
CSDN软件工程师能力认证(以下简称C系列认证)是由中国软件开发者网CSDN制定并推出的一个能力认证标准。C系列认证历经近一年的实际线下调研、考察、迭代、测试,并梳理出软件工程师开发过程中所需的各项技术技能,结合企业招聘需求和人才应聘痛点,基于公开、透明、公正的原则,甑别人才时确保真实业务场景、全部上机实操、所有过程留痕、存档不可篡改。
我们每天将都会精选CSDN站内技术文章供大家学习,帮助大家系统化学习IT技术。
简介web开发 CS即客户端client和server服务器端编程; 客户端和服务器之间要使用socket,约定协议、版本(往往使用的是TCP或者UDP协议),指定端口就可以通信了。 客户端、服务器端传输数据,数据需要有一定格式,这是双方约定的协议。 BS编程,即Browser、server开发。 Browser指浏览器,是一种特殊的客户端,支持http(s)协议,能够通过URL向服务器端发起请求,等待服务端返回HTML等数据,并在浏览器内可视化展示。 server,支持HTTP(s)协议,能够接受众多客户端发起的HTTP协议请求,经过处理,将HTML等数据返回给浏览器。 BS分为两端开发: 客户端开发,简称前端开发。HTML,CSS,JavaScript等; 服务端开发,Python有WSGI,Django,Flask,Tornado等; 本质上说,BS是一种特殊的CS,即客户端必须是一种支持HTTP协议且能够解析并渲染HTML的软件,服务端必须是能够接收多客户端HTTP访问的服务器软件。 根据TCP/IP(Transmission Control Protocol /Internet Protocol)网络协议,HTTP协议底层基于TCP协议实现。并且是应用层面的协议:
 http协议是无状态协议:即客户端两次请求之间没有任何关系,服务端并不知道前后两次请求是否来自同一客户端。(主要原因是创建http协议之初,并没有像现在这样丰富的数据,当时的需求很单一)。 cookie:键值对信息,浏览器每发起一次请求时,都会把cookie信息发送给服务器端。是一种客户端和服务器端传递数据的技术,服务器通过判断这些信息,来确定请求之间是否有联系。一般来说cookie是服务端生成,返回给客户端,客户端需要保存并且在下一次连接时返回的。但是客户端可以修改cookie,因此往往会在cookie上进行不可逆加密。
http协议是无状态协议:即客户端两次请求之间没有任何关系,服务端并不知道前后两次请求是否来自同一客户端。(主要原因是创建http协议之初,并没有像现在这样丰富的数据,当时的需求很单一)。 cookie:键值对信息,浏览器每发起一次请求时,都会把cookie信息发送给服务器端。是一种客户端和服务器端传递数据的技术,服务器通过判断这些信息,来确定请求之间是否有联系。一般来说cookie是服务端生成,返回给客户端,客户端需要保存并且在下一次连接时返回的。但是客户端可以修改cookie,因此往往会在cookie上进行不可逆加密。
URL组成:
URL就是地址,如www.baidu.com(schema://host[:port]/path/…/[;url-params][?query-string][#anchor]),每一个连接指向一个资源供给客户端访问。 schema,协议类型如http(s),ftp,file,mailto等。 host:port ,如百度网站等域名,通过DNS域名解析成IP才能使用,如果是80端口则可以不写,解析后对返回的IP的TCP的80端口发起访问。 /path,指向服务器资源的路径,可以为逻辑地址。 [?query-string],查询字符串,以问号与前面的路径分割,后面是key-value模式,使用&符号分割。 [#anchor],锚点或者标记,作为锚点就是网页内定位用;作为标记就是网页外做链接用(类似于word的超链接)。
HTTP消息
消息分为Request,Response。 Request:客户端(可以是浏览器)向服务器发起的请求; Response:服务器对客户端请求的回应; 它们都是由,请求行、Header消息报头、body消息正文组成。
请求
请求消息行:请求方法method 请求路径 协议版本(CRLF)
GET / HTTP/1.1(这里有回车换行符)
Host: www.baidu.com
Connection: keep-alive
Accept: text/plain, */*; q=0.01
X-Requested-With: XMLHttpRequest
User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/76.0.3809.132 Safari/537.36
Sec-Fetch-Mode: cors
Sec-Fetch-Site: same-origin
Referer: https://www.baidu.com/
Accept-Encoding: gzip, deflate, br
Accept-Language: zh-CN,zh;q=0.9
Cookie:............
