
- SLS机器学习介绍(01):时序统计建模
- SLS机器学习介绍(02):时序聚类建模
- SLS机器学习介绍(03):时序异常检测建模
- SLS机器学习介绍(04):规则模式挖掘
第一篇文章SLS机器学习介绍(01):时序统计建模上周更新完,一下子炸出了很多潜伏的业内高手,忽的发现集团内部各个业务线都针对时序分析存在一定的需求。大家私信问我业务线上的具体方法,在此针对遇到的通用问题予以陈述(权且抛砖引玉,希望各位大牛提供更好的建议和方法):
-
数据的高频抖动如何处理?
- 在业务需求能满足的条件下,进可能的对数据做聚合操作,用窗口策略消除抖动
- 若不能粗粒度的聚合,我一般会选择窗口滤波操作,在针对滤波后的数据进行一次去异常点操作
- 改变检测策略,将问题变成一个回归问题,引入多维度特征,对目标进行预测
-
历史训练数据如何选择?
- 针对自己的时序数据,需要先进行简单的摸底操作,选择合适的模型,是不是有明显的周期?是不是有明显的趋势?
-
这么多方法该如何选择?
- 针对单指标预测的方法,需要采用多种算法模型进行预测,将得到的结果也要集成起来,降低误报操作
- 可以针对历史上的全量报警样本,设计一套报警聚合规则,在一定容忍度的条件下得到较好的结果
在大型互联网企业中,对海量KPI(关键性能指标)进行监控和异常检测是确保服务质量和可靠性的重要手段。基于互联网的服务型企业(如线上购物、社交网络、搜索引擎等)通过监控各种系统及应用的数以万计的KPI(如CPU利用率、每秒请求量等)来确保服务可靠性。KPI上的异常通常反映了其相关应用上可能出现故障,如服务器故障、网络负载过高、外部攻击等。因而,异常检测技术被广泛用于及时检测异常事件以达到快速止损的目的。
问题背景大多数异常检测算法(如雅虎的EDAGS,Twitter的BreakoutDetection,FaceBook的prophet)都需要为每条KPI单独建立异常检测模型,在面对海量KPI时,会产生极大的模型选择、参数调优、模型训练及异常标注开销。幸运的是,由于许多KPI之间存在隐含的关联性,它们是较为相似的。如果我们能够找到这些相似的KPI(例如在一个负载均衡的服务器集群中每个服务器上的每秒请求量KPI是相似的),将它们划分为若干聚类簇,则可以在每个聚类簇中应用相同的异常检测模型,从而大大降低各项开销。
序列聚类建模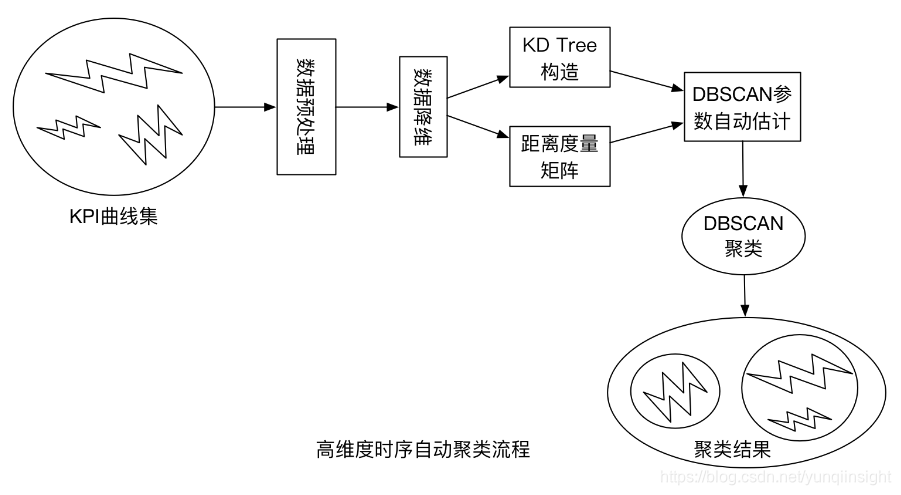
在同一个业务指标的前提下:
- 查找出当前时序序列中有哪些相似的曲线形态?(单条曲线的多形态分解)
- 多条KPI指标曲线有哪些曲线的形态类似?(N条曲线形态聚类)
本文主要从时间对齐的多条时序KPI中进行相似性度量,时间点上的指标的相似性和时序曲线形态的相似性
- 时间点聚类(时间上的相似性) 1.1 闵可夫斯基距离:衡量数值点之间距离的一种常见的方法,假设P=(x1,x2,...,xn)和Q=(y1,y2,...,yn),则具体的公式如下:
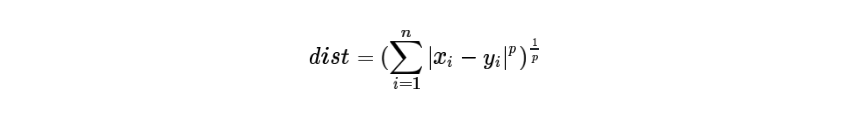
当p=1时,表示曼哈顿距离;p=2时,表示欧几里得距离;当p趋近于无穷大时,该距离转换为切比雪夫距离,具体如下式所式:
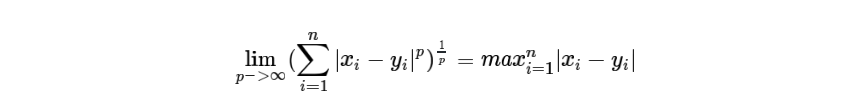
闵可夫斯基距离比较直观,但是它与数据的分布无关,具有一定的局限性,如果x方向的幅值远远大于y方向的幅值,这个距离公式就会过度方法x维度的作用。因此在加算前,需要对数据进行变换(去均值,除以标准差)。这种方法在假设数据各个维度不相关的情况下,利用数据分布的特性计算出不同的距离。如果数据维度之间数据相关,这时该类距离就不合适了!
