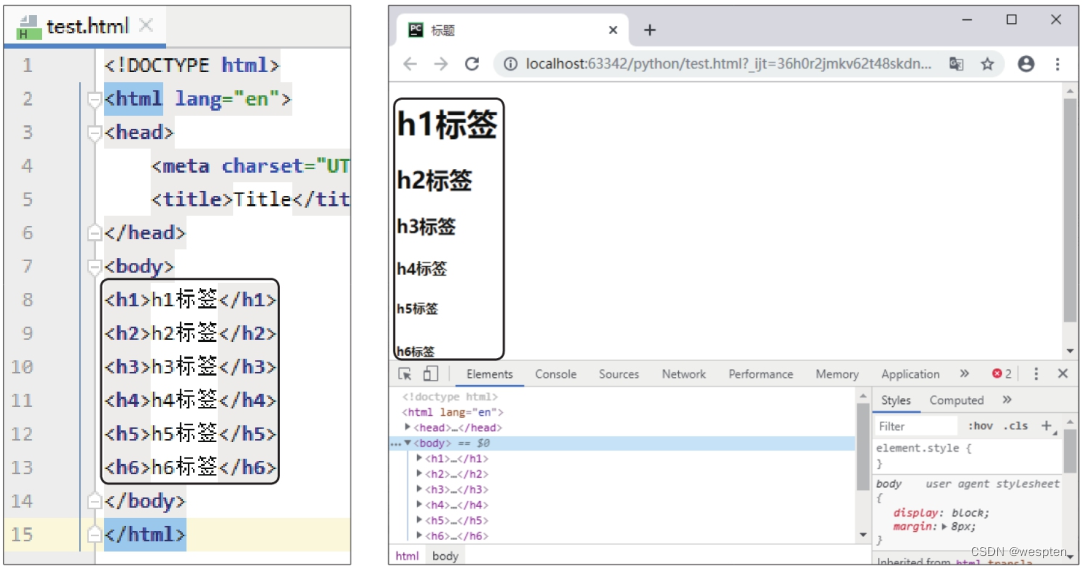
标签用于定义标题,它细分为到共6个标签,标签定义的标题的字号最大,标签定义的标题的字号最小。
在标签下添加标签的代码,如下左图所示。使用谷歌浏览器打开修改后的网页,效果如下右图所示。
4)标签
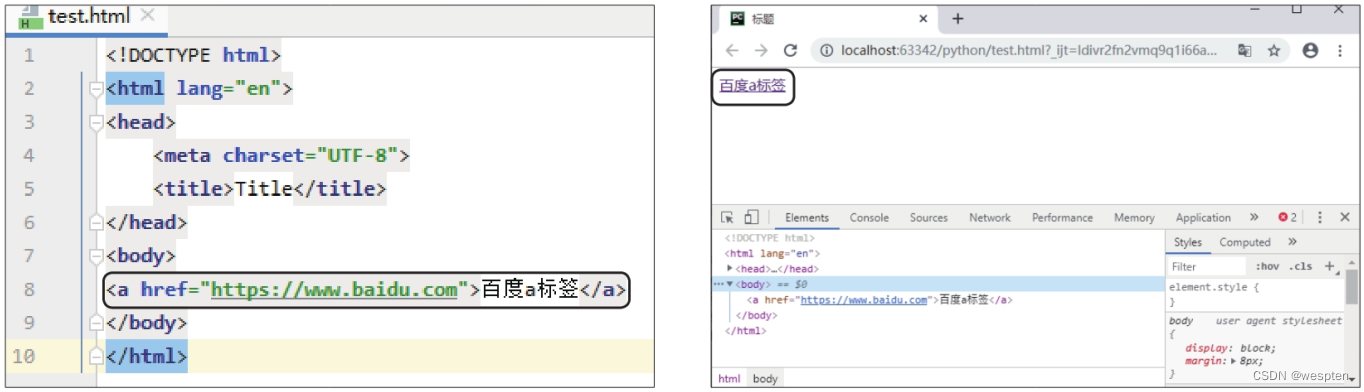
标签用于定义链接,在网页中单击链接,可以跳转到标签的href属性指定的页面地址。 在标签下添加标签的代码,如下左图所示。使用谷歌浏览器打开修改后的网页,效果如下右图所示,如果单击链接“百度a标签”,会跳转到百度首页。
5)
标签
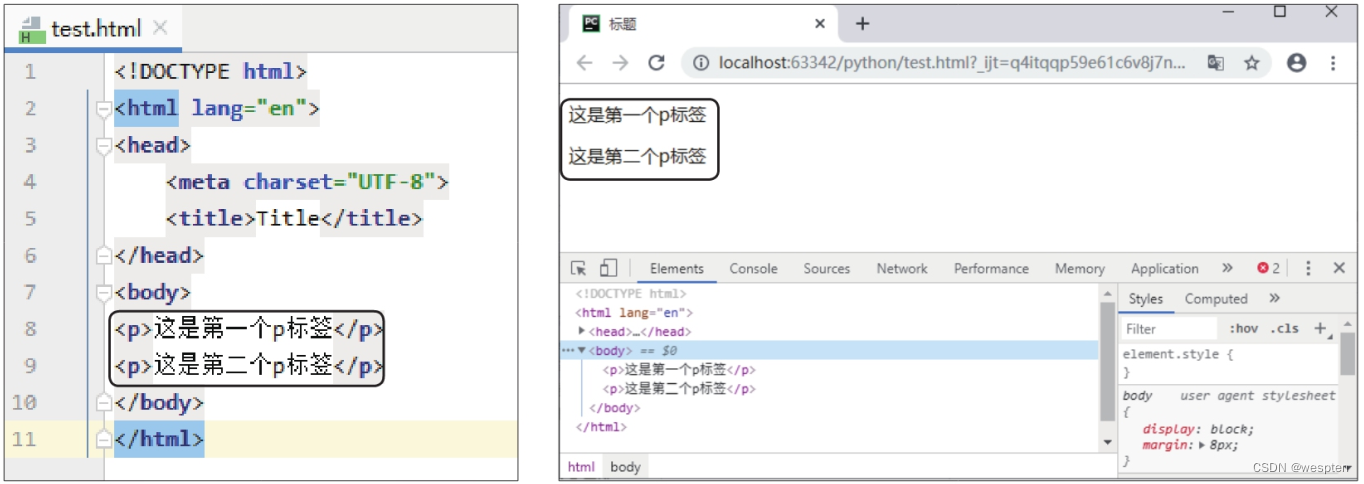
标签用于定义段落,不设置样式时,一个
标签的内容在网页中显示为一行。 在标签下添加
标签的代码,如下左图所示。使用谷歌浏览器打开修改后的网页,效果如下右图所示。
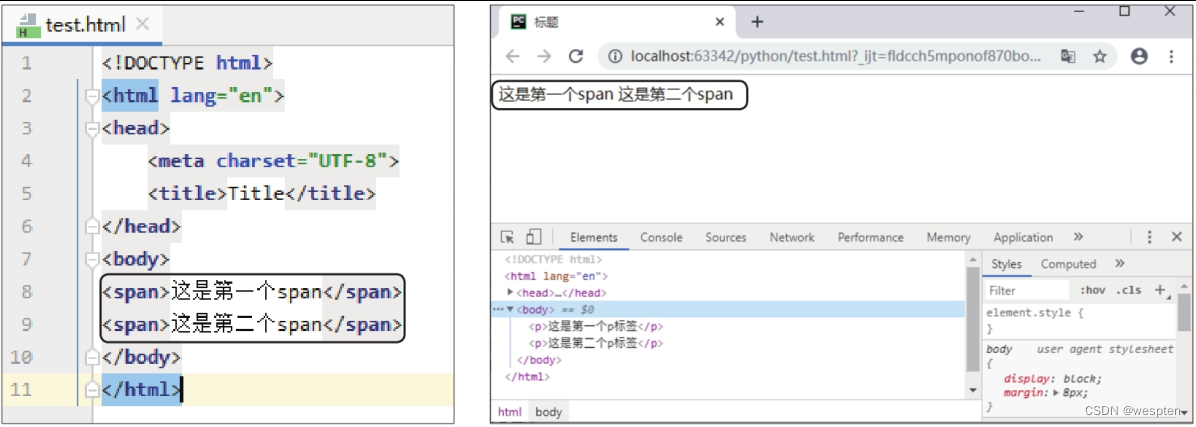
6)标签
标签可以将网页元素放在一行中显示。在标签下添加标签的代码,如下右图所示。使用谷歌浏览器打开修改后的网页,效果如下右图所示。
7)
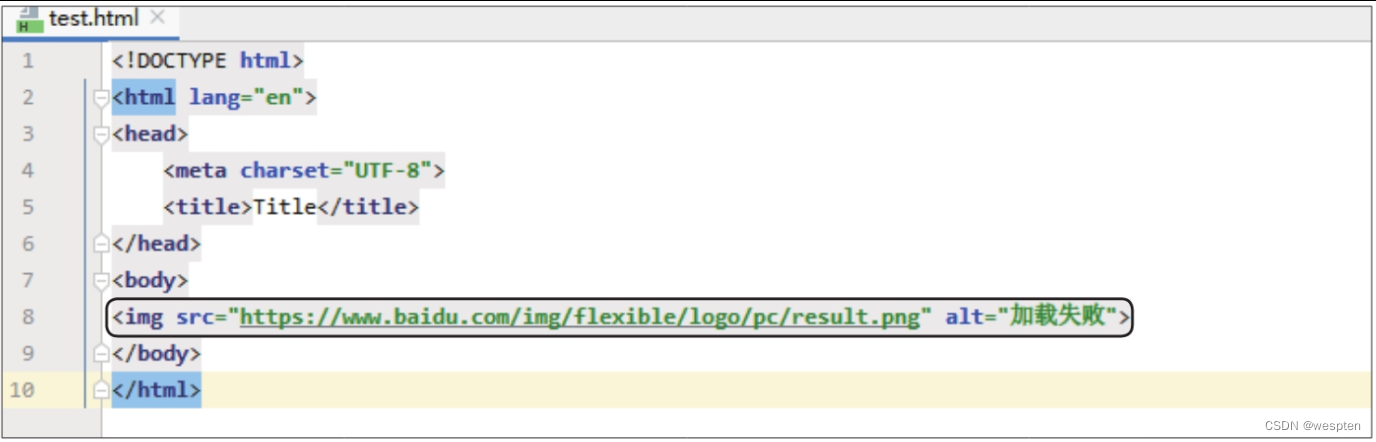
标签
标签主要用于显示图片,src属性指定图片的地址,alt属性指定图片无法正常加载时的替换文本。在标签下添加
标签的代码,如下图所示。
使用谷歌浏览器打开修改后的网页,可看到图片显示在网页中的效果,如下图所示。

3. 百度新闻页面结构剖析
通过前面的学习,相信大家对网页的结构和源代码已经有了基本的认识。下面对百度新闻的页面结构进行剖析,帮助大家进一步理解各个HTML标签的作用。
在谷歌浏览器的地址栏中输入网址https://news.baidu.com/sports,按【Enter】键,打开百度新闻的体育频道。然后按【F12】键打开开发者工具,在“Elements”选项卡下可以看到网页的源代码,如下图所示。其中的标签下存放的就是该网页的主要内容,标签下又包含4个
标签和一些标签,标签主要与JavaScript相关,这里不做具体介绍。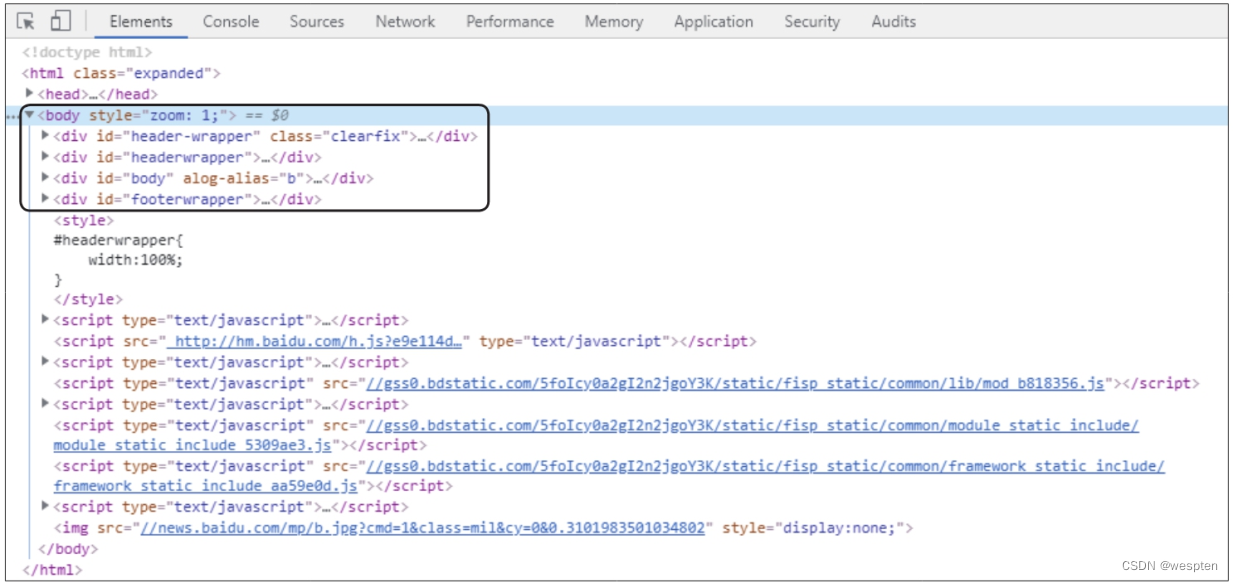
我们需要重点查看4个
标签。在网页源代码中分别单击前3个标签,可以在窗口的上半部分看到分别在网页中选中了3块区域,如下图所示。
单击第4个
标签,可看到选中了网页底部的区域,如下图所示。
单击每个
标签前方的折叠/展开按钮,可以看到该标签下包含的标签,可能是另一个标签,也可能是- 标签、
- 标签等,如下图所示,这些标签同样可以继续展开。这样一层层地剖析,就能大致了解网页的结构组成和源代码之间的对应关系。
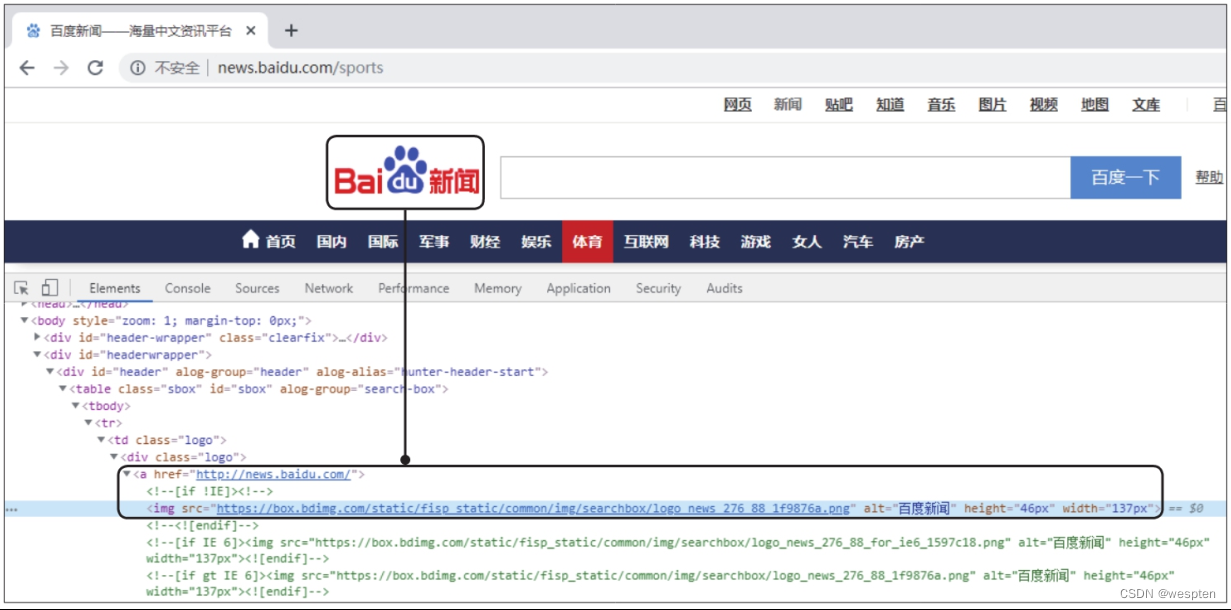
前面介绍标签时定义的是一个文字链接,而许多网页的源代码中的标签下还包含
标签,这表示该链接是一个图片链接。如下图所示为百度新闻页面中的一个图片链接及其对应的源代码,在网页中单击该图片,就会跳转到标签中指定的页面地址。
经过剖析可以发现,百度新闻页面中的新闻标题和链接基本是由大量
- 标签下嵌套的标签定义的。取出标签的文本和href属性值,就能得到每条新闻的标题和链接。
3、网页两种加载方式
只有同步加载的数据才能直接在网页源代码中直接查看到,异步加载的数据直接查看网页源代码是看不到的。
- 同步加载:改变网址上的某些参数会导致网页发生改变,例如:www.itjuzi.com/company?page=1(改变 page= 后面的数字,网页会发生改变)。
- 异步加载:改变网址上的参数不会使网页发生改变,例如:www.lagou.com/gongsi/(翻页后网址不会发生变化)。
- 同步任务:在主线程上排队执行的任务,只有前一个任务执行完毕,才能执行后一个任务。
- 异步任务:不进入主线程,而进入"任务队列"(task queue)的任务。有等主线程任务执行完毕,"任务队列"开始通知主线程,请求执行任务,该任务才会进入主线程执行(如回调函数)。
验证网页是同步还是异步加载的方法:把 JavaScript 由“允许”改为“阻止”,重新刷新页面。若网页正常加载,说明该网页的加载方式是同步加载;若网页没有正常加载,说明该网页的加载方式是异步加载。
4、网页请求
以 chrome 浏览器为例,在网页上点击鼠标右键,选择“检查”(或者直接 F12),选择“network”,刷新页面,选择 ALL 下面的第一个链接,这样就可以看到网页的各种请求信息。
请求头(Request Headers):
- Accept: text/html,image/* (浏览器可以接收的类型)
- Accept-Charset: ISO-8859-1 (浏览器可以接收的编码类型)
- Accept-Encoding: gzip,compress (浏览器可以接收压缩编码类型)
- Accept-Language: en-us,zh-cn (浏览器可以接收的语言和国家类型)
- Host: www.it315.org:80 (浏览器请求的主机和端口)
- If-Modified-Since: Tue, 11 Jul 2000 18:23:51 GMT (某个页面缓存时间)
- Referer: http://www.it315.org/index.jsp (请求来自于哪个页面)
- User-Agent: Mozilla/4.0 (compatible; MSIE 5.5; Windows NT 5.0) (浏览器相关信息)
- Cookie: (浏览器暂存服务器发送的信息)
- Connection: close(1.0)/Keep-Alive(1.1) (HTTP请求的版本的特点)
- Date: Tue, 11 Jul 2000 18:23:51 GMT (请求网站的时间)
响应头(Response Headers):
- Location: http://www.it315.org/index.jsp (控制浏览器显示哪个页面)
- Server: apache tomcat (服务器的类型)
- Content-Encoding: gzip (服务器发送的压缩编码方式)
- Content-Length: 80 (服务器发送显示的字节码长度)
- Content-Language: zh-cn (服务器发送内容的语言和国家名)
- Content-Type: image/jpeg; charset=UTF-8 (服务器发送内容的类型和编码类型)
- Last-Modified: Tue, 11 Jul 2000 18:23:51 GMT (服务器最后一次修改的时间)
- Refresh: 1;url=http://www.it315.org (控制浏览器1秒钟后转发URL所指向的页面)
- Content-Disposition: attachment; filename=aaa.jpg (服务器控制浏览器下载方式打开文件)
- Transfer-Encoding: chunked (服务器分块传递数据到客户端)
- Set-Cookie: SS=Q0=5Lb_nQ; path=/search (服务器发送Cookie相关的信息)
- Expires: -1 (服务器控制浏览器不要缓存网页,默认是缓存)
- Cache-Control: no-cache (服务器控制浏览器不要缓存网页)
- Pragma: no-cache (服务器控制浏览器不要缓存网页)
- Connection: close/Keep-Alive (HTTP请求的版本的特点)
- Date: Tue, 11 Jul 2000 18:23:51 GMT (响应网站的时间)
Fiddler是一个C#实现的浏览器抓包和调试工具,fiddler启用后作为一个proxy存在于浏览器和服务器之间,从中监测浏览器与服务器之间的http/https级别的网络交互。
目前可以支持各种主要浏览器如IE, Chrome, FireFox, Safari, Opera。Fiddler是最强大最好用的Web调试工具之一,已更新至4.4.9.9版。它能记录所有客户端和服务器的http和https请求,允许用户监视,设置断点,甚至修改输入输出数据。
主要用途:
- http/https监测与分析
- 动态修改请求或回复
- 断点调试
- 自动回复
- 自定义脚本扩展
软件下载:
点击下载
2、Fiddler使用方法1. 基本界面
Fiddler的界面通过多个标签页形式显示各种类型的信息,最常用的标签页为Inspectors,通过这个标签页可以查看抓取的网络请求和回复的详细内容。
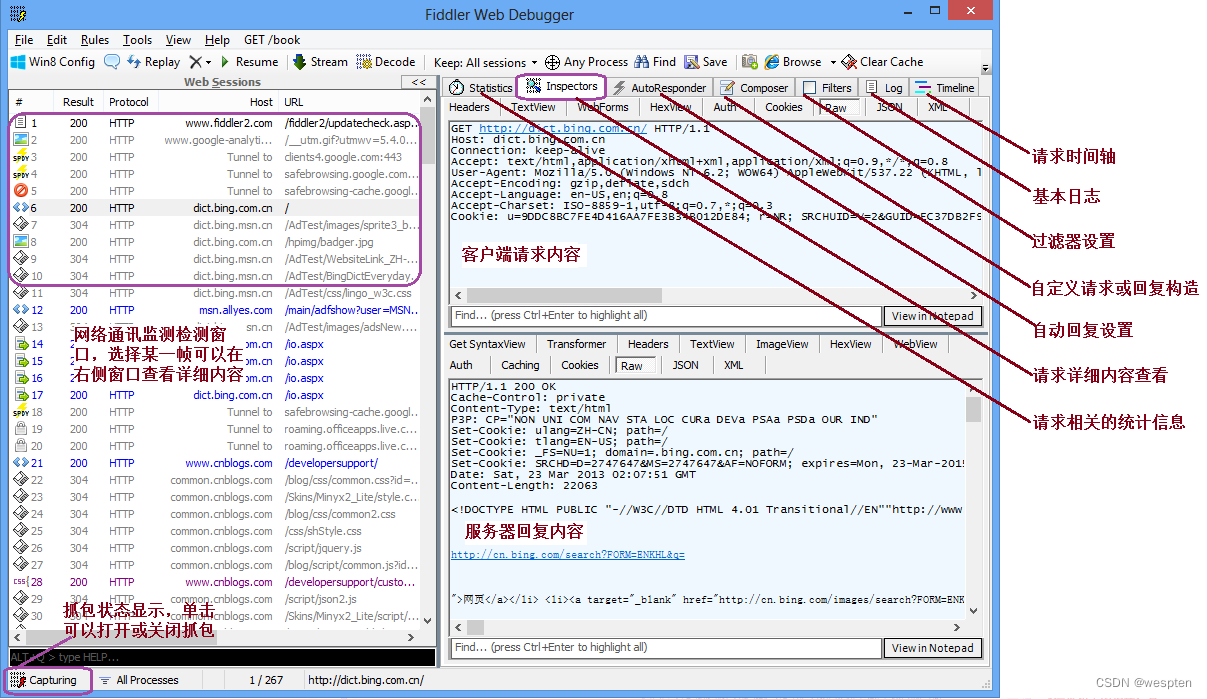
抓包每一帧前面都有不同的图标表示各种请求类型或状态:

2. 抓包方法
开发fiddler之后默认情况下就是抓包状态,可以查看界面左下角显示capturing,如果没有显示,单击此处可以开始抓包。
如果访问的网站是https网站,则需要通过Tools - Fiddler Options - Https - Decrypt Http Traffic来设置将https解密。
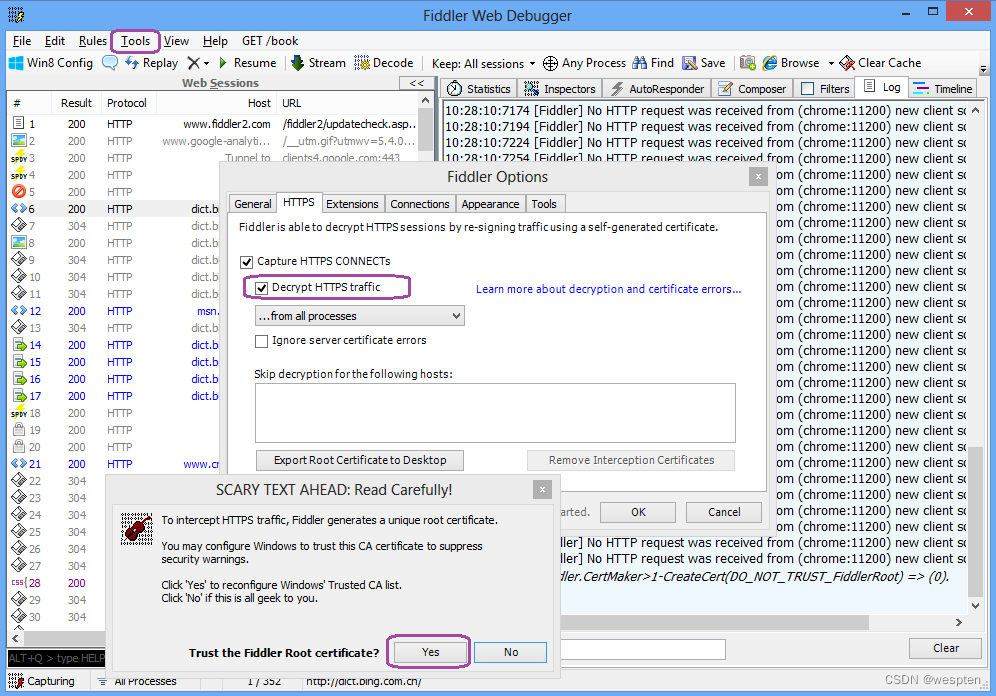
通过浏览器发送请求(在windows平台上此处并不限于浏览器,只要程序是通过winhttp或者wininet发送请求都可以被监测到)。
在收到回复后回到fiddler查看抓包内容。
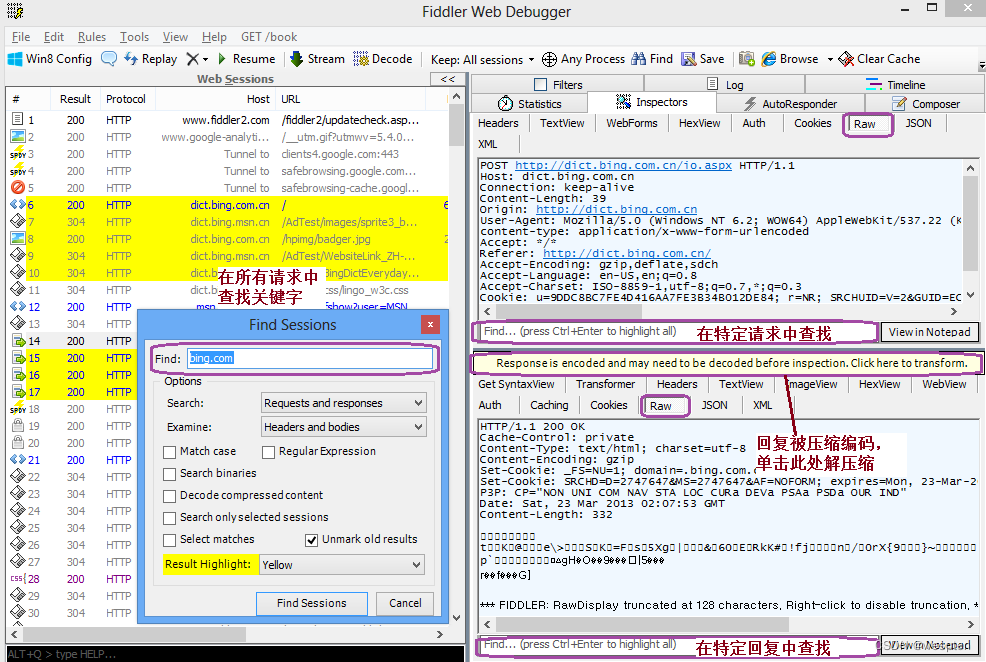
3. 关键字查找
通过Ctr+F调出查找对话框,在全局查找关键字。
在选中特定请求之后可以在Inspecters - Raw中分别在特定的请求或回复中查找内容。
如果回复被压缩过,通过单击提示按钮可以将内容解压缩。
4. 自动回复
请求自动回复应用也比较广,例如将其他机器抓包倒入自动回复,然后再本机回放重现问题;或者动态调试过程中不希望有些请求去调用服务器,而在自动回复中配制或者进行相应的更改直接查看效果。
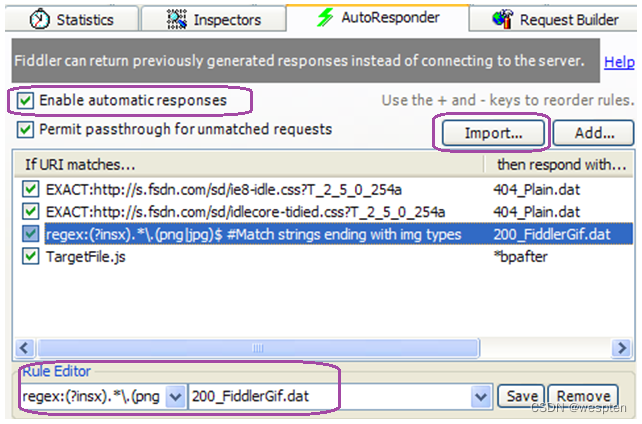
- 切换到自动回复(AutoResponder)标签页
- 选中Enable automatic responses
- 点击Import按钮导入抓包的saz文件
- 可以通过默认Url或者通过Rule Editor来修改请求匹配规
5. 断点设置
通过Rules - Automatic Breakpoints - Before Requests/After Response设置断点:
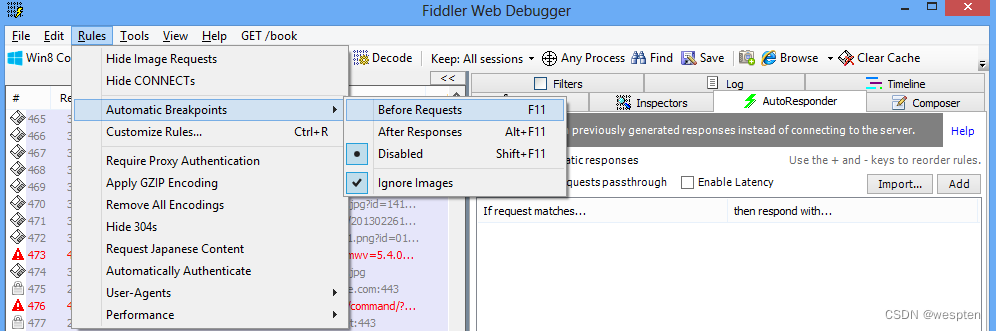
断点在请求或者回复受到后触发,可以动态的修改请求或者回复来进行不同的测试:
3、自定义扩展脚本
Fiddler支持通过Jscript方式扩展功能,比如自动通过脚本对请求及回复进行处理。
具体的实例可以参考fiddler提供的实例代码:Fiddler | Web Debugging Proxy and Troubleshooting Solutions
以下是两个简单例子
以下提到的方法可以在CustomRule.js中找到并进行相应的更改,可以通过Rules - CustomRule来打开CustomRule.js。

三、网络爬虫库目标 需要添加的代码 需要添加代码的方法 Add a request header oSession.oRequest["NewHeaderName"] = "New header value"; nBeforeRequest Delete a response header oSession.oResponse.headers.Remove("Set-Cookie"); OnBeforeResponse前面介绍的是如何在浏览器中获取和查看网页的源代码,那么如何在Python中获取网页的源代码呢?
这里介绍Python的一个第三方模块requests,它可以模拟浏览器发起HTTP或HTTPS协议的网络请求,从而获取网页源代码。
1、request模块Python中有多种库可以用来处理http请求,比如urllib、requests库等。
requests VS urllib:
- urllib 和 urllib2 是相互独立的模块,python3.0 以上把 urllib 和 urllib2 合并成一个库了,requests 库使用了 urllib3。
- requests 库的口号是“HTTP For Humans”(为人类使用 HTTP 而生),因此比起 urllib 包的繁琐,requests 库特别简洁和容易理解。
Requests库的主要方法:

Response对象的属性:
- r.status_code:http 请求的返回状态,200 表示连接成功(HTTP 状态码)
- r.text:返回对象的文本内容
- r.content:猜测返回对象的二进制形式
- r.encoding:分析返回对象的编码方式
- r.apparent_encoding:响应内容编码方式(备选编码方式)
1. get 请求
# 使用 get 方法访问网页资源 >>> resp = requests.get("http://www.baidu.com") # 返回响应对象 >>> resp # 状态码 >>> resp.status_code 200 # 请求地址 >>> resp.url 'http://www.baidu.com/' # 用 resp.encoding 对 resp.content 进行解码后的字符串 >>> print(resp.text[:100]) >> resp.encoding 'ISO-8859-1' # 以字节方式获取的响应内容 >>> print(resp.content[:100]) b'\r\n >> payload = {"key1":"value1", "key2":"value2"} >>> resp = requests.get("http://httpbin.org/get", params=payload) >>> print(resp.text) { "args": { "key1": "value1", "key2": "value2" }, "headers": { "Accept": "*/*", "Accept-Encoding": "gzip, deflate", "Host": "httpbin.org", "User-Agent": "python-requests/2.23.0", "X-Amzn-Trace-Id": "Root=1-5fb685f6-23b6c5e864d8dc4e41e8de27" }, "origin": "113.116.22.63", "url": "http://httpbin.org/get?key1=value1&key2=value2" } # 方式2:使用字典+列表的请求参数 >>> payload = {"key1":"value1", "key2":["value2", "value3"]} >>> resp = requests.get("http://httpbin.org/get", params=payload) >>> resp.url 'http://httpbin.org/get?key1=value1&key2=value2&key2=value3'2. post 请求
post 请求方法有两种方式:
- 表单提交:提交字典或二维元组的数据
- 非表单提交:提交 json 格式的数据
示例一:表单提交的两种方式
# 方式一:使用字典 >>> resp = requests.post("http://httpbin.org/post", data={"key": "value"}) >>> print(resp.text) { "args": {}, "data": "", "files": {}, "form": { "key": "value" }, "headers": { "Accept": "*/*", "Accept-Encoding": "gzip, deflate", "Content-Length": "9", "Content-Type": "application/x-www-form-urlencoded", "Host": "httpbin.org", "User-Agent": "python-requests/2.23.0", "X-Amzn-Trace-Id": "Root=1-5fb67ae5-6c15961202281a1d70522539" }, "json": null, "origin": "113.116.22.63", "url": "http://httpbin.org/post" } # 方式二:使用二维元组 >>> payload = (('key1', 'value1'), ('key1', 'value2')) >>> resp = requests.post("http://httpbin.org/post", data=payload) >>> print(resp.text) { "args": {}, "data": "", "files": {}, "form": { "key1": [ "value1", "value2" ] }, "headers": { "Accept": "*/*", "Accept-Encoding": "gzip, deflate", "Content-Length": "23", "Content-Type": "application/x-www-form-urlencoded", "Host": "httpbin.org", "User-Agent": "python-requests/2.23.0", "X-Amzn-Trace-Id": "Root=1-5fb67b74-716bca001516d46950d0d762" }, "json": null, "origin": "113.116.22.63", "url": "http://httpbin.org/post" }示例二:非表单提交
import requests # 方式1:使用json.dumps import json url = 'http://httpbin.org/post' payload = {'some': 'data'} resp = requests.post(url, data=json.dumps(payload)) >>> print(resp.text) { "args": {}, "data": "{\"some\": \"data\"}", "files": {}, "form": {}, "headers": { "Accept": "*/*", "Accept-Encoding": "gzip, deflate", "Content-Length": "16", "Host": "httpbin.org", "User-Agent": "python-requests/2.23.0", "X-Amzn-Trace-Id": "Root=1-5fb67c87-78a1dd216e987f0226d5b97a" }, "json": { "some": "data" }, "origin": "113.116.22.63", "url": "http://httpbin.org/post" } # 方式2:使用内置参数 json url = 'http://httpbin.org/post' payload = {'some': 'data'} resp = requests.post(url, json=payload)3. 其他请求方法
# put:从客户端向服务器传送的数据取代指定的文档的内容 >>> r = requests.put('http://httpbin.org/put', data={'key':'value'}) >>> print("put:", r.text) put: { "args": {}, "data": "", "files": {}, "form": { "key": "value" }, "headers": { "Accept": "*/*", "Accept-Encoding": "gzip, deflate", "Content-Length": "9", "Content-Type": "application/x-www-form-urlencoded", "Host": "httpbin.org", "User-Agent": "python-requests/2.23.0", "X-Amzn-Trace-Id": "Root=1-5fb6808c-7842d5b450d1777139efab8e" }, "json": null, "origin": "113.116.22.63", "url": "http://httpbin.org/put" } # delete:请求服务器删除指定的页面 >>> r = requests.delete('http://httpbin.org/delete') >>> print("delete:", r.text) delete: { "args": {}, "data": "", "files": {}, "form": {}, "headers": { "Accept": "*/*", "Accept-Encoding": "gzip, deflate", "Content-Length": "0", "Host": "httpbin.org", "User-Agent": "python-requests/2.23.0", "X-Amzn-Trace-Id": "Root=1-5fb6808e-042c04c61a6257820e4ff404" }, "json": null, "origin": "113.116.22.63", "url": "http://httpbin.org/delete" } # head:类似于get请求,只不过返回的响应中没有具体的内容,用于获取报头 >>> r = requests.head('http://httpbin.org/get') >>> print("head:", r.text) head: >>> print(r.headers) {'Date': 'Thu, 19 Nov 2020 14:26:23 GMT', 'Content-Type': 'application/json', 'Content-Length': '306', 'Connection': 'keep-alive', 'Server': 'gunicorn/19.9.0', 'Access-Control-Allow-Origin': '*', 'Access-Control-Allow-Credentials': 'true'} # options:允许客户端查看服务器的性能 >>> r = requests.options('http://httpbin.org/get') >>> print("options:", r.text) options: >>> print(r.headers) {'Date': 'Thu, 19 Nov 2020 14:26:24 GMT', 'Content-Type': 'text/html; charset=utf-8', 'Content-Length': '0', 'Connection': 'keep-alive', 'Server': 'gunicorn/19.9.0', 'Allow': 'OPTIONS, HEAD, GET', 'Access-Control-Allow-Origin': '*', 'Access-Control-Allow-Credentials': 'true', 'Access-Control-Allow-Methods': 'GET, POST, PUT, DELETE, PATCH, OPTIONS', 'Access-Control-Max-Age': '3600'}4. 高级用法
1)获取 json 格式的响应数据
1 r = requests.get('https://api.github.com/events') 2 print(r.json()) # (将json数据转成python对象)本例返回一个列表,里面是一个字典元素 3 print(type(r.json())) # List2)获取原始的 socket 响应数据
>>> resp = requests.get("https://api.github.com/events", stream=True) >>> print(type(resp.raw)) >>> print(resp.raw) >>> print(resp.raw.read()) # 获取流格式的响应数据 b'\x1f\x8b\x08\x00\x00\x00\x00\ ......将数据流保存到文件中:
>>> resp = requests.get("https://api.github.com/events", stream=True) >>> with open("e:\\file.txt", "wb") as f: ... for chunk in resp.iter_content(1000): ... f.write(chunk) ... 2748 2853 4761 4835 4691 4066 5545 7525 4489 2732 3259 2115 >>> with open("e:\\file.txt") as f: ... print(f.read(50)) ... [{"id":"14250730635","type":"PushEvent","actor":{"...]3)设置请求头
1 >>> url = "http://api.github.com/some/endpoint" 2 >>> headers = {"user-agent": "my-app/0.0.1"} # 增加浏览器及版本信息 3 >>> r = requests.get(url, headers=headers)4)上传文件
方式 1:
import requests url = 'http://httpbin.org/post' files = {'file': open('e:\\test.xlsx', 'rb')} r = requests.post(url, files=files) print(r.text)方式 2:显式设置文件名、文件类型和请求头
import requests url = 'http://httpbin.org/post' files = {'file': ('report.xls', open('e:\\test.xlsx', 'rb'), 'application/vnd.ms-excel', {'Expires': '0'})} r = requests.post(url, files=files) print(r.text)建议用二进制模式(binary mode)打开文件。这是因为 requests 可能会试图为你提供 Content-Length header,在它这样做的时候,这个字段值会被设为文件的字节数(bytes)。如果用文本模式(text mode)打开文件,就可能会发生错误。
5)状态码
import requests r = requests.get('http://httpbin.org/get') print(r.status_code) # 200 print(r.status_code == requests.codes.ok) # 状态码判断:True # 非200时抛出异常代码 print(r.raise_for_status()) # None r = requests.get('https://www.cnblogs.com/dinex.indd') print(r.raise_for_status()) # 抛异常:...404 Client Error: Not Found...6)获取响应头信息
1 import requests 2 3 r = requests.get('https://api.github.com/events') 4 print(r.headers) 5 print(r.headers['Content-Type']) 6 print(r.headers.get('content-type'))7)获取/发送 Cookie
获取 Cookie:
import requests url = 'https://www.baidu.com' r = requests.get(url) print(r.cookies) # 存储在字典里 # for k, v in r.cookies.items(): print(k, v) # BDORZ 27315发送 Cookie:
import requests url = 'http://httpbin.org/cookies' cookies = dict(cookies_are='working') r = requests.get(url, cookies=cookies) print(r.text) # {"cookies":{"cookies_are":"working"}}设定跨多个路径的 Cookie:
import requests jar = requests.cookies.RequestsCookieJar() jar.set('tasty_cookie', 'yum', domain='httpbin.org', path='/cookies') jar.set('gross_cookie', 'blech', domain='httpbin.org', path='/elsewhere') url = 'http://httpbin.org/cookies' r = requests.get(url, cookies=jar) print(r.text) # {"cookies":{"tasty_cookie":"yum"}}8)请求超时
1 import requests 2 3 requests.get('http://github.com', timeout=0.001) # 抛超时的异常9)获取重定向响应数据
1 import requests 2 3 r = requests.head('http://github.com', allow_redirects=True) 4 print(r.url) # 最终访问的url:'https://github.com/' 5 print(r.history[0].url) # 跳转前的url:http://github.com/ 6 print(r.history) # 历史响应对象的列表 # []禁止重定向:
1 import requests 2 3 r = requests.get('http://github.com', allow_redirects=False) 4 print(r.status_code) # 301 5 print(r.history) # []10)Session
会话对象让你能够跨请求保持某些参数,它也会在同一个 Session 实例发出的所有请求之间保持 Cookie。
import requests s = requests.Session() # 跨请求主体去请求 s.get('http://httpbin.org/cookies/set/sessioncookie/123456789') # 从上一个请求中获得的cookie信息,会自动的发给下一次请求的网址。 r = s.get("http://httpbin.org/cookies") print(r.text) # {"cookies": {"sessioncookie": "123456789"}}在会话中添加默认请求头配置:
import requests s = requests.Session() s.auth = ('username', 'passwd') # 添加的一个默认header信息 s.headers.update({'x-test': 'true'}) # both 'x-test' and 'x-test2' are sent r=s.get('http://httpbin.org/headers', headers={'x-test2': 'true'}) print(r.text) # both 'x-test' and 'x-test3' are sent r=s.get('http://httpbin.org/headers', headers={'x-test3': 'true'}) print(r.text)5. requests库使用
python2.7、python3.6下:
#coding:utf-8 #python网络爬虫库requests库应用全解 import requests import json print(u'================入门================') r = requests.get('http://blog.csdn.net/luanpeng825485697/') #返回Response对象 # print(r.status_code) # 获取整型返回状态 # print(r.headers) # 获取头部信息,#以字典对象存储服务器响应头,但是这个字典比较特殊,字典键不区分大小写,若键不存在则返回None # print(r.encoding) #获取编码类型 # print(r.url) #获取响应网址 # print(r.history) #获取访问历史 # print(r.reason) #获取文本描述,"Not Found" or "OK". # print(r.cookies) #获取cookie # print(r.raw) #返回原始响应体,也就是 urllib 的 response 对象,使用 r.raw.read() 读取 # print(r.content) #字节方式的响应体,会自动为你解码 gzip 和 deflate 压缩 # print(r.text) #字符串方式的响应体,会自动根据响应头部的字符编码进行解码 # print(r.links) #解析响应的头部连接 # print(r.is_redirect) #是否是重定向响应 #*特殊方法*# # r.json() #如果返回的是json字符串将翻译为python对象 # r.raise_for_status() #功能:如果失败请求(非200响应)抛出异常 # r.close() #关闭连接 print(u'================基本请求================') r = requests.post("http://httpbin.org/post") r = requests.put("http://httpbin.org/put") r = requests.delete("http://httpbin.org/delete") r = requests.head("http://httpbin.org/get") r = requests.options("http://httpbin.org/get") print(u'================基本GET请求================') payload = {'key1': 'value1', 'key2': 'value2'} #字典数据 headers = {'content-type': 'application/json'} #header数据 r = requests.get("http://httpbin.org/get", params=payload, headers=headers) #payload可以省略,会在网址中添加 print(r.url) print(u'================基本POST请求================') url = 'http://httpbin.org/post' payload = {'some': 'data'} r = requests.post(url, data=payload) #上传字典数据 r = requests.post(url, json=json.dumps(payload)) #上传json数据 print(r.text) url = 'http://httpbin.org/post' myfiles = {'file': open('test.txt', 'rb')} #获取文件对象 r = requests.post(url, files=myfiles) #上传文件 print(r.text) #with open('test.txt') as f: #流式上传 # requests.post('http://some.url/streamed', data=f) print('=============携带认证信息的请求==========') from requests.auth import HTTPBasicAuth response = requests.get(host,auth=HTTPBasicAuth('intellif', 'introcks')) print(u'================Cookies================') url = 'http://httpbin.org/cookies' r = requests.get(url) #响应中会包含cookie print(r.cookies) url = 'http://httpbin.org/cookies' cookies = dict(cookies_are='working') #自定义cookie变量 r = requests.get(url, cookies=cookies) #请求时附带cookie print(r.text) print(u'================超时配置================') requests.get('http://github.com', timeout=1) #1秒没有响应就报错 print(u'================会话对象(持久连接)================') s = requests.Session() s.get('http://httpbin.org/cookies/set/sessioncookie/123456789') #get方式设置cookie r = s.get("http://httpbin.org/cookies") #获取cookie print(r.text) headers = {'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8', 'Accept-Encoding': 'gzip, deflate, compress', 'Accept-Language': 'en-us;q=0.5,en;q=0.3', 'Cache-Control': 'max-age=0', 'Connection': 'keep-alive', 'User-Agent': 'Mozilla/5.0 (X11; Ubuntu; Linux x86_64; rv:22.0) Gecko/20100101 Firefox/22.0'} s = requests.Session() s.headers.update(headers) #更新header r = s.get('http://httpbin.org/headers', headers={'x-test': 'true'}) #get函数中添加的headers会覆盖原有同名,添加不同名的,去除值为None的 print(r.text) print(u'================SSL证书验证================') r = requests.get('https://github.com', verify=True) print(r.text) r = requests.get('https://kyfw.12306.cn/otn/', verify=False) #把 verify 设置为 False即可跳过证书验证 print(r.text) print(u'================设置代理服务器================') #第一种方法 proxies = { "https": "http://121.193.143.249:80" } r = requests.post("http://httpbin.org/post", proxies=proxies) print(r.text) #第2中方法 s = requests.session() s.proxies = {'http': '121.193.143.249:80'} s.get('http://httpbin.org/ip')6. 应用案例
1)requests模块获取数据的方式
发起网络请求主要使用的是requests模块中的get()函数和post()函数。get()函数的功能是向服务器发起获取网页的请求,获取到的响应对象可以被缓存到浏览器中,该函数只获取资源,不会在服务器中执行修改操作。而post()函数的功能是向服务器传送数据,服务器会根据这些数据作出响应,所以post()函数常用来模拟用户登录。
用爬虫获取数据最常见的操作是发起获取网页的请求,因此这里先介绍利用get()函数获取数据的3种方式。
(1)获取静态网页的源代码
代码文件:获取静态网页的源代码.py
静态网页是指设计好后其内容就不再变动的网页,所有用户访问该网页时看到的页面效果都一样。对于这种页面可以直接请求源代码,然后对源代码进行数据解析,就能获取想要的数据。
演示代码如下:
1 import requests 2 response = requests.get(url='https://www.baidu.com') 3 print(response.text)第1行代码导入requests模块。
第2行代码使用requests模块中的get()函数对由参数url指定的网页地址发起请求,服务器会根据请求的地址返回一个响应对象。响应对象分为响应头和响应体两部分,响应头包含响应的状态码、日期、内容类型和编码格式等信息,响应体则包含字符串形式的网页源代码。这里将返回的响应对象存储在变量response中。
第3行代码使用响应对象的text属性提取响应对象中的网页源代码字符串,然后使用print()函数进行输出,以便确定网页源代码是否获取成功。
在PyCharm中运行代码的结果如下图所示:
(2)获取动态加载的数据
代码文件:获取动态加载的数据.py
动态网页是指服务器返回一个网页模板,其数据通过Ajax或其他方式填充到模板的指定位置,我们想要的数据一般都在服务器返回的JSON格式数据包中。
提示:
JSON(JavaScript Object Notation)是一种与开发语言无关的、轻量级的数据存储格式,起初来源于JavaScript,后来使用范围越来越广。如今几乎每门编程语言都能处理JSON格式数据。 那么如何判断想要的数据是静态的还是动态加载的呢?一般来说,如果随着浏览器的滚动条的下拉,网页中会有更多的数据加载出来,这种数据就是动态加载的。我们还可以利用开发者工具定位目标数据所在的数据包,再根据数据包的类型判断数据是否是动态加载的。
下面通过一个实例来讲解具体的方法。
在谷歌浏览器中打开豆瓣电影排行榜,网址为https://movie.douban.com/chart,在页面右侧的“分类排行榜”栏目中单击“动画”分类,打开“豆瓣电影分类排行榜-动画片”页面,按【F12】键打开开发者工具,切换到“Network”选项卡。
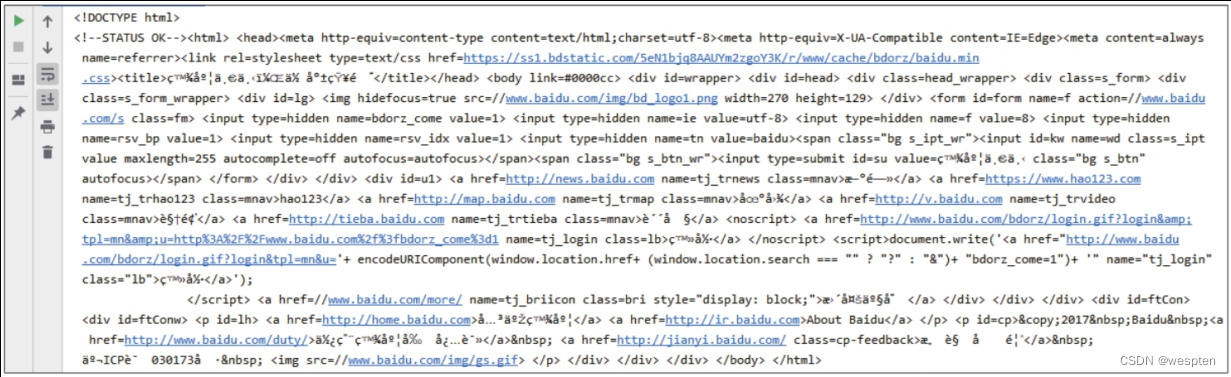
然后单击“All”按钮,按【F5】键刷新页面,在下方左侧的“Name”窗格中找到主页面的数据包并单击(通常第一个数据包就是主页面的数据包),在“Name”窗格的右侧切换至“Response”选项卡,并在网页源代码的任意处单击,按快捷键【Ctrl+F】调出局部搜索框,输入要爬取的数据包含的关键词,如“千与千寻”,按【Enter】键后,如果该关键词存在于静态网页的源代码中,那么就能在源代码中定位到该关键词,这里可以看到搜索框的末端显示搜索结果为“0 of 0”。
如下图所示,说明源代码中没有该关键词,数据是动态加载的:

此时单击开发者工具界面上方的“Search”按钮(放大镜图标),会在左侧出现一个搜索框,在搜索框中输入关键词“千与千寻”后按【Enter】键,在搜索结果中单击数据包,即可在“Response”选项卡中定位到包含该关键词的数据包,如下图所示。
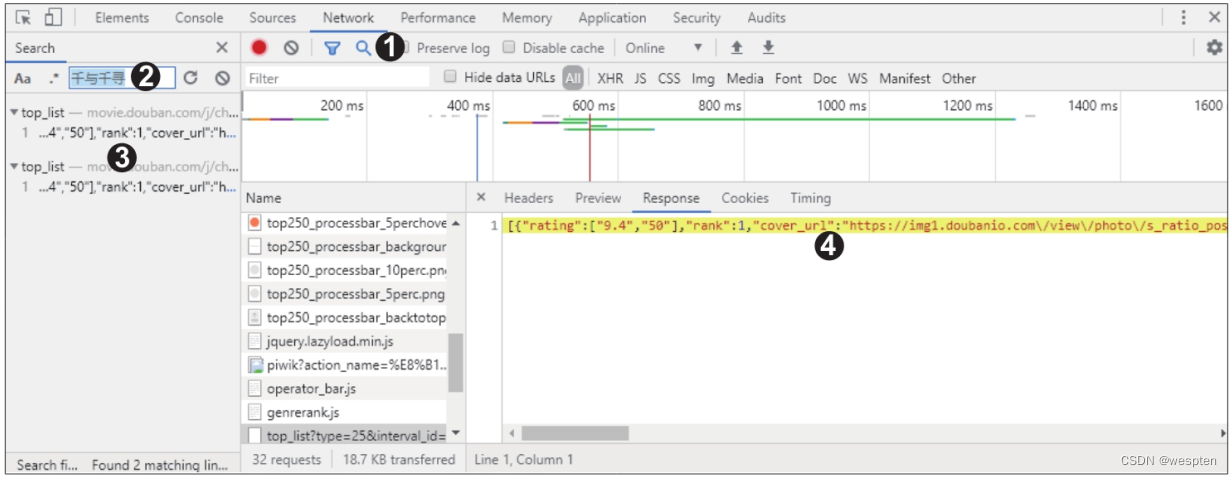
随后就可以编写代码来爬取动态加载的网页数据了。
演示代码如下:
1 import requests 2 headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.108 Safari/537.36'} 3 url = 'https://movie.douban.com/j/chart/top_list' 4 params = {'type': '25', 'interval_id': '100:90', 'action': '', 'start': '0', 'limit': '1'} 5 response = requests.get(url=url, headers=headers, params=params) 6 print(response.json())第2行代码中的headers是get()函数的一个参数,{}里是浏览器的User-Agent信息。
第3行代码中的url地址及第4行代码中的参数params的获取方式。
第5行代码使用get()函数对动态加载的数据包的url地址发起请求并获取响应对象,第6行代码用json()函数获取响应对象的JSON格式数据后进行输出。
在PyCharm中运行代码的结果如下图所示:

(3)获取图片
代码文件:获取图片.py
前面获取网页源代码时,先用get()函数获取响应对象,再用响应对象的text属性提取网页源代码。如果想要获取图片,也是先用get()函数获取响应对象,但随后不能使用text属性来提取,因为网页源代码是文本,而图片是二进制文件,如果用text属性来提取会得到乱码,此时应该使用content属性来提取图片的二进制字节码。
演示代码如下:
1 import requests 2 url = 'https://timgsa.baidu.com/timg?image&quality=80&size=b9999_10000&sec=1587292481371&di=a47137f669670075ec1049a5738eb657&imgtype=0&src=http%3A%2F%2Fbbs.jooyoo.net%2Fattachment%2FMon_0905%2F24_65548_2835f8eaa933ff6.jpg' 3 response = requests.get(url=url) 4 content = response.content 5 with open('图片.jpg', 'wb') as fp: 6 fp.write(content)第2行代码中的url为图片的地址。第3行代码使用get()函数获取响应对象。第4行代码使用content属性提取图片的二进制字节码。第5行和第6行代码将提取到的二进制字节码写入文件,如果文件打开后可以正常显示图片内容,则代表爬取成功。
第5行代码中,open()函数用于指定图片的保存路径和文件名,这里使用相对路径将图片保存在当前代码文件所在的文件夹下,“图片.jpg”为图片的保存名称和保存格式。
运行代码后,在代码文件所在的文件夹下可看到爬取的图片,打开该图片,效果如下图所示,说明爬取成功。

2)get()函数使用方式
get()函数获取数据时,需要根据不同的需求设置其参数,下面就来详细介绍get()函数的一些常用参数。
(1)headers
参数headers用于设置请求包中的请求头信息。很多网站服务器为了防止他人爬取数据,会对发起请求的一方进行身份验证,主要手段就是看请求包的请求头中的User-Agent信息,该信息描述了请求方的身份。
我们可以利用开发者工具查看请求头信息。打开开发者工具后切换至“Network”选项卡,然后单击“All”按钮,刷新页面后,在“Name”窗格中会显示加载的数据包,单击主页面的数据包,一般为第一个,切换至“Headers”选项卡,在“Request Headers”下有一个名为“User-Agent”的参数,如下图所示,服务器就是通过它判断请求方的身份的。
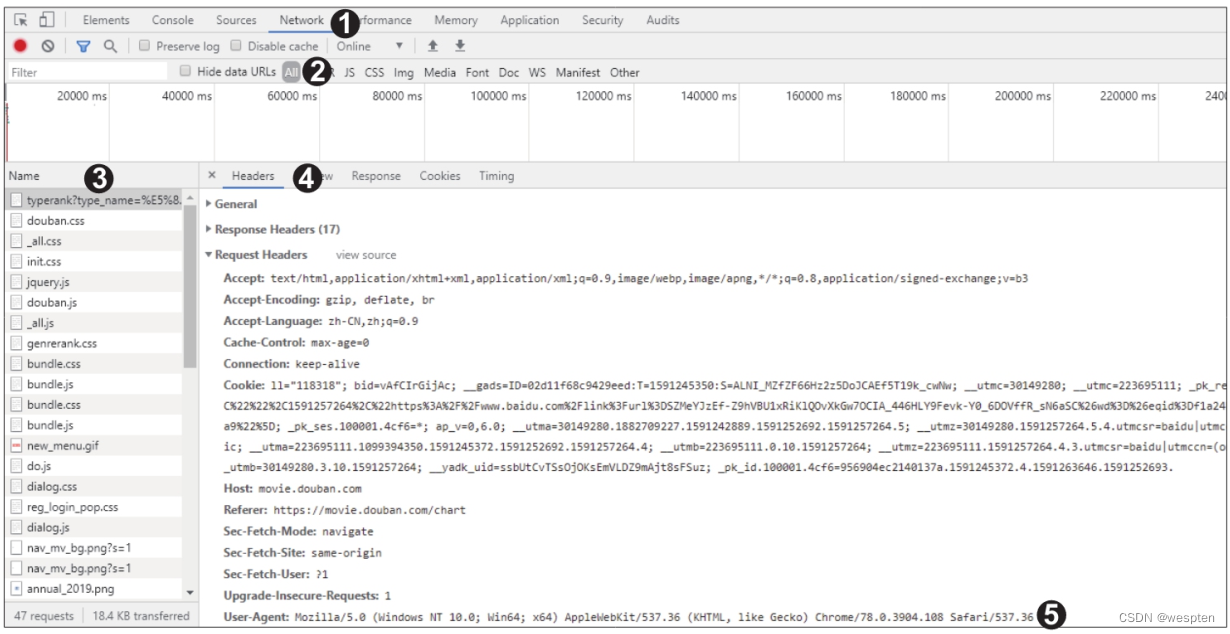
服务器对User-Agent信息进行识别后,如果认为请求不是由浏览器发起的,就不会返回正确的页面源代码。因此,爬虫为了将自己模拟成浏览器,就需要在get()函数发起请求时携带上参数headers,并为该参数设置合适的User-Agent值。
演示代码如下:
1 headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.108 Safari/537.36'} # 浏览器的身份验证信息 2 response = requests.get(url='https://www.sogou.com/web', headers=headers)不同浏览器的User-Agent值不同,查看的方法也不同,有需要的读者可以利用搜索引擎查找具体的方法。
(2)params
参数params用于在发送请求时携带动态参数,例如,搜索引擎会将用户在搜索框中输入的关键词作为参数发送给服务器,供服务器获取相关网页。
以搜狗搜索引擎为例,在搜索框中输入“搜狗新闻”,打开开发者工具,选中数据包后,在“Headers”选项卡下可以看到在“Query String Parameters”下有多个参数,其中就有我们输入的关键词“搜狗新闻”,如下图所示。
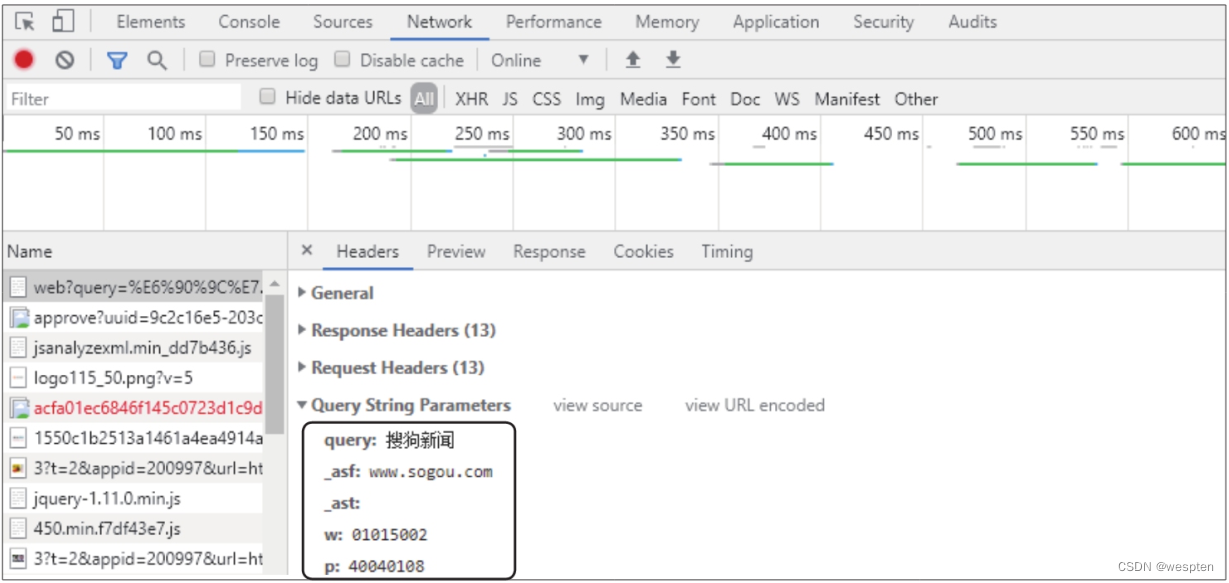
为了模拟这种携带动态参数的请求,就需要为get()函数设置参数params。
演示代码如下:
1 params = {'query': '搜狗新闻'} 2 response = requests.get(url='https://www.sogou.com/web', params=params)每一个动态参数都有其意义,服务器会根据动态参数返回不同的内容。第1行代码中不一定要指定所有动态参数,只需指定需要自定义的动态参数。如果运行代码后没有获取到正确的网页源代码,再尝试将“Query String Parameters”下所有的动态参数都携带上。
(3)timeout
参数timeout用于设置请求超时的时间。由于网络原因或其他原因,并不是每次请求都会被服务器接收到,如果一段时间内服务器还未返回响应结果,requests模块默认会重复发起同一个请求,爬虫程序可能会挂起很长时间来等待响应结果的返回。适当设置参数timeout的值(单位为秒),可以在请求超时时抛出异常,结束程序的运行。
演示代码如下:
1 response = requests.get(url='https://www.sogou.com/web', timeout=1.0)(4)proxies
参数proxies用于设置代理服务器。网站服务器在收到请求的同时还能获得请求方的IP地址,当网站服务器检测到短时间内同一IP地址发起了大量请求,就会认为该IP地址的用户是爬虫程序,并对该IP地址进行访问限制。为了规避这种“反爬”手段,可以使用代理服务器代替实际的IP地址来发起请求。
演示代码如下:
1 proxies = {'https': '101.123.102.12:7999'} # {http或https协议: 代理服务器IP地址和端口} 2 response = requests.get(url='https://www.sogou.com/web', proxies=proxies)3)分析豆瓣短评网页
import requests url = ' https://book.douban.com/subject/27147922/?icn=index-editionrecommend' r = requests.get(url, timeout=20) # 设置超时时间为20秒 # #print(r.text) # 打印返回文本 # 抛出异常 print(r.raise_for_status()) # None4)爬取豆瓣电影动画排行榜
代码文件:案例:爬取豆瓣电影动画排行榜.py
通过前面的学习,相信大家对如何使用requests模块发起网络请求并获取网页源代码有了基本的了解,下面通过爬取豆瓣电影排行榜的动画分类的数据来巩固所学的知识。
首先需要判断数据是静态的还是动态加载的。在谷歌浏览器中打开豆瓣电影排行榜,网址为https://movie.douban.com/chart,在页面右侧的“分类排行榜”栏目中单击“动画”分类,打开“豆瓣电影分类排行榜-动画片”页面,向下拖动滚动条,会看到页面中加载出更多的动画片数据,由此可以判断数据是动态加载的。
爬虫程序需要携带动态参数发起请求,服务器才会返回我们需要的数据。 接着来获取参数。按【F12】键打开开发者工具,切换至“Network”选项卡,再单击“XHR”按钮,然后按【F5】键刷新页面,可在“Name”窗格中看到动态请求的多个数据包,将页面右侧的滚动条拉到底部,加载所有的动画片数据,在“Name”窗格中单击最后一个数据包,如下图所示。
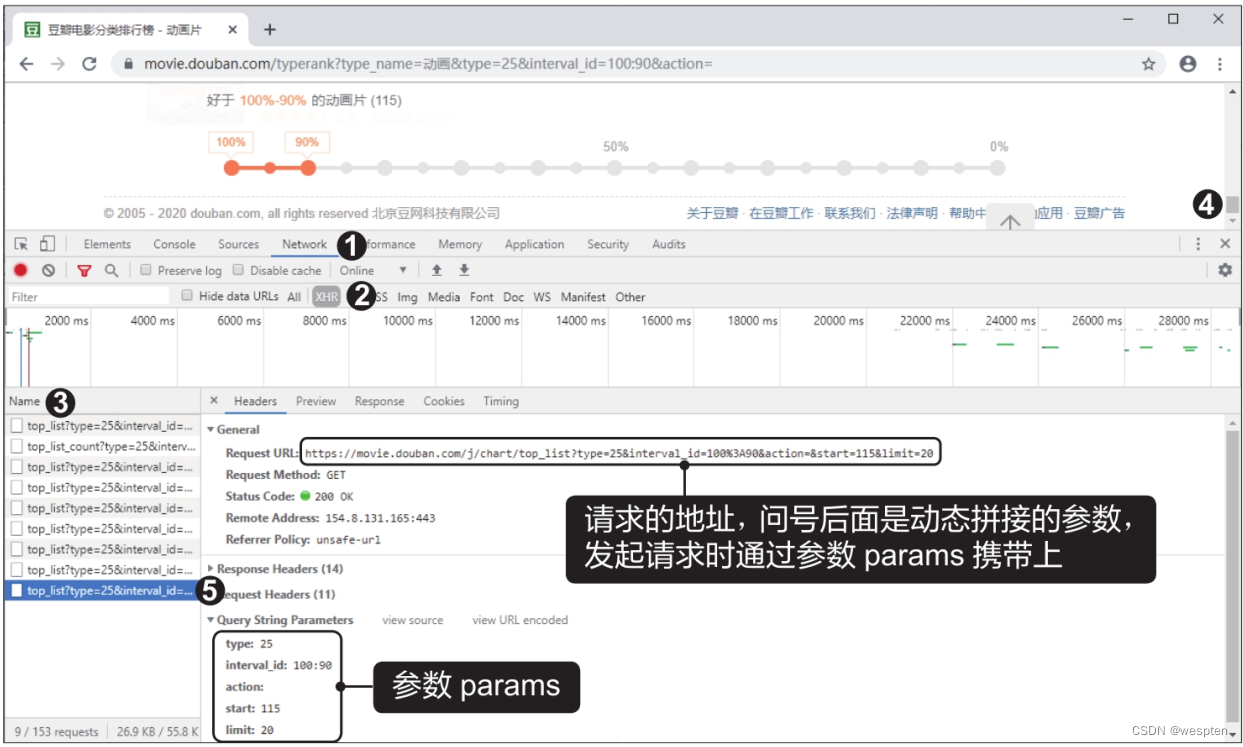
此时即可在“Headers”选项卡下的“General”和“Query String Parameters”中看到数据包中的参数设置。这些参数的名称和值可以直接复制下来,然后在爬虫代码中使用。
上图中的请求地址是浏览器将要携带的动态参数拼接到网址后面得到的,我们在编写爬虫代码时只需要用get()函数对问号前面的网址发起请求,问号后面的动态参数则通过get()函数的参数params来携带。还可以看到动态参数中的start为115,limit为20,意思是从115条数据开始获取20条数据,可以得出排行榜数据总数为135条,因此,爬虫代码携带的动态参数中start应为0,limit应为135。
完成网页的分析和相关参数的查看后,下面开始编写爬虫代码。
步骤1:导入requests模块和json模块,定义请求的地址、需要携带的动态参数和身份验证信息。
演示代码如下:
1 import requests 2 import json # 用于处理JSON格式数据的模块 3 url = 'https://movie.douban.com/j/chart/top_list' # 请求的地址 4 params = {'type': '25', 'interval_id': '100:90', 'action': '', 'start': '0', 'limit': '135'} # 需要携带的动态参数 5 headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.108 Safari/537.36'} # 模拟浏览器的身份验证信息步骤2:使用get()函数发起请求,获取响应对象;再使用json()函数提取响应对象中的JSON格式数据。
演示代码如下:
1 response = requests.get(url=url, params=params, headers=headers) 2 content = response.json() # 提取JSON格式数据步骤3:将content打印出来,可以得到一个含有大量字典的列表,要获取字典中的动画片的片名和评分,就需要将JSON格式数据打印出来,以便确定这两种数据在字典结构中的位置。
演示代码如下:
1 for i in content: 2 print(json.dumps(i, indent=4, ensure_ascii=False, separators=(', ', ': '))) # ensure_ascii设置将数据编码后显示文本内容,spearators设置键之间、键和值之间的分隔符,indent设置缩进量 3 break # 只需打印第1条JSON格式数据用于查看,因此主动结束循环代码运行结果如下图所示:
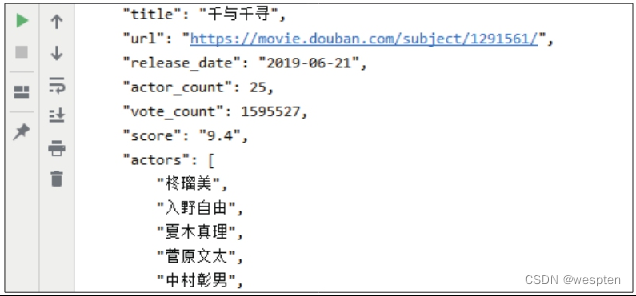
从运行结果可以看出,要获取动画片的片名和评分,需要分别提取title和score这两个键(key)对应的值(value)。
步骤4:利用for语句遍历JSON格式数据,提取title和score这两个键对应的值并写入文本文件中。
演示代码如下:
1 with open('豆瓣电影动画排行榜.txt', 'w', encoding='utf-8') as fp: # 将JSON格式数据写入文本文件中,方便展示效果 2 for i in content: 3 title = i['title'] # 片名 4 score = i['score'] # 评分 5 fp.write(title + ' ' + score + '\n') # '\n'表示换行最后运行整个爬虫代码,在代码文件所在的文件夹下会生成一个名为“豆瓣电影动画排行榜.txt”的文件,打开该文件,可看到爬取的数据,如下图所示。
2、urllib模块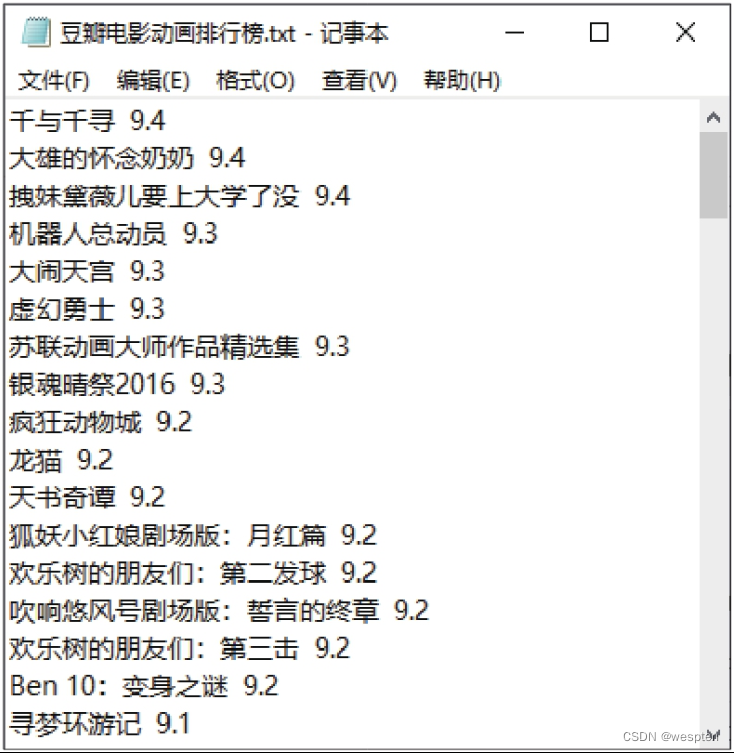
python3.4以后中,将urllib2、urlparse、robotparser并入了urllib模块,并且修改了urllib模块,其中包含了5个子模块,每个子模块中的常用方法如下:
python3中的库 python2中的库 urllib.error: ContentTooShortError; URLError;HTTPError urllib.parse: urlparse; _splitparams; urlsplit; urlunparse; urlunsplit; urljoin; urldefrag; unquote_to_bytes; unquote; parse_qs; parse_qsl; unquote_plus; quote; quote_plus; quote_from_bytes; urlencode; to_bytes; unwrap; splittype; splithost; splituser; splitpasswd; splitport等; urllib.request: urlopen; install_opener; urlretrieve; urlcleanup; request_host; build_opener; _parse_proxy; ProxyHandler; HTTPCookieProcessor; parse_keqv_list; parse_http_list; _safe_gethostbyname; ftperrors; noheaders; getproxies_environment; proxy_bypass_environment; _proxy_bypass_macosx_sysconf; Request等 urllib.response: addbase; addclosehook; addinfo; addinfourl; urllib.robotparser: RobotFileParser- 在Pytho2.x中使用import urllib2——-对应的,在Python3.x中会使用import urllib.request,urllib.error。
- 在Pytho2.x中使用import urllib——-对应的,在Python3.x中会使用import urllib.request,urllib.error,urllib.parse。
- 在Pytho2.x中使用import urlparse——-对应的,在Python3.x中会使用import urllib.parse。
- 在Pytho2.x中使用import urlopen——-对应的,在Python3.x中会使用import urllib.request.urlopen。
- 在Pytho2.x中使用import urlencode——-对应的,在Python3.x中会使用import urllib.parse.urlencode。
- 在Pytho2.x中使用import urllib.quote——-对应的,在Python3.x中会使用import urllib.request.quote。
- 在Pytho2.x中使用cookielib.CookieJar——-对应的,在Python3.x中会使用http.CookieJar。
- 在Pytho2.x中使用urllib2.Request——-对应的,在Python3.x中会使用urllib.request.Request。
python2.7环境,以下的所有程序需要导入以下库:
#coding:utf-8 import urllib import urllib2 import cookielibpython3.6环境下,以下的所有程序需要导入以下库
#coding:utf-8 import urllib import http.cookiejar as cookielib1. urlretrieve()
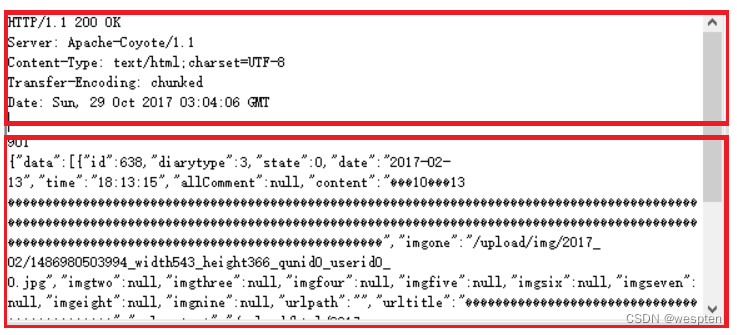
主要包含远程文件的下载,远程文件存储到本地,远程文件的读取,以及http响应的MIME头信息。
所谓的MIME头就是http协议中,数据传输都是以字节流在网线中传递,在一个文件或数据的传递起始部分都有个MIME头,用来描述本次传递的某些属性特点,如图中上面红色框中的内容。下面的红色框为传输的文件内容。
urlretrieve(url, filename=None, reporthook=None, data=None)
-
filename:指定了保存本地路径(如果参数未指定,urllib 会生成一个临时文件保存数据)。
-
reporthook:是一个回调函数,当连接上服务器、以及相应的数据块传输完毕时会触发该回调,我们可以利用这个回调函数来显示当前的下载进度。
-
data:指post导服务器的数据,该方法返回一个包含两个元素的(filename, headers)元组,filename 表示保存到本地的路径,header 表示服务器的响应头。
#远程文件 resphonse = urllib.request.urlopen("http://www.525heart.com/index/index/index.html") # urlopen(url,data,timeout)打开远程文件,返回的是类文件对象,可以使用readline等文件函数 htmlcode = resphonse.readline() #读取一行 htmlcode = resphonse.readlines() #读取所有行 htmlcode = resphonse.read() #读取字节流 print(resphonse.geturl()) #文件网址 print(resphonse.info()) #数据传输的MIME头文件 resphonse.close() #关闭 urllib.request.urlretrieve("http://www.525heart.com/index/index/index.html",'index.html') # 下载远程文件,参数为网址,可本地存储地址示例 1:下载图片
使用 urlretrieve():
1 from urllib.request import urlretrieve 2 3 urlretrieve("http://pic1.win4000.com/pic/b/20/b42b4ca4c5_250_350.jpg", "e:\\1.jpg")使用 requests:
1 import requests 2 3 url = "http://pic1.win4000.com/pic/b/20/b42b4ca4c5_250_350.jpg" 4 r = requests.get(url) 5 with open("e:\\1.jpg", "wb") as fp: 6 fp.write(r.content)示例 2:下载文件并显示下载进度
import os from urllib.request import urlretrieve def cbk(a, b, c): '''回调函数 @a:已经下载的数据块 @b:数据块的大小 @c:远程文件的大小 ''' per = 100*a*b/c if per > 100: per = 100 print('%.2f%%' % per) url = 'http://www.python.org/ftp/python/2.7.5/Python-2.7.5.tar.bz2' dir = os.path.abspath('.') work_path = os.path.join(dir, 'Python-2.7.5.tar.bz2') urlretrieve(url, work_path, cbk)执行效果:
2. urllib.parse.urlparse
urllib.parse.urlparse模块,网址字符串处理。
在python2中是urllib2.urlparse模块。
包含了将网址分解为6元组,将6元组分解为网址,获取指定网址上的链接所代表的绝对网址。
#urlparse()参数:网址、网络协议、是否使用片段,返回值:网络协议、服务器所在地、文件路径、可选参数、键值对、文档锚 prot_sch,net_loc,path,params,query,frag=urllib.parse.urlparse("http://www.525heart.com/index/index/index.html",None,None) print(prot_sch,net_loc,path,params,query,frag) #urlunparse()将6元组合并为网址字符串 urlpath=urllib.parse.urlunparse((prot_sch,net_loc,path,params,query,frag)) print(urlpath) #urljoin()获取根域名,连接新网址 urlpath=urllib.parse.urljoin("http://www.525heart.com/index/index/index.html","../chanpin/detail.html") print(urlpath)3. urllib.request.Request
获取get方式请求响应流。
在python2中是urllib2.Request模块。
很多服务器或代理服务器会查看HTTP头,进而控制网络流量,实现负载均衡,限制不正常用户的访问。所以我们要学会设置HTTP头,来保证一些访问的实现。
HTTP头部分参数说明:
Upgrade-Insecure-Requests:参数为1。该指令用于让浏览器自动升级请求从http到https,用于大量包含http资源的http网页直接升级到https而不会报错。简洁的来讲,就相当于在http和https之间起的一个过渡作用。就是浏览器告诉服务器,自己支持这种操作,我能读懂你服务器发过来的上面这条信息,并且在以后发请求的时候不用http而用https;
User-Agent:有一些网站不喜欢被爬虫程序访问,所以会检测连接对象,如果是爬虫程序,也就是非人点击访问,它就会不让你继续访问,所以为了要让程序可以正常运行,我们需要设置一个浏览器的User-Agent;
Accept:浏览器可接受的MIME类型,可以根据实际情况进行设置;
Accept-Encoding:浏览器能够进行解码的数据编码方式,比如gzip。Servlet能够向支持gzip的浏览器返回经gzip编码的HTML页面。许多情形下这可以减少5到10倍的下载时间;
Accept-Language:浏览器所希望的语言种类,当服务器能够提供一种以上的语言版本时要用到;
Cookie:这是最重要的请求头信息之一。中文名称为“小型文本文件”或“小甜饼“,指某些网站为了辨别用户身份而储存在用户本地终端(Client Side)上的数据(通常经过加密)。定义于RFC2109。是网景公司的前雇员卢·蒙特利在1993年3月的发明。
url= "https://zhuanlan.zhihu.com/p/30488000" postdata = urllib.parse.urlencode({"p":"30488000"}) # urlencode()字典序列化 headers={} headers["User-Agent"]='Mozilla/4.0 (compatible;MSIE 5.5;Windows NT)' #标明浏览器身份,有些服务器或代理服务器会来判断。这里模仿的是IE浏览器 headers["Referer"]='http://www.zhihu.com/p' #标明文件来源,防止盗链用的 headers["Content-Type"]='text/html' #在谁用rest接口的服务器会检测这个值,来确定内容如何解析 request = urllib.request.Request(url,headers=headers) #headers控制请求,因为服务器会根据这个控制头决定如何响应。(resphonse.info()可以查看响应的头的信息) resphonse = urllib.request.urlopen(request) #post请求消息 print(resphonse.read()) #读取响应数据常见的User Agent
1)Android
Mozilla/5.0 (Linux; Android 4.1.1; Nexus 7 Build/JRO03D) AppleWebKit/535.19 (KHTML, like Gecko) Chrome/18.0.1025.166 Safari/535.19 Mozilla/5.0 (Linux; U; Android 4.0.4; en-gb; GT-I9300 Build/IMM76D) AppleWebKit/534.30 (KHTML, like Gecko) Version/4.0 Mobile Safari/534.30 Mozilla/5.0 (Linux; U; Android 2.2; en-gb; GT-P1000 Build/FROYO) AppleWebKit/533.1 (KHTML, like Gecko) Version/4.0 Mobile Safari/533.12)Firefox
Mozilla/5.0 (Windows NT 6.2; WOW64; rv:21.0) Gecko/20100101 Firefox/21.0 Mozilla/5.0 (Android; Mobile; rv:14.0) Gecko/14.0 Firefox/14.03)Google Chrome
Mozilla/5.0 (Windows NT 6.2; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/27.0.1453.94 Safari/537.36 Mozilla/5.0 (Linux; Android 4.0.4; Galaxy Nexus Build/IMM76B) AppleWebKit/535.19 (KHTML, like Gecko) Chrome/18.0.1025.133 Mobile Safari/535.194)iOS
Mozilla/5.0 (iPad; CPU OS 5_0 like Mac OS X) AppleWebKit/534.46 (KHTML, like Gecko) Version/5.1 Mobile/9A334 Safari/7534.48.3 Mozilla/5.0 (iPod; U; CPU like Mac OS X; en) AppleWebKit/420.1 (KHTML, like Gecko) Version/3.0 Mobile/3A101a Safari/419.3上面列举了Andriod、Firefox、Google Chrome、iOS的一些User Agent,直接copy就能用。
所谓get方式,就是将请求数据序列化以后添加到网址中,打开指定网址的过程。
request = urllib.request.Request('http://www.525heart.com/web/getdiaryurl?diaryid=612') try: resphonse = urllib.request.urlopen(request) # urlopen(url,data,timeout)打开远程文件,返回的是类文件对象,可以使用readline等文件函数 except urllib.error.URLError as e: #本机没联网、连接不到服务器、服务器不存在 print(e.reason) except urllib.error.HTTPError as e: #响应状态,响应码 print(e.reason,e.code) print(resphonse.read()) #读取响应数据而对于我们想要爬取的网站,如何知道需要发送什么数据呢,需要用到浏览器的监听功能了。
这里以有道翻译为例,我们希望像服务器发送需要翻译的内容,获取翻译的结果,那么应该发送什么样的内容呢。
打开有道翻译的网址http://fanyi.youdao.com/
右键检查(审查元素)-切换到Network切换到网络监听部分。
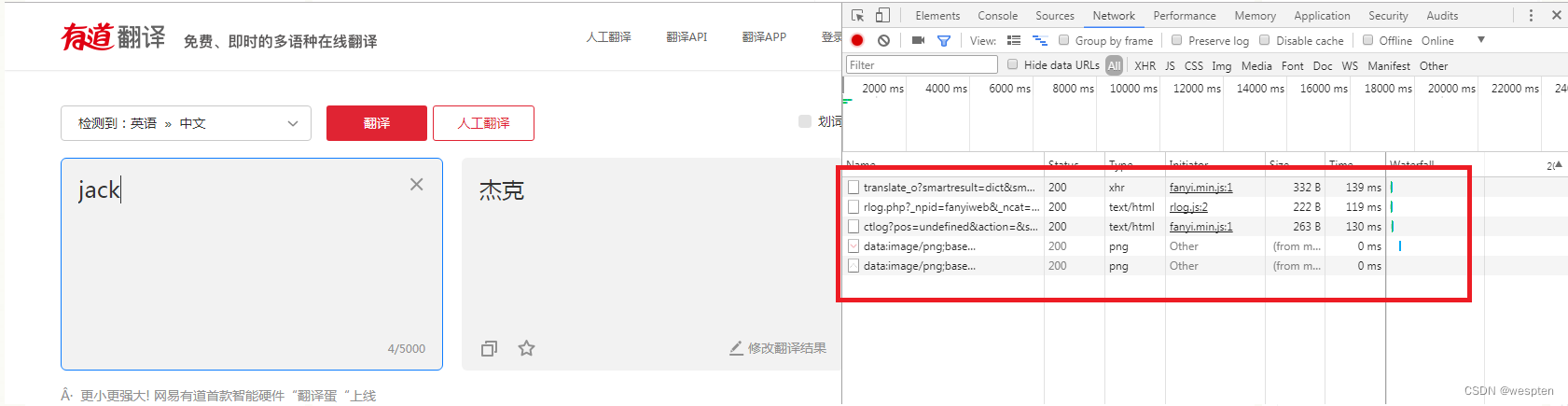
在左侧翻译区输入你要翻译的内容如“jack”,回车后网页自动翻译,获取了翻译结果“杰克”,同时我们看到在右侧网络监听部分,已经显示出在此过程中所有的信息交互。
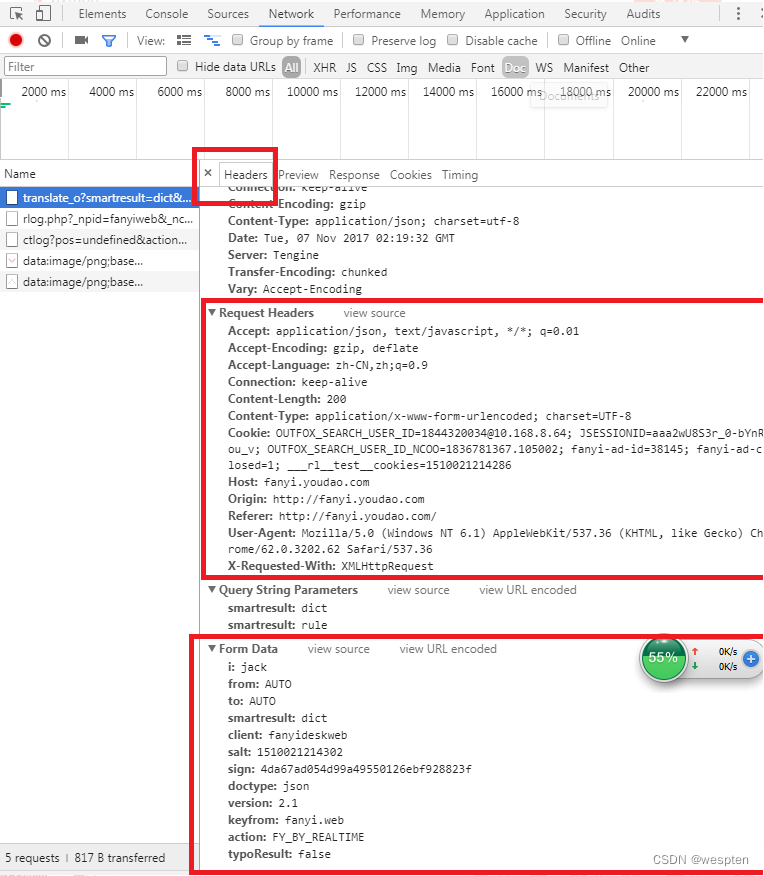
我们点击第一个信息交互记录,可以进入此次交互的详情。包括http头(MIME),和请求数据的格式。我们要发送的数据格式就按照图中的格式添加就可以了。
4. urllib.error
urllib.error有两个方法,URLError和HTTPError
URLError是OSError的一个子类,HTTPError是URLError的一个子类,服务器上HTTP的响应会返回一个状态码,根据这个HTTP状态码,我们可以知道我们的访问是否成功。200状态码,表示请求成功,再比如常见的404错误等。
最后值得注意的一点是,如果想用HTTPError和URLError一起捕获异常,那么需要将HTTPError放在URLError的前面,因为HTTPError是URLError的一个子类。如果URLError放在前面,出现HTTP异常会先响应URLError,这样HTTPError就捕获不到错误信息了。
5. urllib.request.ProxyHandler
设置代理服务器,防止限制IP。
在python2中是urllib2.ProxyHandler函数。
控制代理服务器,防止服务器限制IP。
每隔一段时间换一个代理服务器,代理服务器的ip你可以从网页中自己选择和定期更换。
URL:http://www.xicidaili.com/
#控制代理服务器,防止服务器限制IP。每隔一段时间换一个代理服务器 enable_proxy = True proxy_handler=urllib.request.ProxyHandler({"http":"61.135.217.7:80"}) null_proxy_handler = urllib.request.ProxyHandler({}) if enable_proxy: opener = urllib.request.build_opener(proxy_handler) else: opener = urllib.request.build_opener(null_proxy_handler) urllib.request.install_opener(opener)使用install_opener方法之后,会将程序默认的urlopen方法替换掉。也就是说,如果使用install_opener之后,在该文件中,再次调用urlopen会使用自己创建好的opener。如果不想替换掉,只是想临时使用一下,可以使用opener.open(url),这样就不会对程序默认的urlopen有影响。
编写代码访问http://www.whatismyip.com.tw/,该网站是测试自己IP为多少的网址,服务器会返回访问者的IP。在使用代理服务器以后,访问这里查询本地IP地址的网址的返回结果也会由于代理服务器的存在而随机变化。
下面实现了一个爬虫,爬取http://www.xicidaili.com/ 网站中代理服务器的列表:
#coding:utf-8 #本实例用于获取国内高匿免费代理服务器 import urllib from bs4 import BeautifulSoup def getdata(html): #从字符串中安装正则表达式获取值 allproxy = [] # 所有的代理服务器信息 soup = BeautifulSoup(html, 'html.parser') alltr = soup.find_all("tr", class_="")[1:] #获取tr ,第一个是标题栏,去除 for tr in alltr: alltd =tr.find_all('td') oneproxy ={ 'IP地址':alltd[1].get_text(), '端口号': alltd[2].get_text(), # '服务器地址': alltd[3].a.get_text(), '是否匿名': alltd[4].get_text(), '类型': alltd[5].get_text(), '速度': alltd[6].div['title'], '连接时间': alltd[7].div['title'], '存活时间': alltd[8].get_text(), '验证时间': alltd[9].get_text(), } allproxy.append(oneproxy) alltr = soup.find_all("tr", class_="odd")[1:] # 获取tr ,第一个是标题栏,去除 for tr in alltr: alltd = tr.find_all('td') oneproxy = { 'IP地址': alltd[1].get_text(), '端口号': alltd[2].get_text(), # '服务器地址': alltd[3].a.get_text(), '是否匿名': alltd[4].get_text(), '类型': alltd[5].get_text(), '速度': alltd[6].div['title'], '连接时间': alltd[7].div['title'], '存活时间': alltd[8].get_text(), '验证时间': alltd[9].get_text(), } allproxy.append(oneproxy) return allproxy #根据一个网址,获取该网址中符合指定正则表达式的内容 def getallproxy(url='"http://www.xicidaili.com/nn"'): try: # 构造 Request headers agent = 'Mozilla/5.0 (Windows NT 6.3; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/57.0.2987.98 Safari/537.36 LBBROWSER' headers = { # 这个http头,根据审查元素,监听发包,可以查看 "Host": "www.xicidaili.com", "Referer": "http://www.xicidaili.com/", 'User-Agent': agent } request = urllib.request.Request(url, headers=headers) # 创建一个请求 response = urllib.request.urlopen(request) # 获取响应 html = response.read() #读取返回html源码 return getdata(html) except urllib.error.URLError as e: if hasattr(e,"code"): print(e.code) if hasattr(e,"reason"): print(e.reason) return [] # allproxy = getallproxy() # print(allproxy)有了上面的列表就可以直接从数组中随机选择一个代理服务器:
allproxy = proxy.getallproxy() #获取一批代理服务器列表 ... oneproxy = random.choice(allproxy) #随机选择一个代理服务器 proxy_handler = urllib.request.ProxyHandler({"http": oneproxy['IP地址']+":"+oneproxy['端口号']}) #将代理服务器ip绑定到请求对象中6. urllib.request.HTTPCookieProcessor
设置cookie。
在python2中是urllib2.HTTPCookieProcessor函数:
cookie=cookielib.CookieJar() #声明一个CookieJar对象实例来保存cookie handler=urllib.request.HTTPCookieProcessor(cookie) #利用urllib2库的HTTPCookieProcessor对象来创建cookie处理器 opener=urllib.request.build_opener(handler) #通过handler来构建opener resphonse=opener.open('http://blog.csdn.net/luanpeng825485697/article/details/78264170') #cookie是由服务器来设定的存储在客户端,客户端每次讲cookie发送给服务器来携带数据 for item in cookie: print('Name='+item.name) print('Value='+item.value)将cookie写入文件:
filename='cookie.txt' cookie=cookielib.MozillaCookieJar(filename) #声明一个MozillaCookieJar对象实例来保存cookie,之后写入文件 handler=urllib.request.HTTPCookieProcessor(cookie) #利用urllib2库的HTTPCookieProcessor对象来创建cookie处理器 opener = urllib.request.build_opener(handler) #通过handler来构建opener resphonse=opener.open('http://blog.csdn.net/luanpeng825485697/article/details/78264170') #创建一个请求,原理同urllib2的urlopen cookie.save(ignore_discard=True, ignore_expires=True) #保存cookie文件cookie.save的参数说明:
- ignore_discard的意思是即使cookies将被丢弃也将它保存下来;
- ignore_expires的意思是如果在该文件中cookies已经存在,则覆盖原文件写入。
在这里,我们将这两个全部设置为True。
运行之后,cookies将被保存到cookie.txt文件中。我们可以查看自己查看下cookie.txt这个文件的内容。
从文件中读取cookie:
cookie=cookielib.MozillaCookieJar() #声明一个MozillaCookieJar对象实例 cookie.load("cookie.txt",ignore_discard=True, ignore_expires=True) #从文件中读取cookie内容到变量 req=urllib.request.Request("http://blog.csdn.net/luanpeng825485697/article/details/78264170") #创建请求的request opener=urllib.request.build_opener(urllib.request.HTTPCookieProcessor(cookie)) #利用urllib2的build_opener方法创建一个opener response=opener.open(req) #使用包含了指定cookie的opener发起请求 print(resphonse.read()) #打印响应利用cookie模拟登陆:
创建一个带有cookie的opener,在访问登录的URL时,将登录后的cookie保存下来,然后利用这个cookie来访问其他网址。
现在很多网站需要登陆后才能访问,如知乎,地址https://www.zhihu.com
在没有登陆时访问这个网址,只能出现登陆界面。
如果登陆以后,在访问这个网址,就会出现文章列表:
这是因为访问此地址,知乎服务器会查询请求cookie,如果请求cookie没有用户信息,就证明没有登陆,就会返回登陆界面,如果有cookie信息就会返回文章列表界面,同时包含用户的其他信息。所以首先需要让自己的请求中能带有包含自己信息的cookie。这一步通过登陆来实现。
在登陆界面,通过post将用户账号密码发送给服务器,服务器会将用户信息以cookie的形式返回给用户,用户在下次请求时,就会自动将这个cookie添加到请求http头中,这样下次再访问时,服务器就知道这个用户已经登陆了。
所以在使用cookie模拟登陆,需要两步,第一步是获取cookie,第二步是将cookie添加到http中,模拟用户已经存在的方式请求文章。
第一步,登陆获取cookie(通过post向指定网址发送数据,获取返回cookie即可)
对于发送数据需要添加的post数据和http头可以通过审查元素监听。
由于浏览器的监听在跳转到新的网页就会清空重新监听,所以在登陆到文章列表页面,浏览先监听了登陆页面的数据,后清空监听记录,重新监听文章列表页面的数据。不能及时记录下载登陆界面发送的请求数据,所以建议使用fiddle监听数据。
不过也不是没有办法,监听区红色的记录开关按钮,可以及时的阻止监听。
这里在点击登陆后,我立刻点击了浏览监听中的红色记录按钮,拦截了登陆界面的数据。