请求方法分为: GET:请求获取URL对应的资源,将请求(路径、请求字符串)放在header里,即第一行,body部分没有内容,即两个回车换行符后没有内容; POST:使用表格提交数据至服务器,即两个回车换行符后有内容,body不为空; HEAD:和get类似,不过不返回消息正文。 常见的传递信息的方式: 1、GET方法使用Query String,通过查询字符串在URL中传递数据。 2、post方法提交数据:http://127.0.0.1:9000/xxx/yyy?id=1&name=B,使用表单提交数据,文本框input的name属性为age,weight,height等 请求消息:
POST /xxx/yyy?id=1&name=B HTTP/1.1
HOST: 127.0.0.1:9000
content-length: 26
(这里有两个回车换行符)
age=5&weight=90&height=170
3、URL中本身包含信息:如http://127.0.0.1:9000/python/teacher/003
响应
响应消息行:协议版本 状态码 消息描述CRLF
HTTP/1.1 200 OK
Bdpagetype: 2
Bdqid: 0xfd4f8c6300043417
Cache-Control: private
Connection: Keep-Alive
Content-Type: text/html;charset=utf-8
Date: Fri, 06 Sep 2019 10:16:44 GMT
Expires: Fri, 06 Sep 2019 10:16:44 GMT
Server: BWS/1.1
Set-Cookie: BDSVRTM=263; path=/
Set-Cookie: BD_HOME=1; path=/
Set-Cookie: H_PS_PSSID=1420_21110_20881_29523_29519_29721_29567_29220_26350_22159; path=/; domain=.baidu.com
Strict-Transport-Security: max-age=172800
X-Ua-Compatible: IE=Edge,chrome=1
Transfer-Encoding: chunked
状态码status code:
状态码在响应头第一行。 2XX——表明请求被正常处理了 1、200 OK:请求已正常处理。 2、204 No Content:请求处理成功,但没有任何资源可以返回给客户端,一般在只需要从客户端往服务器发送信息,而对客户端不需要发送新信息内容的情况下使用。 3、206 Partial Content:是对资源某一部分的请求,该状态码表示客户端进行了范围请求,而服务器成功执行了这部分的GET请求。响应报文中包含由Content-Range指定范围的实体内容。
3XX——表明浏览器需要执行某些特殊的处理以正确处理请求(浏览器做重定向,服务器端只负责发送状态码和新的URL) 4、301 Moved Permanently:资源的uri已更新。永久性重定向,请求的资源已经被分配了新的URI,以后应使用资源现在所指的URI。 5、302 Found:资源的URI已临时定位到其他位置了,姑且算你已经知道了这个情况了。临时性重定向。和301相似,但302代表的资源不是永久性移动,只是临时性性质的。换句话说,已移动的资源对应的URI将来还有可能发生改变。 6、303 See Other:资源的URI已更新。该状态码表示由于请求对应的资源存在着另一个URL,应使用GET方法定向获取请求的资源。303状态码和302状态码有着相同的功能,但303状态码明确表示客户端应当采用GET方法获取资源,这点与302状态码有区别。 当301,302,303响应状态码返回时,几乎所有的浏览器都会把POST改成GET,并删除请求报文内的主体,之后请求会自动再次发送。 7、304 Not Modified:资源已找到,但未符合条件请求。该状态码表示客户端发送附带条件的请求时(采用GET方法的请求报文中包含If-Match,If-Modified-Since,If-None-Match,If-Range,If-Unmodified-Since中任一首部)服务端允许请求访问资源,但因发生请求未满足条件的情况后,直接返回304.。 8、307 Temporary Redirect:临时重定向。与302有相同的含义。
4XX——表明客户端是发生错误的原因所在。 9、400 Bad Request:服务器端无法理解客户端发送的请求,请求报文中可能存在语法错误。 10、401 Unauthorized:该状态码表示发送的请求需要有通过HTTP认证(BASIC认证,DIGEST认证)的认证信息,需要有身份认证。 11、403 Forbidden:不允许访问那个资源。该状态码表明对请求资源的访问被服务器拒绝了。(权限,未授权IP等) 12、404 Not Found:服务器上没有请求的资源。路径错误等。
5XX——服务器本身发生错误 13、500 Internal Server Error:内部资源出故障了。该状态码表明服务器端在执行请求时发生了错误。也有可能是web应用存在bug或某些临时故障。 14、502 上游服务器内部资源出故障,例如nginx反向代理服务器出现问题。 15、503 Service Unavailable:抱歉,我现在正在忙着。该状态码表明服务器暂时处于超负载或正在停机维护,现在无法处理请求。
http协议因为基于TCP协议,是面向连接的,因此,需要三次握手和四次断开。 在Http1.1之后,支持keep-alive,默认开启,一个连接打开后会保持一段时间,浏览器如果再次访问该服务器就会使用这个TCP连接,减轻服务器压力,提高效率。