1.2 马氏距离:若不同维度之间存在相关性和尺度变换等关系,需要使用一种变化规则,将当前空间中的向量变换到另一个可以简单度量的空间中去测量。假设样本之间的协方差矩阵是Σ,利用矩阵分解(LU分解)可以转换为下三角矩阵和上三角矩阵的乘积:Σ=LLT。消除不同维度之间的相关性和尺度变换,需要对样本x做如下处理:z=L−1(x−μ),经过处理的向量就可以利用欧式距离进行度量。
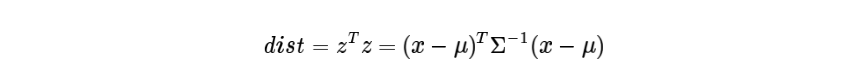
- 形状之间的相似性(空间上的结构相似性) 2.1 编辑距离
如何去比较两个不同长度的字符串的相似性?给定两个字符串,由一个转成另一个所需要的最小编辑操作,其中需要有三个操作,相同位置字符的替换、对字符串中某个位置进行插入与删除。具体的递归表达式如下:
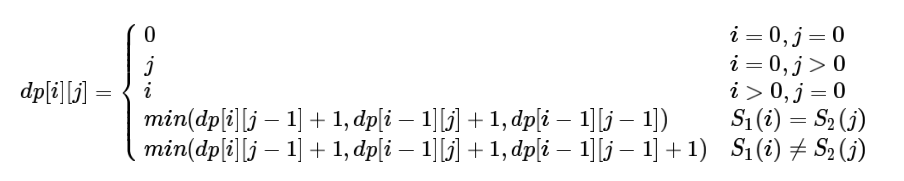
2.2 DTW(Dynamic Time Warpping)距离 动态时间规整(Dynamic Time Warping;DTW)是一种将时间规整和距离测度相结合的一种非线性规整技术。主要思想是把未知量均匀地伸长或者缩短,直到与参考模式的长度一致,在这一过程中,未知量的时间轴要不均匀地扭曲或弯折,以使其特征与参考模式特征对正。 DTW(Dynamic Time Warping)距离的计算过程如下: 假设,两个时间序列Q和C,Q={q1,q2,…,qn},C={c1,c2,…,cm}。构造一个(n, m)的矩阵,第(i, j)单元记录两个点(qi,cj)之间的欧氏距离,d(qi,cj)=|qi−cj|。一条弯折的路径W,由若干个彼此相连的矩阵单元构成,这条路径描述了Q和C之间的一种映射。设第k个单元定义为wk=(i,j)k,则w={w1,w2,w3,...,wK},max(n,m)
最近更新
- 深拷贝和浅拷贝的区别(重点)
- 【Vue】走进Vue框架世界
- 【云服务器】项目部署—搭建网站—vue电商后台管理系统
- 【React介绍】 一文带你深入React
- 【React】React组件实例的三大属性之state,props,refs(你学废了吗)
- 【脚手架VueCLI】从零开始,创建一个VUE项目
- 【React】深入理解React组件生命周期----图文详解(含代码)
- 【React】DOM的Diffing算法是什么?以及DOM中key的作用----经典面试题
- 【React】1_使用React脚手架创建项目步骤--------详解(含项目结构说明)
- 【React】2_如何使用react脚手架写一个简单的页面?

