
如今,机器已经能够在理解、识别图像中的特征和对象等领域实现99%级别的准确率。生活中,我们每天都会运用到这一点,比如,智能手机拍照的时候能够识别脸部、在类似于谷歌搜图中搜索特定照片、从条形码扫描文本或扫描书籍等。造就机器能够获得在这些视觉方面取得优异性能可能是源于一种特定类型的神经网络——卷积神经网络(CNN)。如果你是一个深度学习爱好者,你可能早已听说过这种神经网络,并且可能已经使用一些深度学习框架比如caffe、TensorFlow、pytorch实现了一些图像分类器。然而,这仍然存在一个问题:数据是如何在人工神经网络传送以及计算机是如何从中学习的。为了从头开始获得清晰的视角,本文将通过对每一层进行可视化以深入理解卷积神经网络。

在学习卷积神经网络之前,首先要了解神经网络的工作原理。神经网络是模仿人类大脑来解决复杂问题并在给定数据中找到模式的一种方法。在过去几年中,这些神经网络算法已经超越了许多传统的机器学习和计算机视觉算法。“神经网络”是由几层或多层组成,不同层中具有多个神经元。每个神经网络都有一个输入和输出层,根据问题的复杂性增加隐藏层的个数。一旦将数据送入网络中,神经元就会学习并进行模式识别。一旦神经网络模型被训练好后,模型就能够预测测试数据。
另一方面,CNN是一种特殊类型的神经网络,它在图像领域中表现得非常好。该网络是由YanLeCunn在1998年提出的,被应用于数字手写体识别任务中。其它应用领域包括语音识别、图像分割和文本处理等。在CNN被发明之前,多层感知机(MLP)被用于构建图像分类器。图像分类任务是指从多波段(彩色、黑白)光栅图像中提取信息类的任务。MLP需要更多的时间和空间来查找图片中的信息,因为每个输入元素都与下一层中的每个神经元连接。而CNN通过使用称为局部连接的概念避免这些,将每个神经元连接到输入矩阵的局部区域。这通过允许网络的不同部分专门处理诸如纹理或重复模式的高级特征来最小化参数的数量。下面通过比较说明上述这一点。
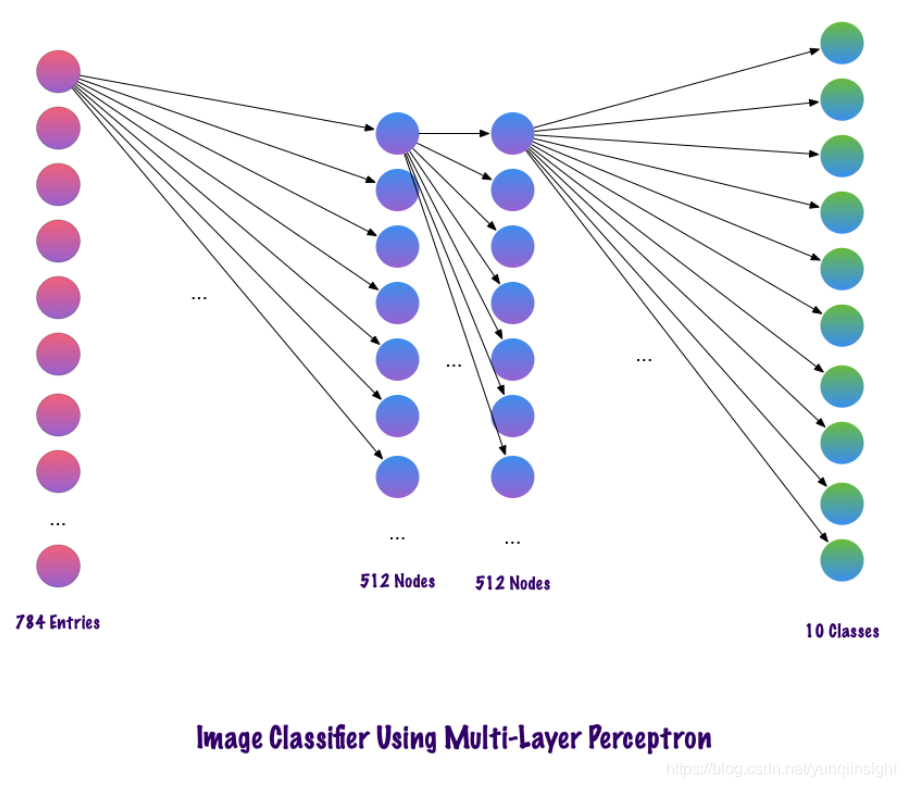
比较MLP和CNN因为输入图像的大小为28x28=784(MNIST数据集),MLP的输入层神经元总数将为784。网络预测给定输入图像中的数字,输出数字范围是0-9。在输出层,一般返回的是类别分数,比如说给定输入是数字“3”的图像,那么在输出层中,相应的神经元“3”与其它神经元相比具有更高的类别分数。这里又会出现一个问题,模型需要包含多少个隐藏层,每层应该包含多少神经元?这些都是需要人为设置的,下面是一个构建MLP模型的例子:
Num_classes = 10
Model = Sequntial()
Model.add(Dense(512, activation=’relu’, input_shape=(784, )))
Model.add(Dropout(0.2))
Model.add(Dense(512, activation=’relu’))
Model.add(Dropout(0.2))