二、WSGIWSGI主要规定了服务器端和应用程序间的接口。 通过了解http和html文档,我们知道web应用就是: 1、客户端发送请求给服务器端一个http请求; 2、服务器端接受请求,并生成一个html文档; 3、服务器端向客户端发送响应,html作为响应的body; 4、客户端收到响应,从http响应消息行中提取html,并通过渲染等显示给用户。 我们将这些步骤交给服务器软件去执行,用Python专注于生成HTML文档。因为我们不希望接触到TCP连接、HTTP原始请求和响应格式,所以,需要一个统一的接口,让我们专心用Python编写Web业务。 这个接口就是WSGI:Web Server Gateway Interface。 WSGI接口定义非常简单,它只要求Web开发者实现一个函数,就可以响应HTTP请求。 wsgiref是一个WSGI参考实现库,通过帮助文档,我们可以简单的实现一个服务器框架,代码如下:
通过了解http和html文档,我们知道web应用就是: 1、客户端发送请求给服务器端一个http请求; 2、服务器端接受请求,并生成一个html文档; 3、服务器端向客户端发送响应,html作为响应的body; 4、客户端收到响应,从http响应消息行中提取html,并通过渲染等显示给用户。 我们将这些步骤交给服务器软件去执行,用Python专注于生成HTML文档。因为我们不希望接触到TCP连接、HTTP原始请求和响应格式,所以,需要一个统一的接口,让我们专心用Python编写Web业务。 这个接口就是WSGI:Web Server Gateway Interface。 WSGI接口定义非常简单,它只要求Web开发者实现一个函数,就可以响应HTTP请求。 wsgiref是一个WSGI参考实现库,通过帮助文档,我们可以简单的实现一个服务器框架,代码如下:
from wsgiref.validate import validator
from wsgiref.simple_server import make_server
def simple_app(environ, start_response):
status = '200 OK' # HTTP Status 状态码信息
headers = [('Content-type', 'text/plain')] # HTTP Headers
start_response(status, headers)
return [b"Hello World"] # 此处返回可迭代对象,示例为含有一个bytes元素的列表
validator_app = validator(simple_app)
with make_server('127.0.0.1', 9000, validator_app) as httpd:
print("Listening on port 8000....")
httpd.serve_forever()
返回使用浏览器访问host:port结果如下: 通过print(environ) 我们得知,environ是一个字典,字典内容如下(我们只截取部分有用的):
通过print(environ) 我们得知,environ是一个字典,字典内容如下(我们只截取部分有用的):
# 前面一些系统信息
SERVER_PROTOCOL : HTTP/1.1 # 协议
SERVER_SOFTWARE : WSGIServer/0.2
REQUEST_METHOD : GET # 请求方法
PATH_INFO : / # path路径
QUERY_STRING : # 查询字符串
HTTP_HOST : 127.0.0.1:9000 # host和port
HTTP_CONNECTION : keep-alive # 连接属于keep-alive连接
HTTP_ACCEPT_ENCODING : gzip, deflate, br # 可以接受的编码
HTTP_ACCEPT_LANGUAGE : zh-CN,zh;q=0.9 # 支持的语言
由源码和上述结果分析可知:make_server先将ip和端口号绑定到WSGIserver实例中,然后将HTTP请求信息封装在字典environ中(如请求方法,URL中的path路径,查询字符串,服务名,端口号,协议,userAgent信息),然后返回WSGIserver实例。其中WSGIserver继承于HTTPserver类,在上一级是socketserver.TCPserver类,再上一级是Baseserver类。在TCPserver类中有__init__,做了地址绑定和listen。然后在server_forever时调用了simple_app。这里可以看出,WSGI是基于HTTP,和TCP的接口。这里我们已经实现了基本的HTTP服务。 由源码,可知start_response(self, status, headers,exc_info=None)在make_server中传入的默认参数WSGIRequestHdenler的父类的父类的父类中调用的handle中,创建的ServerHandler 实例的父类的父类中有定义,返回的是Response Header,含有三个参数。而app返回的是Response Body,因此必须在app返回可迭代对象之前调用。 其三个参数分别代表状态码如‘200 OK’,headers是一个元素为二元组的列表,如[(‘Content-type’, ‘text/plain’)],exc_info是在错误处理的时候用,不使用validator(simple_app)可以设置exc_info参数。 由上例可知,服务器程序需要调用符合上述定义的simple_app,app处理后返回响应头和可迭代对象的正文,由服务器封装返回浏览器端。完成了一个简单的web服务器程序。 本质上: 此服务器:
- 是一个TCP服务器,监听在特定端口上;
- 支持http协议,能够将http请求报文进行解析,能够把响应数据进行http协议的报文封装并返回给客户端;
- 实现了WSGI协议。(可以参看python官方网站中的PEP0333) app:
- 遵从WSGI协议
- 本身是个可调用对象(在python中可调用对象有三种,函数,类,含有call的类)
- 调用了start_response,start_response返回响应头部
- 返回包含正文的可迭代对象
接下来我们手写一个WEB框架
