点击上方“3D视觉工坊”,选择“星标”
干货第一时间送达

几周前,当在全球速卖通(AliExpress)购物时,偶然发现了一个很棒的Maixduino设备。它宣称自带RISC V架构和KPU (KPU是一个通用神经网络处理器)。其不同规格如下;
-
CPU: RISC-V双核64位,带FPU
-
图像识别:QVGA@60fps / VGA@30fps
-
芯片功耗< 300mW

说实话,这个单位很旧了,最近才开始关注。考虑到我对边缘计算的兴趣,我想为一个对象检测示例提供一个完整的端到端指南。这个例子是基于这篇文章:https://www.instructables.com/Object-Detection-With-Sipeed-MaiX-BoardsKendryte-K/
但是,我将全面介绍如何收集图像并对它们进行注释。如果你想知道什么是边缘计算,请阅读下面的文章。
-
https://medium.com/swlh/what-is-edge-computing-d27d15f843e
让我们尝试建立一个图像检测程序,将能够检测出苹果和香蕉。有了检测器,你可以变得更有创造力。在接下来的讨论中,我们将讨论所需的工具和库。

迁移学习是指我们使用预先训练的模型来进一步专业化。简单地说,就是用自己的分类层(或更多层)替换训练过的模型的最后一个预测层。然后冻结除你的自定义层(或一些经过预训练的层)以外的所有层。然后训练网络,以便使用预先训练过的模型的特性来微调你的层,以预测你想要的类。
不幸的是,目前我们要训练的网络没有任何预先训练过的模型。因此,我们将从头开始训练。但这将是一个有趣的实验!
准备数据我们需要按以下格式准备数据。首先,我们需要有苹果和香蕉的图像。同时,我们需要对它们进行注释,以确定每个水果可能在图像中的位置。这就是目标分类和检测之间的区别所在。我们需要说出物体在哪里。为此,你需要以下工具。
-
tzutalin / labelImg :https://github.com/tzutalin/labelImg
LabelImg是一个图形图像标注工具。它是用Python编写的,使用Qt作为图形界面…
或者你可以使用我的工具使用你的背景和对象图像生成注释图像(例如:来自Kaggle的Fruit 360的图像)。阅读更多:
用于对象检测的注释器:https://anuradhawick.medium.com/annotator-for-object-detection-950fd799b651
在我的例子中,我使用以下程序,因为我从网络摄像头捕获。选择简单的方法。下面的程序是用Nvidia jetson nano get started容器编译的。
dusty-nv / camra-capture :https://github.com/dusty-nv/camera-capture
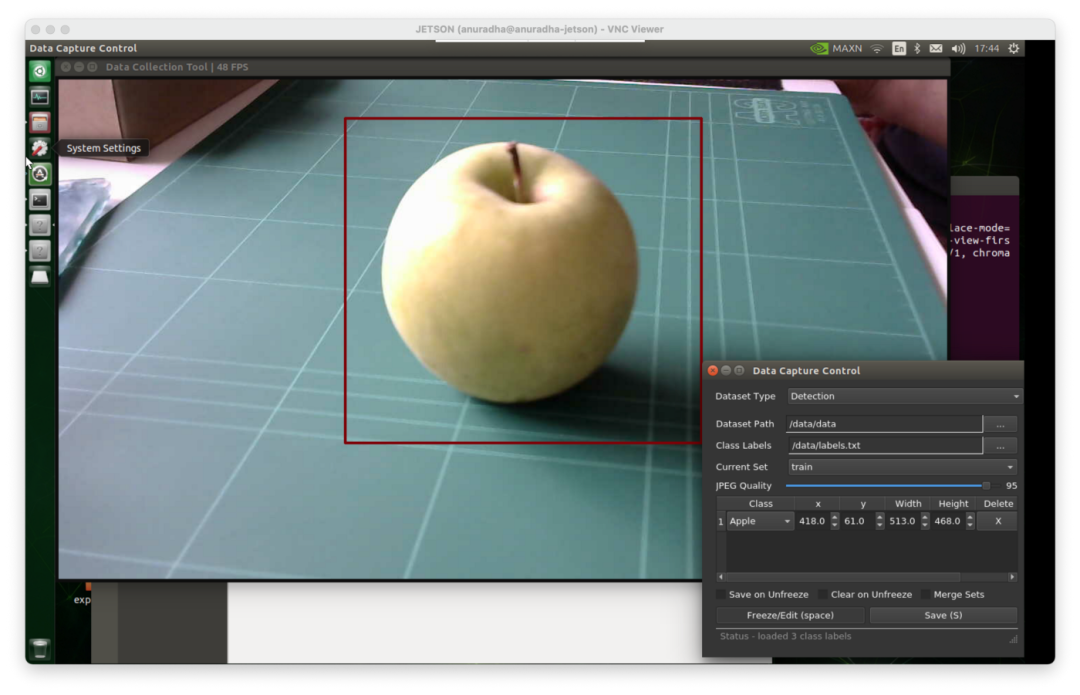
我们想训练我们的模型,这样它们就可以在maxduino设备上运行。为此,我们可以使用以下存储库。它对模型层进行了所有必要的修改,以适应K210处理器的体系结构。克隆并安装所需的依赖项。所有说明可在以下链接获得;
AIWintermuteAI / aXeleRate :https://github.com/AIWintermuteAI/aXeleRate
aXeleRate简化了训练,并将计算机视觉模型转换为在各种硬件平台上运行……
我们需要将我们的训练数据组织如下;
path-to/data ---anns # store the training annotations ---imgs # relevant images for the training ---anns_val # validation annotations ---imgs_val # validation images
现在我们需要创建一个配置。json设置训练选项。对于我们的例子,它应该如下所示:
{
"model" : {
"type": "Detector",
"architecture": "MobileNet7_5",
"input_size": [224,224],