可以看到需要发送的数据除了phone_num手机号、password密码、captcha_type验证码类型(选择不同的登陆方式需要发送的数据类型可以不同),还有一个_xsrf,这个字段是在登陆网页源代码中:

所以在发送post前还要获取网页源代码解析这个字段。
# -*- coding: UTF-8 -*- import requests #import http.cookiejar as cookielib from bs4 import BeautifulSoup import cookielib #post登陆信息,生成cookie文件 session = requests.Session() session.cookies = cookielib.LWPCookieJar("cookie") agent = 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Maxthon/5.1.2.3000 Chrome/55.0.2883.75 Safari/537.36' headers = { #这个http头,根据审查元素,监听发包,可以查看 "Host": "www.zhihu.com", "Origin":"https://www.zhihu.com/", "Referer":"http://www.zhihu.com/", 'User-Agent':agent } postdata = { 'phone_num': '18158208197', #填写手机号 'password': '19910101a', #填写密码 'captcha_type':'cn', } response = session.get("https://www.zhihu.com", headers=headers) soup = BeautifulSoup(response.content, "html.parser") xsrf = soup.find('input', attrs={"name": "_xsrf"}).get("value") #解析_xsrf字段 postdata['_xsrf'] =xsrf #因为知乎登陆需要这个字段的消息 result = session.post('http://www.zhihu.com/login/email', data=postdata, headers=headers) #发送数据 session.cookies.save(ignore_discard=True, ignore_expires=True) #及时登陆失败也会生成cookie,不过这个cookie不能支持后面的模拟登陆状态第二步、通过获取的cookie,模拟已经登陆的状态。这样再次访问知乎网址,就能获取文章了。
访问文章需要的http头可以通过审查元素查看。
四、正则表达式# -*- coding: UTF-8 -*- import requests #import http.cookiejar from bs4 import BeautifulSoup import cookielib #加载cookie文件模拟登陆 session = requests.session() session.cookies = cookielib.LWPCookieJar(filename='cookie') try: session.cookies.load(ignore_discard=True) except: print("Cookie 未能加载") def isLogin(): url = "https://www.zhihu.com/" login_code = session.get(url, headers=headers, allow_redirects=False).status_code if login_code == 200: return True else: return False if __name__ == '__main__': agent = 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Maxthon/5.1.2.3000 Chrome/55.0.2883.75 Safari/537.36' headers = { "Host": "www.zhihu.com", "Origin": "https://www.zhihu.com/", "Referer": "http://www.zhihu.com/", 'User-Agent': agent, } if isLogin(): print('您已经登录')前面使用requests模块发起请求来获取静态网页或动态网页的数据。对于动态加载的数据,我们可以直接提取出JSON格式数据;但是对于静态网页,爬取到的网页源代码中有很多内容是我们不需要的,还需要做进一步的筛选。
我们可以使用正则表达式对网页源代码的字符串进行匹配,从而提取出需要的数据。
1、正则表达式基础正则表达式用于对字符串进行匹配操作,符合正则表达式逻辑的字符串能被匹配并提取出来。正则表达式由一些特定的字符组成,每个字符有不同的含义,编写正则表达式就是利用这些字符组合出用于匹配特定字符串的规则。将编写好的正则表达式与爬取到的网页源代码进行对比,就能筛选出符合要求的字符串。Python内置的re模块可以处理正则表达式。
组成正则表达式的字符分为两种基本类型:普通字符和元字符。
普通字符包含所有大写和小写字母、所有数字、所有标点符号和一些其他符号。
常用普通字符的含义见下表:
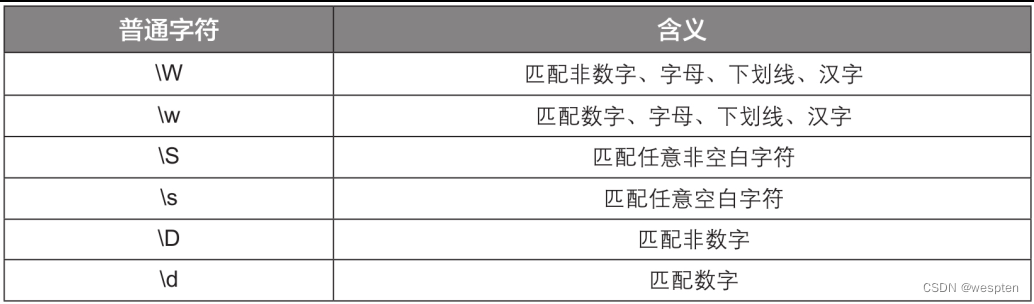
元字符是指在正则表达式中具有特殊含义的专用字符,可以用来规定其前导字符(即位于元字符前面的字符)在目标对象中的出现模式,使正则表达式具有处理能力。
常用元字符的含义见下表:
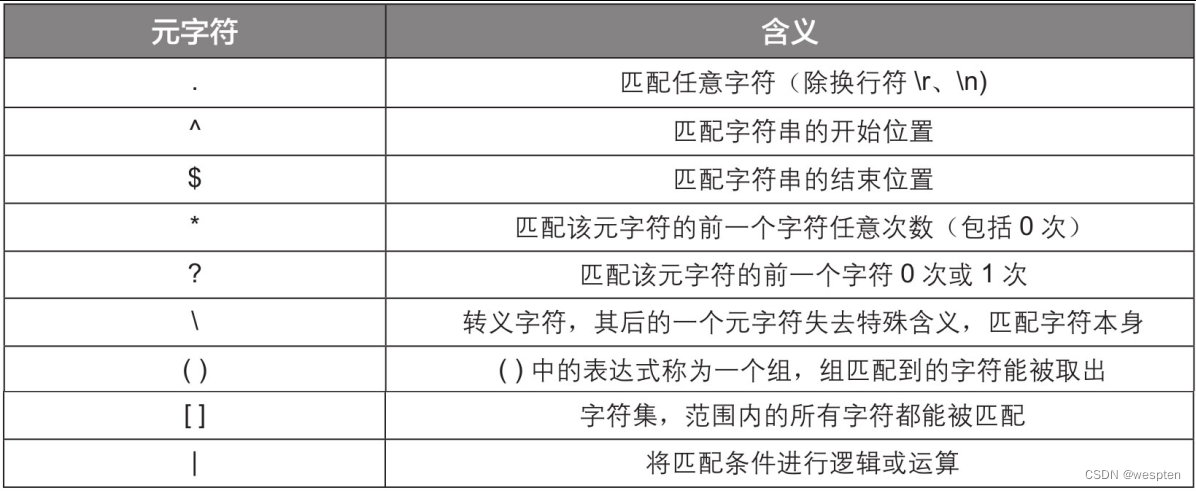
下面通过一些简单的实例,帮助大家理解普通字符和元字符的用法。
1. \w和\W的用法
演示代码如下:
1 import re 2 str1 = '123Qwe!_@#你我他' 3 print(re.findall('\w', str1)) # 匹配所有字母、数字、下划线、汉字 4 print(re.findall('\W', str1)) # 匹配所有非字母、数字、下划线、汉字代码运行结果如下:
1 ['1', '2', '3', 'Q', 'w', 'e', '_', '你', '我', '他'] 2 ['!', '@', '#']2. \s和\S的用法
演示代码如下:
1 import re 2 str2 = "123Qwe!_@#你我他\t \n\r" 3 print(re.findall('\s', str2)) # 匹配所有空白字符,如空格、换行符\r和\n、制表符\t 4 print(re.findall('\S', str2)) # 匹配所有非空白字符代码运行结果如下:
1 ['\t', ' ', '\n', '\r'] 2 ['1', '2', '3', 'Q', 'w', 'e', '!', '_', '@', '#', '你', '我', '他']3. \d和\D的用法
演示代码如下:
1 import re 2 str3 = "123Qwe!_@#你我他\t \n\r" 3 print(re.findall('\d', str3)) # 匹配所有数字 4 print(re.findall('\D', str3)) # 匹配所有非数字代码运行结果如下:
1 ['1', '2', '3'] 2 ['Q', 'w', 'e', '!', '_', '@', '#', '你', '我', '他', '\t', ' ', '\n', '\r]4. ^和$的用法
演示代码如下:
1 import re 2 str4 = '你好吗,我很好' 3 print(re.findall('^你好', str4)) # 匹配位于字符串开头的“你好” 4 str5 = '我很好,你好' 5 print(re.findall('你好$', str5)) # 匹配位于字符串末尾的“你好”代码运行结果如下:
1 ['你好'] 2 ['你好']5. .、*、?的用法 演示代码如下:
1 import re 2 str6 = 'abcaaabb' 3 print(re.findall('a.b', str6)) # 匹配任意一个字符 4 print(re.findall('a?b', str6)) # 匹配字符a 0次或1次 5 print(re.findall('a*b', str6)) # 匹配字符a任意次数(包括0次) 6 print(re.findall('a.*b', str6)) # 匹配任意字符任意次数(贪婪匹配) 7 print(re.findall('a.*?b', str6)) # 匹配任意字符任意次数(非贪婪匹配)代码运行结果如下:
1 ['aab'] 2 ['ab', 'ab', 'b'] 3 ['ab', 'aaab', 'b'] 4 ['abcaaabb'] 5 ['ab', 'aaab']注意:正则表达式“.*”表示匹配任意个数的任意字符,能匹配多长就匹配多长,称为贪婪匹配;正则表达式“.*?”也表示匹配任意个数的任意字符,但是能匹配多短就匹配多短,称为非贪婪匹配。
6. 转义字符\的用法
演示代码如下:
1 import re 2 str7 = '\t123456' 3 print(re.findall('t', str7)) # 匹配不到字符t,因为\t有特殊含义,是一个整体 4 str8 = '\\t123456' 5 print(re.findall('t', str8)) # 使用转义字符\后,\t变为无特殊含义的普通字符,能匹配到字符t 6 str9 = r'\t123456' # 在字符串前加r也可以对字符串进行转义 7 print(re.findall('t', str9))代码运行结果如下:
1 [] 2 ['t'] 3 ['t']7. 字符集[]的用法
演示代码如下:
1 import re 2 str10 = 'aab abb acb azb a1b' 3 print(re.findall('a[a-z]b', str10)) # 只要中间的字符在字母a~z之间就能被匹配到 4 print(re.findall('a[0-9]b', str10)) # 只要中间的字符在数字0~9之间就能被匹配到 5 print(re.findall('a[ac1]b', str10)) # 只要中间的字符是字符集[ac1]的成员就能被匹配到代码运行结果如下:
1 ['aab', 'abb', 'acb', 'azb'] 2 ['a1b'] 3 ['aab', 'acb', 'a1b']8. 分组()与元字符的搭配使用
演示代码如下:
1 import re 2 str11 = '123qwer' 3 print(re.findall('(\w+)q(\w+)', str11)) # \w+代表匹配一个或多个数字、字母、下划线、汉字代码运行结果如下:
1 [('123', 'wer')]9. 逻辑或|的用法
演示代码如下:
1 import re 2 str12 = '你好,女士们先生们,大家好好学习呀' 3 print(re.findall('女士|先生', str12)) # 匹配“女士”或“先生”代码运行结果如下:
2、用正则表达式提取数据1 ['女士', '先生']代码文件:用正则表达式提取数据.py
学会了正则表达式的编写方法,就可以利用re模块提供的一些函数,在网页源代码中根据正则表达式匹配和提取数据了。
常用的几个函数介绍如下。
1. findall()函数
findall()函数能提取满足正则表达式的所有字符串。
演示代码如下:
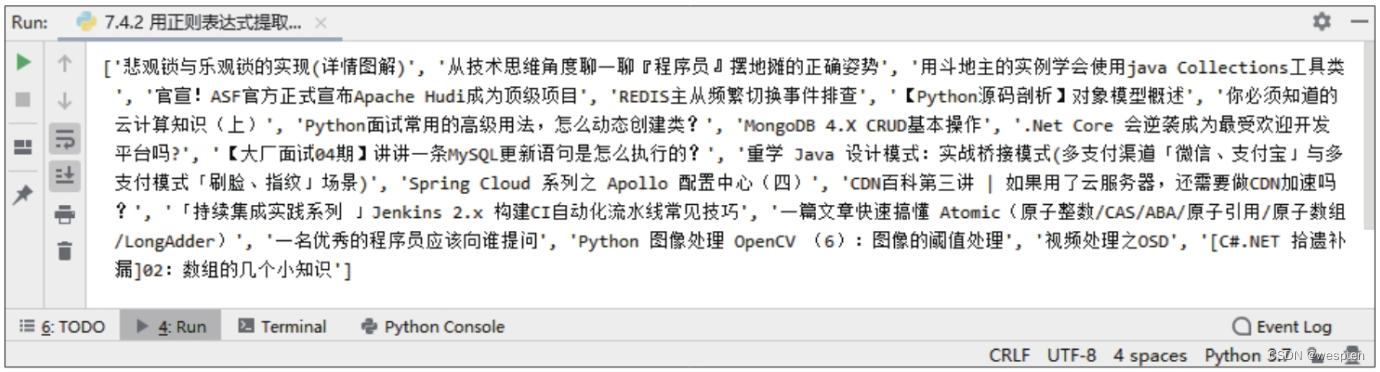
1 import requests 2 import re 3 url = 'https://www.cnblogs.com/' 4 headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.75 Safari/537.36'} 5 response = requests.get(url=url, headers=headers).text 6 ex = '.*?target="_blank">(.*?)' # 正则表达式 7 print(re.findall(ex, response, re.S))上述代码爬取的是博客园首页的热门技术博客标题。第6行代码中的正则表达式含义为:先匹配出以“
×××target="_blank">”开头、以“”结尾的所有字符串片段,再在片段中定位“target="_blank">”和“”之间的字符串,并将其提取出来。第7行代码使用findall()函数根据第6行代码定义的正则表达式在网页源代码中提取字符串,其中的参数re.S表示匹配换行符。
代码运行结果如下:
2. search()函数
search()函数只会匹配第一个满足正则表达式的字符串,匹配后用group()函数取值。
演示代码如下:
1 import re 2 str1 = '123Qwe!_@#你我他' 3 ret = re.search('\w', str1) # 匹配第一个字母、数字、下划线、汉字,如果匹配不到,会返回None,使用group()函数取值时会报错 4 print(ret.group()) # 使用group()函数取值代码运行结果如下:
1 13. match()函数
match()函数和search()函数的功能差不多,区别是match()函数是从开头匹配,如果开头不满足正则表达式,后面满足正则表达式的字符串也不会被匹配到。
4. finditer()函数
finditer()函数和findall()函数的功能差不多,区别是findall()函数返回的是一个列表,finditer()函数返回的则是一个迭代器,需要利用循环来取值。
演示代码如下:
1 import re 2 str1 = '123Qwe!_@#你我他' 3 ret = re.finditer('\w', str1) # 匹配所有字母、数字、下划线、汉字 4 for i in ret: 5 print(i.group(), end='') # end=''表示输出时不换行代码运行结果如下:
五、XPath表达式与BeautifulSoup模块 1、BeautifulSoup模块1 123Qwe_你我他通过正则表达式从网页源代码中提取数据是从字符串处理的角度来进行的,这种方法需要分析网页源代码的特征和规律,并编写复杂的正则表达式,对于不熟悉HTML和正则表达式的人来说难度比较高。那么有没有更简单的方法呢?答案是肯定的。
在开发者工具中可以看到,网页源代码是由结构化的Elements对象组成的,如果能解析这个结构,在结构中定位包含所需内容的标签,再将标签中的内容提取出来,就能得到想要的数据。
BeautifulSoup 提供一些简单的、python 式的函数用来处理导航、搜索、修改分析树等功能。它是一个工具箱,通过解析文档为用户提供需要抓取的数据。
建议使用“pip install beautifulsoup4”或"pip install bs4"命令安装该模块的最新版本。
BeautifulSoup模块是一个HTML/XML解析器,主要用于解析和提取HTML/XML文档中的数据。该模块不仅支持Python标准库中的HTML解析器,而且支持许多功能强大的第三方解析器。推荐使用lxml解析器,该解析器能将网页源代码加载为BeautifulSoup对象,再使用对象的方法提取数据。
1. 常用属性与方法
1)解析HTML文档
soup = BeautifulSoup(html_doc, 'html.parser')- html_doc:文档名称
- "html_parser":解析网页所需的解析器
2)用soup.prettify更友好地打印网页
print(soup.prettify())3)常用属性
- soup.title:返回 title 部分的全部内容:The Dormouse's story
- soup.title.name:返回 title 标签的名称( name 标签):'title'
- soup.title.string:返回这个标签的内容:"The Dormouse's story"
- soup.find_all('a'):返回所有超链接的元素如下:
Elsie, Lacie, Tillie]- soup.find(id="link3"):返回 id=link3 部分的内容,如下:
Tillie]2. BeautifulSoup使用
1)实例化BeautifulSoup对象
简单来说,实例化BeautifulSoup对象就是使用解析器分析指定的网页源代码,得到该源代码的结构模型。
要解析的网页源代码可以是存储在本地硬盘上的HTML文档,也可以是爬虫程序从网站服务器获取到的源代码字符串。下面分别介绍具体方法。
将本地硬盘上存储的HTML文档实例化为BeautifulSoup对象的演示代码如下:
1 from bs4 import BeautifulSoup 2 fp = open('test1.html', encoding='utf-8') # 读取本地HTML文档 3 soup = BeautifulSoup(fp, 'lxml') # 用读取的HTML文档实例化一个BeautifulSoup对象,第2个参数'lxml'表示指定解析器为lxml将获取到的网页源代码字符串实例化为BeautifulSoup对象的演示代码如下:
1 from bs4 import BeautifulSoup 2 import requests 3 headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.108 Safari/537.36'} 4 response = requests.get(url='https://www.baidu.com', headers=headers).text # 获取网页源代码 5 soup = BeautifulSoup(response, 'lxml') # 用获取的网页源代码实例化BeautifulSoup对象2)用BeautifulSoup对象定位标签
代码文件:用BeautifulSoup对象定位标签.py、test1.html
实例化一个BeautifulSoup对象后,就可以使用该对象来定位网页中的标签元素。将通过一个简单的网页“test1.html”讲解标签定位的方法。
该文件中的网页源代码如下:
1 2 3 4 测试BeautifulSoup 5 6 7 8第一个div 917first div下的p标签
10 11 a标签下的span标签 12 first div下的第一个a标签 13 14 1516
1826 27-
19
- 第一个li标签 20
- 第二个li标签 21
- 第三个li标签 22
- 第四个li标签 23
- 第五个li标签 24
(1)通过标签名进行定位
网页源代码中可能会有多个同名标签,通过标签名进行定位只能返回其中的第一个标签。演示代码如下:
1 from bs4 import BeautifulSoup 2 fp = open('test1.html', encoding='utf-8') # 读取HTML文档 3 soup = BeautifulSoup(fp, 'lxml') # 实例化BeautifulSoup对象 4 print(soup.p) # 通过标签名定位第一个标签
代码运行结果如下:
1first div下的p标签
(2)通过标签属性进行定位
标签属性有class、id等,实践中主要使用class属性来定位标签。需要注意的是,因为class这个单词本身是Python的保留字,所以BeautifulSoup模块中的class属性在末尾添加了下划线来进行区分。其他标签属性,如id属性,则没有添加下划线。
演示代码如下:
1 from bs4 import BeautifulSoup 2 fp = open('test1.html', encoding='utf-8') 3 soup = BeautifulSoup(fp, 'lxml') 4 print(soup.find(class_='first')) # 返回class属性值为first的第一个标签 5 print(soup.find_all(class_='first')) # 返回class属性值为first的所有标签的列表第4行代码中的find()函数可以返回符合属性条件的第一个标签。第5行代码中的find_all()函数则可以将符合属性条件的所有标签放在一个列表中返回。
代码运行结果如下:
1 2 [,第一个div 3, 11 a标签下的span标签 12 first div下的第一个a标签 13 ,first div下的p标签
4 5 a标签下的span标签 6 first div下的第一个a标签 7 8 910
- 第一个li标签
]一个标签的属性可以有多个值,例如,第一个
标签的class属性就有first和ten两个值。从运行结果可以看出,find()和find_all()函数在执行时,只要标签的任意一个值满足条件,就会将标签返回。(3)通过标签名+标签属性进行定位
将标签名和标签属性相结合也可以定位标签。
演示代码如下:
1 from bs4 import BeautifulSoup 2 fp = open('test1.html', encoding='utf-8') 3 soup = BeautifulSoup(fp, 'lxml') 4 print(soup.find('div', class_='first')) 5 print(soup.find_all('div', class_='first'))第4行和第5行代码中的find()和find_all()函数的功能在前面已经介绍过,这里为函数设置的第1个参数为标签名,第2个参数为标签属性值。
代码运行结果如下:
1 2 [,第一个div 3]first div下的p标签
4 5 a标签下的span标签 6 first div下的第一个a标签 7 8 910
(4)通过选择器进行定位
使用select()函数可以根据指定的选择器返回所有符合条件的标签。常用的选择器有id选择器、class选择器、标签选择器和层级选择器,下面一一介绍。
- id选择器
id选择器可以根据标签的id属性进行定位。
演示代码如下:
1 from bs4 import BeautifulSoup 2 fp = open('test1.html', encoding='utf-8') 3 soup = BeautifulSoup(fp, 'lxml') 4 print(soup.select('#first'))第4行代码中,select()函数括号中的'#first'是id选择器的书写格式,“#”代表id选择器,“#”后的内容为id属性的值。代码运行结果如下:
1 [- 第一个li标签
]从运行结果可以看出,尽管符合条件的标签只有一个,返回的仍然是一个列表。
- class选择器
class选择器可以根据标签的class属性进行定位。
演示代码如下:
1 from bs4 import BeautifulSoup 2 fp = open('test1.html', encoding='utf-8') 3 soup = BeautifulSoup(fp, 'lxml') 4 print(soup.select('.first'))第4行代码中,select()函数括号中的'.first'是class选择器的书写格式,“.”代表class选择器,“.”后的内容为class属性的值。
代码运行结果如下:
1 [,第一个div 2, 10 a标签下的span标签 11 first div下的第一个a标签 12 ,first div下的p标签
3 4 a标签下的span标签 5 first div下的第一个a标签 6 7 89
- 第一个li标签
]从运行结果可以看出,返回了class属性值为first的所有标签。
- 标签选择器
用标签选择器进行定位与只用标签名进行定位的不同之处在于,该方法能返回所有该类型的标签。演示代码如下:
1 from bs4 import BeautifulSoup 2 fp = open('test1.html', encoding='utf-8') 3 soup = BeautifulSoup(fp, 'lxml') 4 print(soup.select('li')) # 返回所有- 标签
代码运行结果如下:
1 [- 第一个li标签
,- 第二个li标签
,- 第三个li标签
,- 第四个li标签
,- 第五个li标签
]- 层级选择器
一个标签可以包含另一个标签,这些标签位于不同的层级,形成层层嵌套的结构。利用层级选择器可以先定位外层的标签,再定位内层的标签,这样一层层地往里定位,就能找到需要的标签。
演示代码如下:
1 from bs4 import BeautifulSoup 2 fp = open('test1.html', encoding='utf-8') 3 soup = BeautifulSoup(fp, 'lxml') 4 print(soup.select('div>ul>#first')) # 选中所有标签下- 标签中id属性值为first的所有标签
5 print(soup.select('div>ul>li')) # 选中所有
- 标签
6 print(soup.select('div li')) # 选中标签包含的所有
- 标签
第4行和第5行代码中的“>”在层级选择器中表示向下找一个层级,中间不能有其他层级。第6行代码中的空格表示中间可以有多个层级。
代码运行结果如下:
1 [- 第一个li标签
] 2 [- 第一个li标签
,- 第二个li标签
,- 第三个li标签
,- 第四个li标签
,- 第五个li标签
] 3 [- 第一个li标签
,- 第二个li标签
,- 第三个li标签
,- 第四个li标签
,- 第五个li标签
]3)从标签中提取文本内容和属性值
(1)从标签中提取文本内容
定位到标签后,还需要从标签中提取文本内容,才能获得需要的数据。从标签中提取文本内容可以利用标签的string属性或text属性。
string属性返回的是指定标签的直系文本,即直接存在于该标签中的文本,而不是存在于该标签下的其他标签中的文本。text属性返回的则是指定标签下的所有文本。
演示代码如下:
1 from bs4 import BeautifulSoup 2 fp = open('test1.html', encoding='utf-8') 3 soup = BeautifulSoup(fp, 'lxml') 4 print(soup.select('.first')[1].string) 5 print(soup.select('.first')[1].text)第4行和第5行代码中的“select('.first')[1]”表示使用select()函数根据class选择器定位class属性值为first的所有标签,再从返回的标签列表中指定第2个标签用于提取文本内容。第4行代码使用string属性提取直系文本,如果当前标签没有直系文本,或者由于当前标签包含子标签导致string属性无法确定要提取哪些文本,会返回None。第5行代码使用text属性提取所有文本。
代码运行结果如下:
1 None 2 第一个div 3 first div下的p标签 4 5 a标签下的span标签 6 first div下的第一个a标签(2)从标签中提取属性
定位到标签后,还可以通过字典取值的方式取出标签的属性值。
演示代码如下:
1 from bs4 import BeautifulSoup 2 fp = open('test1.html', encoding='utf-8') 3 soup = BeautifulSoup(fp, 'lxml') 4 print(soup.find(class_='first')['class'])第4行代码表示定位class属性值为first的第一个标签,然后提取该标签的class属性值,返回一个列表。
代码运行结果如下:
1 ['first', 'ten']3. BeautifulSoup使用案例
1)爬取“NATIONAL WEATHER”的天气数据
import requests from bs4 import BeautifulSoup # 通过requests来获取我们需要爬取的网页 weather_url = 'http://forecast.weather.gov/MapClick.php?lat=37.77492773500046&lon=-122.41941932299972' try: # 调用get函数对请求的url返回一个response对象 web_page = requests.get(weather_url).text except Exception as e: print('Error code:', e.code) # 通过BeautifulSoup解析和获取已爬取的网页内容 soup = BeautifulSoup(web_page, 'html.parser') soup_forecast = soup.find(id='seven-day-forecast-container') # 找到所需要部分的内容 date_list = soup_forecast.find_all(class_='period-name') desc_list = soup_forecast.find_all(class_='short-desc') temp_list = soup_forecast.find_all(class_='temp') # 将获取的内容更好地打印出来 for i in range(9): date = date_list[i].get_text() desc = desc_list[i].get_text() temp = temp_list[i].get_text() print('{} - {} - {}'.format(date, desc, temp))执行效果:
Today - DecreasingClouds - High: 62 °F Tonight - Mostly Clear - Low: 49 °F Monday - Sunny - High: 70 °F MondayNight - Mostly Clear - Low: 48 °F Tuesday - Sunny - High: 68 °F TuesdayNight - Mostly Clear - Low: 46 °F Wednesday - Mostly Sunny - High: 64 °F WednesdayNight - Mostly Clear - Low: 47 °F Thursday - Sunny - High: 62 °F2)爬取豆瓣电影 TOP 250 的电影名与链接
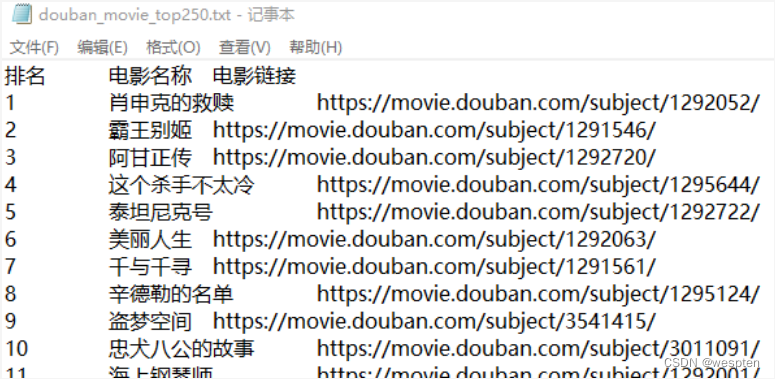
import requests from bs4 import BeautifulSoup from fake_useragent import UserAgent # 伪装请求头的库 ua = UserAgent() movie_top250 = 'https://movie.douban.com/top250?start={}' with open('C:\\Users\\juno\\Desktop\\douban_movie_top250.txt', 'w') as file: file.write('排名\t电影名称\t电影链接\n') # 每页展示25部电影,因此需要遍历10页 for i in range(10): start = i * 25 visit_url = movie_top250.format(start) crawler_content = requests.get(visit_url, headers={"User-Agent": ua.random}).text soup = BeautifulSoup(crawler_content, 'html.parser') all_pic_divs = soup.find_all(class_='pic') for index, each_pic_div in enumerate(all_pic_divs): movie_name = each_pic_div.find('img')['alt'] movie_href = each_pic_div.find('a')['href'] print('{}\t{}\t{}\n'.format(index+1+start, movie_name, movie_href)) file.write('{}\t{}\t{}\n'.format(index+1+start, movie_name, movie_href))执行效果:
3)爬取股票信息
import requests import re from selenium import webdriver from bs4 import BeautifulSoup import time import json # 通过正则,从股票列表页面,获取所有的股票编号 def get_stock_no_list(url): r = requests.get(url) html = r.text # print(html) stock_codes = re.findall(r'php\?stockcode=(\d+)"', html) return stock_codes # print(get_stock_no_list(url)) # 使用无头浏览器获取页面js执行后的源码 def get_page_souce(driver, url): driver.get(url) html = driver.page_source return html # 用bs4把信息提取出来,保存到文件中, def save_stock_info_to_file(html, file_path): infoDict = {} if html=="": return None soup = BeautifulSoup(html, 'html.parser') # 通过find方法,使用h1标签和id属性,确定h1这个元素,在用find(i)找到它下面的i元素, # 再用.text,取到i元素的文本---》股票名字 try: print(soup.find("h1", attrs={'id':"stockName"}).find("i").text) stock_name = soup.find("h1", attrs={'id':"stockName"}).find("i").text infoDict["股票名字"]= stock_name ths = soup.find("div", attrs={'id':"hqDetails"}).find_all("th") tds = soup.find("div", attrs={'id':"hqDetails"}).find_all("td") for i in range(len(ths)): key = ths[i].text value = tds[i].text infoDict[key]=value print(infoDict) with open(file_path, "a", errors="ignore") as fp: fp.write(json.dumps(infoDict, ensure_ascii=False)) except Exception as e: print("提取信息出错!") print(e) # 股票列表的网址 stock_list_url = 'http://www.bestopview.com/stocklist.html' # 股票详情页面网址 url = "http://finance.sina.com.cn/realstock/company/sh600121/nc.shtml" # 浏览器所在位置 path = r'E:\phantomjs\bin\phantomjs.exe' # 启动一个无头浏览器 driver = webdriver.PhantomJS(path) # 获取指定网址的源码 # print(get_page_souce(driver, url)) stock_list = get_stock_no_list(stock_list_url) for stock_no in stock_list[:20]: stock_info_url = "http://finance.sina.com.cn/realstock/company/sh%s/nc.shtml" %stock_no html = get_page_souce(driver, stock_info_url) print("============== 开始爬取股票的信息:%s=====================" %stock_no) save_stock_info_to_file(html, "e:\\stock_info.txt")执行效果:
2、XPath表达式
1. Xpath 简介
XPath 即为 XML 路径语言(XML Path Language),它是一种用来定位 XML 文档中某部分内容的所处位置的语言。
XPath 基于 XML 的树状结构,提供在数据结构树中找寻节点的能力。起初 XPath 提出的初衷是将其作为一个通用的、介于 XPointer 与 XSL 间的语法模型。但是 XPath 很快的被开发者采用来当作小型查询语言。
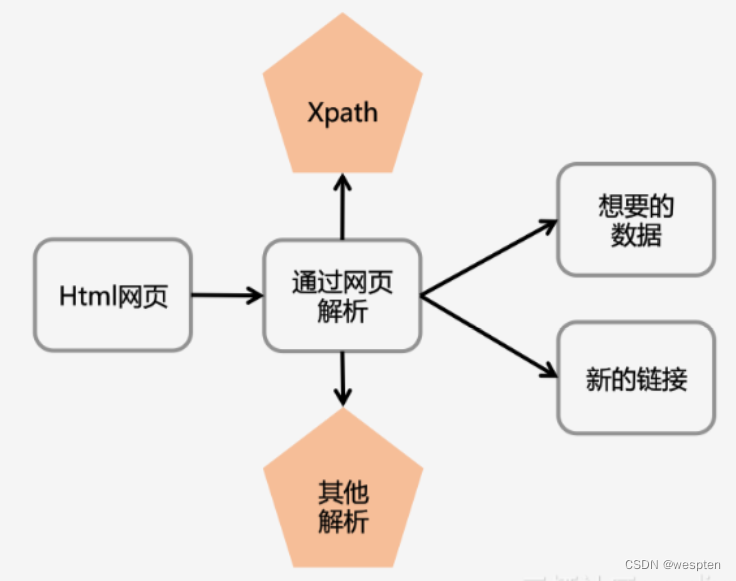
Xpath 解析网页的流程:
-
首先通过 Requests 库获取网页数据;
-
通过网页解析,得到想要的数据或者新的链接;
-
网页解析可以通过 Xpath 或者其它解析工具进行,Xpath 是一个非常好用的网页解析工具。
常用的网页解析:
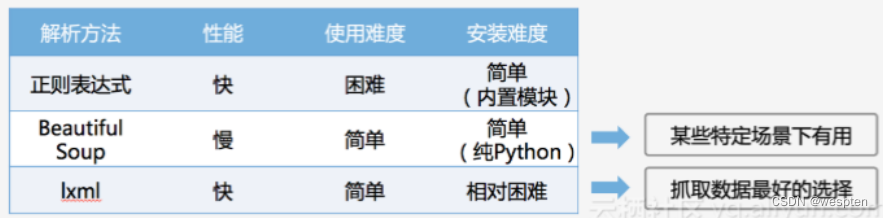
- 正则表达式:使用比较困难,学习成本较高。
- BeautifulSoup:性能较慢,相对于 Xpath 较难,在某些特定场景下有用。
- Xpath:使用简单,速度快(Xpath 是 lxml 里面的一种),是抓取数据最好的选择。
2. lxml模块
lxml作为BeautifulSoup的解析器对网页源代码进行解析,其实lxml本身就是一个功能强大的第三方模块,该模块中的etree类可以将网页源代码实例化为一个etree对象,该对象支持使用XPath表达式进行标签的定位,从而获取想要的数据。
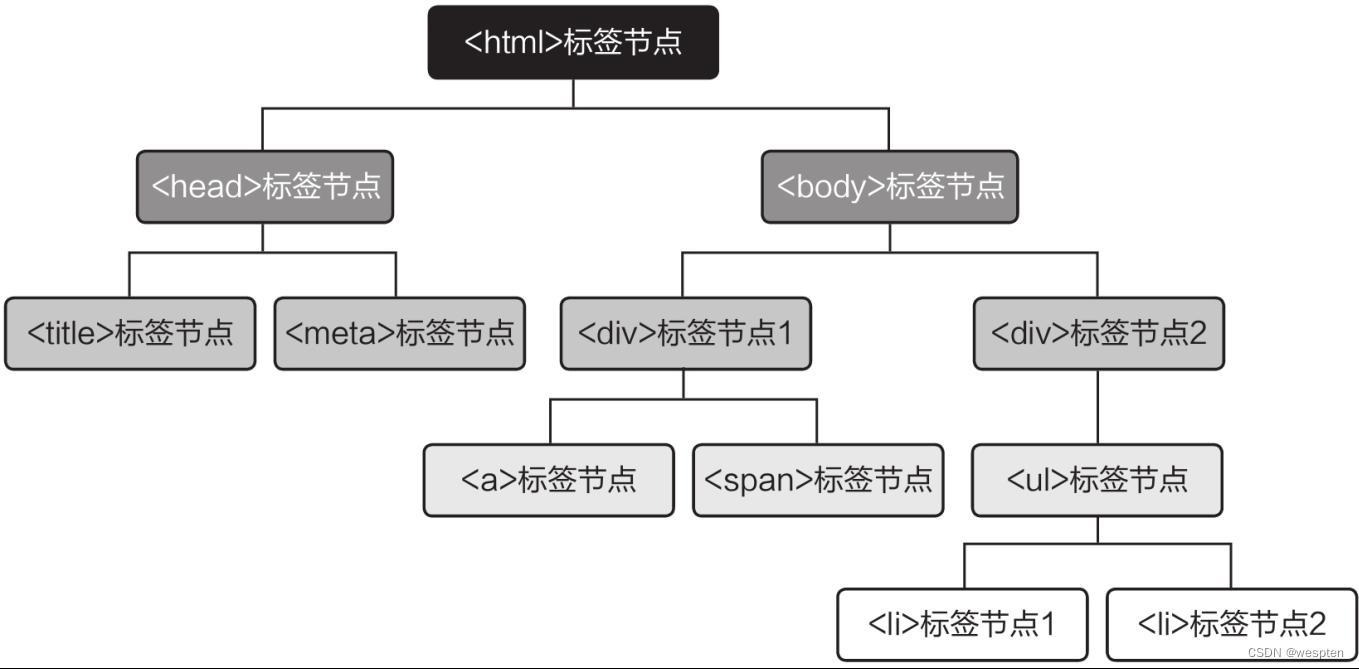
创建为etree对象后的网页源代码可以视为一个树形结构,每个标签是树的一个节点,节点之间为平级或上下级关系,通过上级能定位到下级,如下图所示。而XPath表达式则描述了从一个节点到另一个节点的路径,通过标签的属性或名称定位到上级标签,再通过路径定位到该上级标签的任意下级标签。
使用lxml模块前需要通过pip命令安装该模块。需要注意的是,由于lxml模块的部分版本没有集成etree类,建议在安装时要指定模块的版本。
例如,“pip install lxml==4.5.2”就表示指定安装4.5.2版本的lxml模块,这个版本的模块集成了etree类。
3. lxml路径选择语法
1)语法规则
表达式 描述 nodename 选取此节点的所有子节点。 / 子元素。 // 后代元素。 . 选取当前节点。 .. 选取当前节点的父节点。 @ 选取属性(获取属性的值)。举例:
路径表达式 结果 bookstore 选取 bookstore 元素的所有子节点。 /bookstore 选取根元素 bookstore。注释:假如路径起始于正斜杠( / ),则此路径始终代表到某元素的绝对路径! bookstore/book 选取属于 bookstore 的子元素的所有 book 元素。 //book 选取所有 book 后代元素,而不管它们在文档中的位置。 bookstore//book 选择属于 bookstore 元素的后代的所有 book 元素,而不管它们位于 bookstore 之下的什么位置。 //@lang 选取名为 lang 的所有属性(获取所有名为lang属性的值)。2)谓语
路径表达式 结果 /bookstore/book[1] 选取属于 bookstore 子元素的第一个 book 元素。 /bookstore/book[last()] 选取属于 bookstore 子元素的最后一个 book 元素。 /bookstore/book[last()-1] 选取属于 bookstore 子元素的倒数第二个 book 元素。 /bookstore/book[position()35.00] 选取 bookstore 元素的所有 book 元素,且其中的 price 元素的值须大于 35.00。 /bookstore/book[price>35.00]/title 选取 bookstore 元素中的 book 元素的所有 title 元素,且其中的 price 元素的值须大于 35.00。3)通配符
通配符 描述 * 匹配任何元素节点。 @* 匹配任何属性节点。 node() 匹配任何类型的节点。通配符举例:
路径表达式 结果 /bookstore/* 选取 bookstore 元素的所有子元素。 //* 选取文档中的所有元素。 //title[@*] 选取所有带有属性的 title 元素。4)|或运算符
路径表达式 结果 //book/title | //book/price 选取 book 元素的所有 title 和 price 元素。 //title | //price 选取文档中的所有 title 和 price 元素。 /bookstore/book/title | //price 选取属于 bookstore 元素的 book 元素的所有 title 元素,以及文档中所有的 price 元素。python2.7、python3.6中代码:
# coding:utf-8 # 网络爬虫库lxml的应用 from lxml import etree print(u'解析html(具有自动修复功能)') text = '''''' html = etree.HTML(text) result = etree.tostring(html) print(result) # 将字符串写入文件 fh = open('test.html', 'w') fh.write(result.decode("utf8")) #fh.write(result) fh.close() print(u'读取文件(要求html代码完整)') html = etree.parse('test.html') #只能解析本地html、xml文件 result = etree.tostring(html, pretty_print=True) print(result) print(u'获取所有的- first item
- second item
- third item
- fourth item
- fifth item
- 标签') html = etree.parse('test.html') # 创建dom树 print(type(html)) result = html.xpath('//li') # 获取元素列表 print(result) print(len(result)) # 获取列表长度 print(type(result)) print(type(result[0])) # 获取元素 result = html.xpath('//li/@class') # 获取
- 标签的所有 class属性的值 print(result) result = html.xpath('//li/a[@href="link1.html"]') # 获取
- 标签下 href 为 link1.html 的 标签 print(result) result = html.xpath('//li//span') # 获取
- 标签下的所有后代元素 标签 print(result) result = html.xpath('//li/span') # 获取
- 标签下的所有子元素 标签 print(result) result = html.xpath('//li/a//@class') # 获取
- 标签下的所有a元素的后代 class print(result) result = html.xpath('//li[last()]/a/@href') # 获取最后一个
- 下的 的 href属性 print(result) result = html.xpath('//li[last()-1]/a') # 获取倒数第二个li元素下的a元素列表 print(result[0].text) # 打印输出元素文本 result = html.xpath('//*[@class="bold"]') # 获取 class 为 bold 的标签名 print(result[0].tag)
4. lxml模块使用
1)实例化etree对象
要使用XPath表达式进行数据解析,首先需要实例化一个etree对象,具体方法有两种,分别介绍如下。
(1)etree.parse('HTML文档路径')
对于本地HTML文档,使用parse()函数进行etree对象的实例化。
演示代码如下:
1 from lxml import etree 2 html = etree.parse('test1.html') #将HTML文档加载到etree类中,实例化成一个名为html的etree对象(2)etree.HTML(网页源代码)
对于爬虫程序从网站服务器获取到的网页源代码字符串,使用HTML()函数进行etree对象的实例化。
演示代码如下:
1 import requests 2 from lxml import etree 3 headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.108 Safari/537.36'} 4 response = requests.get(url='https://www.baidu.com', headers=headers) # 获取响应对象 5 result = response.text # 获取响应对象中的网页源代码 6 html = etree.HTML(result) # 将获取的网页源代码加载到etree类中,实例化成一个名为html的etree对象2)用XPath表达式定位标签并提取数据
完成etree对象的实例化后,就可以使用XPath表达式定位标签并提取数据了。
(1)定位标签
XPath表达式提供了多种定位标签的方法,下面以开头的树状图为例,分别进行介绍。
- 标签名定位
假设要定位
- 标签节点下的所有
- 标签节点,在图中从下往上逆向推导可知,路径是从上往下依次定位标签节点→标签节点→标签节点2→
- 标签节点→
- 标签节点1、
- 标签节点2。那么如何表达每个标签节点之间的层级关系呢?很简单,用“/”表示一个层级,用“//”表示多个层级,因此,上述路径的XPath表达式为“/html/body/div[1]/ul/li”。
如果需要不加区分地定位页面中的所有
- 标签,也可以用“//”表示
- 标签节点之上的每一级标签节点,对应的XPath表达式为“//li”。
- 索引定位
etree对象的每一个层级都是一个包含所有标签节点的列表,如果同一层级中有多个同名的标签节点,使用列表切片就能定位到所需的标签节点,即通过索引定位。
- 属性定位
在复杂的网页中,每个标签都有其属性,此时可以通过属性进行定位。
演示代码如下:
1 import requests 2 from lxml import etree 3 headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.108 Safari/537.36'} 4 response = requests.get(url='https://www.baidu.com', headers=headers) 5 result = response.text 6 html = etree.HTML(result) # 实例化etree对象 7 print(html.xpath('//*[@class = 'title']')) # 用class属性定位标签第7行代码中的“//”表示多个层级,处于XPath表达式的开头代表从任意层级开始定位;“*”代表任意标签;“[@class = 'title']”代表定位class属性值为title的任意标签。使用这种方法能定位到指定属性的任意标签。
如果拥有同一个class属性值的标签不止一个,可考虑用id属性值来定位,因为在同一个网页中一个id属性值通常只能出现一次。如果还不能达到目的,可用其他属性来定位,也可将上述XPath表达式中的“*”替换为指定的标签名称,如html.xpath('//p[@class = 'title']')。
- 逻辑运算定位
如果使用上述方法仍然不能满足要求,可以配合逻辑运算来进行更精确的定位。
演示代码如下:
1 html.xpath('//p[@class="title" and @name="color"]') 2 html.xpath('//p[@class="title" or @name="color"]')第1行代码中的“and”表示定位同时满足两种属性条件的标签节点。第2行代码中的“or”表示定位满足两种属性条件中的任意一个条件的标签节点。
(2)提取文本内容和属性值
定位到标签节点后,可在XPath表达式后面添加“/text()”来提取该节点的直系文本内容,添加“//text()”来提取该节点下的所有文本内容,添加“/@属性名”来提取该节点的指定属性值。
演示代码如下:
1 html.xpath('//*[@class="title"]/text()') 2 html.xpath('//*[@class="title"]//text()') 3 html.xpath('//*[@class="title"]/@id')3)快速获取标签节点的XPath表达式
XPath表达式虽然不复杂,但编写时还是需要费点心思,那么有没有更快捷的方法来获取XPath表达式呢?答案是肯定的。使用谷歌浏览器开发者工具的右键快捷菜单命令就能快速获取XPath表达式。
在谷歌浏览器中打开一个网页,然后打开开发者工具,在“Elements”选项卡下的网页源代码中右击要获取XPath表达式的标签,在弹出的快捷菜单中执行“Copy>Copy XPath”命令,如下图所示,即可复制该标签的XPath表达式。随后就可以将复制的XPath表达式粘贴到爬虫代码中使用了。
5. lxml模块使用案例
使用 Xpath 解析网页数据的步骤:
- 从 lxml 导入 etree;
- 解析数据,返回 xml 结构;
- 使用 .xpath() 寻找和定位数据。
import requests from lxml import etree from fake_useragent import UserAgent # 伪装请求头的库 # 伪装请求头中的浏览器 ua = UserAgent() url = "https://book.douban.com/subject/27147922/comments/" # html数据,使用requests获取 # 写爬虫最实用的是可以随意变换headers,一定要有随机性。ua.random支持随机生成请求头 r = requests.get(url, headers={"User-Agent": ua.random}).text # print(r) # 解析html数据 s = etree.HTML(r) # 使用.xpath() print(s.xpath('//*[@id="comments"]/div[1]/ul/li[1]/div[2]/p/span')) # [] # 获取文本,加上/text() print(s.xpath('//*[@id="comments"]/div[1]/ul/li[1]/div[2]/p/span/text()')) # ['周而复始、如履薄冰的生活仍值得庆幸,因为无论是主动还是被动的脱轨,都可能导致万劫不复。吉根是描绘“日常灾难”的大师,所有绝望都薄如蝉翼,美得微妙。']获取Xpath的两种方法:
第一种方法:从浏览器直接复制
- 首先在浏览器上定位到需要爬取的数据;
- 右键,点击“检查”,在“Elements”下找到定位到所需数据;
- 右键——Copy——Copy Xpath,即可完成Xpath的复制。
第二种方法:手写 Xpath
- 获取文本内容用 text()。
- 获取注释用 comment()。
- 获取其它任何属性用@xx,如:src、value 等。
- 想要获取某个标签下所有的文本(包括子标签下的文本),使用 string。
- 如”< p>123< a>来获取我啊< /a>< /p>”,这边如果想要得到的文本为”123来获取我啊”,则需要使用 string。
- starts-with 匹配字符串前面相等。
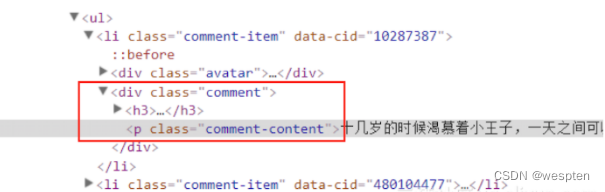
1 # 手写Xpath 2 import requests 3 from lxml import etree 4 5 url = 'https://book.douban.com/subject/1084336/comments/' 6 r = requests.get(url).text 7 8 s = etree.HTML(r) 9 print(s.xpath('//div[@class="comment"]/p/text()')[0])使用 Xpath 爬取豆瓣图书《小王子》短评网页
import requests from lxml import etree from fake_useragent import UserAgent # 伪装请求头的库 # 伪装请求头中的浏览器 ua = UserAgent() url = 'https://book.douban.com/subject/1084336/comments/' r = requests.get(url, headers={"User-Agent": ua.random}).text s = etree.HTML(r) # 从浏览器复制第一条评论的Xpath print(s.xpath('//*[@id="comments"]/div[1]/ul/li[1]/div[2]/p/span/text()')) # 从浏览器复制第二条评论的Xpath print(s.xpath('//*[@id="comments"]/div[1]/ul/li[2]/div[2]/p/span/text()')) # 从浏览器复制第三条评论的Xpath print(s.xpath('//*[@id="comments"]/div[1]/ul/li[3]/div[2]/p/span/text()')) # 掌握规律,删除li[]的括号,获取全部短评 # print(s.xpath('//*[@id="comments"]/div[1]/ul/li/div[2]/p/span/text()')) # 手写Xpath获取全部短评 # print(s.xpath('//div[@class="comment"]/p/span/text()'))执行效果:
['十几岁的时候渴慕着小王子,一天之间可以看四十四次日落。是在多久之后才明白,看四十四次日落的小王子,他有多么难过。'] ['读了好多年,终于读完了,但是实在共鸣不起来,虽然知道那些道理,但真的觉得没什么了不起啊,是我还太幼稚吗?'] ['我早该猜到,在她那可笑的伎俩后面是缱绻柔情啊。花朵是如此的天真无邪,可是,我毕竟太年轻了,不知该如何去爱她。']通过对比可以发现从浏览器复制的 Xpath 中,“li[]”括号中的数字代表对应的第几条评论,直接删除括号,即可获取全部短评。
对于结构清晰的 html 网页,可以直接手写 Xpath,更加简洁且高效。
对于结构复杂的 html 网页,可以通过浏览器复制的方式获取 Xpath。
6. pyquery模块
在线安装方法:cmd中输入”pip install pyquery”。
python2.7、python3.6中代码:
六、Scrapy爬虫项目框架 1、Scrapy简介#coding:utf-8 #网络爬虫库pyquery的应用,以下代码同时支持python2和python3 from pyquery import PyQuery as pq print(u'=====================初始化====================') doc = pq("") #传入html代码 #from lxml import etree #doc = pq(etree.fromstring("")) #可以首先用lxml 的 etree 处理一下代码 doc = pq('http://www.baidu.com') #传入网址 text = '''''' #将字符串写入文件 fh = open('test.html', 'w') fh.write(text) fh.close() doc = pq(filename='test.html') #传入本地文件 print(doc.html()) #获取元素的内部html代码 print(type(doc)) #返回类型是PyQuery li = doc('li') #获取所有的li元素 print(type(li)) #返回类型依然是PyQuery,可以进行二次筛选 print(li.text()) #获取li的内部文本 print(u'=====================属性====================') p = pq('')('p') #创建dom树后获取标签 print(p.attr("id")) #读取属性值 print(p.attr("id", "plop")) #设置属性值 print(p.attr("id", "hello")) #设置属性值 print(p.addClass('beauty')) #添加class print(p.removeClass('hello')) #去除class print(p.css('font-size', '16px')) #设置css值 print(p.css({'background-color': 'yellow'})) #通过列表设置css print(u'=====================DOM====================') print(p.append(' check out reddit')) #在内部原有html代码后添加代码 print(p.prepend('Oh yes!')) #在内部原有html代码前添加代码 d = pq('- first item
- second item
- third item
- fourth item
- fifth item
') #创建一个dom树 td = d('#test') #获取id为test的元素 p.prependTo(td) #将p元素添加到td元素内,在td内部html代码的前面,源节点不变 print(d) d.empty() #清空元素内部html代码 print(d) print(u'=====================遍历====================') doc = pq(filename='test.html') lis = doc('li') for li in lis.items(): print(li.html()) #打印li元素的内部html代码 print(lis.each(lambda e: e)) #each遍历函数,lambda表达式,不常用 print(u'=====================网页请求====================') print(pq('http://www.525heart.com/index/index/index.html', headers={'user-agent': 'pyquery'})) #get请求方式,可设置headers print(pq('http://httpbin.org/post', {'foo': 'bar'}, method='post', verify=True)) #post请求方式,可设置data和headers,已经控制是否检验GermyScrapy 是一套用 python 编写的异步爬虫框架,基于 twisted 实现,运行于 linux/windows/macOS 等多种环境,具有速度快、扩展性强、使用简便等特点。
Scrapy 可以在本地运行,也能部署到云端(scrapyd)实现真正的生产级数据采集系统。
Scrapy架构:
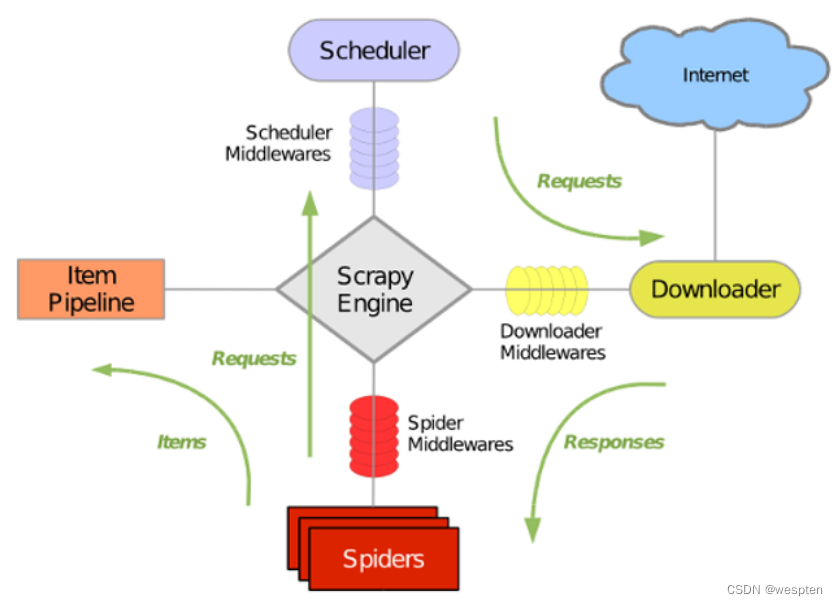
- Scrapy Engine(引擎):Scrapy框架的核心部分,负责在Spider和ItemPipeline、Downloader、Scheduler之间通信、传递数据等。
- Spider(爬虫):发送需要爬取的链接给引擎,最后引擎把其他模块请求回来的数据再发送给爬虫,爬虫就去解析想要的数据。这个部分是我们开发者自己写的,因为要爬取哪些链接,页面中的哪些数据是我们需要的,都是由程序员自己决定。
- Scheduler(调度器):负责接收引擎发送过来的请求,并按照一定的方式进行排列和整理,负责调度请求的顺序等。
- Downloader(下载器):负责接收引擎传过来的下载请求,然后去网络上下载对应的数据再交还给引擎。
- Item Pipeline(管道):负责将Spider(爬虫)传递过来的数据进行保存。具体保存在哪里,应该看开发者自己的需求。
- Downloader Middlewares(下载中间件):可以扩展下载器和引擎之间通信功能的中间件。
- Spider Middlewares(Spider中间件):可以扩展引擎和爬虫之间通信功能的中间件。
github托管:https://github.com/data-infra/crawler/tree/master/myscrapy
2、Scrapy安装在cmd中输入:
pip install Scrapy Or pip install -i https://pypi.douban.com/simple/scrapyScrapy的安装依赖wheel、twiste、lxml包。所以先通过pip install wheel安装wheel库,通过pip install lxml安装lxml库,不过twiste包必须通过离线whl文件安装。
进入http://www.lfd.uci.edu/~gohlke/pythonlibs/,在网页中搜索twisted找到其对应的whl包并下载 Twisted‑17.9.0‑cp36‑cp36m‑win_amd64.whl
成功安装了上面的依赖包,就可以通过pip在线安装Scrapy了。
验证安装:cmd中输入Scrapy,显示如下图,表示安装成功。现在Scrapy已经出到了1.4版。
另外你需要在cmd中输入以下命令,分别安装pywin32、pyOPENSSL、lxml包。
3、Scrapy处理流程Scrapy Engine(Scrapy核心) 负责数据流在各个组件之间的流动。
Spiders(爬虫)发出Requests请求,经由Scrapy Engine(Scrapy核心) 交给Scheduler(调度器),Downloader(下载器)Scheduler(调度器) 获得Requests请求,然后根据Requests请求,从网络下载数据。Downloader(下载器)的Responses响应再传递给Spiders进行分析。根据需求提取出Items,交给Item Pipeline进行下载。Spiders和Item Pipeline是需要用户根据响应的需求进行编写的。
除此之外,还有两个中间件,Downloaders Mddlewares和Spider Middlewares,这两个中间件为用户提供方面,通过插入自定义代码扩展Scrapy的功能,例如去重等。
Scrapy执行流程:
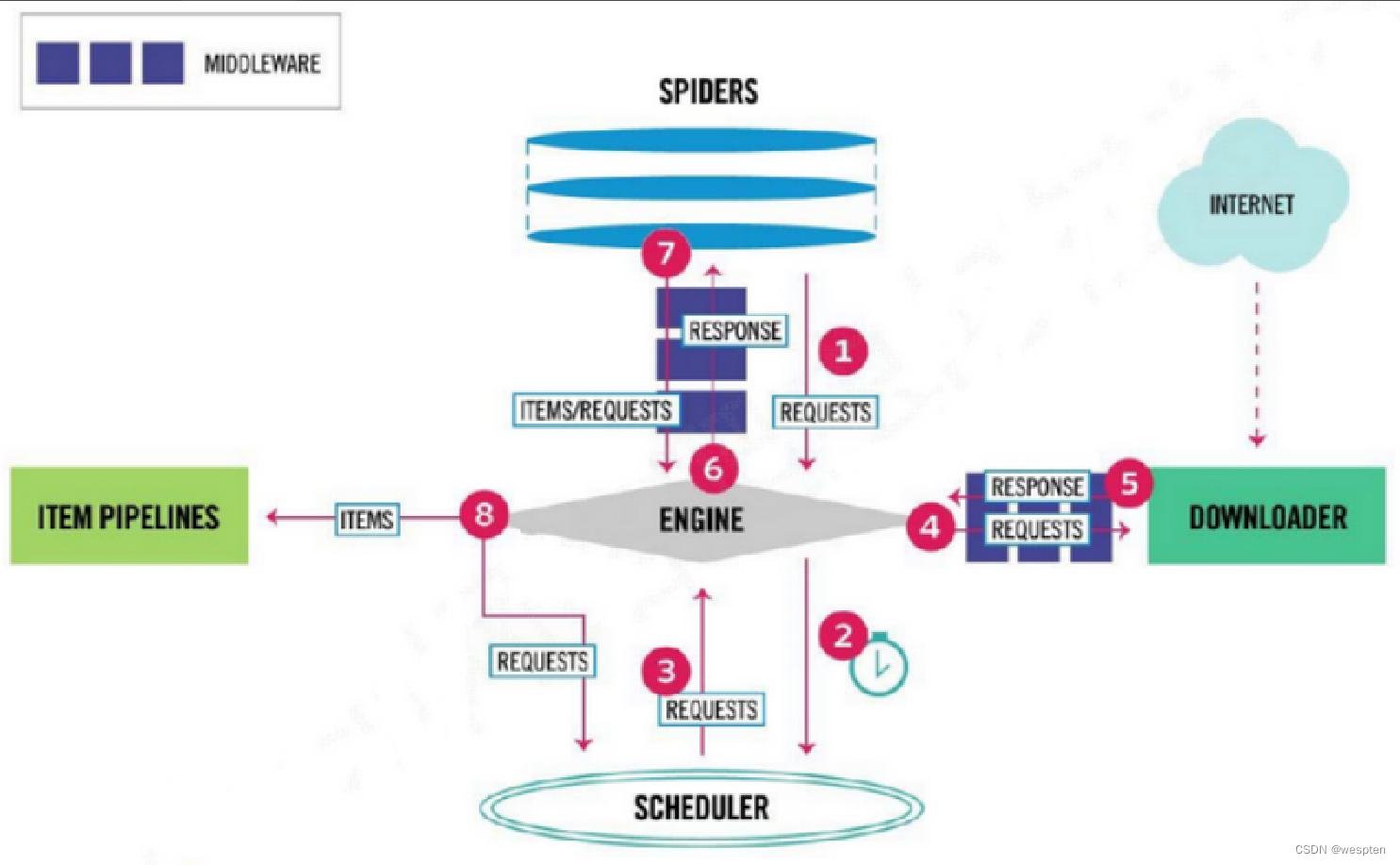
Scrapy 框架的执行顺序:
- Spiders 的 yeild 将 request 发送给 Engine;
- Engine 对request 不做任何处理发送给 Scheduler;
- Scheduler 生成 request交给 Engine;
- Engine 拿到 request,通过 Middleware 进行层层过滤发送给 Downloader;
- Downloader 在网上获取到 response 数据之后,又经过 Middleware 进行层层过滤发送给 Engine;
- Engine 获取到 response 数据之后,返回给 Spiders,Spiders 的 parse() 方法对获取到的 response 数据进行处理,解析出 items 或者 requests;
- 将解析出来的 items 或者 requests 发送给 Engine;
- Engine 获取到 items 或者 requests,将 items 发送给Iitem Pipelines,将 requests 发送给Scheduler。 注意!只有当 Scheduler 中不存在任何 request 了,整个程序才会停止(也就是说,对于下载失败的 url,scrapy 也会重新下载)。
示例:
- 引擎:Hi!Spider, 你要处理哪一个网站?
- Spider:老大要我处理xxxx.com。
- 引擎:你把第一个需要处理的URL给我吧。
- Spider:给你,第一个URL是xxxxxxx.com。
- 引擎:Hi!调度器,我这有request请求你帮我排序入队一下。
- 调度器:好的,正在处理你等一下。
- 引擎:Hi!调度器,把你处理好的request请求给我。
- 调度器:给你,这是我处理好的request。
- 引擎:Hi!下载器,你按照老大的下载中间件的设置帮我下载一下这个request请求。
- 下载器:好的!给你,这是下载好的东西。(如果失败:sorry,这个request下载失败了。然后引擎告诉调度器,这个request下载失败了,你记录一下,我们待会儿再下载)。
- 引擎:Hi!Spider,这是下载好的东西,并且已经按照老大的下载中间件处理过了,你自己处理一下(注意!这儿 responses 默认是交给 parse() 这个函数处理的)。
- Spider:(处理完毕数据之后对于需要跟进的URL)Hi!引擎,我这里有两个结果,这个是我需要跟进的URL,还有这个是我获取到的Item数据。
- 引擎:Hi!管道,我这儿有个item你帮我处理一下。Hi!调度器,这是需要跟进URL你帮我处理下。然后从第四步开始循环,直到获取完老大需要全部信息。
- 管道&调度器:好的,现在就做!
Scrapy 常用命令:
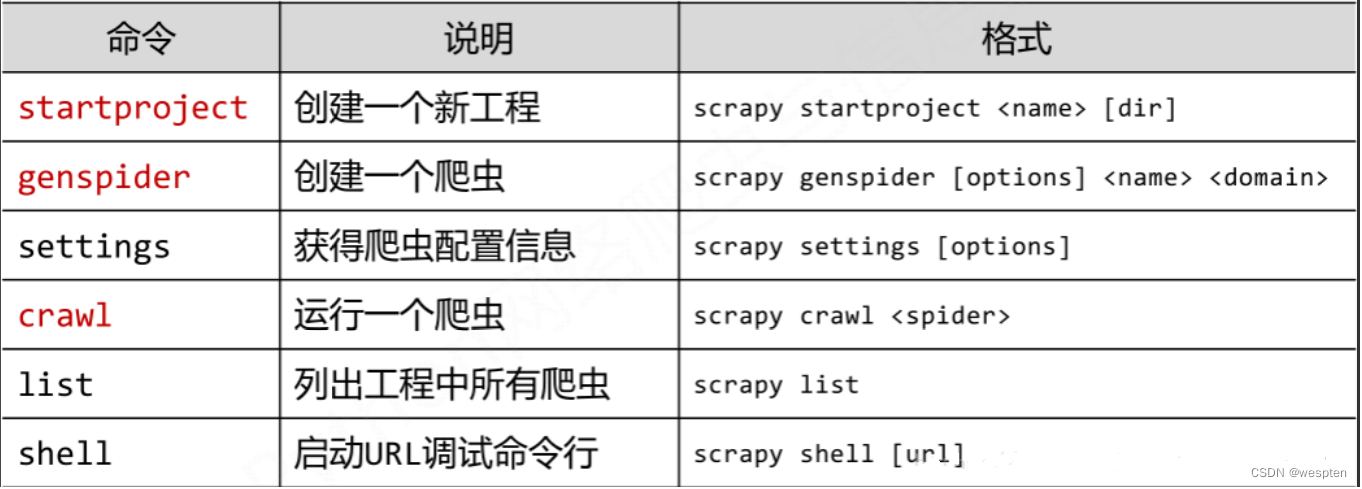
Scrapy 保存信息的简单方法:
- json格式,默认为Unicode编码:scrapy crawl 项目名 -o 项目名.json
- json lines格式,默认为Unicode编码:scrapy crawl 项目名 -o 项目名.jsonlines
- csv 逗号表达式,可用Excel打开:scrapy crawl 项目名 -o 项目名.csv
- xml格式:scrapy crawl 项目名 -o 项目名.xml
Parse()方法的工作机制:
- 因为使用的yield,而不是return。parse函数将会被当做一个生成器使用。scrapy会逐一获取parse方法中生成的结果,并判断该结果是一个什么样的类型;
- 如果是request则加入爬取队列,如果是item类型则使用pipeline处理,其他类型则返回错误信息;
- scrapy取到第一部分的request不会立马就去发送这个request,只是把这个request放到队列里,然后接着从生成器里获取;
- 取尽第一部分的request,然后再获取第二部分的item,取到item了,就会放到对应的pipeline里处理;
- Parse()方法作为回调函数(callback)赋值给了Request,指定parse()方法来处理这些请求 scrapy.Request(url, callback=self.parse);
- Request对象经过调度,执行生成 scrapy.http.response()的响应对象,并送回给parse()方法,直到调度器中没有Request(递归的思路);
- 取尽之后,parse()工作结束,引擎再根据队列和pipelines中的内容去执行相应的操作;
- 程序在取得各个页面的items前,会先处理完之前所有的request队列里的请求,然后再提取items;
- 这一切的一切,Scrapy引擎和调度器将负责到底。
Scrapy 项目的开发步骤:
可以使用命令行来新建一个爬虫工程,这个工程会自动按照scrapy的结构创建一个工程目录。
- 创建项目:scrapy startproject xxx(项目名字,不区分大小写)
- 明确目标 (编写items.py):明确你想要抓取的目标
- 制作爬虫 (spiders/xxspider.py):制作爬虫开始爬取网页
- 存储内容 (pipelines.py):设计管道存储爬取内容
- 启动程序的py文件(start.py):等同于此命令(scrapy crawl xxx -o xxx.json)
spiders文件夹下定义的爬虫,请求网址,获取响应,解析数据,赋值想要的数据给items中定义的类实体。最后会自动调用pipelines下的类获取items中的数据,进一步做处理。
1. 创建项目
创建项目,在cmd中先cd到你的项目路径,然后使用scrapy创建一个项目。这里将项目放在D:\scrapydemo文件夹下。
所以在cmd中执行:
D: cd /scrapydemo scrapy startproject projectnamescrapy startproject是固定命令,后面的projectname是自己想起的工程名字。
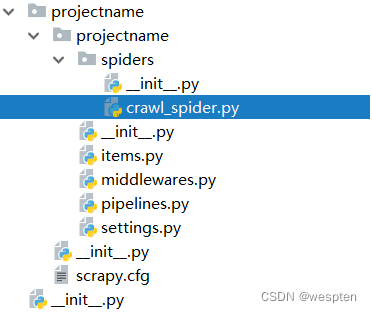
该命令将会创建包含下列内容的projectname目录:
projectname/ scrapy.cfg projectname/ __init__.py items.py middlewares.py pipelines.py settings.py spiders/ __init__.py ...这些文件分别是:
- scrapy.cfg: 项目的配置文件;
- projectname/: 该项目的python模块。之后将在此加入Spider代码;
- projectname/items.py: 项目中的item文件,定义需要的实体类;
- projectname/middlewares .py:项目中的中间件,不用关心;
- projectname/pipelines.py: 项目中的pipelines文件;用来写爬虫之后的处理文件;
- projectname/settings.py: 项目的设置文件,定义参数;
- projectname/spiders/: 放置spider代码的目录。定义爬虫要放在这个文件夹下;
2. 定义我们需要的实体类items.py
在这里我们定义我们需要的文章名称、链接、阅读数目:
# -*- coding: utf-8 -*- # 定义我们要爬取信息的标准格式,这个类被爬虫引用,爬虫解析数据后赋值给该类实例,并将类实例提交给pipelines,再进行进一步处理。 import scrapy class myentity(scrapy.Item): name = scrapy.Field() link = scrapy.Field() readnum = scrapy.Field()3. 创建一个爬虫
我们使用这个爬虫获取博客下的文章名称、链接地址、阅读数量。
在projectname/spiders/文件夹下新建一个crawl_spider.py,我们在这里实现请求、响应、解析的过程。
# -*- coding: utf-8 -*- # 在这里实现请求、响应、解析的过程 import re import scrapy import urllib from scrapy import Selector from projectname.items import myentity class MySpider(scrapy.Spider): name = 'myspider' #爬虫名称,需要这个名称才能启动爬虫 def __init__(self): self.allowed_domains = ['blog.csdn.net'] self.start_urls = ['http://blog.csdn.net/luanpeng825485697/article/list/'] #从start_requests发送请求 def start_requests(self): yield scrapy.Request(url = self.start_urls[0]+"1", meta = {'data':1},callback = self.parse1) #请求网址,设置响应函数,同时向响应函数传递参数 #解析response,获得文章名称、连接、阅读数目,还可以进行二次请求。 def parse1(self, response): index = response.meta['data'] #接收请求函数发来的参数 if index>100: #这里只爬取前100页 return hxs = Selector(response) #文章链接地址 links = hxs.xpath("//span[@class='link_title']/a[1]/@href").extract() #xpath路径表达式获取文章连接地址 #文章名 names = hxs.xpath("//span[@class='link_title']/a[1]/text()").extract() #xpath路径表达式获取文章名 #文章阅读数量 reads = hxs.xpath("//span[@class='link_view']/text()").extract() #xpath路径表达式获取文章阅读数量 #将爬取的数据赋值给items for i in range(1,len(links)): item = myentity() item['link'] = urllib.parse.urljoin('http://blog.csdn.net/',links[i]) #获取绝对域名 item['name'] = names[i] item['readnum'] = reads[i] # 返回item,交给item pipeline处理 yield item #迭代下一页 yield scrapy.Request(url=self.start_urls[0]+str(index+1), meta={'data': index+1}, callback=self.parse1)4. 设置pipeline处理文件
pipeline主要是负责根据item数据进行下一步处理,比如下载图片,保存文件,
这里只是把item中的文章名称、链接、阅读书目进行保存文件。
data文件地址:crawler/myscrapy/projectname at master · data-infra/crawler · GitHub
# -*- coding: utf-8 -*- #pipelines.py主要根据item保存的信息,进行进一步多线程操作 from projectname import settings from scrapy import Request import requests import os class MyPipeline(object): allpaper=[] def process_item(self, item, spider): paper={} paper['name']=item['name'] paper['link'] = item['link'] paper['read'] = item['readnum'] self.allpaper.append(paper) file_object = open('data.txt', 'a') file_object.write(str(paper)+"\r\n") file_object.close() return item5. 完善settings配置文件
settings.py中的内容大部分都是自动生成的,我们不需要做太多改动,在这里只是使用字典的形式定义自己的pipelines中的处理类。
SPIDER_MODULES = ['projectname.spiders'] #自动生成的内容; NEWSPIDER_MODULE = 'projectname.spiders' #自动生成的内容; # Obey robots.txt rules #它的作用是,告诉搜索引擎爬虫,本网站哪些目录下的网页不希望你进行爬取收录 ROBOTSTXT_OBEY = False #自动生成的内容,是否遵守robots.txt规则,这里选择不遵守; ITEM_PIPELINES = { #定义item的pipeline; 'projectname.pipelines.MyPipeline': 1, #此处的1表示优先级,因为本项目只用到这一个pipeline,所以随意取0-1000中的一个数值即可 } DOWNLOAD_DELAY = 0.25 # 下载延时,这里使用250ms延时。 COOKIES_ENABLED = False #Cookie使能,这里禁止Cookie;支持我们需要编写的东西都完成了。
下图是文件目录结构:
6. 运行scrapy项目
首先在cmd中cd到自己的项目文件夹下,即scrapy.cfg所在的目录中,这里cd到D:\scrapydemo\projectname文件夹下,然后使用下面的代码运行自己的爬虫。
myspider就是在crawl_spider.py文件中的name变量:
6、Scrapy项目开发scrapy crawl myspider1. setting.py:爬虫基本配置
必选配置项:
BOT_NAME = 'tutorial' SPIDER_MODULES = ['tutorial.spiders'] NEWSPIDER_MODULE = 'tutorial.spiders' ROBOTSTXT_OBEY = False # 若抓不到东西,就设置为True # 取消下述注释行 ITEM_PIPELINES = { 'tutorial.pipelines.TutorialPipeline': 300, }可选配置项:
- CONCURRENT_REQUESTS_PER_DOMAIN = 16 # 每个域名,同时并发的请求次数限制;
- CONCURRENT_REQUESTS_PER_IP = 16 # 每个IP,同时并发的请求次数限制;
- CONCURRENT_REQUESTS = 32 # 框架最大的并发请求数量,针对多个域名和多个ip的一个并发请求上限;
2. items.py:定义您想抓取的数据
# Define here the models for your scraped items # # See documentation in: # https://docs.scrapy.org/en/latest/topics/items.html import scrapy class TutorialItem(scrapy.Item): # define the fields for your item here like: # name = scrapy.Field() URL = scrapy.Field() # 存放当前网页地址 TITLE = scrapy.Field() # 存放当前网页title,格式类似于:百度一下 H1 = scrapy.Field() # 存放一级标题 TEXT = scrapy.Field() # 存放正文3. spider目录下的sohu.py:编写提取数据的Spider
- 拿到每个网页的页面源码;
- 拿到网页源码中的url;
- 把网页源码中要的4个数据都存到一个类似字典格式的字符串;
- 把抓取的结果发给pipelines做持久化;
- 把新获取的url通过递归的方式,进行抓取;
import scrapy import re,os from tutorial.items import TutorialItem from scrapy import Request class SohuSpider(scrapy.Spider): name = 'sohu' # 项目名称 # allowed_domains = ['www.sohu.com'] # 如果指定爬虫作用范围,则作用于首页之后的页面 start_urls = ['http://www.sohu.com/'] # 开始url def parse(self, response): # response:网页源码对象 # 从源码对象中获取/html下的所有标签内容,拿到了所有网页的源码 all_urls = re.findall('href="(.*?)"',response.xpath("/html").extract_first()) for url in all_urls: # 每生成这个对象,就可以存储一组4个数据 item = TutorialItem() if re.findall("(\.jpg)|(\.jpeg)|(\.gif)|(\.ico)|(\.png)|(\.js)|(\.css)$",url.strip()): pass # 去掉无效链接 elif url.strip().startswith("http") or url.strip().startswith("//"): temp_url = url.strip() if url.strip().startswith('http') else 'http:' + url.strip() # 三目运算符获取完整网址 item = self.get_all(item,response) # 判断item中存在正文且不为空,页面一级标题不为空 if 'TEXT' in item and item['TEXT'] != '' and item['TITLE'] != '': yield item # 发送到管道 print('发送到下载器') # 提示 yield Request(temp_url,callback=self.parse) # 递归调用,实现了不断使用新的url进行下载 # 自定义封装的方法:从网页中提取4个要爬取的内容放到类似字典item的里面 def get_all(self,item,response): # 获取当前页面的网址、title、一级标题、正文内容 item['URL'] = response.url.strip() item['TITLE'] = response.xpath('/html/head/title/text()').extract()[0].strip() contain_h1 = response.xpath('//h1/text()').extract() # 获取当前网页所有一级标题 contain= contain_h1[0] if len(contain_h1) !=0 else "" # 获取第一个一级标题 item["H1"] = contain.strip() main_text = [] # 遍历网页中所有p标签和br标签的内容 for tag in ['p','br']: sub_text = self.get_content(response,tag) main_text.extend(sub_text) # 对正文内容去重并判断不为空 main_text = list(set(main_text)) if len(main_text) != 0: item['TEXT'] = '\n'.join(main_text) return item def get_content(self,response,tag): # 判断只有大于100个文字的内容才保留 main_text = [] contexts = response.xpath('//'+tag+'/text()').extract() for text in contexts: if len(text.strip()) > 100: main_text.append(text.strip()) return main_text4. pipelines.py:将爬取后的item数据进行存储
# Define your item pipelines here # # Don't forget to add your pipeline to the ITEM_PIPELINES setting # See: https://docs.scrapy.org/en/latest/topics/item-pipeline.html import json class TutorialPipeline(object): def __init__(self): # 存爬取数据的文件句柄 self.filename = open("content.txt",'w',encoding="utf-8") # 集合对象,用于去重爬取数据 self.contain = set() # 数据怎么存 def process_item(self, item, spider): # item:爬取来的数据 # 抓取后的数据,包含中文的话,可以直接看到正文。等价于text= str(item) text = json.dumps(dict(item),ensure_ascii=False) + '\n' # 把json串转换为字典 text_dict = eval(text) # 用字典去取数据 if text_dict['URL'] not in self.contain: # 抓取到新网页,并写入文件 # 判断url是否被抓取过,如果没有被抓取过,就存到文件里面 for _,targetName in text_dict.items(): # 实现存储数据的逻辑 # 网页正文包含“人”才会保存, # “人”是我们想抓取页面的核心关键词,可以换成其它关键词 if "人" in targetName: # 有的话,把这个字典写到文件里面 self.write_to_txt(text_dict) # 避免重复写入 break # 每次记录文件后把网页url写入集合,重复的url会自动过滤掉 self.contain.add(text_dict['URL']) # 表示item处理完了 return item # 爬虫关掉时,把文件关掉 def close_spider(self,spider): self.filename.close() # 具体把字典写入到文件的方法 def write_to_txt(self,text_dict): # 把抓取到的内容写入文件中 for key,value in text_dict.items(): self.filename.write(key+"内容:\n"+value+'\n') self.filename.write(50*'='+'\n')说明:
Item 在 Spider 中被收集之后,它将会被传递到 Item Pipeline,一些组件会按照一定的顺序执行对 Item 的处理。
每个 Item Pipeline 组件(有时称之为“Item Pipeline”)是实现了简单方法的 python 类。他们接收到 Item 并通过它执行一些行为,同时也决定此 Item 是否继续通过 Pipeline,或是被丢弃而不再进行处理。
Item Pipeline 的一些典型应用:
- 清理 HTML 数据
- 验证爬取的数据(检查 Item 包含某些字段)
- 查重(并丢弃)
Item Pipeline的内置方法
每个 item pipiline 组件是一个独立的 python 类,同时必须实现以下方法:
process_item(item, spider)每个item pipeline组件都需要调用该方法,这个方法必须返回一个 Item(或任何继承类)对象, 或是抛出 DropItem 异常,被丢弃的 item 将不会被之后的 pipeline 组件所处理。
- item (Item 对象) – 被爬取的 item
- spider (Spider 对象) – 爬取该 item 的 spider
open_spider(spider)当 spider 被开启时,这个方法被调用。
- spider (Spider 对象) – 被开启的 spider
close_spider(spider)当 spider 被关闭时,这个方法被调用。
- spider(Spider 对象)– 被关闭的 spider
5. 执行结果:查看爬取数据
在根目录下执行命令:
方式一 指定json文件输出:
scrapy crawl sohu -o items.json方式二 根据pipelines.py定义输出:
scrapy crawl sohu例:E:\tutorial无限制爬取\tutorial>scrapy crawl sohu
七、数据清洗
通过前面的学习,大家应该能够进行简单的数据爬取了,但是采集到的原始数据还可能含有缺失值、重复值、异常值或乱码,并不能直接用于分析。为了保证数据分析的准确性,需要先对缺失值、重复值、异常值或乱码进行处理,这项工作称为数据清洗。
1、异常值的处理代码文件:异常值的处理.py、test.csv
假设要处理的数据存储在“test.csv”文件中,先使用pandas模块将数据读取出来,并赋给变量data。
演示代码如下:
1 import pandas as pd 2 data = pd.read_csv('test.csv') 3 print(data)代码运行结果如下图所示:
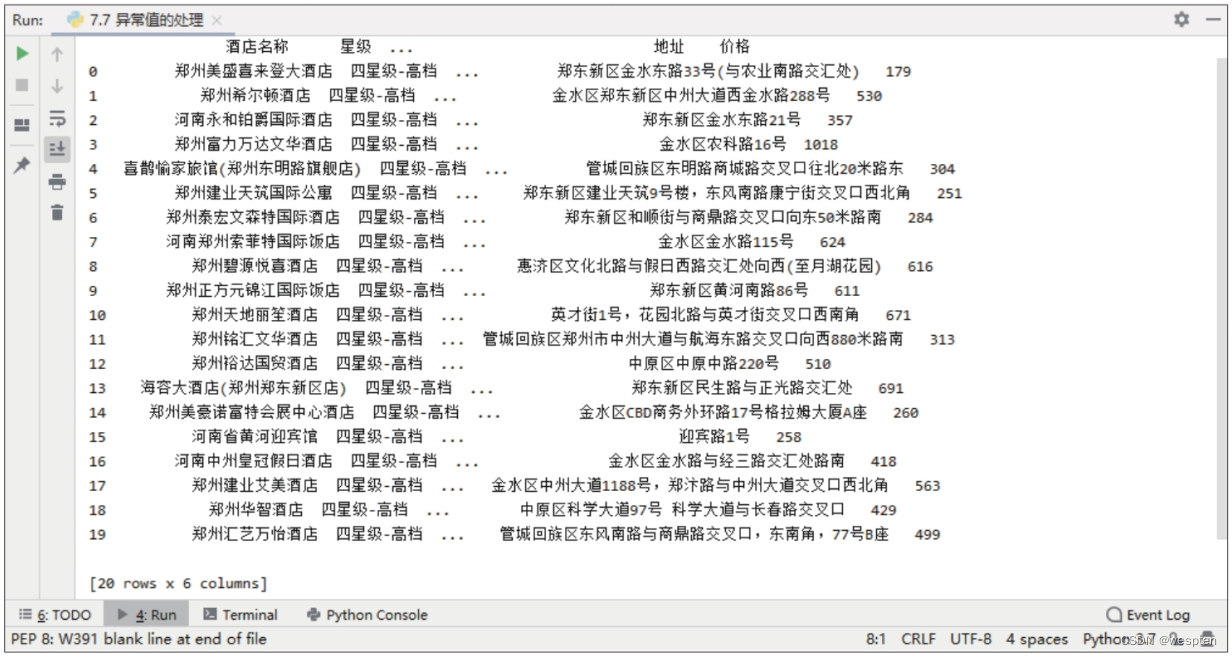
在同一列中,可能会有个别值与其他值的差距较大。例如,“价格”列中大部分的值位于100~1000之间,而行标签为3的行的价格值却大于1000,这种值通常就需要标记为异常值并做处理。异常值的常用处理方法有两种,下面分别介绍。
第一种方法是将异常值替换为空值,然后删除空值。
演示代码如下:
1 data['价格'][data['价格'] > 1000] = None # 将“价格”列中大于1000的值替换为空值 2 print(data.dropna()) # 删除空值所在的行代码运行结果如下图所示:
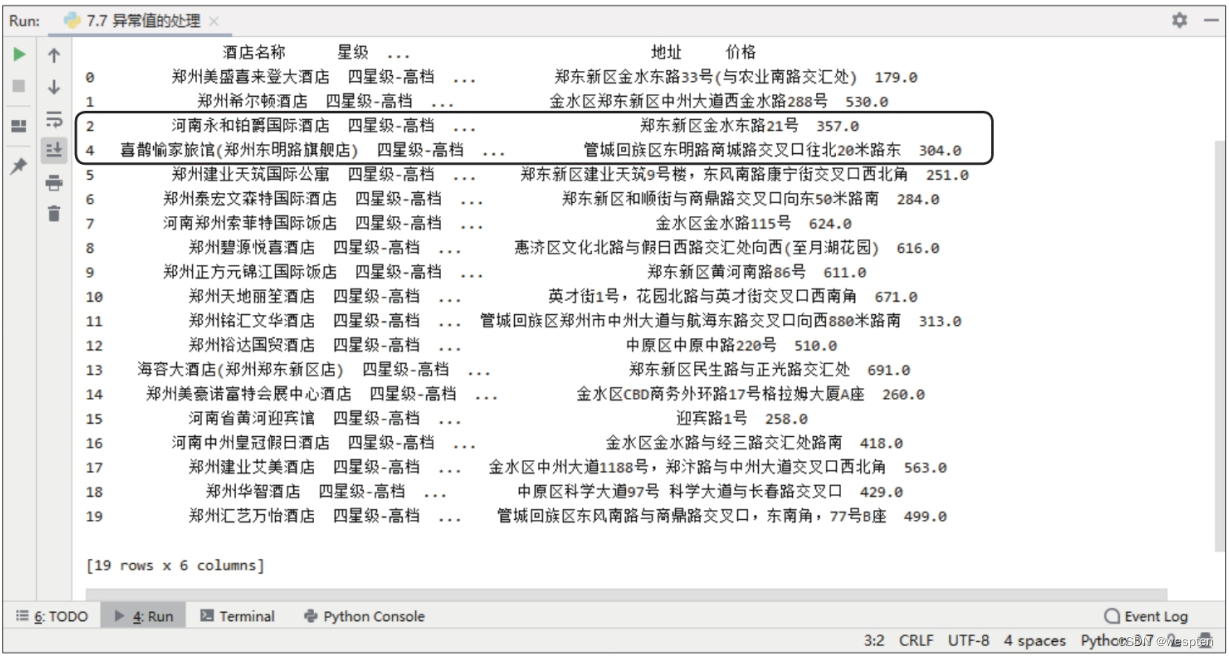
可以看到,行标签为3的行被删除了。
第二种方法是将异常值替换为空值后进行数据插补,将异常值带来的影响降到最低。演示代码如下:
1 data['价格'][data['价格'] > 1000] = None 2 print(data.fillna(data.mean())) # 插补空值第1行代码将异常值替换为空值。第2行代码用mean()函数对各列数据计算平均值,然后将各列中的空值替换为该列的平均值。此外,还可以根据需要使用max()、min()、median()等函数来插补空值。
代码运行结果如下图所示:
2、乱码的处理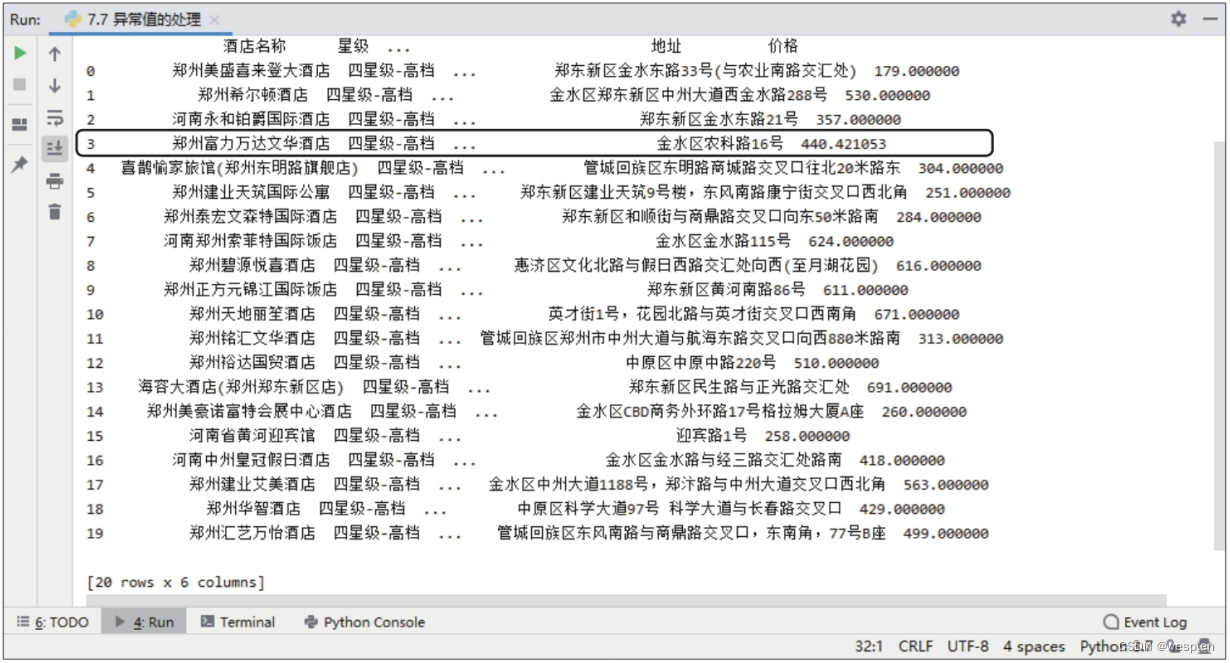
在网络数据传输中,发送方会将数据按照一定的编码格式转换成二进制码,再发送出去,接收方接收到二进制码后再按照对应的编码格式对数据进行解码。用爬虫从网页上采集到的数据如果包含乱码,通常的原因是网页使用的编码格式和我们对数据进行解码时使用的解码方式不一致。
网页编码格式的信息通常放在响应对象的响应头中,使用requests模块的text属性从响应对象中提取网页源代码时,会从响应头中获取content-type字段的值,该值就包含编码格式的信息。例如,获取到content-type字段的值为“text/html; charset=utf-8”,其中的“charset=utf-8”表示此网页的编码格式为UTF-8,text属性就会对响应对象进行UTF-8格式的解码操作,我们看到的数据就不会出现乱码。
但是,有的网页返回的content-type字段的值为“text/html”,没有包含编码格式的信息,此时text属性会默认使用ISO-8859-1格式进行解码操作。如果网页的编码格式并不是ISO-8859-1,解码后就会出现乱码。为了避免这种情况,我们可以使用下面的方法手动获取网页的编码格式。
在谷歌浏览器中使用开发者工具查看某个网页的源代码,编码格式信息一般写在标签中,如下图所示。
由上图可知,该网页的编码格式为GBK,使用get()函数获取到响应对象后,就可以通过对响应对象的encoding属性赋值,为响应对象指定这种编码格式。
演示代码如下:
1 response.encoding = 'gbk'这样无论响应头中是否包含编码格式信息,响应对象的text属性都能正确地解码。
还有一种方法是通过响应对象的apparent_encoding属性获取网页源代码中书写的编码格式信息,这样就不需要通过开发者工具查看标签中的编码格式信息。
演示代码如下:
1 response.encoding = response.apparent_encoding此外,还有一种常见乱码是以“\u”开头的十六进制字符串,需要通过编码转换的方式来解码。演示代码如下:
八、Selenium模块1 str_16_1= "b'\\u4f60\\u597d'" 2 str_16_2 = str_16_1.encode('utf-8').decode('unicode_escape') # 进行编码转换 3 print(str_16_2) # 转换结果是“b'你好'”Selenium模块是一个Web应用程序测试工具。在爬虫的应用中,上一章学习的requests模块能模拟浏览器发送请求,而Selenium模块则能控制浏览器发送请求,并和获取到的网页中的元素进行交互,因此,只要是浏览器发送请求能得到的数据,Selenium模块也能直接得到。
用requests模块爬取网页上动态加载的数据需要携带各种复杂的参数,编写程序时比较麻烦,而用Selenium模块爬取动态加载的数据则要相对简单一些。
1、Selenium模块的安装与基本用法代码文件:Selenium模块的基本用法.py
使用Selenium模块需要先下载和安装浏览器驱动程序,然后在编程时通过Selenium模块实例化一个浏览器对象,再通过浏览器对象访问网页和操作网页元素。下面介绍具体步骤。
1. 查看浏览器的版本号
Selenium模块实际上是通过调用浏览器的驱动程序来访问网页的。因此,在使用“pip install selenium”命令安装Selenium模块之后,还需要下载和安装浏览器的驱动程序。
不同的浏览器有不同的驱动程序,例如,谷歌浏览器的驱动程序叫ChromeDriver,火狐浏览器的驱动程序叫GeckoDriver,等等。并且对于同一种浏览器,还需要安装与其版本号匹配的驱动程序,才能顺利爬取数据。因此,在下载浏览器驱动程序之前,需要先查看浏览器的版本号。
以谷歌浏览器为例,单击其窗口右上角的按钮,在弹出的菜单中执行“帮助>关于Google Chrome”命令,在打开的界面中就可以看到浏览器的版本号,这里显示的主版本号是83。
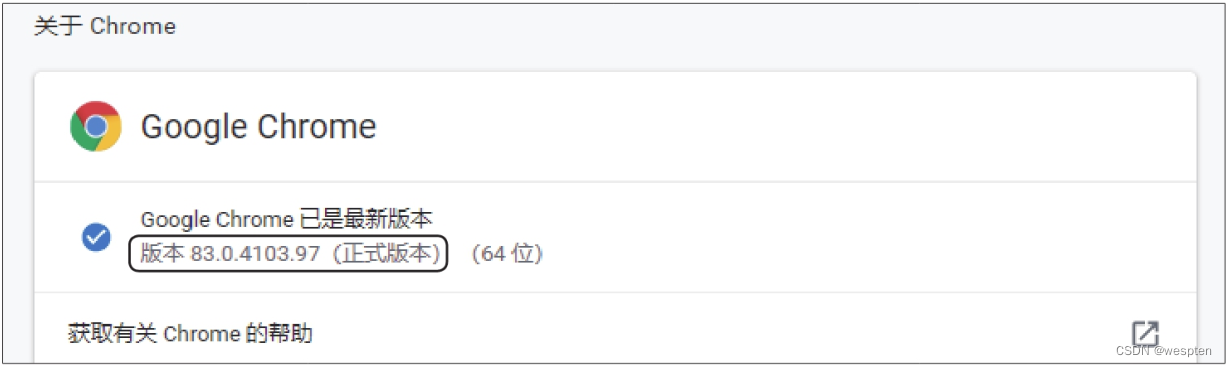
2. 下载和安装浏览器驱动程序
在谷歌浏览器中打开ChromeDriver的官方下载网址:https://chromedriver.storage.googleapis.com/index.html,可看到多个版本号的文件夹链接。单击对应版本号的文件夹链接,如单击“83.0.4103.39”,如下图所示。开头的“83”对应前面查到的浏览器的主版本号。

