
作为一款致力于成为数字化企业「最强大脑」的服务,Azure Synapse Analysis高效高弹性的架构设计、简单易用的操作、强大的功能和澎湃的数据处理和分析能力,能够帮助我们解决与数据准备、数据管理、数据仓库、大数据和AI等方面有关的很多挑战。
我们将通过《数据“科学家”必读》系列文章带领大家全面体验Azure Synapse Analysis。本系列共分为六期内容,本篇是其中的第五期:
-
第一次亲密接触:开箱初体验,概括了解Azure Synapse Analysis的功能与价值;
-
围绕Cosmos DB自行DIY的Azure Synapse Analysis解决方案;
-
Azure Synapse Analysis与Azure Function服务的配合使用;
-
通过增量数据CDC对Azure Synapse Analysis中的数据进行更新;
-
借助Azure Data Factory工具实现数据处理水线的自动化操作;
-
借助Synapse Link的一键同步省略ETL过程,实现最新数据的直接访问。

在上一期内容中,我们已经介绍了如何在Azure Data Warehouse中拉入增量数据CDC(Change Data Capture),并对Azure Data Warehouse现有数据进行更新。本期,我们将介绍如何通过Data Factory工具将整个数据水线自动化。
我们将通过Data Factory工具将该数据处理水线实现自动化,大体思路是将前面的Data Warehouse ETL和Update通过存储过程在DW中函数化,然后通过在Data Factory中创建数据水线来调起存储过程,整个水线的触发可以通过Data Lake中新的CDC数据产生作为事件触发条件。
首先,回顾一下整个架构:
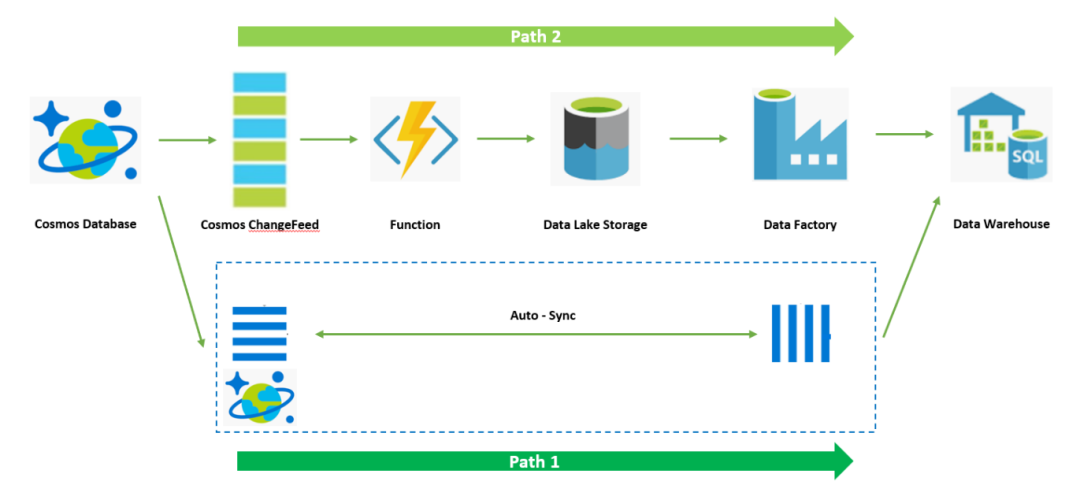
接下来开始介绍具体操作:
1. 创建存储过程,将上期获得的ELT和Update T-SQL脚本通过存储过程进行实现。

2. 创建Data Factory Pipeline。先通过Copy Activity将Data Lake中的CDC数据拷贝至Data Warehouse中的Staging Table,再通过调用存储过程实现对DW中生产表格的Update操作。此步骤可将下面的Data Factory Pipeline Json描述文件导入到Data Factory中并按照自己环境中的SQL Pool和Data Lake连接参数进行修改。

3. 创建Data Factory Pipeline触发条件,定义Data Lake CDC文件创建作为触发条件,其中blobPathBeginWith参数和scope参数替换为相应Data Lake存储参数值。

4. 通过在Cosmos中仿真数据变更操作,查看整个Pipeline工作日志。
通过上述配置,我们实现了通过Data Factory数据水线工具自动化完成CDC由数据湖导入Data Warehouse并更新Data Warehouse数据表格的工作。
目前Azure Synapse Analysis处于预览阶段,所以在内置的Data Factory中还不支持通过Managed Identity连接SQL Pool,且不支持Blob Event Trigger Pipleline。Managed Identity 问题可使用ServicePrinciple来解决,Blob Event Trigger则会在七月底得到支持,目前大家可通过手动触发的方式或者使用非Synapse Analysis内置Data Factory来实现相同逻辑。
到此为止,整个Cosmos DB ChangeFeed数据完整的处理流程已经完毕。作为本系列的最后一篇,下期将介绍直通模式Synapse Link实现Cosmos DB一跳对接Data Warehouse的方案。