Model.add(Dense(num_classes, activation=’softmax’))上面的代码片段是使用Keras框架实现(暂时忽略语法错误),该代码表明第一个隐藏层中有512个神经元,连接到维度为784的输入层。隐藏层后面加一个dropout层,丢弃比例设置为0.2,该操作在一定程度上克服过拟合的问题。之后再次添加第二个隐藏层,也具有512谷歌神经元,然后再添加一个dropout层。最后,使用包含10个类的输出层完成模型构建。其输出的向量中具有最大值的该类将是模型的预测结果。
这种多层感知器的一个缺点是层与层之间完全连接,这导致模型需要花费更多的训练时间和参数空间。并且,MLP只接受向量作为输入。
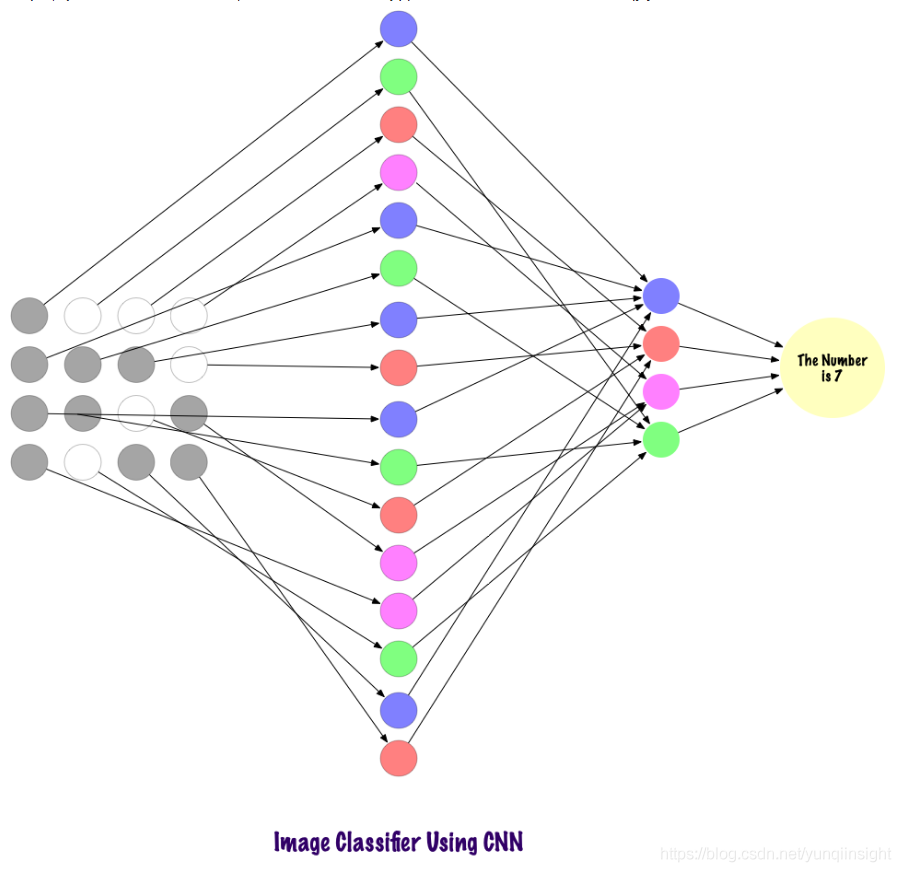
卷积使用稀疏连接的层,并且其输入可以是矩阵,优于MLP。输入特征连接到局部编码节点。在MLP中,每个节点都有能力影响整个网络。而CNN将图像分解为区域(像素的小局部区域),每个隐藏节点与输出层相关,输出层将接收的数据进行组合以查找相应的模式。
看着图片并解释其含义,这对于人类来说很简单的一件事情。我们生活在世界上,我们使用自己的主要感觉器官(即眼睛)拍摄环境快照,然后将其传递到视网膜。这一切看起来都很有趣。现在让我们想象一台计算机也在做同样的事情。
在计算机中,使用一组位于0到255范围内的像素值来解释图像。计算机查看这些像素值并理解它们。乍一看,它并不知道图像中有什么物体,也不知道其颜色。它只能识别出像素值,图像对于计算机来说就相当于一组像素值。之后,通过分析像素值,它会慢慢了解图像是灰度图还是彩色图。灰度图只有一个通道,因为每个像素代表一种颜色的强度。0表示黑色,255表示白色,二者之间的值表明其它的不同等级的灰灰色。彩色图像有三个通道,红色、绿色和蓝色,它们分别代表3种颜色(三维矩阵)的强度,当三者的值同时变化时,它会产生大量颜色,类似于一个调色板。之后,计算机识别图像中物体的曲线和轮廓。。
下面使用PyTorch加载数据集并在图像上应用过滤器:
# Load the libraries
import torch
import numpy as np
from torchvision import datasets
import torchvision.transforms as transforms
# Set the parameters
num_workers = 0
batch_size = 20
# Converting the Images to tensors using Transforms
transform = transforms.ToTensor()
train_data = datasets.MNIST(root='data', train=True,
download=True, transform=transform)
test_data = datasets.MNIST(root='data', train=False,