"anchors": [0.57273, 0.677385, 1.87446, 2.06253, 3.33843, 5.47434, 7.88282, 3.52778, 9.77052, 9.16828],
"labels": ["Apple", "Banana"],
"coord_scale" : 1.0,
"class_scale" : 1.0,
"object_scale" : 5.0,
"no_object_scale" : 1.0
},
"weights" : {
"full": "",
"backend": "imagenet"
},
"train" : {
"actual_epoch": 50,
"train_image_folder": "data/imgs",
"train_annot_folder": "data/anns",
"train_times": 2,
"valid_image_folder": "data/imgs_val",
"valid_annot_folder": "data/anns_val",
"valid_times": 2,
"valid_metric": "mAP",
"batch_size": 4,
"learning_rate": 1e-4,
"saved_folder": "obj_detector",
"first_trainable_layer": "",
"augumentation": true,
"is_only_detect" : false
},
"converter" : {
"type": ["k210"]
}
}
注意:使用绝对路径可以避免不必要的错误。
接下来,我们可以使用以下命令进行训练;
python3 aXelerate/axelerate/traing.py -c config.json
现在训练结束了。我们感兴趣的是在项目文件夹中生成的kmodel文件。我们可以把它移到microSD卡上,然后连接到MaixDuino设备上。
预测下面是我将在maixPy IDE中使用的草图。
import sensor,image,lcd
import KPU as kpulcd.init()
sensor.reset()
sensor.set_pixformat(sensor.RGB565)
sensor.set_framesize(sensor.QVGA)
sensor.set_windowing((224, 224))
sensor.set_vflip(1)
sensor.run(1)classes = ["Apple", "Banana"]
task = kpu.load("/sd/name_of_the_model_file.kmodel")
a = kpu.set_outputs(task, 0, 7, 7, 35)anchor = (0.57273, 0.677385, 1.87446, 2.06253, 3.33843, 5.47434, 7.88282, 3.52778, 9.77052, 9.16828)
a = kpu.init_yolo2(task, 0.3, 0.3, 5, anchor) while(True):
img = sensor.snapshot().rotation_corr(z_rotation=90.0)
a = img.pix_to_ai()
code = kpu.run_yolo2(task, img)
if code:
for i in code:
a = img.draw_rectangle(i.rect(),color = (0, 255, 0))
a = img.draw_string(i.x(),i.y(), classes[i.classid()],
color=(255,0,0), scale=3)
a = lcd.display(img)
else:
a = lcd.display(img)a = kpu.deinit(task)
一定要更改输出参数,以适应kpu中训练过的神经网络中的输出参数。set_outputs(task, 0, 7, 7, 35)。现在可以运行程序了。这很容易。查看以下截图。