三、web框架实现过程由上例可以看出,虽然在WSGI服务器处理http报文后会得到一个environ字典,但是用起来很不方便,我们可以尝试自己编写程序(查询字符串一般是xxx=yyy&zzz=ccc)用partition,split函数将字符串切割成去解析查询字符串,或者使用cgi模块(已过期的模块)和urllib模块中的parse.parse_qs,出来的就是查询字符串的键值对。 我们采用webob库来解析environ的数据,它可以将其封装成对象,并提供对响应进行高级封装(如装饰器)。官方文档在docs.webob.org。在linux和windows中都可以采用pip install webob安装webob库
webob库的使用
webob.Request对象
可以创建request = Request(environ)实例,其中request有很多方法如(只截取部分): GET:返回GET字典,是一个多值字典(简单地说key不再是唯一,get、getone后进先出,getall返回同key的所有value); POST:返回request.body的数据,同上; params:返回所有数据,参数,所有你想要的都在这里。
webob.Response对象
response = Response(),部分方法: status:返回状态码 headerlist:返回headers 由Response的源码可知,app可以返回设置了body和状态码的webob.Response对象,本身是可调用的,并且调用后返回可迭代对象就是response.body,也可以得到之前代码的结果:
from wsgiref.validate import validator
from wsgiref.simple_server import make_server
from webob import Response,Request
def app(environ, start_response):
res = Response()
res.body = b"Hello World"
return res(environ, start_response)
validator_app = validator(app)
with make_server('127.0.0.1', 9000, validator_app) as httpd:
print("Listening on port 9000....")
httpd.serve_forever()
返回 hello word
webob.dec装饰器
在webob.dec下有一个wsgify装饰器,由帮助文档可知,被wsgify装饰后只需要:
@wsgify
def app2(request):
res = Response()
res.body = b"Hello World"
return res
class Application: # 或者封装成类,以便增强功能。
@wsgify
def __call__(self, request):
res = Response()
res.body = b"Hello World"
return res
即可得到之前代码的结果。装饰器可以帮你把return的值封装成Response实例返回。你可以将return值设置为:Response,字符串,bytes类型实例。
我们可以用一个类来代替app,增强app的功能。首先要知道一个web服务器应该有的需求如下: 不同的path路径分配到不同的函数中处理,中间可以有多个拦截器。 我们先一步一步来实现上图所述的web框架。
我们先一步一步来实现上图所述的web框架。
实现路由
路由即不同的URL访问不同的资源,对于动态网页来说不同路径对应不同应用程序;静态网页则对应静态文件。因此实现路由是web框架的第一步。 我们设置四个路由:
路由内容/hello word/pythonhello python/bossthis boss’s room其他404其中404 我们采用webob.exc中的异常模块HTTPNotFound。 首先我们要将路由,和app分别设定类,因为各有各的功能,最好不要混在一起,不方便使用和升级。简单实现代码如下:
from wsgiref.validate import validator
from wsgiref.simple_server import make_server
from webob import Request,Response
from webob.dec import wsgify
from webob.exc import HTTPNotFound
class Router:
routertables = { }
@classmethod
def register(cls, path):
def _wrapper(handler):
cls.routertables[path] = handler
return handler
return _wrapper
class Application:
def __init__(self):
self.router = Router()
@wsgify
def __call__(self, request: Request):
try:
return self.router.routertables[request.path](request)
except:
raise HTTPNotFound
@Router.register('/')
def indexhandler(request):
return 'hello word'
@Router.register('/python')
def pythonhandler(request):
return 'hello python'
@Router.register('/boss')
def indexhandler(request):
return 'this boss\'s room'
validator_app = validator(Application())
with make_server('127.0.0.1', 9000, validator_app) as httpd:
print("Listening on port 9000....")