download=True, transform=transform)
# Loading the Data
train_loader = torch.utils.data.DataLoader(train_data, batch_size=batch_size,
num_workers=num_workers)
test_loader = torch.utils.data.DataLoader(test_data, batch_size=batch_size,
num_workers=num_workers)
import matplotlib.pyplot as plt
%matplotlib inline
dataiter = iter(train_loader)
images, labels = dataiter.next()
images = images.numpy()
# Peeking into dataset
fig = plt.figure(figsize=(25, 4))
for image in np.arange(20):
ax = fig.add_subplot(2, 20/2, image+1, xticks=[], yticks=[])
ax.imshow(np.squeeze(images[image]), cmap='gray')
ax.set_title(str(labels[image].item()))

下面看看如何将单个图像输入神经网络中:
img = np.squeeze(images[7])
fig = plt.figure(figsize = (12,12))
ax = fig.add_subplot(111)
ax.imshow(img, cmap='gray')
width, height = img.shape
thresh = img.max()/2.5
for x in range(width):
for y in range(height):
val = round(img[x][y],2) if img[x][y] !=0 else 0
ax.annotate(str(val), xy=(y,x),
color='white' if img[x][y]
关注
打赏
最近更新
- 深拷贝和浅拷贝的区别(重点)
- 【Vue】走进Vue框架世界
- 【云服务器】项目部署—搭建网站—vue电商后台管理系统
- 【React介绍】 一文带你深入React
- 【React】React组件实例的三大属性之state,props,refs(你学废了吗)
- 【脚手架VueCLI】从零开始,创建一个VUE项目
- 【React】深入理解React组件生命周期----图文详解(含代码)
- 【React】DOM的Diffing算法是什么?以及DOM中key的作用----经典面试题
- 【React】1_使用React脚手架创建项目步骤--------详解(含项目结构说明)
- 【React】2_如何使用react脚手架写一个简单的页面?

