
简介:作业帮是一家以科技为载体的在线教育公司,其大数据中台作为基础系统中台,主要负责建设公司级数仓,向各个产品线提供面向业务主题的数据信息。本文主要分享了作业帮基于 DeltaLake 的数据湖建设最佳实践。
作者:
刘晋 作业帮-大数据平台技术部负责人
王滨 作业帮-大数据平台技术部高级架构师
毕岩 阿里云-计算平台开源大数据平台技术专家
内容框架:
- 业务背景
- 问题&痛点
- 解决方案
- 基于 DeltaLake 的离线数仓
- 未来规划
- 致谢
作业帮是一家以科技为载体的在线教育公司。目前旗下拥有工具类产品作业帮、作业帮口算,K12直播课产品作业帮直播课,素质教育产品小鹿编程、小鹿写字、小鹿美术等,以及喵喵机等智能学习硬件。作业帮教研中台、教学中台、辅导运营中台、大数据中台等数个业务系统,持续赋能更多素质教育产品,不断为用户带来更好的学习和使用体验。其中大数据中台作为基础系统中台,主要负责建设公司级数仓,向各个产品线提供面向业务主题的数据信息,如留存率、到课率、活跃人数等,提高运营决策效率和质量。

上图为作业帮数据中台总览。主要分为三层:
- 第一层是数据产品以及赋能层
主要是基于主题数据域构建的数据工具以及产品,支撑商业智能、趋势分析等应用场景。
- 第二层是全域数据层
通过OneModel统一建模,我们对接入的数据进行了标准化建模,针对不同时效性的场景构建了业务域的主题数据,提高上层产品的使用效率和质量。
- 第三层是数据开发层
构建了一系列的系统和平台来支持公司内所有的数据开发工程,包括数据集成、任务开发、数据质量、数据服务、数据治理等。
本次分享的内容主要是面向离线数仓(天级、小时级)解决其生产、使用过程中的性能问题。
二、问题&痛点作业帮离线数仓基于 Hive 提供从 ODS 层到 ADS 层的数据构建能力,当 ADS 表生成后,会通过数据集成写入 OLAP 系统面向管理人员提供 BI 服务;此外,DWD、DWS、ADS 表,也会面向分析师提供线下的数据探查以及取数服务。

随着业务逐步发展以及对应的数据量越来越多,离线数仓系统突显如下主要问题:
- ADS 表产出延迟越来越长
由于数据量增多,从 ODS 层到 ADS 层的全链路构建时间越来越长。虽然对于非常核心的 ADS 表链路可以通过倾斜资源的模式来短期解决,但是其实这个本质上就是丢车保帅的模式,该模式无法规模化复制,影响了其他重要的 ADS 表的及时产出,如对于分析师来说,由于数据表的延迟,对于T+1的表最差需等到T+2才可以看到。
- 小时级表需求难以承接
有些场景是小时级产出的表,如部分活动需要小时级反馈来及时调整运营策略。对于这类场景,随着数据量增多、计算集群的资源紧张,小时级表很多时候难以保障及时性,而为了提高计算性能,往往需要提前预备足够的资源来做,尤其是需要小时级计算天级数据的时候,最差情况下计算资源需要扩大24倍。
- 数据探查慢、取数稳定性差
数据产出后很多时候是面向分析师使用的,直接访问 Hive 则需要几十分钟甚至小时级,完全不能接受,经常会收到用户的吐槽反馈,而采用 Presto 来加速 Hive 表的查询,由于 Presto 的架构特点,导致查询的数据表不能太大、逻辑不能太复杂,否则会导致 Presto 内存 OOM,且 Hive 已有的 UDF 和 VIEW 等在 Presto 中也没法直接使用,这也非常限制分析师的使用场景。
三、解决方案 问题分析不论是常规的 ODS 层到 ADS 层全链路产出慢、或者是面对具体表的探查取数慢,本质上都是在说 Hive 层的计算性能不足。从上述场景分析来看:
- 链路计算慢的原因:由于 Hive 不支持增量更新,而来自业务层数据源的 Mysql-Binlog 则包含大量的更新信息,因此在 ODS 这一层,就需要用增量数据和历史的全量数据做去重后形成新的全量数据,其后 DWD、DWS、ADS 均是类似的原理。这个过程带来了数据的大量重复计算,同时也带来了数据产出的延迟。
- 数据查询慢的原因:由于 Hive 本身缺少必要的索引数据,因此不论是重吞吐的计算还是希望保障分钟级延迟的查询,均会翻译为 MR-Job 进行计算,这就导致在数据快速探查场景下,查询结果产出变慢。
从上面分析来看,如果可以解决离线数仓的数据增量更新问题就可以提高链路计算的性能,而对于数据表支持索引能力,就可以在保障查询功能不降级的前提下降低查询的延迟。
- 基于 HBase+ORC 的解决方案
解决数据的更新问题,可以采用 HBase 来做。对 RowKey 设置为主键,对各列设置为 Column,这样就可以提供数据实时写入的能力。但是受限于 HBase 的架构,对于非主键列的查询性能则非常差。为了解决其查询性能,需要定期(如小时表则小时级、天级表则天级)将 HBase 的表按照特定字段排序后导出到 HDFS 并存储为 ORC 格式,但是 ORC 格式只支持单列的 min、max 索引,查询性能依然无法满足需求,且由于 HBase 的数据写入一直在持续发生,导出的时机难以控制,在导出过程中数据还可能发生变化,如我们希望导出12月11日21点前的数据作为数据表21点分区的数据就需要考虑版本数、存储容量、筛选带来的计算性能等因素,系统复杂度陡增,同时也引入了 HBase 系统增加了运维成本。
- 数据湖
数据湖实际上是一种数据格式,可以集成在主流的计算引擎(如 Flink/Spark)和数据存储(如对象存储)中间,不引入额外的服务,同时支持实时 Upsert,提供了多版本支持,可以读取任意版本的数据。
目前数据湖方案主要有 DeltaLake、Iceberg、Hudi。 我们调研了阿里云上这三种方案,其区别和特点如下:

此外,考虑到易用性(DeltaLake 语义清晰,阿里云提供全功能 SQL 语法支持,使用简单;后两者的使用门槛较高)、功能性(仅 DeltaLake 支持 Zorder/Dataskipping 查询加速)等方面,结合我们的场景综合考虑,我们最后选择 DeltaLake 作为数据湖解决方案。
四、基于 DeltaLake 的离线数仓引入 DeltaLake 后,我们的离线数仓架构如下:

首先 Binlog 通过 Canal 采集后经过我们自研的数据分发系统写入 Kafka,这里需要提前说明的是,我们的分发系统需要对 Binlog 按照 Table 级严格保序,原因下面详述。其后使用 Spark 将数据分批写入 DeltaLake。最后我们升级了数据取数平台,使用 Spark SQL 从 DeltaLake 中进行取数。
在使用 DeltaLake 的过程中,我们需要解决如下关键技术点:
流数据转批业务场景下,对于离线数仓的 ETL 任务,均是按照数据表分区就绪来触发的,如2021-12-31日的任务会依赖2021-12-30日的数据表分区就绪后方可触发运行。这个场景在 Hive 的系统上是很容易支持的,因为 Hive 天然支持按照日期字段(如dt)进行分区。但是对于 DeltaLake 来说,我们数据写入是流式写入的,因此就需要将流数据转为批数据,即某天数据完全就绪后,方可对外提供对应天级分区的读取能力。
如何界定数据完全就绪
流式数据一般会有乱序的情况,在乱序的情况下,即使采用 watermark 的机制,也只能保障一定时间范围内的数据有序,而对于离线数仓来说,数据需要100%可靠不丢。而如果我们可以解决数据源的有序性问题,那么数据就绪问题的解决就会简化很多:假如数据按照天级分区,那么当出现12-31的数据时,就可以认为12-30的数据都就绪了。
因此,我们的方案拆解为两个子问题:
- 流数据有序后界定批数据边界
- 保障流数据有序的机制
首先对于前者,总体方案如下:

- 设定数据表的逻辑分区字段 dt 以及对应的时间单位信息。

- 当 Spark 读取某一个 batch 数据后,根据上述表元数据使用数据中的 event time 生成对应的 dt 值,如数据流中 event time 的值均属于T+1,则会触发生成数据版本T的 snapshot,数据读取时根据 snapshot 找到对应的数据版本信息进行读取。
如何解决流数据的乱序问题
不论是 app-log 还是 MySQL-Binlog,对于日志本身都是有序的,以 MySQL-Binlog 举例,单个物理表的 Binlog 必然有序,但是实际业务场景下,业务系统会经常进行分库分表的使用,对于使用分表的场景,一张逻辑表 Table 会分为 Table1、Table2、……几张表,对于离线数仓的 ODS 表,则需要屏蔽掉业务侧 MySQL 分表的细节和逻辑,这样,问题就聚焦为如何解决分表场景下数据有序的问题。
- 保障分库分表,甚至不同分表在不同集群的情况下,数据写入到 Kafka 后的有序性。即写入 DeltaLake 的 Spark 从某个 topic 读取到逻辑表的数据是 partition 粒度有序的。
- 保障 ODS 表就绪的时效性,如区分无 Binlog 数据的情况下,ODS 层数据也可以按期就绪。
此处需要对原有系统进行升级改造,方案如下:
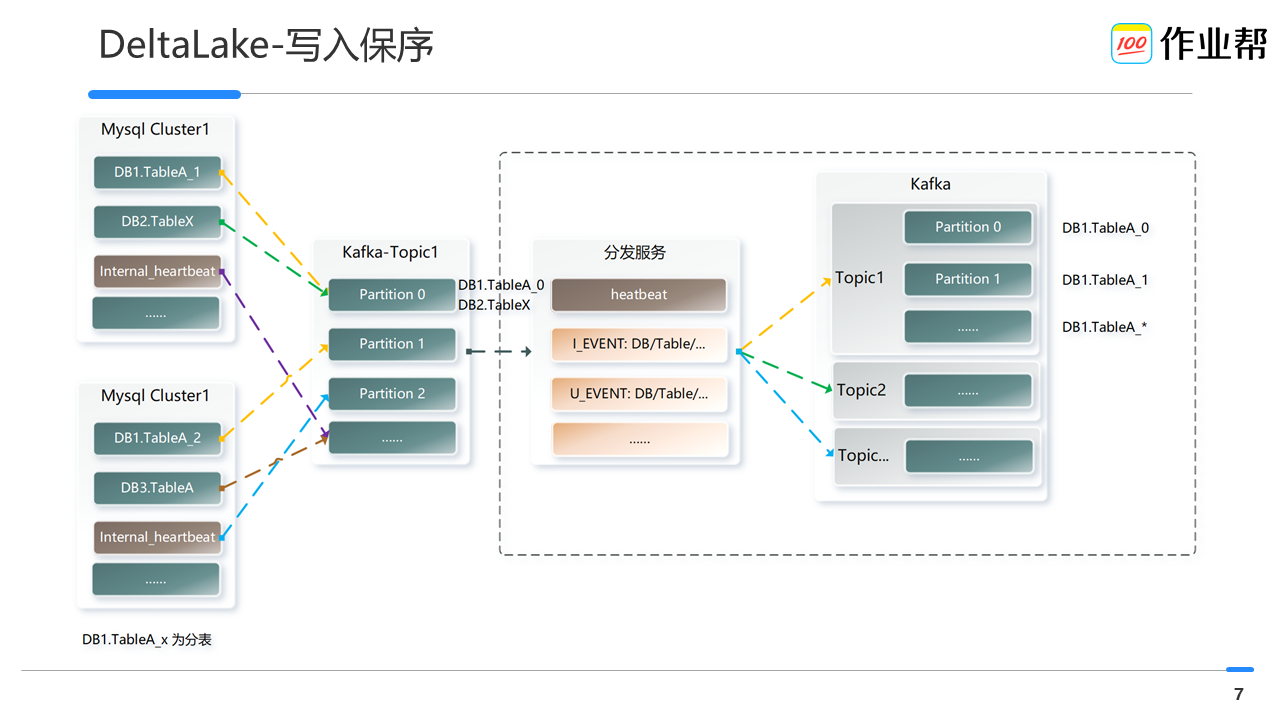
如上图所示:某个 MySQL 集群的 Binlog 经 Canal 采集后写入到特定的 Kafka-topic,但是由于写入时按照db和 Table(去分表_*后缀)做 hash 确定 partition,因此单个 partition 内部会存在多个物理表的 Binlog,对于写入 DeltaLake 来说非常不友好。考虑到对其他数据应用方的兼容性,我们新增了数据分发服务:
- 将逻辑表名(去分表_*后缀)的数据写入到对应的 topic,并使用物理表名进行 hash。保障单 partition 内部数据始终有序,单 topic 内仅包括一张逻辑表的数据。
- 在 MySQL 集群内构建了内部的心跳表,来做 Canal 采集的延迟异常监控,并基于此功能设置一定的阈值来判断当系统没有 Binlog 数据时是系统出问题了还是真的没数据了。如果是后者,也会触发 DeltaLake 进行 savepoint,进而及时触发 snapshot来保障 ODS 表的及时就绪。
通过上述方案,我们将 Binlog 数据流式的写入 DeltaLake 中,且表分区就绪时间延迟
最近更新
- 深拷贝和浅拷贝的区别(重点)
- 【Vue】走进Vue框架世界
- 【云服务器】项目部署—搭建网站—vue电商后台管理系统
- 【React介绍】 一文带你深入React
- 【React】React组件实例的三大属性之state,props,refs(你学废了吗)
- 【脚手架VueCLI】从零开始,创建一个VUE项目
- 【React】深入理解React组件生命周期----图文详解(含代码)
- 【React】DOM的Diffing算法是什么?以及DOM中key的作用----经典面试题
- 【React】1_使用React脚手架创建项目步骤--------详解(含项目结构说明)
- 【React】2_如何使用react脚手架写一个简单的页面?