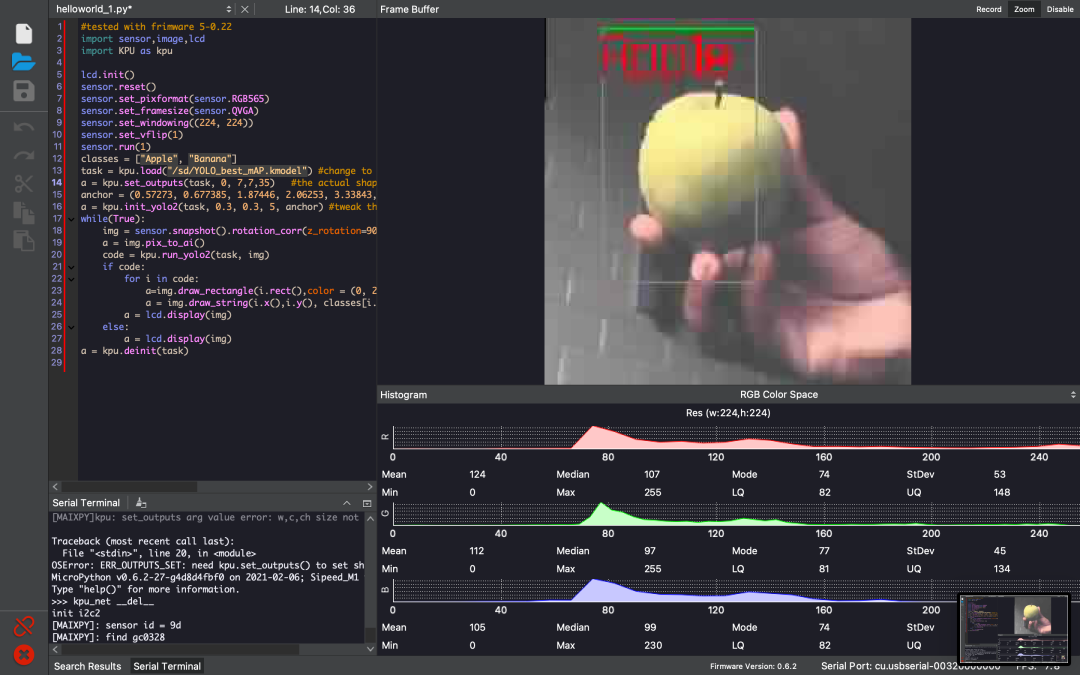
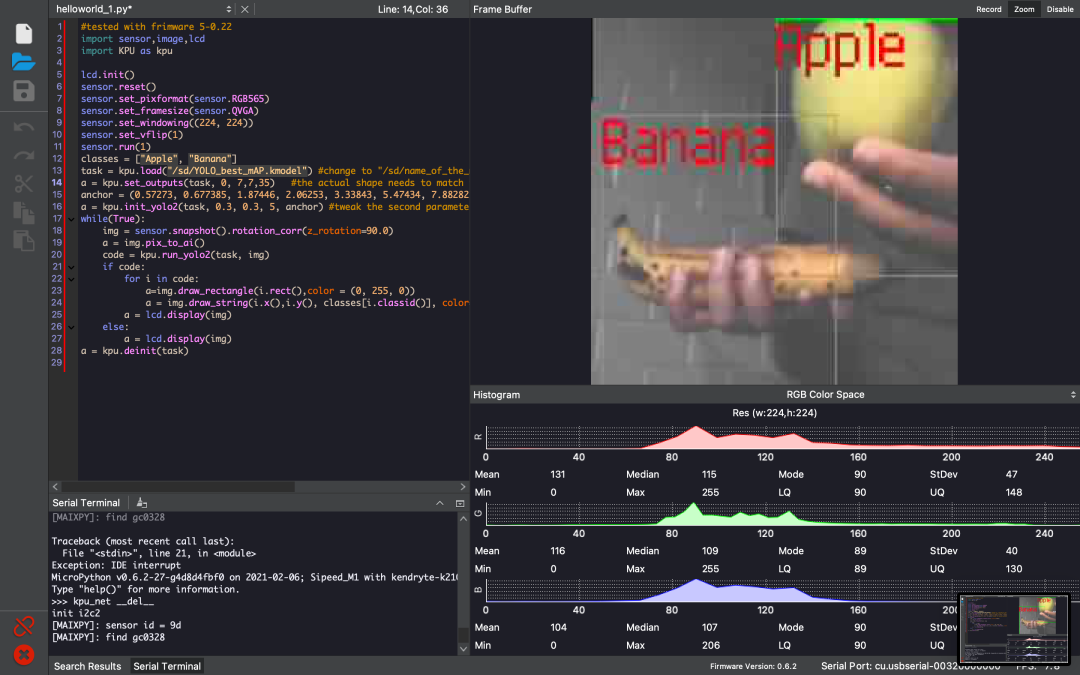
请注意,质量很低。这是因为maixPy IDE允许我们将LCD显示流传输到计算机。所以质量更差。
该图像检测程序可以在300mA电流下运行。此外,它有类似Arduino nano板的GPIO引脚。所以可能性是很多的。
希望本文能使你对数据科学的新水平有所了解。
本文仅做学术分享,如有侵权,请联系删文。
下载1
在「3D视觉工坊」公众号后台回复:3D视觉,即可下载 3D视觉相关资料干货,涉及相机标定、三维重建、立体视觉、SLAM、深度学习、点云后处理、多视图几何等方向。
下载2
在「3D视觉工坊」公众号后台回复:3D视觉github资源汇总,即可下载包括结构光、标定源码、缺陷检测源码、深度估计与深度补全源码、点云处理相关源码、立体匹配源码、单目、双目3D检测、基于点云的3D检测、6D姿态估计源码汇总等。
下载3
在「3D视觉工坊」公众号后台回复:相机标定,即可下载独家相机标定学习课件与视频网址;后台回复:立体匹配,即可下载独家立体匹配学习课件与视频网址。
重磅!3DCVer-学术论文写作投稿 交流群已成立