然后根据当前操作系统选择下载文件。例如,Windows操作系统就单击“chromedriver_win32.zip”,如下图所示。这是一个压缩文件,下载后需要解压,得到一个名为“chromedriver.exe”的可执行文件,它就是浏览器驱动程序。

随后需要将解压后的浏览器驱动程序安装到Python的安装路径中,让Python能够更方便地调用它。按快捷键【Win+R】,调出“运行”对话框,输入“cmd”,按【Enter】键,然后在弹出的命令行窗口中输入“where python”,按【Enter】键,可看到Python的安装路径。
在Windows资源管理器中打开这个安装路径,找到并打开“Scripts”文件夹,将前面解压得到的“chromedriver.exe”文件复制到“Scripts”文件夹中,如下图所示。这样就完成了浏览器驱动程序的下载和安装操作。
3. 使用Selenium模块访问网页
安装好Selenium模块及对应的浏览器驱动程序后,就可以使用Selenium模块访问网页了。演示代码如下:
1 from selenium import webdriver 2 browser = webdriver.Chrome(executable_path='chromedriver.exe') # 实例化谷歌浏览器对象 3 browser.get('https://www.taobao.com')第1行代码导入Selenium模块中的WebDriver功能。第2行代码通过WebDriver的Chrome类实例化一个谷歌浏览器对象(其他浏览器的实例化方法可查阅Selenium模块的官方文档)并命名为browser,通过该对象可以控制浏览器进行各种操作。第3行代码使用browser对象的get()函数控制浏览器发起请求,访问淘宝网首页的网址https://www.taobao.com。
运行代码后,谷歌浏览器会自动打开,并访问淘宝网首页,如下图所示。而且窗口中会显示提示信息,说明谷歌浏览器正受到自动测试软件的控制。

除了访问网页,Selenium模块还可以进行其他操作。
该模块中常用的函数和属性的功能如下表所示:
2、Selenium模块的标签定位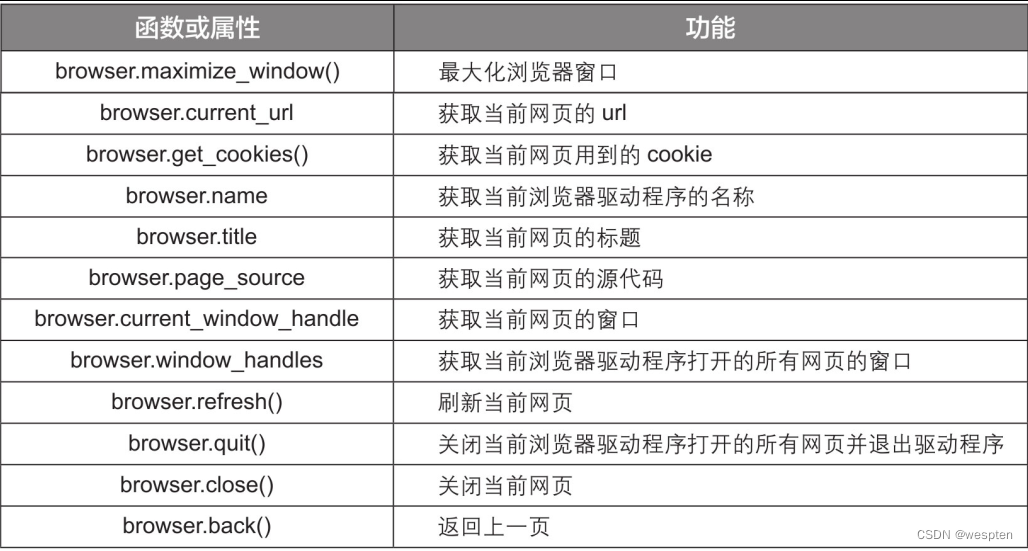
代码文件:Selenium模块的标签定位.py
完成了网页的访问后,如果需要模拟用户操作网页元素,则需要先通过标签来定位网页元素。Selenium模块提供了8种标签定位方式,分别对应8个函数,具体见下表。