httpd.serve_forever()
运行正常,到此基本实现了路由功能,但是我们还需要加入正则表达式,以更加灵活和流畅的方式实现路由匹配。
路由的正则匹配
先简单复习一下正则表达式: 模式字符串使用特殊的语法来表示一个正则表达式。 字母和数字表示他们自身。一个正则表达式模式中的字母和数字匹配同样的字符串。 多数字母和数字前加一个反斜杠时会拥有不同的含义。 标点符号只有被转义时才匹配自身,否则它们表示特殊的含义。 反斜杠本身需要使用反斜杠转义。 由于正则表达式通常都包含反斜杠,所以你最好使用原始字符串来表示它们。模式元素(如 r’/t’,等价于’//t’)匹配相应的特殊字符。 下表列出了正则表达式模式语法中的特殊元素。如果你使用模式的同时提供了可选的标志参数,某些模式元素的含义会改变。
表达式描述^匹配字符串的开头$匹配字符串的末尾.匹配任意字符,除了换行符,当re.DOTALL标记被指定时,则可以匹配包括换行符的任意字符。[…]用来表示一组字符,单独列出:[amk] 匹配 ‘a’,‘m’或’k’[^…]不在[]中的字符:[^abc] 匹配除了a,b,c之外的字符。re*匹配0个或多个的表达式。re+匹配1个或多个的表达式。?非贪婪方式,尽可能的少,如*?,+?,??,{n,}?,{n,m}?re{ n,}精确匹配至少n个前面表达式。re{ n, m}匹配 n 到 m 次由前面的正则表达式定义的片段,贪婪方式a| b匹配a或b(re)匹配括号内的表达式,也表示一个组(?Pre)匹配括号内的表达式,表示一个组,组名是name(?:re)不产生分组,如(?:w(?#…)注释.(?= re)断言,如f(?=oo),断言f右边必有oo,返回匹配的f,不返回oo(?同上\w匹配字母数字,包括中文,Unicode字符,下划线\W匹配非字母数字,同上\s匹配一位任意空白字符,等价于 [\t\n\r\f].\S匹配1位任意非空字符\d匹配任意数字,等价于 [0-9].\D匹配任意非数字\A匹配字符串开始\Z匹配字符串结束,如果是存在换行,只匹配到换行前的结束字符串。\z匹配字符串结束\G匹配最后匹配完成的位置。\b匹配一个单词边界,也就是指单词和空格间的位置。例如, ‘er\b’ 可以匹配"never" 中的 ‘er’,但不能匹配 “verb” 中的 ‘er’。\B匹配非单词边界。‘er\B’ 能匹配 “verb” 中的 ‘er’,但不能匹配 “never” 中的 ‘er’。\n, \t, 等.匹配一个换行符。匹配一个制表符。\1…\9匹配第n个分组的子表达式。\10匹配第n个分组的子表达式,如果它经匹配。否则指的是八进制字符码的表达式。 方法作用compile编译正则表达式match从头匹配,只匹配一次,返回match对象,Nonesearch只匹配一次,返回match对象fullmatch完全匹配,返回match对象findall从头找,返回所有匹配的元素列表finditer同上,返回匹配的match对象组成的迭代器用正则表达式为了接下来做分级匹配铺垫。之前用的字典储存匹配路径和应用,并不适用于分级匹配,所以我们改用列表,尝试着做一些改动,加入正则表达式分组。 改动如下:
class Router:
routertables = []
@classmethod
def register(cls, path):
def _wrapper(handler):
cls.routertables.append((re.compile(path), handler))
return handler
return _wrapper
class Application:
def __init__(self):
self.router = Router()
@wsgify
def __call__(self, request: Request):
for path, handler in self.router.routertables:
if path.match(request.path):
request.groups = path.match.groups() # 或者groupdict()
request.groupdict = matcher.groupdict() # 为request动态增加属性
return handler(request)
raise HTTPNotFound('猜猜我在哪儿?')