扫码添加小助手微信,可申请加入3D视觉工坊-学术论文写作与投稿 微信交流群,旨在交流顶会、顶刊、SCI、EI等写作与投稿事宜。
同时也可申请加入我们的细分方向交流群,目前主要有3D视觉、CV&深度学习、SLAM、三维重建、点云后处理、自动驾驶、多传感器融合、CV入门、三维测量、VR/AR、3D人脸识别、医疗影像、缺陷检测、行人重识别、目标跟踪、视觉产品落地、视觉竞赛、车牌识别、硬件选型、学术交流、求职交流、ORB-SLAM系列源码交流、深度估计等微信群。
一定要备注:研究方向+学校/公司+昵称,例如:”3D视觉 + 上海交大 + 静静“。请按照格式备注,可快速被通过且邀请进群。原创投稿也请联系。

▲长按加微信群或投稿

▲长按关注公众号
3D视觉从入门到精通知识星球:针对3D视觉领域的知识点汇总、入门进阶学习路线、最新paper分享、疑问解答四个方面进行深耕,更有各类大厂的算法工程人员进行技术指导。与此同时,星球将联合知名企业发布3D视觉相关算法开发岗位以及项目对接信息,打造成集技术与就业为一体的铁杆粉丝聚集区,近3000星球成员为创造更好的AI世界共同进步,知识星球入口:
学习3D视觉核心技术,扫描查看介绍,3天内无条件退款

圈里有高质量教程资料、可答疑解惑、助你高效解决问题
觉得有用,麻烦给个赞和在看~ 