需要注意的是,上表中的函数定位的是满足条件的第一个标签,如果要定位满足条件的多个标签,则要将函数名中的“element”改为“elements”。
实例化一个browser对象,并访问了淘宝网首页,下面就以淘宝网首页为例 介绍上述函数的使用方法。
1. find_element_by_id()函数
该函数通过id属性值定位标签,这里以定位淘宝网首页顶部的搜索框为例进行讲解。在淘宝网首页中打开开发者工具,用元素选择工具选中首页顶部的搜索框,可以看到搜索框对应的网页源代码是一个标签,其id属性值为“q”,如下图所示。
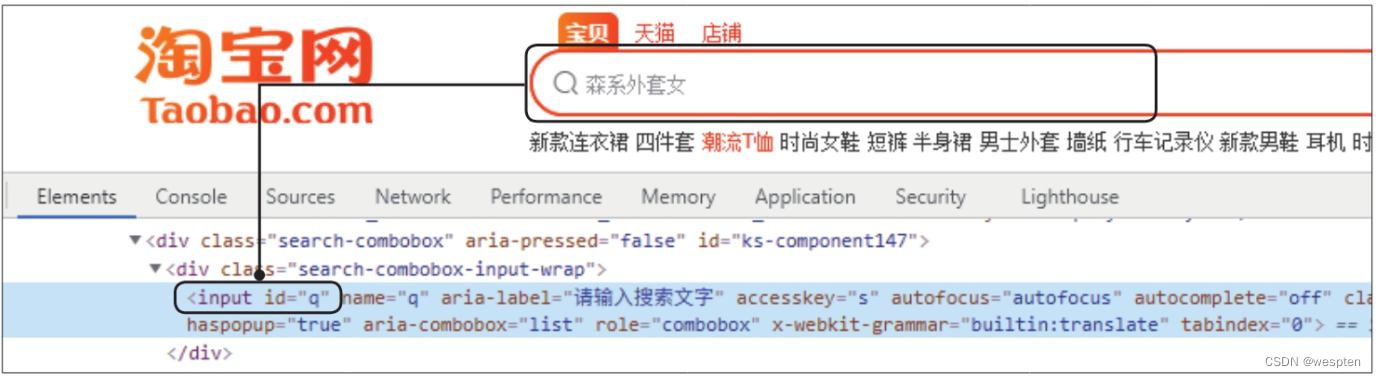
随后就可以通过这个id属性值来定位搜索框了。
演示代码如下:
1 search_input1 = browser.find_element_by_id('q')2. find_element_by_name()函数
该函数通过name属性值定位标签,这里以定位淘宝网首页的“登录”按钮为例进行讲解。在开发者工具中找到“登录”按钮的name属性值为“登录”,如下图所示。
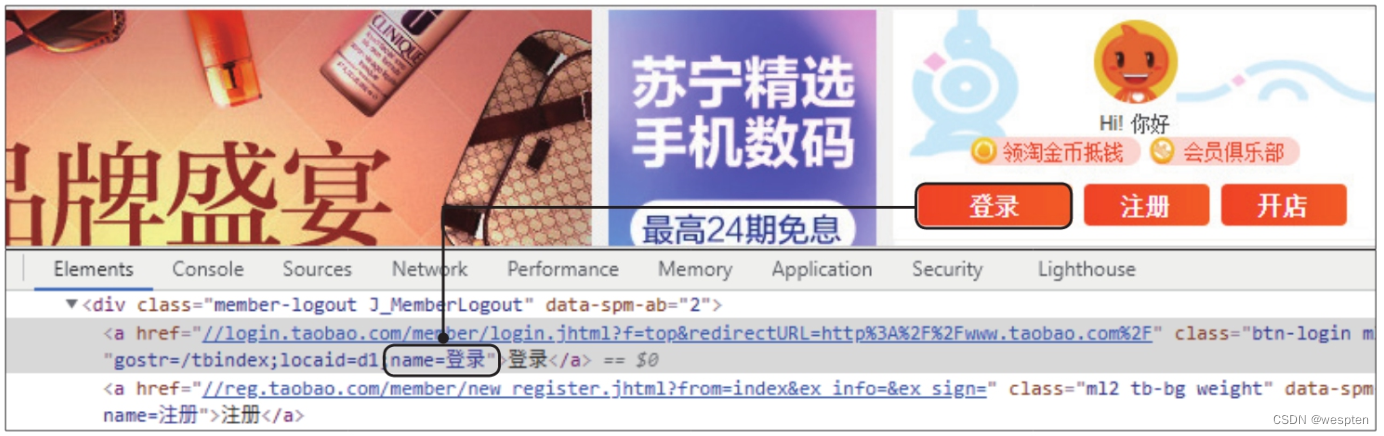
后就可以通过这个name属性值来定位“登录”按钮了。
演示代码如下:
1 login_btn = browser.find_element_by_name('登录')3. find_element_by_class_name()函数
该函数通过class属性值定位标签,这里以定位淘宝网首页的“搜索”按钮为例进行讲解。在开发者工具中找到“搜索”按钮的网页源代码是一个标签,其class属性值有两个,分别为“btn-search”和“tb-bg”,如下图所示。
在class属性的两个值中选择专属于“搜索”按钮的属性值“btn-search”用于定位。
演示代码如下:
1 search_btn = browser.find_element_by_class_name('btn-search')4. find_element_by_tag_name()函数
该函数通过标签名称定位标签。这里以定位标签为例进行讲解。
演示代码如下:
1 search_input2 = browser.find_element_by_tag_name('input')5. find_element_by_link_text()函数
该函数会精确查找与指定关键词完全相同的链接文本,然后返回该链接文本所在的标签。这里以定位淘宝网首页中链接文本等于“女装”的标签为例进行讲解。
演示代码如下:
1 girl_lnk = browser.find_element_by_link_text('女装')6. find_element_by_partial_link_text()函数
该函数会模糊查找包含指定关键词的链接文本,然后返回该链接文本所在的标签。这里以定位淘宝网首页中链接文本包含“保健”的标签为例进行讲解。
演示代码如下:
1 baojian_lnk = browser.find_element_by_partial_link_text('保健')7. find_element_by_css_selector()函数
该函数通过CSS选择器定位标签,定位方式有很多,例如,通过id属性值定位写成'#属性值',通过class属性值定位写成'.属性值'。这里以id属性为例进行讲解。
演示代码如下:
1 search_input3 = browser.find_element_by_css_selector('#q')8. find_element_by_xpath()函数
该函数通过标签的XPath表达式定位标签。这里以顶部搜索框的标签的XPath表达式为例进行讲解。
演示代码如下:
1 search_input4 = browser.find_element_by_xpath('//*[@id="q"]')Selenium模块还在一个名为By的类中封装了上述8种定位方法,使用起来更加清晰明了。
演示代码如下:
3、Selenium模块的标签操作1 from selenium import webdriver 2 from selenium.webdriver.common.by import By 3 browser= webdriver.Chrome(executable_path='chromedriver.exe') # 实例化一个谷歌浏览器对象 4 browser.get('https://www.taobao.com') # 访问淘宝网首页 5 search_input1 = browser.find_element(By.ID, 'q') # 通过id属性值定位标签 6 search_input2 = browser.find_element(By.NAME, 'q') # 通过name属性值定位标签 7 search_btn = browser.find_element(By.CLASS_NAME, 'btn-search') # 通过class属性值定位标签 8 search_input3 = browser.find_element(By.TAG_NAME, 'input') # 通过标签名称定位标签 9 girl_lnk = browser.find_element(By.LINK_TEXT, '女装') # 通过精确查找链接文本来定位标签 10 baojian_lnk = browser.find_element(By.PARTIAL_LINK_TEXT, '保健') # 通过模糊查找链接文本来定位标签 11 search_input4 = browser.find_element(By.CSS_SELECTOR, '#q') # 通过CSS选择器定位标签 12 search_input5 = browser.find_element(By.XPATH, '//*[@id = "q"]') # 通过XPath表达式定位标签代码文件:Selenium模块的标签操作.py
定位到标签后,就可以从标签中获取数据或对标签进行操作,常用的函数或属性如下表所示。
上表中函数或属性的使用方法的演示代码如下:
1 from selenium import webdriver 2 browser= webdriver.Chrome(executable_path='chromedriver.exe') # 实例化一个谷歌浏览器对象 3 browser.get('https://www.taobao.com') # 访问淘宝网首页 4 a_href = browser.find_element_by_xpath('/html/body/div[4]/div[1]/div/div[1]/div/ul/li[1]/a[1]') # 通过XPath表达式定位左侧商品分类栏中的“女装”链接 5 print(a_href.get_attribute('href')) # 获取“女装”链接的href属性值 6 print(a_href.is_selected()) # 查看“女装”链接是否被选中 7 print(a_href.is_displayed()) # 查看“女装”链接是否显示 8 print(a_href.is_enabled()) #查看“女装”链接是否可用 9 print(a_href.text) # 获取“女装”链接的文本 10 print(a_href.tag_name) # 获取“女装”链接的标签名称 11 print(a_href.size) # 获取“女装”链接的大小 12 print(a_href.location) # 获取“女装”链接的位置坐标 13 input_search = browser.find_element_by_xpath('//*[@id = "q"]') # 通过XPath表达式定位搜索框 14 input_search.send_keys('鞋子') # 在搜索框中输入文本“鞋子” 15 search_button = browser.find_element_by_xpath('//*[@id = "J_TSearchForm"]/div[1]/button') # 通过XPath表达式定位搜索框右侧的“搜索”按钮 16 search_button.click() # 单击“搜索”按钮代码运行结果如下:
1 https://www.taobao.com/markets/nvzhuang/taobaonvzhuang 2 False 3 True 4 True 5 女装 6 a 7 {'height': 17, 'width': 28} 8 {'x': 40, 'y': 269}随后会自动打开一个谷歌浏览器窗口,并进入淘宝网首页,在页面顶部的搜索框中自动输入搜索关键词“鞋子”,然后自动执行搜索操作。但是因为淘宝网在未登录时无法使用搜索功能,所以会停留在淘宝账号的登录界面。
4、模拟鼠标操作常用的鼠标操作有单击、双击、右击、长按、拖动、移动等,模拟这些操作需要用到Selenium模块中的ActionChains类。该类的基本使用方法是将实例化好的WebDriver对象作为参数传到该类中,实例化成一个ActionChains对象,然后调用ActionChains对象的函数针对WebDriver对象中的网页元素模拟需要的鼠标操作。调用模拟鼠标操作的函数后,不会立即执行操作,而是将操作存储到一个队列中,当调用perform()函数时,再从队列中依次取出各个操作来执行。
下面分别讲解常用鼠标操作的模拟方法。
1. 模拟鼠标的单击、双击、右击
ActionChains类中的click()函数用于模拟鼠标单击操作。
演示代码如下:
1 from selenium import webdriver 2 from selenium.webdriver import ActionChains 3 browser= webdriver.Chrome(executable_path='chromedriver.exe') # 实例化一个谷歌浏览器对象 4 browser.get('https://www.taobao.com') 5 search_button = browser.find_element_by_xpath('//*[@id = "J_TSearchForm"]/div[1]/button') # 定位到搜索框右侧的“搜索”按钮 6 actions = ActionChains(browser) # 利用WebDriver对象browser实例化一个ActionChains对象,命名为actions 7 actions.click(search_button).perform() # 调用click()函数模拟针对“搜索”按钮的单击操作,再调用perform()函数执行该操作此外,类中的double_click()函数用于模拟鼠标双击操作,context_click()函数则用于模拟鼠标右击操作,这两个函数的使用方法和click()函数一致。
2. 模拟鼠标的长按和松开长按
click_and_hold()函数用于模拟鼠标的长按操作(按下鼠标且不松开),release()函数则用于模拟松开长按的鼠标的操作。
演示代码如下:
1 actions.click_and_hold(search_button).perform() # 长按“搜索”按钮 2 time.sleep(5) # 等待5秒 3 actions.release(search_button).perform() # 松开长按的鼠标,触发单击事件,页面跳转3. 模拟鼠标的拖动
drag_and_drop()函数用于模拟拖动鼠标的操作,drag_and_drop_by_offset()函数则用于模拟用鼠标将目标拖动一定距离的操作(需给出水平方向和垂直方向上的位移值)。在登录界面模拟拖动滑块验证时常用到这两个函数。
4. 模拟鼠标的移动
move_by_offset()函数用于模拟将鼠标移动一定距离的操作(需给出水平方向和垂直方向上的位移值)。move_to_element()函数用于模拟将鼠标移动到指定元素所在位置的操作。
5、标签处理标签用于在一个网页中嵌套另一个网页。嵌套的网页可以作为一个独立的部分实现局部刷新,常用于表单的提交和第三方广告的异步加载等。
以淘宝网为例,在未登录状态下打开一个商品详情页,单击“立即购买”按钮,就会弹出登录表单。打开开发者工具,使用元素选择工具定位登录表单,可以看到登录表单存储在标签中,并且有自己的标签、标签和其他标签,相当于一个嵌套在主页面中的子页面,如下图所示。
对于嵌套在标签中的子页面,不能直接使用普通的标签定位方法来定位标签,而要将这个子页面视为一个新页面,先使用Selenium模块中的switch_to_frame()函数跳转到这个新页面,再进行标签的定位。
演示代码如下:
1 from selenium import webdriver 2 from selenium.webdriver import ActionChains # 导入动作链的类 3 browser = webdriver.Chrome(executable_path='chromedriver.exe') # 实例化一个谷歌浏览器对象 4 browser.implicitly_wait(10) # 设置隐式等待 5 browser.get('https://www.taobao.com') # 访问淘宝网首页 6 shop_a = browser.find_element_by_xpath('/html/body/div[5]/div/div[1]/div/ul/a[1]/div[1]/img') # 定位到“有好货”栏目的商品链接 7 actions = ActionChains(browser) 8 actions.click(shop_a).perform() # 单击定位到的商品链接,打开新页面 9 browser.switch_to_window(browser.window_handles[-1]) # 切换到打开的新页面 10 shop_one = browser.find_element_by_xpath('/html/body/div[2]/div[3]/ul/li[1]/a/img') # 定位第一款商品 11 actions1 = ActionChains(browser) # browser对象中的页面跳转后,需要重新实例化ActionChains对象 12 actions1.click(shop_one).perform() # 单击第一款商品 13 browser.switch_to_window(browser.window_handles[-1]) # 跳转到商品详情页,会弹出登录表单 14 iframe_login = browser.find_element_by_id('sufei-dialog-content') # 定位登录表单所在的标签 15 browser.switch_to_frame(iframe_login) # 切换到标签中的子页面,即登录表单 16 user_input = browser.find_element_by_xpath('//*[@id = "fm-login-id"]') # 定位登录表单中的用户名输入框 17 user_input.send_keys('12344') # 在输入框中输入“12344” 18 browser.quit() # 关闭所有页面,退出浏览器驱动程序第9行和第13行代码中的switch_to_window()函数用于切换到指定窗口中的页面,其参数browser.window_handles[-1]表示获取所有窗口的列表,然后使用列表切片的方式获取最后一个窗口,也就是最新打开的页面。
第15行代码中的switch_to_frame()函数用于切换到标签中的子页面,需要将定位到的标签作为参数传入。
6、显式等待和隐式等待在使用Selenium模块模拟用户操作浏览器时,浏览器会对要加载的网页用到的所有资源发送请求,然而网络阻塞或服务器繁忙等原因会导致各个资源的加载进度不一致,如果在网页尚未完全加载时就进行定位标签等操作,就有可能因为标签不存在而出错。
为了解决这一问题,我们需要为程序设置延时。Python内置的time模块可以实现让程序等待指定的时间,但是这种方法需要在网页可能未加载完毕的地方都设置等待。为了简化代码,建议使用Selenium模块中定义的两种等待方式:显式等待和隐式等待。
下面分别进行讲解。
1. 显式等待
显式等待是指当指定条件成立时再进行下一步操作,如果条件一直不成立就一直等待,直到等待时间达到了设定的超时时间才会报错。
使用显式等待需要使用WebDriverWait类,传入WebDriver对象和超时时间作为参数,配合until()或until_not()函数进行条件设定(可以利用expected_conditions类设定各种条件),根据返回值判断是否报错。
演示代码如下:
1 from selenium import webdriver 2 from selenium.webdriver.common.by import By 3 from selenium.webdriver.support import expected_conditions as EC 4 from selenium.webdriver.support.ui import WebDriverWait 5 browser = webdriver.Chrome(executable_path='chromedriver.exe') 6 browser.get('https://www.taobao.com') # 访问淘宝网首页 7 element = WebDriverWait(driver=browser, timeout=10).until(EC.presence_of_element_located((By.ID,'q'))) # until()函数在等待期间会每隔一段时间就判断元素是否存在,直到返回值不是False,如果超时,则报错 8 element = WebDriverWait(driver=browser, timeout=10).until_not(EC.presence_of_element_located((By.ID,'w'))) # until_not()函数在等待期间会每隔一段时间就判断元素是否存在,直到返回值是False,如果超时,则报错2. 隐式等待
隐式等待是指在实例化浏览器的WebDriver对象时,为该对象设置一个超时时间,在操作该对象时,代码遇到元素未加载完毕或者不存在时,会在规定的超时时间内不断地刷新页面来寻找该元素,直到找到该元素,如果超过超时时间还是找不到该元素,则会报错。这种方法仅适用于元素缺少的情况。
演示代码如下:
7、案例:模拟登录123061 from selenium import webdriver 2 from selenium.webdriver.support.ui import WebDriverWait 3 browser = webdriver.Chrome(executable_path='chromedriver.exe') 4 browser.get('https://www.taobao.com') # 访问淘宝网首页 5 browser.implicitly_wait(10) # 设置隐式等待,超时时间为10秒代码文件:案例:模拟登录12306.py
学习完Selenium模块的基础和进阶操作,通过模拟登录售卖车票的专业网站12306来综合应用所学的知识。
在谷歌浏览器中打开12306网站的登录页面,网址为https://kyfw.12306.cn/otn/resources/login.html。
登录表单中默认显示的登录方式是“扫码登录”,由于Selenium模块无法模拟手机扫描二维码登录的操作,我们需要单击“账号登录”按钮,切换为账号登录方式,接着输入账号和密码,然后完成图片验证,最后单击“立即登录”按钮,如下图所示。

上述一系列操作中,单击按钮及在输入框中输入文字的操作都可以用前面学习的Selenium模块的知识来模拟,难点在于图片验证操作的模拟:我们需要根据图片验证码中的说明文字,在系统随机给出的8张图像中单击正确的图像才能通过验证,然而正确图像的数量和位置也是随机的。
本案例采用的处理思路是:将整个登录页面以屏幕截图的方式保存成图片,再将图片验证码的部分裁剪出来,交由第三方平台进行识别,返回正确图像的坐标,然后由Selenium模块根据坐标模拟单击图像的操作,完成验证。
图片的裁剪等编辑操作使用第三方模块Pillow来完成,其安装命令为“pip install pillow”。图片验证码内容的识别要用到图像识别技术,这里使用第三方平台“超级鹰”来完成。
步骤1:通过Selenium模块访问12306的登录页面,定位并单击“账号登录”按钮,然后分别定位账号和密码输入框,并输入账号和密码。
演示代码如下:
1 from selenium import webdriver 2 from selenium.webdriver import ActionChains 3 from selenium.webdriver.common.by import By 4 from PIL import Image # 导入Pillow模块的图像处理子模块 5 import time # 导入time模块,用于时间处理 6 browser = webdriver.Chrome(executable_path='chromedriver.exe') # 实例化一个谷歌浏览器对象 7 browser.get('https://kyfw.12306.cn/otn/resources/login.html') # 访问12306的登录页面 8 browser.maximize_window() # 将窗口最大化,以便截取未变形和未缩放的登录页面 9 login_user_page = browser.find_element(By.XPATH, '/html/body/div[2]/div[2]/ul/li[2]/a') # 通过XPath表达式定位“账号登录”按钮 10 login_user_page.click() # 单击“账号登录”按钮 11 username_input = browser.find_element(By.ID, 'J-userName') # 通过标签的id属性值定位账号输入框 12 password_input = browser.find_element(By.ID, 'J-password') # 通过标签的id属性值定位密码输入框 13 username_input.send_keys('123456789') # 在账号输入框中输入账号,读者需要将字符串修改为实际使用的账号 14 time.sleep(2) # 为了让模拟操作更像真实的人类用户,在两次输入之间插入时间间隔 15 password_input.send_keys('123456') # 在密码输入框中输入密码,读者需要将字符串修改为实际使用的密码步骤2:截取网页图片并裁剪出图片验证码。如果是静态图片,只需要对静态图片的网址发起请求就能获取图片。但是图片验证码是动态变化的,所以需要先将整个页面截取并保存成图片,再通过标签的location属性(坐标)和size属性(大小)定位图片验证码,最后将图片验证码裁剪出来并保存成图片。
这里创建一个自定义函数get_image()来完成上述操作,演示代码如下:
1 def get_image(browser): # 获取验证码图片 2 browser.save_screenshot('12306.png') # 截取当前页面并保存为图片 3 img_page = Image.open('12306.png') # 打开当前页面的截图 4 img_element = browser.find_element(By.ID, 'J-loginImg') # 通过标签的id属性值定位验证码图片 5 location = img_element.location # 获取验证码图片的坐标 6 size = img_element.size # 获取验证码图片的大小 7 left = location['x'] # 获取验证码图片左上角的x坐标 8 top = location['y'] # 获取验证码图片左上角的y坐标 9 right = left + size['width'] # 获取验证码图片右下角的x坐标 10 bottom = top + size['height'] # 获取验证码图片右下角的y坐标 11 img_code = img_page.crop((left, top, right, bottom)) # 使用crop()函数根据坐标参数裁剪当前页面的截图,得到验证码图片 12 img_code.save('code.png') # 保存验证码图片 13 return步骤3:获取超级鹰的软件ID并购买题分。在浏览器中打开超级鹰官网(https://www.chaojiying.com/),注册并登录账号后,进入“用户中心”,然后切换至“软件ID”界面,单击“生成一个软件ID”链接,生成一个软件ID,如下图所示。
此外,还需要在“用户中心”购买题分,才能使用超级鹰提供的各项服务。
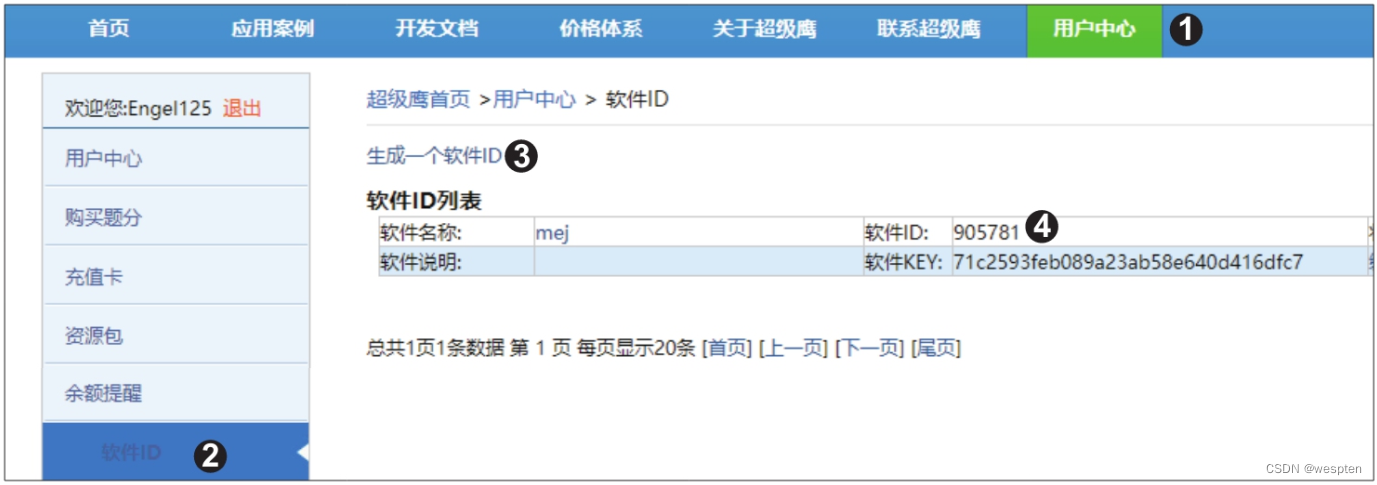
步骤4:下载超级鹰的Python示例代码。返回超级鹰首页,切换至“开发文档”界面,在“常用开发语言示例下载”中单击“Python”,如下图所示。

然后在新的页面中单击“点击这里下载”链接,如下图所示,即可下载示例代码。
步骤5:下载好的示例代码是一个压缩文件,将解压后得到的“chaojiying_Python”文件夹移动到本案例的代码文件所在的文件夹。然后在本案例的代码中导入超级鹰示例代码中定义的Chaojiying_Client类,就能调用类中的函数识别验证码了。
演示代码如下:
1 from chaojiying_Python.chaojiying import Chaojiying_Client步骤6:打开“chaojiying_Python”文件夹下的代码文件“chaojiying.py”,将其中调用Chaojiying_Client类中函数的代码复制、粘贴到本案例的代码文件中,并修改这段代码,自定义一个函数chaojinying()。注意修改函数中的超级鹰账号、密码和软件ID(步骤3中生成的)。
演示代码如下:
1 def chaojinying(ImgPath, ImgType): 2 chaojiying = Chaojiying_Client('12345', '12345', '905781') # 替换为实际的超级鹰账号、密码和软件ID 3 im = open(ImgPath, 'rb').read() # 打开要识别的验证码图片 4 return chaojiying.PostPic(im, ImgType) # 根据设置的验证码类型识别验证码图片并返回结果如果运行过程中提示代码文件“chaojiying.py”中存在错误,请检查该代码文件中的缩进是否有混用空格键和【Tab】键的情况,以及print()函数后是否缺少括号。
步骤7:确定验证码类型。超级鹰支持识别多种图片验证码,为了让超级鹰能够正确完成识别,我们需要确定12306的图片验证码是哪种类型。进入超级鹰官网的“价格体系”页面(https://www.chaojiying.com/price.html),页面中列出了各种验证码的类型代码。前面说过,我们要利用超级鹰返回正确图像的坐标,因此,找到坐标类返回值的类型代码表格,如下图所示。
12306的图片验证码中正确图像的数量不是固定的,符合表格中9004、9005或9008的验证码类型。通过刷新登录页面中的验证码可以发现,正确图像的数量在1~5个之间变化,为了保险起见,本案例使用代码为9005的验证码类型。
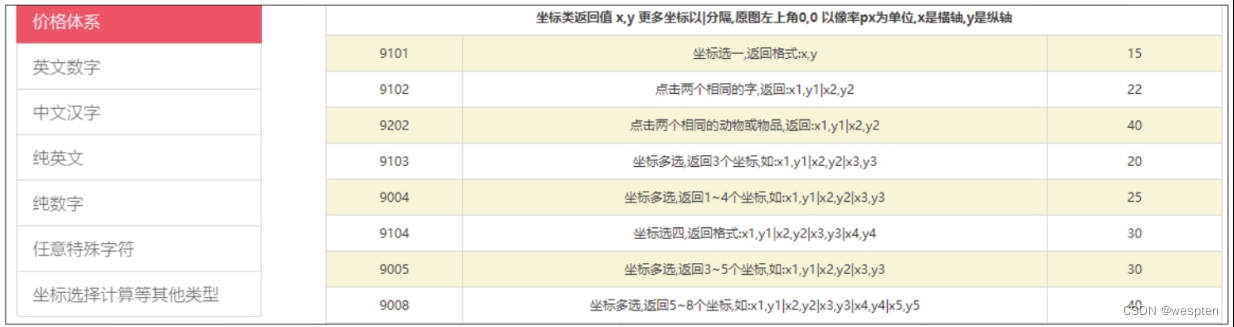
步骤8:获得正确图像的坐标。在本案例的代码中调用截取验证码和调用超级鹰平台识别验证码的函数,也就是步骤2中自定义的get_image()函数和步骤6中自定义的chaojinying()函数,从而获得正确图像的坐标。
演示代码如下:
1 get_image(browser) # 截取验证码图片 2 result = chaojinying('code.png', 9005) # 将验证码图片上传至超级鹰平台并指定验证码类型,获得识别结果 3 print(result) 4 location_code = result['pic_str'] # 从识别结果中提取需要的坐标信息 5 print(location_code) 6 img_element = browser.find_element(By.ID, 'J-loginImg') # 通过标签的id属性值定位验证码图片标签步骤9:对坐标信息进行字符串拆分处理,获取每组坐标的x值和y值,并通过模拟鼠标操作单击每组坐标,完成验证。
演示代码如下:
1 for i in location_code.split('|'): 2 x = i.split(',')[0] # 获取坐标的x值 3 y = i.split(',')[1] # 获取坐标的y值 4 ActionChains(browser).move_to_element_with_offset(img_element, x, y).click().perform()步骤10:最后定位并单击“立即登录”按钮,完成模拟登录。演示代码如下:
九、PhantomJS模块 1、PhantomJS简介1 login_button = browser.find_element(By.ID, 'J-login') 2 login_button.click()如果页面是JS渲染的该怎么办呢?如果我们单纯去分析一个个后台的请求,手动去摸索JS渲染的到的一些结果,那简直没天理了。所以,我们需要有一些好用的工具来帮助我们像浏览器一样渲染JS处理的页面。
其中有一个比较常用的工具,那就是PhantomJS。
PhantomJS是一个无界面的,可脚本编程的WebKit浏览器引擎。它原生支持多种web 标准:DOM 操作,CSS选择器,JSON,Canvas 以及SVG。因此可以比浏览器更加快速的解析处理js加载。
2、PhantomJS安装首先下载PhantomJS。(点击进入下载链接)
下载后解压,将文件夹bin下的phantomjs.exe放在python安装目录的Script文件夹C:\Python27\Scripts下。起始这里是为了把phantomjs.exe的路径添加到环境变量,而python安装目录的Script文件夹路径,已经添加到了环境变量中,所以这里也就省略了。
在cmd中输入:
phantomjs -v如果正常显示版本号,那么证明安装成功了。如果提示错误,那么检查python的环境变量是否设置。
3、PhantomJS使用1. 第一个程序
第一个程序当然是Hello World,新建一个 js 文件。命名为 helloworld.js:
console.log('Hello, world!'); phantom.exit();打开cmd,先cd到js文件夹所在的目录,再调用如下语句实现phantom运行js文件。
如我的js文件存储在D:\FFF文件夹下,依次执行下面的命令:
d: cd \FFF phantomjs helloworld.js程序输出了 Hello,world!程序第二句话终止了 phantom 的执行。
注意:**phantom.exit();**这句话非常重要,否则程序将永远不会终止。
2. 页面加载
可以利用 phantom 来实现页面的加载,下面的例子实现了页面的加载并将页面保存为一张图片。
将以下命令存储为pageload.js保存在你的文件夹中:
var page = require('webpage').create(); page.open('http://blog.csdn.net/luanpeng825485697', function (status) { console.log("Status: " + status); if (status === "success") { page.render('example.png'); } phantom.exit(); });首先创建了一个webpage对象,然后加载本站点主页,判断响应状态,如果成功,那么保存截图为 example.png。
打开cmd,先cd到js文件夹所在的目录,再调用如下语句实现phantom运行js文件。
phantomjs pageload.js3. 测试页面加载速度
下面这个例子计算了一个页面的加载速度,同时还用到了命令行传参的特性。新建文件保存为 loadspeed.js。
var page = require('webpage').create(), system = require('system'), t, address; if (system.args.length === 1) { console.log('Usage: loadspeed.js '); phantom.exit(); } t = Date.now(); address = system.args[1]; page.open(address, function(status) { if (status !== 'success') { console.log('FAIL to load the address'); } else { t = Date.now() - t; console.log('Loading ' + system.args[1]); console.log('Loading time ' + t + ' msec'); } phantom.exit(); });程序判断了参数的多少,如果参数不够,那么终止运行。然后记录了打开页面的时间,请求页面之后,再纪录当前时间,二者之差就是页面加载速度。
phantomjs loadspeed.js http://blog.csdn.net/luanpeng825485697运行结果:
Loading http://blog.csdn.net/luanpeng825485697 Loading time 8576 msec这个时间包括JS渲染的时间,当然和网速也有关。
4. 代码评估
利用 evaluate 方法我们可以获取网页的源代码。这个执行是“沙盒式”的,它不会去执行网页外的 JavaScript 代码。evalute 方法可以返回一个对象,然而返回值仅限于对象,不能包含函数(或闭包)。
var url = 'http://www.baidu.com'; var page = require('webpage').create(); page.open(url, function(status) { var title = page.evaluate(function() { return document.title; }); console.log('Page title is ' + title); phantom.exit(); });以上代码获取了百度的网站标题。
5. 屏幕捕获
因为 PhantomJS 使用了 WebKit内核,是一个真正的布局和渲染引擎,它可以像屏幕截图一样捕获一个web界面。因为它可以渲染网页中的人和元素,所以它不仅用到HTML,CSS的内容转化,还用在SVG,Canvas。可见其功能是相当强大的。
除了 png 格式的转换,PhantomJS还支持 jpg,gif,pdf等格式。
前面有使用介绍,这里就不介绍了。
其中最重要的方法便是 viewportSize 和 clipRect 属性。
viewportSize 是视区的大小,你可以理解为你打开了一个浏览器,然后把浏览器窗口拖到了多大。
clipRect 是裁切矩形的大小,需要四个参数,前两个是基准点,后两个参数是宽高。
var page = require('webpage').create(); page.viewportSize = { width: 1024, height: 768 }; page.clipRect = { top: 0, left: 0, width: 1024, height: 500 }; page.open('http://blog.csdn.net/luanpeng825485697', function() { page.render('csdn.png'); phantom.exit(); });就相当于把浏览器窗口拖到了 1024×768 大小,然后从左上角裁切出了 1024×500 的页面。
6. 网络监听
因为 PhantomJS 有网络通信的检查功能,它也很适合用来做网络行为的分析。
当接受到请求时,可以通过改写onResourceRequested和onResourceReceived回调函数来实现(接收到资源请求)和(资源接收完毕)的监听。例如:
var url = 'http://www.525heart.com'; var page = require('webpage').create(); page.onResourceRequested = function(request) { console.log('Request ' + JSON.stringify(request, undefined, 4)); }; page.onResourceReceived = function(response) { console.log('Receive ' + JSON.stringify(response, undefined, 4)); }; page.open(url);运行结果会打印出所有资源的请求和接收状态,以JSON格式输出。
4、页面自动化处理因为 PhantomJS 可以加载和操作一个web页面,所以用来自动化处理也是非常适合的。
1. DOM操作
脚本都是像在浏览器中运行的,所以标准的 JavaScript 的 DOM 操作和 CSS 选择器也是生效的。
例如下面的例子就修改了 User-Agent,然后还返回了页面中某元素的内容:
var page = require('webpage').create(); console.log('The default user agent is ' + page.settings.userAgent); page.settings.userAgent = 'SpecialAgent'; page.open('http://blog.csdn.net/luanpeng825485697', function(status) { if (status !== 'success') { console.log('Unable to access network'); } else { var ua = page.evaluate(function() { return document.getElementById('blog_title').textContent; }); console.log(ua); } phantom.exit(); });运行结果首先打印出了默认的 User-Agent,然后通过修改它,请求验证 User-Agent 的一个站点,通过选择器得到了修改后的 User-Agent。
2. 使用附加库
在1.6版本之后允许添加外部的JS库,比如下面的例子添加了jQuery,然后执行了jQuery代码。
var page = require('webpage').create(); page.open('http://blog.csdn.net/luanpeng825485697', function() { page.includeJs("http://ajax.googleapis.com/ajax/libs/jquery/1.6.1/jquery.min.js", function() { page.evaluate(function() { $("button").click(); }); phantom.exit() }); });引用了 jQuery 之后,我们便可以在下面写一些 jQuery 代码了。
3. 页面事件案例
// The purpose of this is to show how and when events fire, considering 5 steps // happening as follows: // // 1. Load URL // 2. Load same URL, but adding an internal FRAGMENT to it // 3. Click on an internal Link, that points to another internal FRAGMENT // 4. Click on an external Link, that will send the page somewhere else // 5. Close page // // Take particular care when going through the output, to understand when // things happen (and in which order). Particularly, notice what DOESN'T // happen during step 3. // // If invoked with "-v" it will print out the Page Resources as they are // Requested and Received. // // NOTE.1: The "onConsoleMessage/onAlert/onPrompt/onConfirm" events are // registered but not used here. This is left for you to have fun with. // NOTE.2: This script is not here to teach you ANY JavaScript. It's aweful! // NOTE.3: Main audience for this are people new to PhantomJS. "use strict"; var sys = require("system"), page = require("webpage").create(), logResources = false, step1url = "http://en.wikipedia.org/wiki/DOM_events", step2url = "http://en.wikipedia.org/wiki/DOM_events#Event_flow"; if (sys.args.length > 1 && sys.args[1] === "-v") { logResources = true; } function printArgs() { var i, ilen; for (i = 0, ilen = arguments.length; i < ilen; ++i) { console.log(" arguments[" + i + "] = " + JSON.stringify(arguments[i])); } console.log(""); } page.onInitialized = function() { console.log("page.onInitialized"); printArgs.apply(this, arguments); }; page.onLoadStarted = function() { console.log("page.onLoadStarted"); printArgs.apply(this, arguments); }; page.onLoadFinished = function() { console.log("page.onLoadFinished"); printArgs.apply(this, arguments); }; page.onUrlChanged = function() { console.log("page.onUrlChanged"); printArgs.apply(this, arguments); }; page.onNavigationRequested = function() { console.log("page.onNavigationRequested"); printArgs.apply(this, arguments); }; page.onRepaintRequested = function() { console.log("page.onRepaintRequested"); printArgs.apply(this, arguments); }; if (logResources === true) { page.onResourceRequested = function() { console.log("page.onResourceRequested"); printArgs.apply(this, arguments); }; page.onResourceReceived = function() { console.log("page.onResourceReceived"); printArgs.apply(this, arguments); }; } page.onClosing = function() { console.log("page.onClosing"); printArgs.apply(this, arguments); }; // window.console.log(msg); page.onConsoleMessage = function() { console.log("page.onConsoleMessage"); printArgs.apply(this, arguments); }; // window.alert(msg); page.onAlert = function() { console.log("page.onAlert"); printArgs.apply(this, arguments); }; // var confirmed = window.confirm(msg); page.onConfirm = function() { console.log("page.onConfirm"); printArgs.apply(this, arguments); }; // var user_value = window.prompt(msg, default_value); page.onPrompt = function() { console.log("page.onPrompt"); printArgs.apply(this, arguments); }; setTimeout(function() { console.log(""); console.log("### STEP 1: Load '" + step1url + "'"); page.open(step1url); }, 0); setTimeout(function() { console.log(""); console.log("### STEP 2: Load '" + step2url + "' (load same URL plus FRAGMENT)"); page.open(step2url); }, 5000); setTimeout(function() { console.log(""); console.log("### STEP 3: Click on page internal link (aka FRAGMENT)"); page.evaluate(function() { var ev = document.createEvent("MouseEvents"); ev.initEvent("click", true, true); document.querySelector("a[href='#Event_object']").dispatchEvent(ev); }); }, 10000); setTimeout(function() { console.log(""); console.log("### STEP 4: Click on page external link"); page.evaluate(function() { var ev = document.createEvent("MouseEvents"); ev.initEvent("click", true, true); document.querySelector("a[title='JavaScript']").dispatchEvent(ev); }); }, 15000); setTimeout(function() { console.log(""); console.log("### STEP 5: Close page and shutdown (with a delay)"); page.close(); setTimeout(function(){ phantom.exit(); }, 100); }, 20000);详情参考:
Page Automation with PhantomJS
Example Scripts for PhantomJS
5、PhantomJS +Selenium应用安装PhantomJS。
安装selenium,在cmd中输入pip install selenium即可实现在线安装。
或者离线下载(点击下载),再安装(安装教程)
首先我们将PhantomJS.exe存储在代码文件当前目录下,以便我们调用。
python3.6下:
# -*- coding:utf-8 -*- #python+selenium+PhantomJS 无视图的浏览器处理。高效处理模拟js功能 from selenium import webdriver from selenium.webdriver.common.keys import Keys from selenium.webdriver.support.ui import Select from selenium.webdriver.common.by import By from selenium.webdriver.support.ui import WebDriverWait from selenium.webdriver.support import expected_conditions as EC import time driver = webdriver.PhantomJS(executable_path='C:\Python27\Scripts\phantomjs.exe') #使用PhantomJS这个浏览器来作为js处理器 driver.get("http://pythonscraping.com/pages/javascript/ajaxDemo.html") #请求指定网址。所以的js反应会自动修改driver,所以不同时间访问driver会有不同的效果 #隐式等待(等待特定的时间) time.sleep(3) #等待页面中的初始化js函数和初始化ajax函数完成。如果这里时间短,则下面的driver内容会不一样。 # driver.implicitly_wait(3) # seconds #显示等待,等待指定条件结束 driver.get("http://somedomain/url_that_delays_loading") try: element = WebDriverWait(driver, 10).until( #10为超时时间 EC.presence_of_element_located((By.ID, "myDynamicElement")) #程序默认会 500ms 调用一次来查看元素是否已经生成,如果本来元素就是存在的,那么会立即返回。 #以下是内置的等待条件 # title_is # title_contains # presence_of_element_located # visibility_of_element_located # visibility_of # presence_of_all_elements_located # text_to_be_present_in_element # text_to_be_present_in_element_value # frame_to_be_available_and_switch_to_it # invisibility_of_element_located # element_to_be_clickable – it is Displayed and Enabled. # staleness_of # element_to_be_selected # element_located_to_be_selected # element_selection_state_to_be # element_located_selection_state_to_be # alert_is_present ) finally: driver.quit() html = driver.page_source #获取页面执行后的网页源代码(初始化js和初始化ajax执行结束后的源代码,即谷歌中审查元素的网页源代码) print(html) #获取元素、元素列表 element = driver.find_element_by_css_selector('#content') #根据css选择器获取元素 element = driver.find_element_by_tag_name("div") #根据标签名称获取元素 element = driver.find_element_by_name("passwd") #根据名称选择 element = driver.find_element_by_xpath("//input[@id='passwd-id']") #根据路径表达式选择 element = driver.find_element_by_class_name('class1') #根据样式类选择元素 element = driver.find_element_by_id('content') #根据id获取元素 elements = driver.find_elements_by_css_selector("div") #find_elements获取元素列表 #通过by类来实现选择 driver.find_element(By.XPATH, '//button[text()="Some text"]') driver.find_elements(By.XPATH, '//button') # ID = "id" # XPATH = "xpath" # LINK_TEXT = "link text" # PARTIAL_LINK_TEXT = "partial link text" # NAME = "name" # TAG_NAME = "tag name" # CLASS_NAME = "class name" # CSS_SELECTOR = "css selector" #selsect选择元素 select = Select(driver.find_element_by_name('name')) #根据查找到的select元素,构建Select对象 select.select_by_index(1) #根据索引来选择 select.select_by_visible_text("text") #根据值来选择 select.select_by_value("value1") #根据文字来选择 select.deselect_all() #全部取消选择 all_selected_options = select.all_selected_options #获取所有的已选选项 options = select.options #获取所有可选选项 #元素属性 element.get_attribute("value") #元素属性 element.text #元素文本 #模拟操作 element.send_keys("some text") #追加填入文本 element.send_keys("and some", Keys.ARROW_DOWN) #点击按键 element.clear() #清除文本 element.click() #模拟点击 element.submit() #提交元素提交 #元素拖拽 element = driver.find_element_by_name("source") target = driver.find_element_by_name("target") from selenium.webdriver import ActionChains action_chains = ActionChains(driver) action_chains.drag_and_drop(element, target).perform() # 页面切换 driver.switch_to.window("windowName") #切换到指定名称的窗口 for handle in driver.window_handles: #遍历窗口对象 driver.switch_to.window(handle) #切换到窗口对象 driver.switch_to.frame("frameName.0.child") #切换到指定名称的fragme,焦点会切换到一个 name 为 child 的 frame 上 # 弹窗处理 alert = driver.switch_to.alert() #获取弹窗对象 # 历史记录 driver.forward() #页面前进 driver.back() #页面后退 # Cookies处理 cookie = {'name' : 'foo', 'value' : 'bar'} #使用字典定义cookie的值 driver.add_cookie(cookie) #设置cookie driver.get_cookies() #读取cookie driver.close()查找当前节点子节点方法:
find_element_by_id 在当前节点查找指定id的子节点 find_elements_by_id 在当前节点查找指定id的子节点集 find_element_by_name 在当前节点查找指定name的子节点 find_elements_by_name 在当前节点查找指定name的子节点集 find_element_by_link_text 在当前节点查找指定链接文本的子节点 find_elements_by_link_text 在当前节点查找指定链接文本的子节点集 find_element_by_partial_link_text 在当前节点查找指定链接部分文本的子节点 find_elements_by_partial_link_text 在当前节点查找指定链接部分文的子节点集 find_element_by_tag_name 在当前节点查找指定html tag的子节点 find_elements_by_tag_name 在当前节点查找指定html tag的子节点集 find_element_by_xpath 在当前节点查找指定xpath的子节点 find_elements_by_xpath 在当前节点查找指定xpath的子节点集 find_element_by_class_name 在当前节点查找指定class name的子节点 find_elements_by_class_name 在当前节点查找指定class name的子节点集 find_element_by_css_selector 在当前节点查找指定css选择器的子节点 find_elements_by_css_selector 在当前节点查找指定css选择器的子节点集当前元素操作:
十、反爬虫机制tag_name 获取当前元素的tag name属性 text 获取当前元素的text内容 get_property 获取当前元素指定属性值 get_attribute 获取当前元素指定属性值,注意请看源码,该方法与get_property的区别 is_selected 判断元素的选择状态(针对radio button和checkbox) is_enabled 判断元素是否可用 send_keys 键盘输入(主要针对text、或text area 可接受键盘输入的元素) is_displayed 判断元素是否可见通过前面的学习,可能有人会认为用爬虫程序获取数据很简单,但是在实战中并非如此。爬虫会给网站服务器带来很大的负担,影响网站的正常运营,因此,网站的拥有者或运营者会采取一些技术手段来限制爬取的信息内容或数据的量,这些技术手段称为“反爬”,当然相应地也有许多“反反爬”策略。
1、IP反爬的应对思路IP地址是标识一台计算机的网络地址。在网络上,计算机对服务器发起请求,服务器会得到各种信息,其中就包括计算机的IP地址。为了保证网站的正常运营,很多网站会采取IP反爬措施,即限制同一IP地址的请求频率。当服务器发现同一IP地址在短时间内对服务器发起了大量请求,就会判定这些请求都是爬虫程序发起的,并将该IP地址加入黑名单。在该IP地址再次向服务器发起请求时,服务器会先判断该IP地址是否在黑名单中,如果在黑名单中就拒绝请求,这样爬虫程序就爬取不到数据了。
IP反爬是针对IP地址进行判定的,如果多次发起请求时不使用同一个IP地址,就能在一定程度上规避IP反爬,那么怎么实现呢?很简单,只需要使用代理服务器帮我们向网站服务器发起请求,这样网站服务器检测到的IP地址就是代理IP的地址。我们可以将多个代理IP地址集中在一起,创建一个代理IP池,每次发起请求时在代理IP池中随机取出一个代理IP地址来使用,就能降低请求被拒绝的概率。
1. 设定程序休止时间
1 import time 2 3 time.sleep(n)2. 设定代理
代理服务器的存在,可以应对网站禁止某个 IP 访问的反爬虫措施。代理服务器有着不同的匿名类型,通常我们会挑选中、高级别的代理服务器来访问网页。