@Router.register(r'^/(?P\d+)')
@Router.register('/')
def indexhandler(request):
print(request.groupdict)
return 'hello word'
路由分组
通常我们不仅仅需要一级目录,还需要二级,甚至三级目录。在这里我们只做一级目录的映射。 因此,之前所做的注册函数已经满足不了需求,如何将一个个前缀和URL联系,我们将每一个前缀都用Router实例化,不同的前缀对应不同的Router实例,以达到管理profix下的URL的目的。做到路由类管理URL,app类管理程序调用,并将方法属性化。 实现代码如下:
from wsgiref.validate import validator
from wsgiref.simple_server import make_server
from webob import Request,Response
from webob.dec import wsgify
from webob.exc import HTTPNotFound
import re
class Attrdict:
def __init__(self, dic:dict):
self.__dict__.update(dic if dic else {})
def __setattr__(self, key, value):
raise HTTPNotFound('dont touch it')
def __repr__(self):
return '{}'.format(self.__dict__)
def __len__(self):
return len(self.__dict__)
class Router:
def __init__(self, prefix):
self.prefix = prefix
self.routertables = []
def register(self, path, *methods):
def _wrapper(handler):
self.routertables.append(
(tuple(map(lambda x: x.upper(), methods)), re.compile(path), handler)
)
return handler
return _wrapper
def get(self, path):
return self.register(path, 'GET')
def post(self, path):
return self.register(path, 'post')
def match(self, request: Request):
if not request.path.startswith(self.prefix):
return None
for methods, path, handler in self.routertables:
if not methods or request.method in methods:
matcher = path.match(request.path) # 先match一次原地址,如果可以说明是直接用prefix访问
if matcher:
request.groups = matcher.groups()
request.groupdict = Attrdict(matcher.groupdict())
return handler(request)
matcher = path.match(request.path.replace(self.prefix, '', 1)) # 再match一次去掉prefix的路径
if matcher:
request.groups = matcher.groups()
request.groupdict = Attrdict(matcher.groupdict())
return handler(request)
index = Router('/')
py = Router('/python')
bos = Router('/boss')
class Application:
_router = []
@classmethod
def routers(cls, *routers):
for router in routers:
cls._router.append(router)
@wsgify
def __call__(self, request: Request):
for router in self._router:
response = router.match(request)
if response:
return response
raise HTTPNotFound('你看不到我')
Application.routers(index, py, bos)
@index.register(r'^/(?P\d+)$')
@index.register(r'^/$')
def indexhandler(request):
return 'hello word'
@py.get('^/python$')
def pythonhandler(request):
return 'hello python'
@py.get('^/(?P\d+?)$')
def pymore(request):
id = request.groupdict.id if request.groupdict else ''
return 'hey {} are in python room'.format(id)
@bos.register('^/boss$', 'get')
def boss(request):
return 'this boss\'s room'
@bos.get('^/(?P\d+?)$')
def bossmore(request):
id = request.groupdict.id if request.groupdict else ''
return 'hey {} are in boss room'.format(id)
validator_app = validator(Application())
with make_server('127.0.0.1', 9000, validator_app) as httpd:
print("Listening on port 9000....")
httpd.serve_forever()
当然我们也可以将prefix的下属路径交给应用程序去分辨和执行。
正则表达式的化简
之前写的正则表达式不太适合于生产环境中,URL需要规范,尤其是对restful风格。之前写的是/boss/12314,第一段是业务,第二段是id,从CSDN博客也可以看出/mdeditor/100533324。 如何将路径规范化? 尝试按照/{name:str}/{id:int}这种方式将路径规范化。 首先要对类型进行归纳,将类型映射到正则表达式。 如下:
TYPEPATTERNS = {
'str': r'[^/]+',
'word': r'/w+',
'int': r'[+-]?\d+',
'float': r'[+-]?\d+\.d+',
'any': r'.+'
}
TYPECAST = {
'str': str,
'word': str,
'int': int,
'float': float,
'any': str
}
转换/student/{name:str}/{id:int}字符串,使用正则表达式
(\{([^\{\}]+):([^\{\}]+)\})
search整个字符串,匹配{name:str}/{id:int},替换为目标正则表达式。首先想到的是sub函数,但是sub函数的局限性太大,无法增加需要捕获数据类型。于是我们手写一个类似于sub函数的方法。整合过后,代码如下:
class Attrdict:
def __init__(self, dic: dict):
self.__dict__.update(dic if dic else {})
def __setattr__(self, key, value):
raise HTTPNotFound('dont touch it')
def __repr__(self):
return '{}'.format(self.__dict__)
def __len__(self):
return len(self.__dict__)
class Router:
reg = re.compile(r'\{([^\{\}]+):([^\{\}]+)\}')
TYPEPATTERNS = {
'str': r'[^/]+',
'word': r'/w+',
'int': r'[+-]?\d+',
'float': r'[+-]?\d+\.d+',
'any': r'.+'
}
TYPECAST = {
'str': str,
'word': str,
'int': int,
'float': float,
'any': str
}
def parser(self, path): # 注册的时候替换,不然无法匹配path路径
start = 0
types = {}
temp = ''
matchers = self.reg.finditer(path)
for i, matcher in enumerate(matchers):
name = matcher.group(1)
t = matcher.group(2)
types[name] = self.TYPECAST.get(t, str) # 如果group2是空,默认为str
# 把原字符串替换,并返回回去
temp += path[start:matcher.start()]
temp += '(?P{})'.format(
name,
self.TYPEPATTERNS.get(t, self.TYPEPATTERNS['str'])
)
start = matcher.end()
else:
temp += path[start:]
return temp, types
def __init__(self, prefix):
self.prefix = prefix
self.routertables = []
def register(self, path, *methods):
def _wrapper(handler):
newpath, types = self.parser(path) # 在注册的时候调用parser
self.routertables.append(
(tuple(map(lambda x: x.upper(), methods)), re.compile(newpath), types, handler)
)
return handler
return _wrapper
def get(self, path):
return self.register(path, 'GET')
def post(self, path):
return self.register(path, 'post')
def match(self, request: Request):
if not request.path.startswith(self.prefix):
return None
for methods, path, type, handler in self.routertables:
if not methods or request.method in methods:
matcher = path.match(request.path) # 先match一次原地址,如果可以说明是直接用prefix访问
if matcher:
newdict = {}
for k,v in matcher.groupdict().items():
newdict[k] = type[k](v)
request.groups = matcher.groups()
request.groupdict = Attrdict(newdict)
return handler(request)
matcher = path.match(request.path.replace(self.prefix, '', 1)) # 再match一次去掉prefix的路径
if matcher:
newdict = {}
for k, v in matcher.groupdict().items():
newdict[k] = type[k](v)
request.groups = matcher.groups()
request.groupdict = Attrdict(newdict)
return handler(request)
index = Router('/')
py = Router('/python')
bos = Router('/boss')
class Application:
_router = []
@classmethod
def routers(cls, *routers):
for router in routers:
cls._router.append(router)
@wsgify
def __call__(self, request: Request):
for router in self._router:
response = router.match(request)
if response:
return response
raise HTTPNotFound('你看不到我')
Application.routers(index, py, bos)
@index.register(r'^/{id:int}')
@index.register(r'^/$')
def indexhandler(request):
return 'hello word'
@py.get('^/python$')
def pythonhandler(request):
return 'hello python'
@py.get('^/{id:int}$')
def pymore(request):
id = request.groupdict.id if request.groupdict else ''
return 'hey {} are in python room'.format(id)
@bos.register('^/boss$', 'get')
def boss(request):
return 'this boss\'s room'
@bos.get('^/{id:int}')
def bossmore(request):
id = request.groupdict.id if request.groupdict else ''
return 'hey {} are in boss room'.format(id)
validator_app = validator(Application())
with make_server('127.0.0.1', 9000, validator_app) as httpd:
print("Listening on port 9000....")