示例:
1 # 使用urllib.request的两个方法进行代理的设置 2 proxy = urlrequest.ProxyHandler({'https': '47.91.78.201:3128'}) 3 opener = urlrequest.build_opener(proxy)3. 设定 User-Agent
网站是可以识别你是否在使用脚本进行爬取,因此需要在你发送网络请求时,把 header 部分伪装成浏览器。
方式1:使用python下非常好用的伪装请求头的库 fake-useragent
安装:
pip install fake-useragent使用示例:
from fake_useragent import UserAgent ua = UserAgent() # 获取各浏览器的fake-useragent # ie浏览器的user agent print(ua.ie) # chrome浏览器 print(ua.chrome) # safri浏览器 print(ua.safari) # 最常用的方式 # 写爬虫最实用的是可以随意变换headers,一定要有随机性。支持随机生成请求头 print(ua.random) # 请求头 headers={"User-Agent":ua.random}方式2:手工设置
2、搭建代理IP池import random def get_headers(): useragent_list = [ 'Mozilla/5.0 (Windows NT 6.1; rv,2.0.1) Gecko/20100101 Firefox/4.0.1', 'Opera/9.80 (Macintosh; Intel Mac OS X 10.6.8; U; en) Presto/2.8.131 Version/11.11', 'Mozilla/5.0 (Windows; U; Windows NT 6.1; en-us) AppleWebKit/534.50 (KHTML, like Gecko) Version/5.1 Safari/534.50', 'Mozilla/5.0 (Windows NT 6.1; rv,2.0.1) Gecko/20100101 Firefox/4.0.1', 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/51.0.2704.106 Safari/537.36', 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Maxthon/4.9.2.1000 Chrome/39.0.2146.0 Safari/537.36', 'Mozilla/5.0 (X11; CrOS i686 2268.111.0) AppleWebKit/536.11 (KHTML, like Gecko) Chrome/20.0.1132.57 Safari/536.11', 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1063.0 Safari/536.3', 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_8_0) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1063.0 Safari/536.3', 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_8_0) AppleWebKit/532.3 (KHTML, like Gecko) Chrome/19.0.1063.0 Safari/532.3', 'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/536.5 (KHTML, like Gecko) Chrome/19.0.1084.9 Safari/536.5', 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.81 Safari/537.36' ] useragent = random.choice(useragent_list) header = {'User-Agent': useragent} return header代码文件:搭建代理IP池.py
国内有很多的代理服务器提供商,在其官网注册账号后购买服务,就可获得其提供的代理服务器的IP地址、端口和代理请求类型。下面以流冠代理为例来讲解如何获取代理IP地址并搭建代理IP池。
步骤1:在浏览器中打开代理官网,网址为https://www.hailiangip.com/,注册账号并完成实名认证。切换至“购买IP代理”页面并充值,然后单击“选择提取API”按钮,在该页面中选择产品类型、订单号、省份城市、提取数量等参数,如下图所示。
步骤2:单击“生成API链接”按钮,系统会根据选择的参数生成不同的链接,随后可看到生成的API链接,单击“复制API链接”按钮,如下图所示。
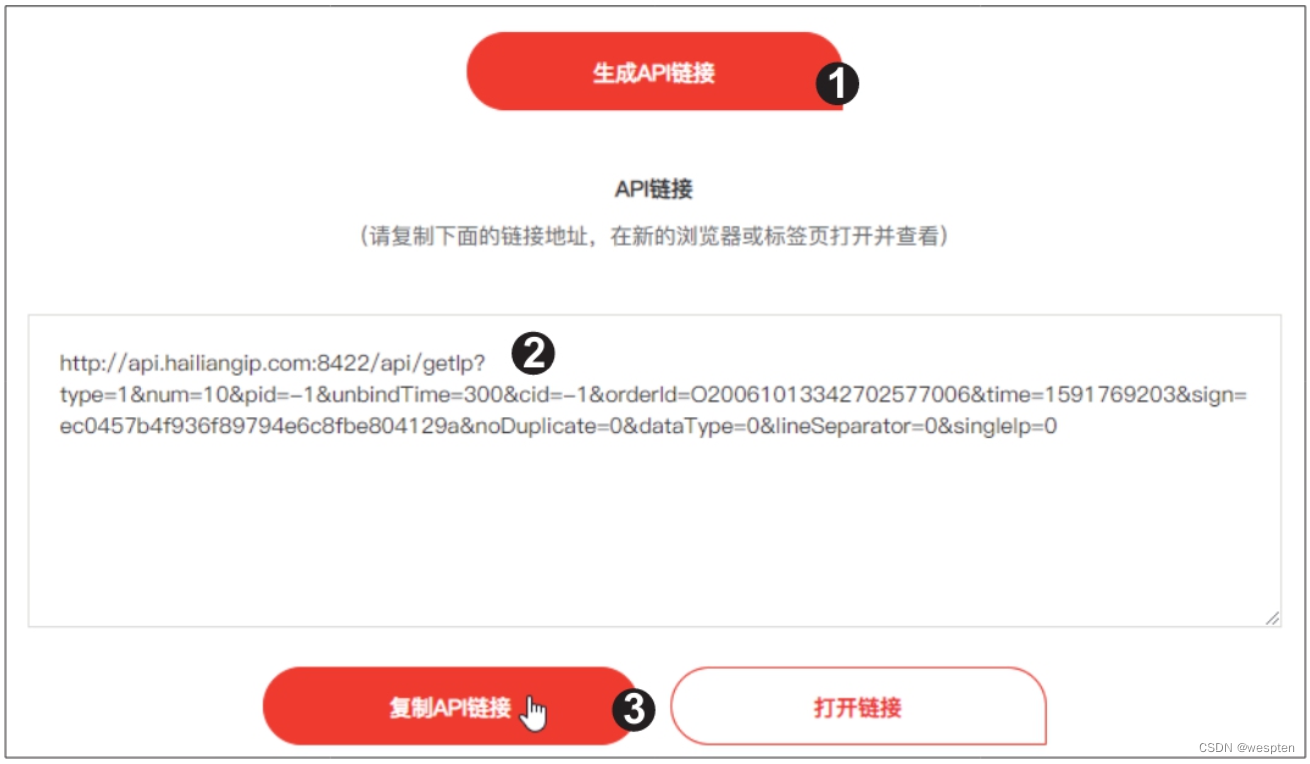
步骤3:对生成的API链接发起请求,获取JSON格式的代理IP地址数据。
演示代码如下:
1 import requests 2 import random # 导入random模块,用于随机选取代理IP地址 3 url = 'http://api.hailiangip.com:8422/api/getIp?type=1&num=10&pid=-1&unbindTime=300&cid=-1&orderId=O20061013342702577006&time=1591769203&sign=ec0457b4f936f89794e6c8fbe804129a&noDuplicate=0&dataType=0&lineSeparator=0&singleIp=0' # 前面生成的API链接 4 headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.75 Safari/ 537.36'} 5 response = requests.get(url=url, headers=headers).json() # 对API链接发起请求并获取JSON格式数据步骤4:提取JSON格式数据中的IP地址和端口。流冠代理的代理请求类型都是https的,将JSON格式数据中的IP地址、端口和https类型以拼接字符串的方式处理成{'https': 'IP地址:端口'}的字典格式,以满足requests模块中get()函数的参数proxies的格式要求。
演示代码如下:
1 proxies_list = [] # 定义一个空列表作为代理IP池,用于存放代理IP地址 2 for i in response['data']: 3 ip = i['ip'] # 提取每一个IP地址 4 port = i['port'] # 提取每一个IP地址对应的端口 5 ip_dict = {'https': f'{ip}:{port}'} # 通过拼接字符串完成参数的格式化 6 proxies_list.append(ip_dict) # 将格式化的参数添加到代理IP池步骤5:在代码中使用代理IP池。使用random模块从代理IP池中随机取出一个代理IP地址,可以在get()函数中作为参数proxies的值使用。
演示代码如下:
3、反爬虫案例1 proxies = random.choice(proxies_list)步骤6:为方便使用代理IP池,将上面的代码封装成一个自定义函数。为该函数传入API链接作为参数,函数就能返回一个代理IP地址。演示代码如下: 1 def ip_pond(url): 2 headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.75 Safari/537.36'} 3 response = requests.get(url=url, headers=headers).json() 4 proxies_list = [] 5 for i in response['data']: 6 ip = i['ip'] 7 port = i['port'] 8 ip_dict = {'https': f'{ip}:{port}'} 9 proxies_list.append(ip_dict) 10 proxies = random.choice(proxies_list) 11 return proxies一个提供免费代理IP地址的网站,网址为https://www.kuaidaili.com/free/。这个网站为了正常运营,采用了IP反爬措施。本案例要利用从流冠获取的代理IP地址访问快代理,爬取网站上的数据。
先不使用代理IP地址,向快代理的页面循环发起请求。
演示代码如下:
1 import requests 2 headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.75 Safari/537.36'} 3 for i in range(1, 100): # 对快代理的前100页发起请求 4 url = f'https://www.kuaidaili.com/free/inha/{i}/' 5 response = requests.get(url=url, headers=headers) # 对拼接的网址发起请求,不使用代理IP地址 6 print(response) # 查看响应对象代码运行结果如右图所示,可发现一段时间后出现了状态码为503的响应对象。以5开头的状态码代表服务器错误,而503大多是没有正确请求到资源或者服务器拒绝请求时返回的状态码,说明我们的IP地址被网站限制访问了。
这时在浏览器中访问快代理的网址https://www.kuaidaili.com/free/,会显示如下图所示的错误页面。
下面使用从流冠代理获取的代理IP地址发起请求,演示代码如下:
1 import requests 2 import random 3 api = 'http://api.hailiangip.com:8422/api/getIp?type=1&num=10&pid=-1&unbindTime=300&cid=-1&orderId=O20061013342702577006&time=1591769203&sign=ec0457b4f936f89794e6c8fbe804129a&noDuplicate=0&dataType=0&lineSeparator=0&singleIp=0' 4 def ip_pond(url): # 从代理IP池中获取IP 5 headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.75 Safari/537.36'} 6 response = requests.get(url=url, headers=headers).json() 7 proxies_list = [] 8 for i in response['data']: 9 ip = i['ip'] 10 port = i['port'] 11 ip_dict = {'https': f'{ip}:{port}'} 12 proxies_list.append(ip_dict) 13 proxies = random.choice(proxies_list) 14 return proxies 15 headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.75 Safari/537.36'} 16 for i in range(1, 100): 17 url = f'https://www.kuaidaili.com/free/inha/{i}/' 18 proxies = ip_pond(api) 19 response = requests.get(url=url, headers=headers, proxies=proxies) # 使用代理IP地址发起请求 20 print(response) # 查看响应对象运行代码后,返回的响应对象变为,表示请求已成功。
需要注意的是,由于网络原因或者代理IP服务到期,可能会遇到连接代理IP失败且超过最大重试次数的问题,此时解决方法有两个:一是使用try语句提升程序的健壮性;二是购买更好的代理IP服务。
4、让爬虫更像人类在互联网上进行自动数据采集(抓取)这件事和互联网存在的时间差不多一样长。今天大众好像更倾向于用“网络数据采集”,有时会把网络数据采集程序称为网络机器人(bots)。最常用的方法是写一个自动化程序向网络服务器请求数据(通常是用 HTML 表单或其他网页文件),然后对数据进行解析,提取需要的信息。
说句实在话,如果我的网站总是让人爬来爬取的,经常被虚拟访问者骚扰,我也是蛮烦的,而且如果遇到“霸道”一点的爬虫,都能直接把服务器卡死。因此,我们在爬取别人网站的时候,也多为对方考虑考虑。
网站防采集的前提就是要正确地区分人类访问用户和网络机器人。现在网站有很多技术来防止爬虫,比如验证码,对于一些简单的数字验证码,可以使用训练好的caffemodel诸如此类的模型去识别,准确率还是可以的。
当然,也可以在Github搜一搜关于验证码识别的东西,看一看大牛们是怎么玩的。除了这些高大上的,还有一些十分简单的方法可以让你的网络机器人看起来更像人类访问用户。
1. 构造合理的HTTP请求头
除了处理网站表单,requests 模块还是一个设置请求头的利器。HTTP 的请求头是在你每次向网络服务器发送请求时,传递的一组属性和配置信息。HTTP 定义了十几种古怪的请求头类型,不过大多数都不常用。
每个网站都有不同的请求头,如何获取这个请求头呢?可以用我从前提到过的Fiddler或者审查元素的方法,我们可以根据实际情况进行配置。例如,GET百度根目录的时候,需要添加的请求头信息如下:
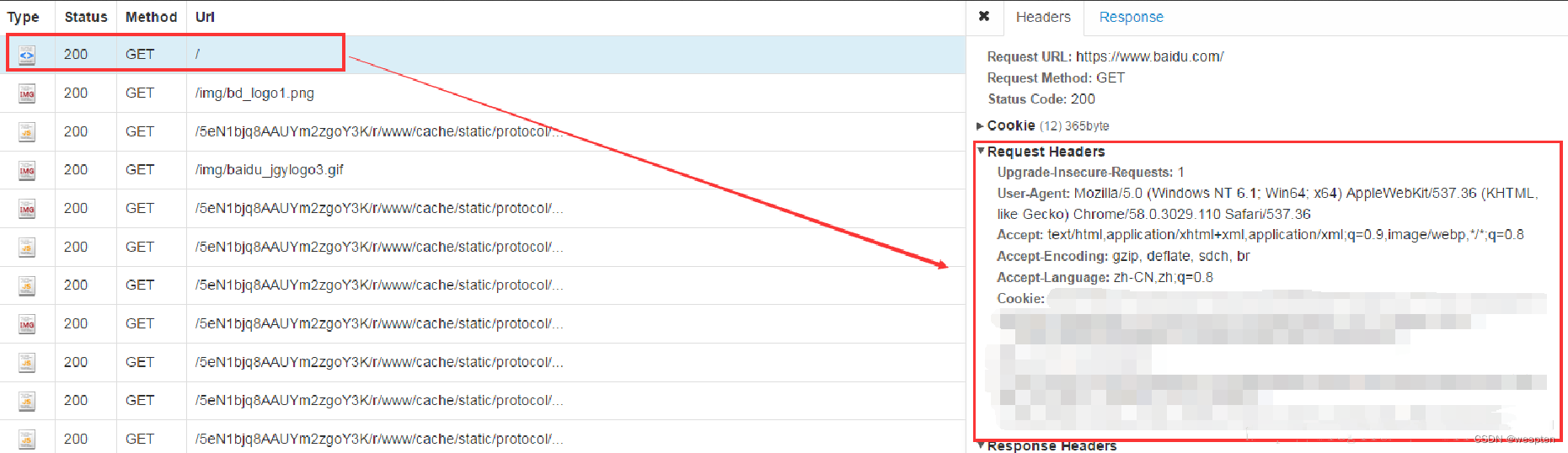
部分参数说明:
-
Upgrade-Insecure-Requests:参数为1。该指令用于让浏览器自动升级请求从http到https,用于大量包含http资源的http网页直接升级到https而不会报错。简洁的来讲,就相当于在http和https之间起的一个过渡作用。就是浏览器告诉服务器,自己支持这种操作,我能读懂你服务器发过来的上面这条信息,并且在以后发请求的时候不用http而用https;
-
User-Agent:有一些网站不喜欢被爬虫程序访问,所以会检测连接对象,如果是爬虫程序,也就是非人点击访问,它就会不让你继续访问,所以为了要让程序可以正常运行,我们需要设置一个浏览器的User-Agent;
-
Accept:浏览器可接受的MIME类型,可以根据实际情况进行设置;
-
Accept-Encoding:浏览器能够进行解码的数据编码方式,比如gzip。Servlet能够向支持gzip的浏览器返回经gzip编码的HTML页面。许多情形下这可以减少5到10倍的下载时间;
-
Accept-Language:浏览器所希望的语言种类,当服务器能够提供一种以上的语言版本时要用到;
-
Cookie:这是最重要的请求头信息之一。中文名称为“小型文本文件”或“小甜饼“,指某些网站为了辨别用户身份而储存在用户本地终端(Client Side)上的数据(通常经过加密)。定义于RFC2109。是网景公司的前雇员卢·蒙特利在1993年3月的发明。
2. 设置Cookie的学问
虽然 cookie 是一把双刃剑,但正确地处理 cookie 可以避免许多采集问题。网站会用 cookie 跟踪你的访问过程,如果发现了爬虫异常行为就会中断你的访问,比如特别快速地填写表单,或者浏览大量页面。虽然这些行为可以通过关闭并重新连接或者改变 IP 地址来伪装,但是如果 cookie 暴露了你的身份,再多努力也是白费。
在采集一些网站时 cookie 是不可或缺的。要在一个网站上持续保持登录状态,需要在多个页面中保存一个 cookie。有些网站不要求在每次登录时都获得一个新 cookie,只要保存一个旧的“已登录”的 cookie 就可以访问。
如果你在采集一个或者几个目标网站,建议你检查这些网站生成的 cookie,然后想想哪一个 cookie 是爬虫需要处理的。有一些浏览器插件可以为你显示访问网站和离开网站时 cookie 是如何设置的。例如:EditThisCookie,该插件可以谷歌商店进行下载。URL:EditThisCookie
Cookie信息,也可以更具实际情况填写。不过requests已经封装好了很多操作,自动管理cookie,session保持连接。我们可以先访问某个目标网站,建立一个session连接之后,获取cookie。代码如下:
# -*- coding:UTF-8 -*- import requests if __name__ == '__main__': url = 'https://www.baidu.com/' headers = {'Upgrade-Insecure-Requests':'1', 'User-Agent':'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36', 'Accept':'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8', 'Accept-Encoding':'gzip, deflate, sdch, br', 'Accept-Language':'zh-CN,zh;q=0.8', } s = requests.Session() req = s.get(url=url,headers=headers) print(s.cookies)运行结果如下:
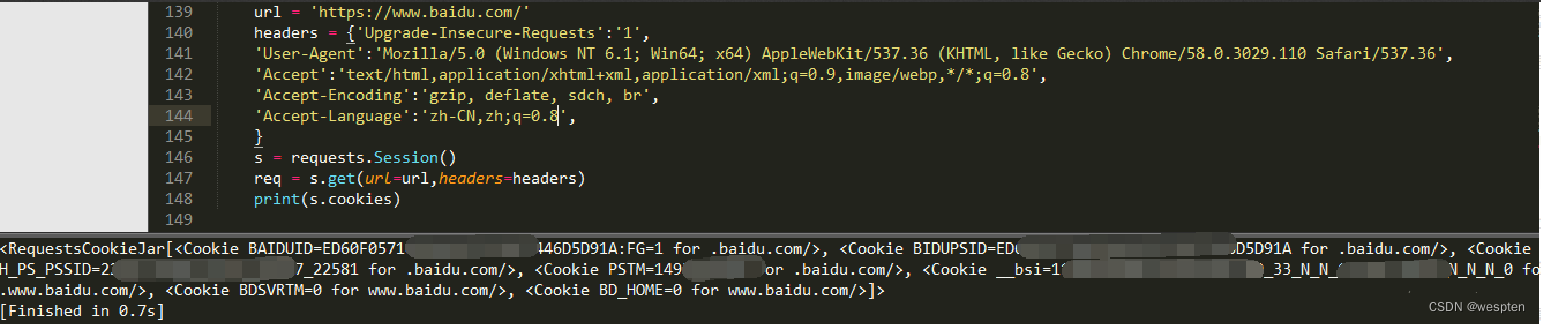
使用 requests.Session 会话对象让你能够跨请求保持某些参数,它也会在同一个 Session 实例发出的所有请求之间保持 cookie, 期间使用 urllib3 的 connection pooling 功能。详细内容参见requests高级用法:http://docs.python-requests.org/zh_CN/latest/user/advanced.html
因为 requests 模块不能执行 JavaScript,所以它不能处理很多新式的跟踪软件生成的 cookie,比如 Google Analytics,只有当客户端脚本执行后才设置 cookie(或者在用户浏览页面时基于网页事件产生 cookie,比如点击按钮)。要处理这些动作,需要用 Selenium 和 PhantomJS 包。
Selenium的安装已经在之前的文章中讲到,今天就说下PhantomJS吧。URL:PhantomJS - Scriptable Headless Browser PhantomJS 是一个“无头”(headless)浏览器。它会把网站加载到内存并执行页面上的 JavaScript,但不会向用户展示网页的图形界面。将 Selenium 和 PhantomJS 结合在一起,就可以运行一个非常强大的网络爬虫了,可以处理 cookie、JavaScript、headers,以及任何你需要做的事情。
PhantomJS可以依据自己的开发平台选择不同的包进行下载:Download PhantomJS 解压即用,很方便。
接下来呢,还是以实例出发,对 http://pythonscraping.com 网站调用 webdriver 的 get_cookie()方法来查看 cookie(D:/phantomjs-2.1.1-windows/bin/phantomjs.exe是我的PhantomJS路径,这里需要更改成你自己的):
# -*- coding:UTF-8 -*- from selenium import webdriver if __name__ == '__main__': url = 'http://pythonscraping.com' driver = webdriver.PhantomJS(executable_path='D:/phantomjs-2.1.1-windows/bin/phantomjs.exe') driver.get(url) driver.implicitly_wait(1) print(driver.get_cookies())这样就可以获得一个非常典型的 Google Analytics 的 cookie 列表:

还可以调用 delete_cookie()、add_cookie() 和 delete_all_cookies() 方法来处理 cookie。另外,还可以保存 cookie 以备其他网络爬虫使用。
通过Selenium和PhantomJS,我们可以很好的处理一些需要事件执行后才能获得的cookie。
3. 正常的访问速度
有一些防护措施完备的网站可能会阻止你快速地提交表单,或者快速地与网站进行交互。即使没有这些安全措施,用一个比普通人快很多的速度从一个网站下载大量信息也可能让自己被网站封杀。
因此,虽然多进程程序可能是一个快速加载页面的好办法——在一个进程中处理数据,另一个进程中加载页面——但是这对编写好的爬虫来说是恐怖的策略。还是应该尽量保证一次加载页面加载且数据请求最小化。如果条件允许,尽量为每个页面访问增加一点儿时间间隔,即使你要增加两行代码:
import time time.sleep(1)合理控制速度是你不应该破坏的规则。过度消耗别人的服务器资源会让你置身于非法境地,更严重的是这么做可能会把一个小型网站拖垮甚至下线。拖垮网站是不道德的,是彻头彻尾的错误。所以请控制采集速度!
4. 注意隐含输入字段
在 HTML 表单中,“隐含”字段可以让字段的值对浏览器可见,但是对用户不可见(除非看网页源代码)。随着越来越多的网站开始用 cookie 存储状态变量来管理用户状态,在找到另一个最佳用途之前,隐含字段主要用于阻止爬虫自动提交表单。
下图显示的例子就是 Facebook 登录页面上的隐含字段。虽然表单里只有三个可见字段(username、password 和一个确认按钮),但是在源代码里表单会向服务器传送大量的信息。

用隐含字段阻止网络数据采集的方式主要有两种。第一种是表单页面上的一个字段可以用服务器生成的随机变量表示。如果提交时这个值不在表单处理页面上,服务器就有理由认为这个提交不是从原始表单页面上提交的,而是由一个网络机器人直接提交到表单处理页面的。绕开这个问题的最佳方法就是,首先采集表单所在页面上生成的随机变量,然后再提交到表单处理页面。
第二种方式是“蜜罐”(honey pot)。如果表单里包含一个具有普通名称的隐含字段(设置蜜罐圈套),比如“用户名”(username)或“邮箱地址”(email address),设计不太好的网络机器人往往不管这个字段是不是对用户可见,直接填写这个字段并向服务器提交,这样就会中服务器的蜜罐圈套。服务器会把所有隐含字段的真实值(或者与表单提交页面的默认值不同的值)都忽略,而且填写隐含字段的访问用户也可能被网站封杀。
总之,有时检查表单所在的页面十分必要,看看有没有遗漏或弄错一些服务器预先设定好的隐含字段(蜜罐圈套)。如果你看到一些隐含字段,通常带有较大的随机字符串变量,那么很可能网络服务器会在表单提交的时候检查它们。另外,还有其他一些检查,用来保证这些当前生成的表单变量只被使用一次或是最近生成的(这样可以避免变量被简单地存储到一个程序中反复使用)。
5. 爬虫如何避开蜜罐
虽然在进行网络数据采集时用 CSS 属性区分有用信息和无用信息会很容易(比如,通过读取 id和 class 标签获取信息),但这么做有时也会出问题。如果网络表单的一个字段通过 CSS 设置成对用户不可见,那么可以认为普通用户访问网站的时候不能填写这个字段,因为它没有显示在浏览器上。如果这个字段被填写了,就可能是机器人干的,因此这个提交会失效。
这种手段不仅可以应用在网站的表单上,还可以应用在链接、图片、文件,以及一些可以被机器人读取,但普通用户在浏览器上却看不到的任何内容上面。访问者如果访问了网站上的一个“隐含”内容,就会触发服务器脚本封杀这个用户的 IP 地址,把这个用户踢出网站,或者采取其他措施禁止这个用户接入网站。实际上,许多商业模式就是在干这些事情。
下面的例子所用的网页在 A bot-proof form,这是一个给我们python爬虫学习的一个网站。这个页面包含了两个链接,一个通过 CSS 隐含了,另一个是可见的。另外,页面上还包括两个隐含字段:
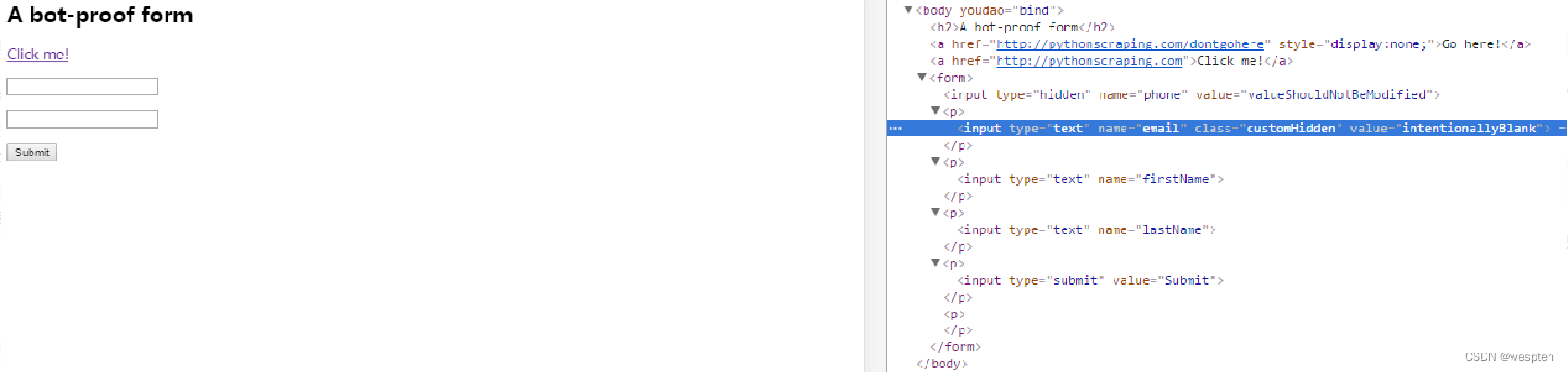
这三个元素通过三种不同的方式对用户隐藏:
- 第一个链接是通过简单的 CSS 属性设置 display:none 进行隐藏;
- 电话号码字段 name=”phone” 是一个隐含的输入字段;
- 邮箱地址字段 name=”email” 是将元素向右移动 50 000 像素(应该会超出电脑显示器的边界)并隐藏滚动条。
因为 Selenium 可以获取访问页面的内容,所以它可以区分页面上的可见元素与隐含元素。通过 is_displayed() 可以判断元素在页面上是否可见。
例如,下面的代码示例就是获取前面那个页面的内容,然后查找隐含链接和隐含输入字段(同样,需要更改下PhantomJS路径):
# -*- coding:UTF-8 -*- from selenium import webdriver if __name__ == '__main__': url = 'http://pythonscraping.com/pages/itsatrap.html' driver = webdriver.PhantomJS(executable_path='D:/phantomjs-2.1.1-windows/bin/phantomjs.exe') driver.get(url) links = driver.find_elements_by_tag_name('a') for link in links: if not link.is_displayed(): print('连接:' + link.get_attribute('href') + ',是一个蜜罐圈套.') fields = driver.find_elements_by_tag_name('input') for field in fields: if not field.is_displayed(): print('不要改变' + field.get_attribute('name') + '的值.')Selenium 抓取出了每个隐含的链接和字段,结果如下所示:
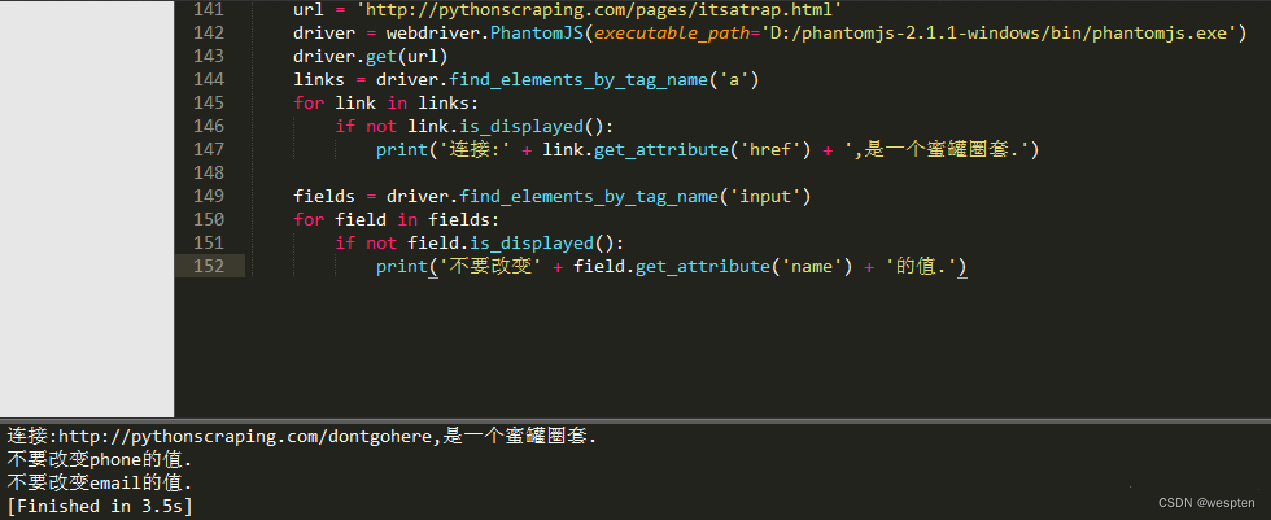
虽然你不太可能会去访问你找到的那些隐含链接,但是在提交前,记得确认一下那些已经在表单中、准备提交的隐含字段的值(或者让 Selenium 为你自动提交)。
6. 创建自己的代理IP池
启用远程平台的人通常有两个目的:对更大计算能力和灵活性的需求,以及对可变 IP 地址的需求。
有一些网站会设置访问阈值,也就是说,如果一个IP访问速度超过这个阈值,那么网站就会认为,这是一个爬虫程序,而不是用户行为。为了避免远程服务器封锁IP,或者想加快爬取速度,一个可行的方法就是使用代理IP,我们需要做的就是创建一个自己的代理IP池。
思路:通过免费IP代理网站爬取IP,构建一个容量为100的代理IP池。从代理IP池中随机选取IP,在使用IP之前,检查IP是否可用。如果可用,使用该IP访问目标页面,如果不可用,舍弃该IP。当代理IP池中IP的数量小于20的时候,更新整个代理IP池,即重新从免费IP代理网站爬取IP,构建一个新的容量为100的代理IP池。
还是使用在之前笔记中提到过的西刺代理,URL:http://www.xicidaili.com/,如果想方便一些,可以使用他们提供的API,直接获取IP。但是这些IP的更新速度有些慢,15分钟更新一次,如果满足需求,使用这个API无妨,如果需求得不到满足呢?

我们可以自己爬取IP。但是,注意一点,千万不要爬太快!很容易被服务器Block哦!
比如,我想爬取国内高匿代理,第一页的URL为:www.xicidaili.com/nn/1,第二页的URL为:www.xicidaili.com/nn/2,其他页面一次类推,一页IP正好100个,够我们用了。
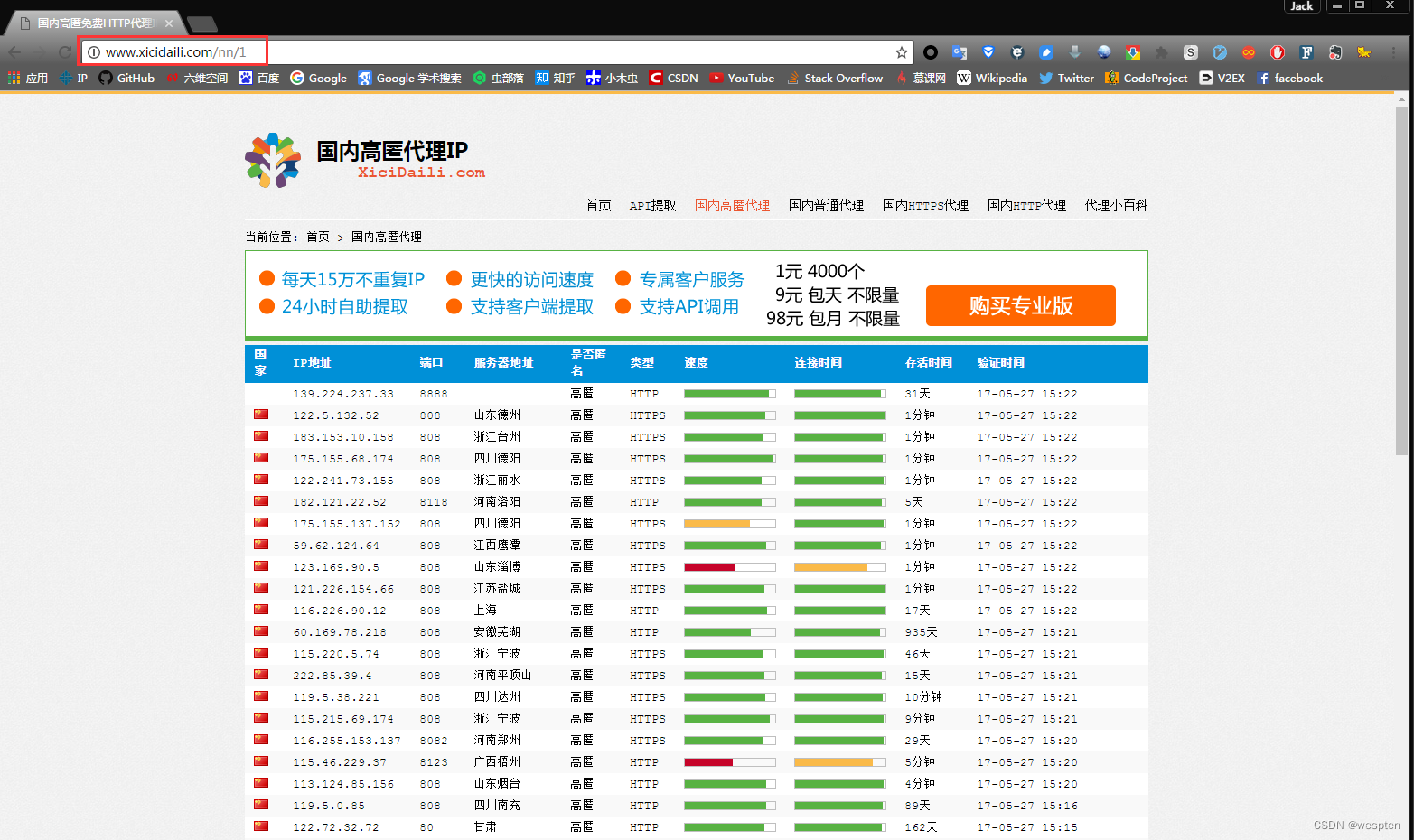
通过审查元素可知,这些ip都存放在了id属性为ip_list的table中。
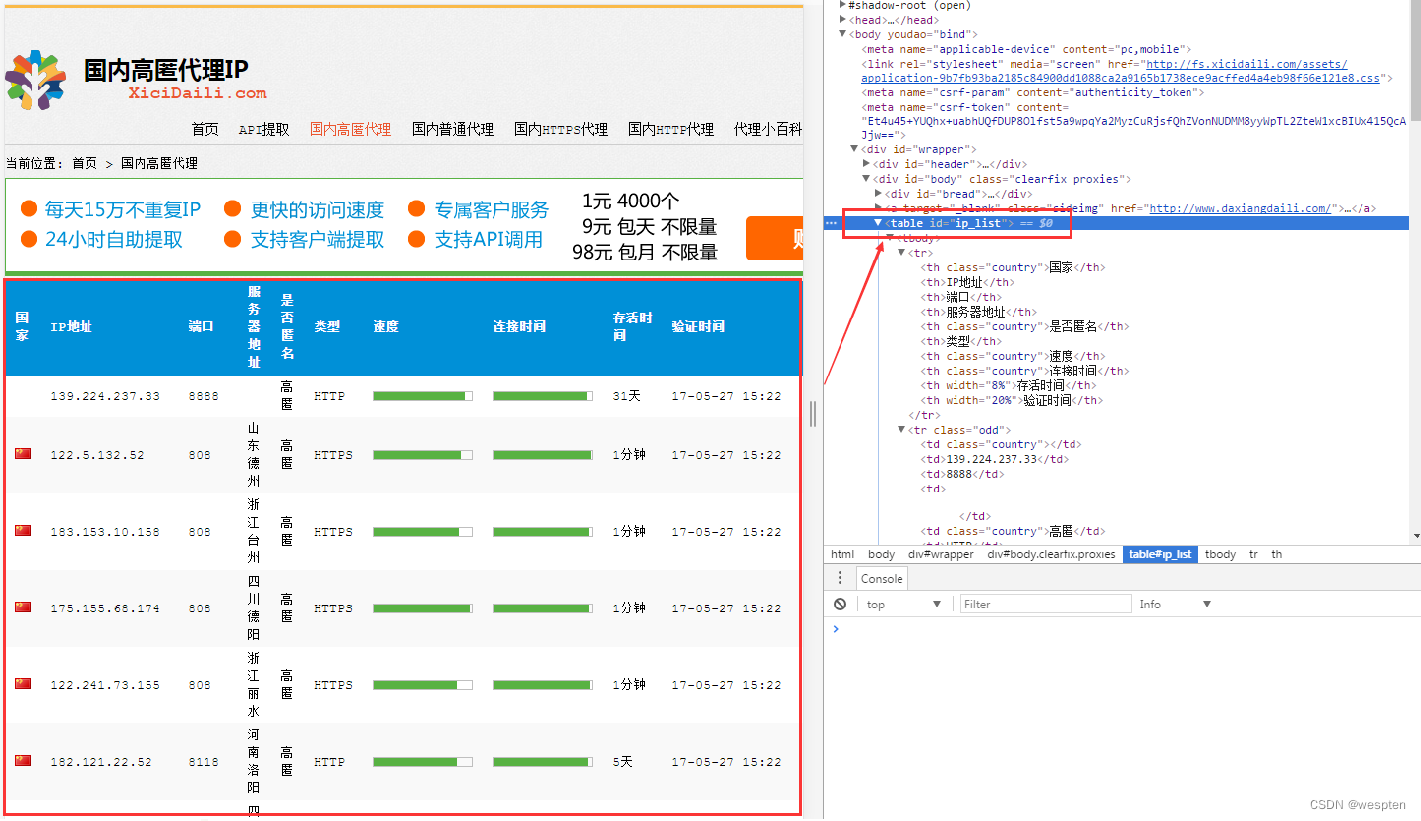
我们可以使用lxml的xpath和Beutifulsoup结合的方法,爬取所有的IP。当然,也可以使用正则表达式,方法很多。代码如下:
# -*- coding:UTF-8 -*- import requests from bs4 import BeautifulSoup from lxml import etree if __name__ == '__main__': #requests的Session可以自动保持cookie,不需要自己维护cookie内容 page = 1 S = requests.Session() target_url = 'http://www.xicidaili.com/nn/%d' % page target_headers = {'Upgrade-Insecure-Requests':'1', 'User-Agent':'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36', 'Accept':'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8', 'Referer':'http://www.xicidaili.com/nn/', 'Accept-Encoding':'gzip, deflate, sdch', 'Accept-Language':'zh-CN,zh;q=0.8', } target_response = S.get(url = target_url, headers = target_headers) target_response.encoding = 'utf-8' target_html = target_response.text bf1_ip_list = BeautifulSoup(target_html, 'lxml') bf2_ip_list = BeautifulSoup(str(bf1_ip_list.find_all(id = 'ip_list')), 'lxml') ip_list_info = bf2_ip_list.table.contents proxys_list = [] for index in range(len(ip_list_info)): if index % 2 == 1 and index != 1: dom = etree.HTML(str(ip_list_info[index])) ip = dom.xpath('//td[2]') port = dom.xpath('//td[3]') protocol = dom.xpath('//td[6]') proxys_list.append(protocol[0].text.lower() + '#' + ip[0].text + '#' + port[0].text) print(proxys_list)可以看到,通过这种方法,很容易的就获得了这100个IP,包括他们的协议、IP和端口号。这里我是用”#”符号隔开,使用之前,只需要spilt()方法,就可以提取出信息。
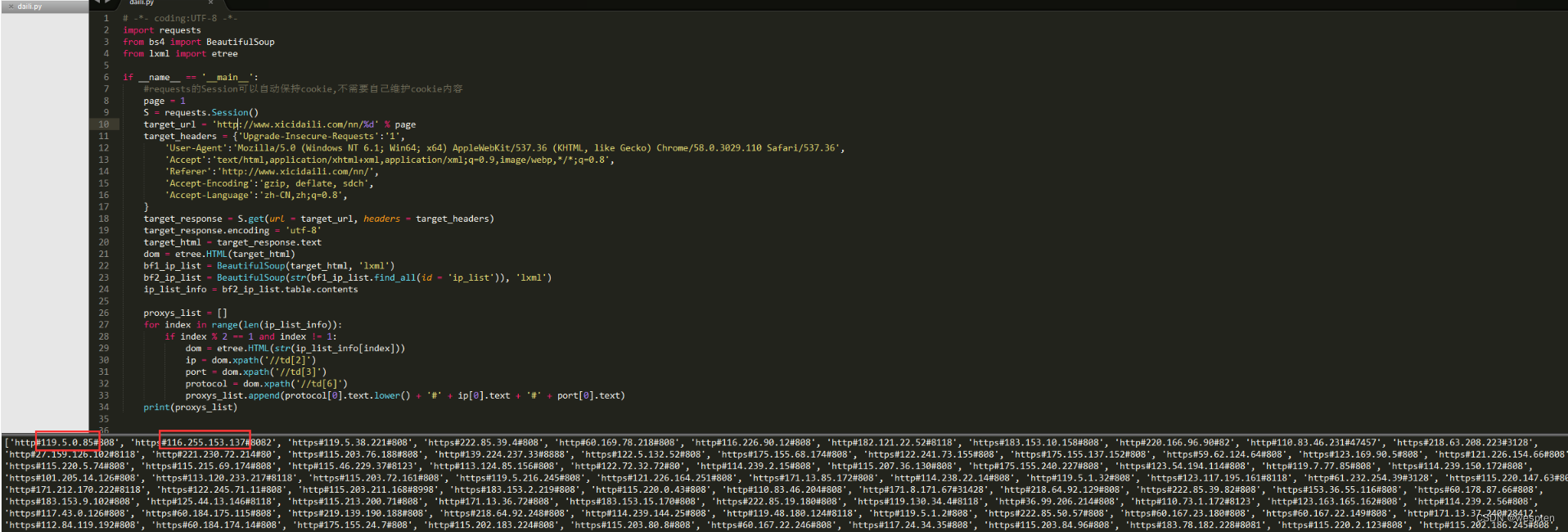
已经获取了IP,如何验证这个IP是否可用呢?一种方案是GET请求一个网页,设置timeout超市时间,如果超时服务器没有反应,说明IP不可用。这里的实现,可以参见Requests的高级用法:http://docs.python-requests.org/zh_CN/latest/user/advanced.html
这种设置timeout的验证方法是一种常见的方法,很多人都这样验证。所以博主就想了一个问题,有没有其他的方法呢?经过思考,想出了一个方法,测试了一个,验证一个IP大约需要3秒左右。呃…当然这种方法是我自己琢磨出来的,没有参考,所以,如果有错误之处,或者更好的方法,还望指正!
在Windows下,可以在CMD中输入如下指令查看IP的连通性(mac和linux可以在中断查看):
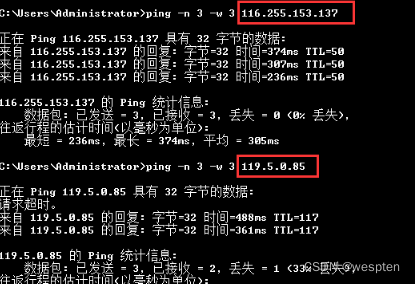
从免费代理网站获得的代理IP很不稳定,过几分钟再测试这个代理IP你可能会发现,这个IP已经不能用了。所以再使用代理IP之前,我们需要测试下代理IP是否可用。
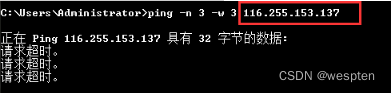
从上文可知,通过测试本机和代理IP地址的连通性,我们能够大致知道这个代理 IP的健康情况。如果,本机能够ping通这个代理 IP,那么我们也就可以使用这个代理 IP去访问其他网站。这个过程是在cmd中执行的,那么python有没有提供一个方法,通过程序来实现这样的操作呢?答案是肯定的,有!Subprocess.Popen()可以创建一个进程,当shell参数为true时,程序通过shell来执行:

-
参数args可以是字符串或者序列类型(如:list,元组),用于指定进程的可执行文件及其参数。如果是序列类型,第一个元素通常是可执行文件的路径。我们也可以显式的使用executeable参数来指定可执行文件的路径。
-
参数stdin, stdout,stderr分别表示程序的标准输入、输出、错误句柄。他们可以是PIPE,文件描述符或文件对象,也可以设置为None,表示从父进程继承。
-
如果参数shell设为true,程序将通过shell来执行。
-
subprocess.PIPE:在创建Popen对象时,subprocess.PIPE可以初始化stdin,stdout或stderr参数。表示与子进程通信的标准流。
-
subprocess.STDOUT:创建Popen对象时,用于初始化stderr参数,表示将错误通过标准输出流输出。
-
了解到以上这些,我们就可以写我们的程序了(ping本机回环地址):
# -*- coding:UTF-8 -*- import subprocess as sp if __name__ == '__main__': cmd = "ping -n 3 -w 3 127.0.0.1" #执行命令 p = sp.Popen(cmd, stdin=sp.PIPE, stdout=sp.PIPE, stderr=sp.PIPE, shell=True) #获得返回结果并解码 out = p.stdout.read().decode("gbk") print(out)运行结果如下:
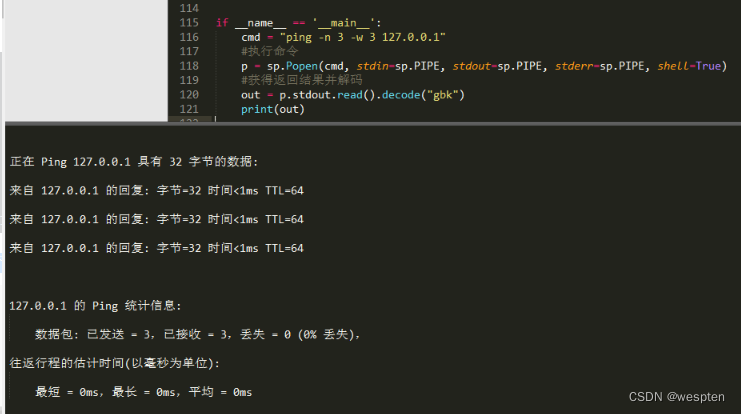
能都得到返回结果,跟cmd中类似,接下来,我们就可以制定相应的规则,根据返回信息来剔除不满足要求的ip。
整体代码如下:
# -*- coding:UTF-8 -*- from bs4 import BeautifulSoup import subprocess as sp from lxml import etree import requests import random import re """ 函数说明:获取IP代理 Parameters: page - 高匿代理页数,默认获取第一页 Returns: proxys_list - 代理列表 Modify: 2017-05-27 """ def get_proxys(page = 1): #requests的Session可以自动保持cookie,不需要自己维护cookie内容 S = requests.Session() #西祠代理高匿IP地址 target_url = 'http://www.xicidaili.com/nn/%d' % page #完善的headers target_headers = {'Upgrade-Insecure-Requests':'1', 'User-Agent':'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36', 'Accept':'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8', 'Referer':'http://www.xicidaili.com/nn/', 'Accept-Encoding':'gzip, deflate, sdch', 'Accept-Language':'zh-CN,zh;q=0.8', } #get请求 target_response = S.get(url = target_url, headers = target_headers) #utf-8编码 target_response.encoding = 'utf-8' #获取网页信息 target_html = target_response.text #获取id为ip_list的table bf1_ip_list = BeautifulSoup(target_html, 'lxml') bf2_ip_list = BeautifulSoup(str(bf1_ip_list.find_all(id = 'ip_list')), 'lxml') ip_list_info = bf2_ip_list.table.contents #存储代理的列表 proxys_list = [] #爬取每个代理信息 for index in range(len(ip_list_info)): if index % 2 == 1 and index != 1: dom = etree.HTML(str(ip_list_info[index])) ip = dom.xpath('//td[2]') port = dom.xpath('//td[3]') protocol = dom.xpath('//td[6]') proxys_list.append(protocol[0].text.lower() + '#' + ip[0].text + '#' + port[0].text) #返回代理列表 return proxys_list """ 函数说明:检查代理IP的连通性 Parameters: ip - 代理的ip地址 lose_time - 匹配丢包数 waste_time - 匹配平均时间 Returns: average_time - 代理ip平均耗时 Modify: 2017-05-27 """ def check_ip(ip, lose_time, waste_time): #命令 -n 要发送的回显请求数 -w 等待每次回复的超时时间(毫秒) cmd = "ping -n 3 -w 3 %s" #执行命令 p = sp.Popen(cmd % ip, stdin=sp.PIPE, stdout=sp.PIPE, stderr=sp.PIPE, shell=True) #获得返回结果并解码 out = p.stdout.read().decode("gbk") #丢包数 lose_time = lose_time.findall(out) #当匹配到丢失包信息失败,默认为三次请求全部丢包,丢包数lose赋值为3 if len(lose_time) == 0: lose = 3 else: lose = int(lose_time[0]) #如果丢包数目大于2个,则认为连接超时,返回平均耗时1000ms if lose > 2: #返回False return 1000 #如果丢包数目小于等于2个,获取平均耗时的时间 else: #平均时间 average = waste_time.findall(out) #当匹配耗时时间信息失败,默认三次请求严重超时,返回平均好使1000ms if len(average) == 0: return 1000 else: # average_time = int(average[0]) #返回平均耗时 return average_time """ 函数说明:初始化正则表达式 Parameters: 无 Returns: lose_time - 匹配丢包数 waste_time - 匹配平均时间 Modify: 2017-05-27 """ def initpattern(): #匹配丢包数 lose_time = re.compile(u"丢失 = (\d+)", re.IGNORECASE) #匹配平均时间 waste_time = re.compile(u"平均 = (\d+)ms", re.IGNORECASE) return lose_time, waste_time if __name__ == '__main__': #初始化正则表达式 lose_time, waste_time = initpattern() #获取IP代理 proxys_list = get_proxys(1) #如果平均时间超过200ms重新选取ip while True: #从100个IP中随机选取一个IP作为代理进行访问 proxy = random.choice(proxys_list) split_proxy = proxy.split('#') #获取IP ip = split_proxy[1] #检查ip average_time = check_ip(ip, lose_time, waste_time) if average_time > 200: #去掉不能使用的IP proxys_list.remove(proxy) print("ip连接超时, 重新获取中!") if average_time < 200: break #去掉已经使用的IP proxys_list.remove(proxy) proxy_dict = {split_proxy[0]:split_proxy[1] + ':' + split_proxy[2]} print("使用代理:", proxy_dict)从上面代码可以看出,我制定的规则是,如果丢包数大于2个,则认为ip不能用。ping通的平均时间大于200ms也抛弃。当然,我这个要求有点严格,可以视情况放宽规则:
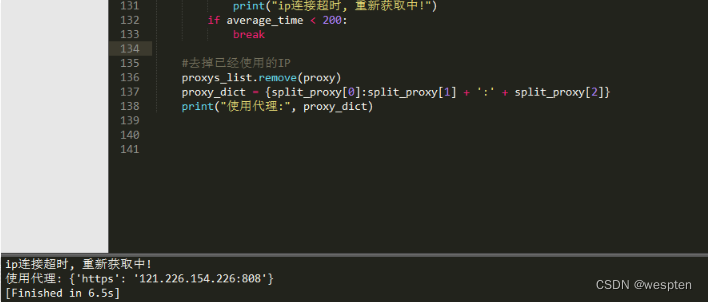
从打印结果中可以看出,第一个随机选取的IP被抛弃了,第二个随机选取的IP能用。
我只是实现了,构建代理IP池和检查IP是否可用,如果你感兴趣也可以将获取的IP放入到数据库中,不过我没这样做,因为感觉免费获取的代理IP,失效很快,随用随取就行。当然,也可以自己写代码试试reqeusts的GET请求,通过设置timeout参数来验证代理IP是否可用,因为方法简单,所以在此不再累述。
除此之外,我们也可以个创建一个User-Agent的列表,多罗列点。也是跟代理IP一样,每次访问随机选取一个。这样在一定程度上,也能避免被服务器封杀。
总结:
如果你一直被网站封杀却找不到原因,那么这里有个检查列表,可以帮你诊断一下问题出在哪里。
- **首先,检查 JavaScript 。**如果你从网络服务器收到的页面是空白的,缺少信息,或其遇到他不符合你预期的情况(或者不是你在浏览器上看到的内容),有可能是因为网站创建页面的 JavaScript 执行有问题。
- **检查正常浏览器提交的参数。**如果你准备向网站提交表单或发出 POST 请求,记得检查一下页面的内容,看看你想提交的每个字段是不是都已经填好,而且格式也正确。用 Chrome 浏览器的网络面板(快捷键 F12 打开开发者控制台,然后点击“Network”即可看到)查看发送到网站的 POST 命令,确认你的每个参数都是正确的。
- **是否有合法的 Cookie?**如果你已经登录网站却不能保持登录状态,或者网站上出现了其他的“登录状态”异常,请检查你的 cookie。确认在加载每个页面时 cookie 都被正确调用,而且你的 cookie 在每次发起请求时都发送到了网站上。
- **IP 被封禁?**如果你在客户端遇到了 HTTP 错误,尤其是 403 禁止访问错误,这可能说明网站已经把你的 IP 当作机器人了,不再接受你的任何请求。你要么等待你的 IP 地址从网站黑名单里移除,要么就换个 IP 地址。如果你确定自己并没有被封杀,那么再检查下面的内容:
- 确认你的爬虫在网站上的速度不是特别快。快速采集是一种恶习,会对网管的服务器造成沉重的负担,还会让你陷入违法境地,也是 IP 被网站列入黑名单的首要原因。给你的爬虫增加延迟,让它们在夜深人静的时候运行。切记:匆匆忙忙写程序或收集数据都是拙劣项目管理的表现;应该提前做好计划,避免临阵慌乱。
- 还有一件必须做的事情:修改你的请求头!有些网站会封杀任何声称自己是爬虫的访问者。如果你不确定请求头的值怎样才算合适,就用你自己浏览器的请求头吧。
- 确认你没有点击或访问任何人类用户通常不能点击或接入的信息。
- 如果你用了一大堆复杂的手段才接入网站,考虑联系一下网管吧,告诉他们你的目的。试试发邮件到 webmaster@< 域名 > 或 admin@< 域名 >,请求网管允许你使用爬虫采集数据。管理员也是人嘛!
使用免费的代理IP也是有局限的,就是不稳定。更好的方法是,花钱买一个可以动态切换IP的阿里云服务器,这样IP就可以无限动态变化了!
十一、提高爬虫程序爬取效率前面编写的爬虫程序是运行在一个CPU开启的单个进程中的,每个爬虫任务依次执行,这种代码执行方式称为串行,其执行效率很低。
要提高爬虫程序的执行效率,可以使用两种代码执行方式:第一种方式称为并行,它使用多个CPU来执行爬虫程序中的每个爬虫任务,相对于串行方式而言效率更高;第二种方式称为并发,在执行爬虫任务中遇到I/O(输入/输出)操作时,由于I/O设备的速度远远低于CPU的运行速度,CPU就会出现空闲,并发方式会利用空闲让CPU去执行其他爬虫任务,以充分利用单个CPU资源,让CPU时刻处于执行任务的状态。下面就来讲解并行和并发的编程方法。
1、多进程实现并行1. 进程的创建
代码文件:进程的创建.py
在学习多进程并行之前,先来学习创建单个进程的两种方法。
第一种方法是新建一个继承自Process(进程)类的类,在类中定义run()函数,然后使用start()函数开启主进程,再由主进程调用类的run()函数来开启子进程。
演示代码如下:
1 from multiprocessing import Process 2 import time 3 class MyProcess(Process): # 新建一个类,继承自Process类 4 def __init__(self, name): 5 super().__init__() # 执行父类的构造函数 6 self.name = name 7 def run(self): # 必须定义一个run()函数 8 print(f'{self.name} 正在爬取') 9 time.sleep(5) # 模拟数据爬取需要的时间 10 print(f'{self.name} 爬取完毕') 11 if __name__ == '__main__': # Windows环境下,开启多进程的代码一定要写在这一行代码的下方 12 p = MyProcess('www.1.com') 13 p.start() # 开启主进程 14 print('主进程开始运行')第二种方法是直接使用Process类,将执行爬虫任务的函数的名称作为参数target的值,其他参数以元组或字典的格式传入。
演示代码如下:
1 from multiprocessing import Process 2 import time 3 def task(url1): # 执行爬虫任务的函数 4 print(f'{url1} 正在爬取') 5 time.sleep(5) 6 print(f'{url1} 爬取完毕') 7 if __name__ == '__main__': # Windows环境下,开启多进程的代码一定要写在这一行代码的下方 8 p = Process(target=task, kwargs={'url1': 'www.1.com'}) # 用参数target传入执行爬虫任务的函数task(),其参数url1的值用参数kwargs以字典格式传入 9 p.start() # 开启主进程,通知操作系统在内存中开辟一个空间,将p进程放进去由CPU执行 10 print('主进程开始运行')两种方法的代码运行结果是一样的,如下图所示:
2. 多进程的通信和基本用法
代码文件:多进程的通信和基本用法.py
不同进程之间是有数据隔离的,即一个进程更改了全局变量后,其他进程不知道该全局变量被更改,还是会取得未更改时的全局变量。因此,在实现多进程之前需要解决进程之间的数据隔离问题,实现不同进程之间的通信,这样才能实现多进程之间的任务分配。常用的方法是使用队列,例如,将需要爬取的不同网址放在同一队列中,不同进程从同一队列中取出不同的网址进行爬取。如果不使用队列,那么每个进程都会对所有网址进行爬取,费时且低效。
下面将多个网址放入一个队列中,在每个进程中取出队列中的一个网址进行爬取,实现网址爬取任务的分配,演示代码如下:
1 import os 2 from multiprocessing import Queue 3 from multiprocessing import Process 4 import time 5 def task(q): 6 try: 7 print(os.getpid(), q.get()) 8 time.sleep(2) # 模拟数据请求的耗时 9 except Exception: 10 return 11 if __name__ == '__main__': 12 process_list = [] # 创建一个空列表用于存放进程对象 13 q = Queue(10) # 创建一个队列,容量为10 14 for i in range(10): # 模拟10个网址放入队列中 15 url = f'www.{i}.com' 16 q.put(url) 17 start_time = time.time() 18 for i in range(10): # 创建10个子进程 19 p = Process(target=task, args=(q,)) # 将task()作为任务函数、队列q作为参数传入子进程 20 process_list.append(p) 21 p.start() # 由主进程开启子进程 22 for p in process_list: 23 p.join() # 待每一个子进程都结束后再结束主进程 24 print('程序耗时', time.time() - start_time) 25 print('数据爬取完成')代码运行结果如下图所示。
可发现每个进程都分配到了不同的网址,即实现了不同进程之间的任务分配。每个进程中使用time模块延时了2秒,如果不使用多进程至少要耗时20秒,使用多进程来执行只耗时约3秒
2、进程池的创建
代码文件:进程池的创建.py
上一节实现了多进程通信,通过循环创建多个进程来操作一个队列,但是这种方式会为每个任务创建一个进程,如果任务太多就会创建出大量进程,给计算机带来很大的负担。下面要介绍的进程池可以解决这个问题。
进程池也能创建进程来执行任务,它的特点在于:如果进程池中的进程数量没有达到规定的上限,对于新任务会创建新进程来执行;如果进程池满了,还未执行的任务会进入等待状态,直到一个进程处理完当前任务,继续接手下一个任务。这样做的好处就是不用频繁地开启进程和杀死进程,还能限定开启进程的个数,对计算机资源进行合理调配。其实在编程中很多地方都有池的概念,例如,为了减少连接和断开数据库时的计算机资源消耗,可以使用数据库连接池来优化程序。
在Python中使用Pool类创建进程池。向进程池提交任务建议采用异步提交的方式,这样才能让多个进程同时处理多个任务;如果采用同步提交的方式,则会执行完上一个进程后提交任务,再创建进程执行任务,这样和单进程没什么区别,失去了多进程的意义。
演示代码如下:
1 import os 2 import time 3 from multiprocessing import Process 4 from multiprocessing.pool import Pool # 导入Pool类创建进程池 5 def task(i): # 定义任务函数 6 print(f'{os.getpid()}处理第{i}个任务') 7 time.sleep(2) 8 if __name__ == '__main__': 9 poll = Pool(4) # 创建容量为4的进程池,最多创建4个进程 10 for i in range(1, 11): 11 poll.apply_async(task, (i, )) # 异步提交任务 12 poll.close() # 关闭进程池 13 poll.join() # 使用异步方式提交任务,必须使用close()和join()函数,目的是等待进程池的子进程结束后才结束主进程,并关闭进程池第11行代码是实现异步提交任务必须要编写的。因为使用同步方式提交任务时,主进程会等待子进程的任务完成后再提交下一个任务;而使用异步方式提交任务时,主进程会直接执行下一行代码,不会等待子进程的任务完成后再提交下一个任务,这样可以快速提交多个任务。
此外,如果主进程结束,进程池也就关闭了,任务就不能被处理,所以在第12行代码使用close()函数手动关闭进程池,并在第13行代码使用join()函数让主进程等待进程池中的任务处理完毕后再执行主进程的下一步代码,这样就不会提前关闭进程池了。
代码运行结果如下图所示。可以看到只有4个进程,当进程池满了后,一个进程执行完当前任务就去执行下一个任务,而不会开启新进程,这就是进程池的优点。
3、多线程实现并发
代码文件:多线程实现并发.py
一个进程中能存在多个线程,一个线程遇到I/O阻塞时会处于挂起状态,此时其他线程会来争抢CPU资源,CPU就会去执行其他线程。线程的切换速度很快,快到能使人发现不了两个任务的执行其实是有先后顺序的,感觉所有线程是在同时运行一样,这就是并发的效果。而且线程占用系统资源小,执行速度更快,所以使用多线程可以提高程序的运行效率。Python的threading模块提供了创建线程的方法。
1. 单线程的创建
线程的创建方式和进程的创建方式差不多,只是使用的函数不同。
演示代码如下:
1 from threading import Thread 2 def task(url1): # 模拟爬虫任务 3 print(f'{url1}正在爬取') 4 if __name__ == '__main__': 5 t = Thread(target=task, args=('www.1.com', )) # 创建线程 6 t.start() # 开启主线程 7 print('主线程开始')代码运行结果如下图所示。可以看到和进程不同的是,主线程开始时输出的提示信息在子线程开始时输出的提示信息之后,原因是线程的执行速度太快了,主线程的代码还没有运行完毕,子线程的代码就运行完毕了。如果在子线程中模拟I/O操作,运行结果中提示信息的输出顺序会相反。
和进程一样,也可以用join()函数让主线程等待子线程结束再结束。
2. 多线程的基本用法
线程之间本身是可以通信的,所以无须借助队列,使用普通的列表就能实现任务的分配。演示代码如下:
1 from threading import Thread 2 import time 3 import random 4 def task(url_list): 5 try: 6 print(random.choice(url_list)) 7 time.sleep(2) # 模拟数据请求的耗时 8 except Exception: 9 return 10 if __name__ == '__main__': 11 thread_list = [] # 创建一个空列表用于存放线程对象 12 url_list = [] # 创建一个空列表用于存放所有网址 13 for i in range(10): # 模拟10个网址放入列表中 14 url = f'www.{i}.com' 15 url_list.append(url) 16 start_time = time.time() 17 for i in range(10): # 创建10个子线程 18 t = Thread(target=task, args=(url_list,)) # 将task()作为任务函数,队列q作为参数传入子线程 19 thread_list.append(t) 20 t.start() # 由主线程开启子线程 21 for t in thread_list: 22 t.join() # 待每一个子线程都结束后再结束主进程 23 print('程序耗时', time.time() - start_time) 24 print('数据爬取完成')代码运行结果如下图所示。一个任务耗时2秒,多线程执行10个任务耗时约2秒,可见多线程对提高代码执行效率有很大作用。
4、线程池的创建
代码文件:线程池的创建.py
线程池和进程池的作用很相似,也是通过创建指定数量的线程来执行任务,一个线程执行完一个任务会接着执行下一个任务,减少了开启新线程的系统开销,可以更合理地调配系统资源。线程池的创建需要用到concurrent.futures模块中的ThreadPoolExecutor类。
演示代码如下:
1 from concurrent.futures import ThreadPoolExecutor 2 from threading import current_thread 3 import os 4 import time 5 a = 1 6 def task(url1): 7 global a 8 time.sleep(1) # 模拟I/O阻塞 9 print(f'线程{current_thread().ident}开始第{a}个任务') # 使用current_thread().ident查看线程ID 10 a += 1 11 executor = ThreadPoolExecutor(max_workers=3) # 创建线程池 12 for i in range(1, 11): 13 future = executor.submit(task, i) # 创建子线程并获取返回值 14 executor.shutdown() # 关闭线程池代码运行结果如下图所示:

细心的读者可能会发现相同的线程处理了不同的任务,其实本质上并非如此,只是在同一时刻有多个线程在运行,线程之间可以直接通信,所以它们能同时读取全局变量a,就会得到相同的值。
这是线程共享全局变量带来的数据安全隐患,可以通过加锁来解决:使用Lock类实例化一个锁,在调用共享全局变量的前后分别进行加锁和解锁的操作。
演示代码如下:
1 from threading import Lock 2 import os 3 import time 4 a = 1 5 lock = Lock() # 实例化一个锁 6 def task(i): 7 lock.acquire() # 加锁 8 time.sleep(1) # 模拟I/O阻塞 9 global a 10 print(f'线程{current_thread().ident}开始第{a}个任务') # 使用current_thread().ident查看线程ID 11 a += 1 12 lock.release() # 解锁第5、7、12行代码就是对线程池代码的任务函数做了加锁和解锁操作,主要是确保同一时间只有一个线程在使用共享资源。加锁会让代码执行效率变低,但是不用担心,因为在实际的爬虫程序中应用线程池时一般会使用队列,而队列会自己做加锁和解锁的操作,以保证队列中的一个任务只会被一个线程执行,并且有多个任务等待被执行,不会造成多个线程等待一个任务的情况。
如果为了保证数据安全不得不使用全局变量,则必须加锁,造成的执行效率变低是不可避免的。虽然效率变低了,但是相较于使用同一个线程来处理爬虫任务,速度还是快了很多。
5、多任务异步协程实现并发代码文件:多任务异步协程实现并发.py
协程其实是由代码调度的线程,可以让CPU在指定的不同线程中来回执行线程中的任务,其他线程不会争抢到CPU的执行权限,从而减少CPU切换的系统开销。协程也是实现并发的一种途径,能大大提高代码的执行效率。asyncio是用于实现并发协程的Python内置模块,它能将多个协程对象封装成任务对象,再将多个任务对象注册到事件循环对象,从而实现多个任务的并发执行。下面就来学习如何用多任务异步协程提高爬虫任务的执行效率。
首先使用asyncio模块创建协程对象,这个模块会使用async关键词修饰一个函数,被修饰的函数在被调用时不会立即执行,而是返回一个协程对象。
演示代码如下:
1 import asyncio 2 import time 3 async def get_page(url): # 使用async关键词修饰函数,使函数在被调用时返回一个协程对象 4 print(f'正在爬取{url}') 5 time.sleep(1) 6 print(f'{url}爬取完毕') 7 return '页面源代码' 8 def parse_page(task): # 回调函数 9 print('数据解析结果为xxxxxx', task.result()) # task.result()为绑定回调函数的get_page()函数的返回值 10 coroutine = get_page('www.1.com') # 实例化一个协程对象然后将协程对象进一步封装为任务对象。任务对象可以使用回调函数,在爬虫应用中很重要,因为回调函数会在任务函数之后执行。假设在爬虫应用中任务函数是对网址发起请求,回调函数是对请求的网页源代码进行数据解析,网址请求完毕后再调用数据解析的回调函数,数据解析完毕,一个网址的爬虫任务才算完成。
如果不使用回调函数,对网址发起请求的函数不知道数据解析何时完毕,当前协程何时结束,需要对数据解析函数进行轮询,这样效率就比较低。因此,在事件驱动型程序中,回调函数是比较常用的。
创建任务对象的演示代码如下:
1 task = asyncio.ensure_future(coroutine) # 将协程对象封装为任务对象 2 task.add_done_callback(parse_page) # 给任务对象绑定回调函数接着创建事件循环对象。事件循环是asyncio模块的核心,它可以执行异步任务、事件回调、网络I/O操作及运行子进程。使用事件循环能以异步的方式高效地执行事件循环对象中的任务对象,提高爬虫代码的执行效率。
演示代码如下:
1 loop = asyncio.get_event_loop() # 创建一个事件循环对象 2 loop.run_until_complete(task) # 将任务对象注册到事件循环对象,并开启事件循环对象,处理任务对象第2行代码一运行就会执行注册到事件循环对象的任务对象,任务对象的执行结果就是被修饰的函数真正执行的结果。也就是说,第2行代码运行时才会真正执行get_page()函数。
最后使用for语句构造循环,创建多个协程对象,然后封装成多个任务对象,注册到事件循环对象中,就能实现多任务的异步协程。演示代码如下:
1 import asyncio 2 import time 3 async def get_page(url): # 使用async关键词修饰函数,使函数在被调用时返回一个协程对象 4 print(f'正在爬取{url}') 5 await asyncio.sleep(1) 6 print(f'{url}爬取完毕') 7 url_list = ['www.1.com', 'www.2.com', 'www.3.com', 'www.4.com', 'www.5.com'] # 网址列表 8 task_list = [] # 任务对象列表 9 for url in url_list: 10 coroutine = get_page(url) # 实例化一个协程对象 11 task = asyncio.ensure_future(coroutine) # 将协程对象封装为任务对象 12 task_list.append(task) # 将任务对象存放到列表中 13 loop = asyncio.get_event_loop() # 创建一个事件循环对象 14 time1 = time.time() 15 loop.run_until_complete(asyncio.wait(task_list)) # 将任务对象列表中的任务对象逐个注册到事件循环对象中 16 time2 = time.time() - time1 17 print(time2) # 查看任务运行耗时第5行代码中不能使用time模块来模拟I/O阻塞,因为time模块不支持异步,如果使用time模块,执行时间就会延长。这里使用的是asyncio模块的sleep()函数,但是注意需要加上await关键词进行修饰,让代码等待I/O操作完成再进行下一步。如果不使用await关键词修饰I/O操作,执行时间就会接近0秒,其中的任务未完成就结束了,这样无意义。第15行代码也需要使用asyncio模块的wait()函数将任务列表逐个注册到事件循环对象中,不能直接使用列表注册,否则会报错。
代码运行结果如下图所示。可以看到运行耗时约1秒,与逐个执行任务函数相比快了几倍,说明利用多任务异步协程可以大大提高爬虫代码的执行效率。
6、多进程、多线程和多任务异步协程在爬虫中的应用
代码文件:多进程、多线程和多任务异步协程在爬虫中的应用.py
将通过爬取视频链接来直观地对比普通执行方式与多进程、多线程和多任务异步协程在耗时上的区别。
在浏览器中打开网址http://699pic.com/,依次单击“视频>实拍视频”链接,找到不同页码页面的网址模板,如http://699pic.com/video-sousuo-0-1-{页码}-all-popular-0-0-0-0-0-0.html。
1. 使用普通执行方式爬取视频链接
使用普通执行方式爬取数据时,可以使用循环创建一个网址列表,对列表中的每个网址发起请求并解析页面中的视频链接,同时计算耗时。
演示代码如下:
1 import requests 2 import time 3 from lxml import etree 4 headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.75 Safari/537.36'} 5 url_list = [] # 网址列表 6 for i in range(1, 100): # 在网址列表中添加网址 7 url = f'http://699pic.com/video-sousuo-0-1-{i}-all-popular-0-0-0-0-0-0.html' 8 url_list.append(url) 9 def get_response(url): # 发起请求的函数 10 response = requests.get(url=url, headers=headers).text 11 html = etree.HTML(response) 12 video_parse(html) # 调用解析视频链接的函数 13 def video_parse(html): # 解析视频链接的函数 14 video_url = html.xpath('/html/body/div[2]/div[4]/ul/li/a[1]/div/video/@data-original') 15 print(video_url) # 打印视频链接 16 start_time = time.time() # 记录开始时间 17 for url in url_list: 18 get_response(url) 19 finish_time = time.time() # 记录结束时间 20 pay_time = finish_time-start_time # 计算耗时 21 print(pay_time)代码运行结果如下图所示,可看到总耗时约25秒。
2. 使用进程池爬取视频链接
这里使用concurrent.futures模块中的ProcessPoolExecutor类创建进程池,使用方法和用于创建线程池的ThreadPoolExecutor类一致。
演示代码如下:
1 import requests 2 import time 3 from lxml import etree 4 from concurrent.futures import ProcessPoolExecutor 5 headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.75 Safari/537.36'} 6 def get_response(url): # 发起请求的函数 7 response = requests.get(url=url, headers=headers) 8 result = response.text 9 html = etree.HTML(result) 10 video_parse(html) # 调用解析视频链接的函数 11 def video_parse(html): # 解析视频链接的函数 12 video_url = html.xpath('/html/body/div[2]/div[4]/ul/li/a[1]/div/video/@data-original') 13 print(video_url) # 打印视频链接 14 if __name__ == '__main__': 15 poll = ProcessPoolExecutor(4) # 创建容量为4的进程池 16 start_time = time.time() # 记录开始时间 17 for i in range(1, 100): # 创建网址队列 18 url = f'http://699pic.com/video-sousuo-0-1-{i}-all-popular-0-0-0-0-0-0.html' 19 poll.submit(get_response, url) # 提交任务 20 poll.shutdown(wait=True) 21 finish_time = time.time() # 记录结束时间 22 pay_time = finish_time - start_time # 计算耗时 23 print(pay_time)代码运行结果如下图所示,可看到总耗时约8秒,只有之前的1/3。如果将进程池容量设置得更大,执行速度会更快。不过建议进程池容量不要太大,因为开启太多进程会给计算机带来很大的负担。
3. 使用线程池爬取视频链接
使用线程池爬取视频链接的代码与使用进程池爬取视频链接的代码基本相同,只需将第4行代码导入的ProcessPoolExecutor类改为ThreadPoolExecutor类,并将第15行代码改为poll = ThreadPoolExecutor(4)。
代码运行结果如下图所示,可看到其耗时比使用进程池的耗时稍微短了一些,但是改善并不算明显。
4. 使用多任务异步协程爬取视频链接
在asyncio模块中不能使用不支持异步的模块,这样会让异步的效果消失。因为requests模块不支持异步,所以这里使用aiohttp模块代替requests模块发起请求。
演示代码如下:
1 import aiohttp 2 import asyncio 3 import time 4 from lxml import etree 5 headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.75 Safari/537.36'} 6 async def get_response(url): # 发起请求的函数 7 async with aiohttp.ClientSession() as s: 8 async with await s.get(url=url, headers=headers) as response: 9 result = await response.text() 10 html = etree.HTML(result) 11 return html 12 def video_parse(task): # 解析视频链接的函数 13 html = task.result() # 取出任务函数的返回值,即获取到的网页源代码 14 video_url = html.xpath('/html/body/div[2]/div[4]/ul/li/a[1]/div/video/@data-original') 15 print(video_url) # 打印视频链接 16 task_list = [] 17 start_time = time.time() # 记录开始时间 18 for i in range(1, 100): # 创建网址队列 19 url = f'http://699pic.com/video-sousuo-0-1-{i}-all-popular-0-0-0-0-0-0.html' 20 coroutine = get_response(url) # 实例化协程对象 21 task = asyncio.ensure_future(coroutine) # 封装任务对象 22 task.add_done_callback(video_parse) # 绑定回调函数 23 task_list.append(task) # 将任务对象添加到任务列表 24 loop = asyncio.get_event_loop() # 创建事件循环对象 25 loop.run_until_complete(asyncio.wait(task_list)) # 开启事件循环对象 26 finish_time = time.time() # 记录结束时间 27 pay_time = finish_time - start_time # 计算耗时 28 print(pay_time)使用多任务异步协程时,在I/O阻塞操作的任务函数前需要添加await关键词,例如,第8行和第9行代码的函数前就添加了await;同时还需要在第7行和第8代码中的每个with前添加async关键词,否则运行时会报错。
代码运行结果如下图所示,可看到耗时不到3秒。
比较上述代码和运行结果,从代码的复杂程度来说,使用进程池和线程池很简单,只需将创建的进程提交给进程池或线程池;而使用多任务异步协程就麻烦了许多,需要额外添加async、await等关键词。尽管如此,多任务异步协程对代码执行效率的改善最为明显,是非常重要的爬虫程序优化手段。
十二、爬虫助手 1、各大网站RSS订阅源地址各大网站RSS订阅源地址_Techzero的博客-CSDN博客_rss订阅地址
2、腾讯股票接口、和讯网股票接口、新浪股票接口、雪球股票数据、网易股票接口、A股、港股、美股
腾讯股票接口、和讯网股票接口、新浪股票接口、雪球股票数据、网易股票接口、A股、港股、美股_hnxcmyron的博客-CSDN博客_和讯股票接口
关注打赏 - 标签
标签下所有- 标签中的所有
最近更新
- 深拷贝和浅拷贝的区别(重点)
- 【Vue】走进Vue框架世界
- 【云服务器】项目部署—搭建网站—vue电商后台管理系统
- 【React介绍】 一文带你深入React
- 【React】React组件实例的三大属性之state,props,refs(你学废了吗)
- 【脚手架VueCLI】从零开始,创建一个VUE项目
- 【React】深入理解React组件生命周期----图文详解(含代码)
- 【React】DOM的Diffing算法是什么?以及DOM中key的作用----经典面试题
- 【React】1_使用React脚手架创建项目步骤--------详解(含项目结构说明)
- 【React】2_如何使用react脚手架写一个简单的页面?
立即登录/注册

微信扫码登录
- 标签等,如下图所示,这些标签同样可以继续展开。这样一层层地剖析,就能大致了解网页的结构组成和源代码之间的对应关系。
- 和
- 标签,如下左图所示。使用谷歌浏览器打开修改后的网页,效果如下右图所示。
- 标签之下,一个
- 标签分别用于定义无序列表和有序列表。
- 标签位于
- 标签和