httpd.serve_forever()
这里一级路径访问并没有很多元素,我们并不需要使用字典。
模板、拦截器、json,打包,异常处理
目前我们依旧在框架中返回的是字符串,这些字符串被webob包装成response对象,就是http响应正文;但是此时数据和数据格式(即html)混合在一起了,是否可以将数据和格式分离? 我们可以用简单的html模板,在里面采用和刚才规范化路径的方式一样的方法,在html里写入有一定格式的字符串,将数据填充的指定位置,然后生成新的html返回。 我们采用Jinja2(知识是世界的),其设计思路来自于Django模板引擎。 官方网站:http://jinja.pocoo.org/docs/2.10/ 安装采用pip即可。 Jinja的简单使用 将模块建立如下图:
from jinja2 import Environment, FileSystemLoader
env = Environment(
# loader=PackageLoader('webarch', 'templates') # 包的位置,和index的包名
loader=FileSystemLoader('templates') # 在同一级 templates和template. 与webarch在哪儿没关系,建议使用这个。出错也是路径出问题。
)
d = {
'userlist': [
(1, 'bilibili', 10),
(3, 'li', 18),
(9, 'huang', 26)
]
}
template = env.get_template('index.html')
html = template.render(**d)
print(html)
index.html
this is title
显示数据
{% for name,id,age in userlist %} # 循环输出
- {{loop.index}} {{id}} {{name}} {{age}}
{% endfor %}
在原有代码中增加:
from jinja2 import Environment, FileSystemLoader, PackageLoader
def render(name, data):
env = Environment(
# loader=PackageLoader('webarch', 'templates') # 包的位置,和index的包的名字,用绝对路径,不然容易报错
loader=FileSystemLoader(r'C:\Users\Administrator\PycharmProjects\untitled\excercise\webarch/templates') # 用绝对路径
)
template = env.get_template(name)
return template.render(**data) # html
@bos.register('^/boss$', 'get')
def boss(request):
user = {
'userlist': [
('bilibili', 1, 10),
('li', 3, 18),
('huang', 9, 26)
]
}
return render('index.html', user)
运行正常。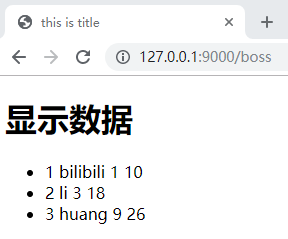 还差拦截器实现和json,我们先简单了解一下。拦截器可以分为:
还差拦截器实现和json,我们先简单了解一下。拦截器可以分为:
- 请求时拦截
- 响应时拦截 前两个为拦截点不同,后两个为影响区域不同
- 全局拦截:在实例中的app中拦截
- 局部拦截:在router中拦截 可以在app或者router类中加入拦截器,或者使用Mixin,我们区分一下,router拦截器是会根据实例不同而有不同的表现,适合直接加入router中,而app的拦截器适合使用Mixin。 webob.response.Response支持json,在Response中加入关键字json=d即可。 json就是一种轻量级的数据交换格式。可以完全独立于语言,适合于网络传输,以增加传输效率。因此html常用json来进行网络传输。 我们可以通过模块化,和打包,轻松的将写好的完整代码,打包,安装。至此代码全部编写完毕。





关于CSDN软件工程师能力认证
CSDN软件工程师能力认证(以下简称C系列认证)是由中国软件开发者网CSDN制定并推出的一个能力认证标准。C系列认证历经近一年的实际线下调研、考察、迭代、测试,并梳理出软件工程师开发过程中所需的各项技术技能,结合企业招聘需求和人才应聘痛点,基于公开、透明、公正的原则,甑别人才时确保真实业务场景、全部上机实操、所有过程留痕、存档不可篡改。C系列认证的宗旨是让一流的技术人才凭真才实学进大厂拿高薪,同时为企业节约大量招聘与培养成本,使命是提升高校大学生的技术能力,为行业提供人才储备,为国家数字化战略贡献力量。
了解详情可点击:CSDN软件工程师能力认证介绍
本文出处:https://blog.csdn.net/weixin_43149144/article/details/100533324?ops_request_misc=&request_id=&biz_id=102&utm_term=python%20web框架&utm_medium=distribute.pc_search_result.none-task-blog-2~all~sobaiduweb~default-2-100533324.pc_search_result_before_js&spm=1018.2226.3001.4187

