项目、论文地址:在公众号「3D视觉工坊」,后台回复「PHOSA」,即可直接下载。
概述作者提出了一种能够推断出人类和物体的形状和空间排列的方法,只需要一张在自然环境中捕捉的图像,且不需要任何带有3D监督的数据集。该方法的主要观点是,将人类和物体结合起来考虑,这样会产生“三维常识”,可以用来消除歧义。验证表明,该方法可以极大地减少物体的三维空间,达到更好的效果,作者在含有人类和大型物体的图像上面展示了该方法(如自行车、摩托车和冲浪板)。最后作者分析了该方法在恢复人类和物体之间的空间排列方面的能力,并概述了在这个相对未被探索的领域中仍存在的挑战。
简介从构成物体的角度来估计物体的二维结构已经取得了巨大的进步,但是与此相比,三维结构面临着很多约束,例如需要在特定的实验室条件下才能得到模型。为了得到准确的三维场景,作者认为必须着眼于整体布局,将人类和物体综合考虑,纠正局部的歧义。
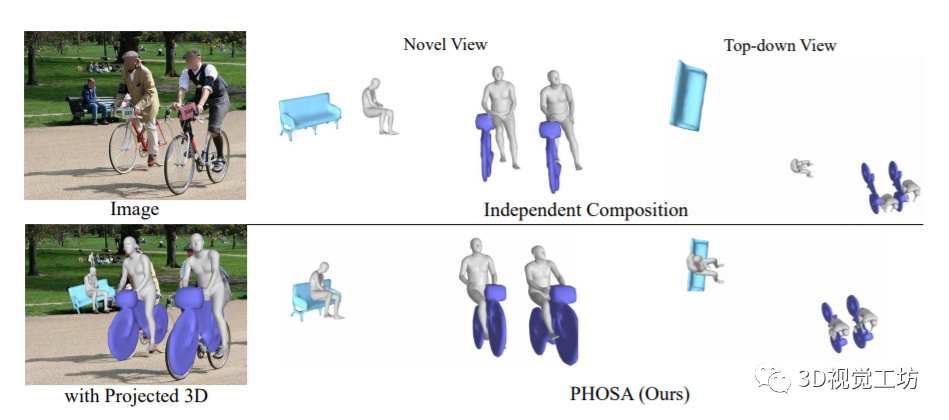
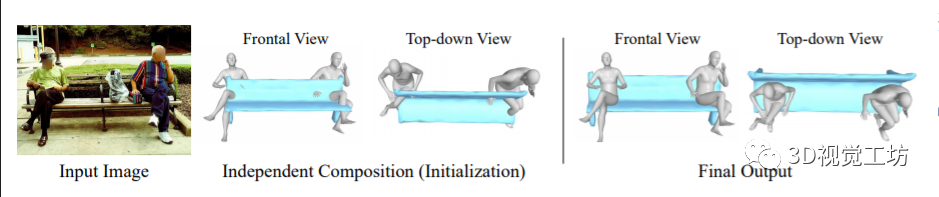
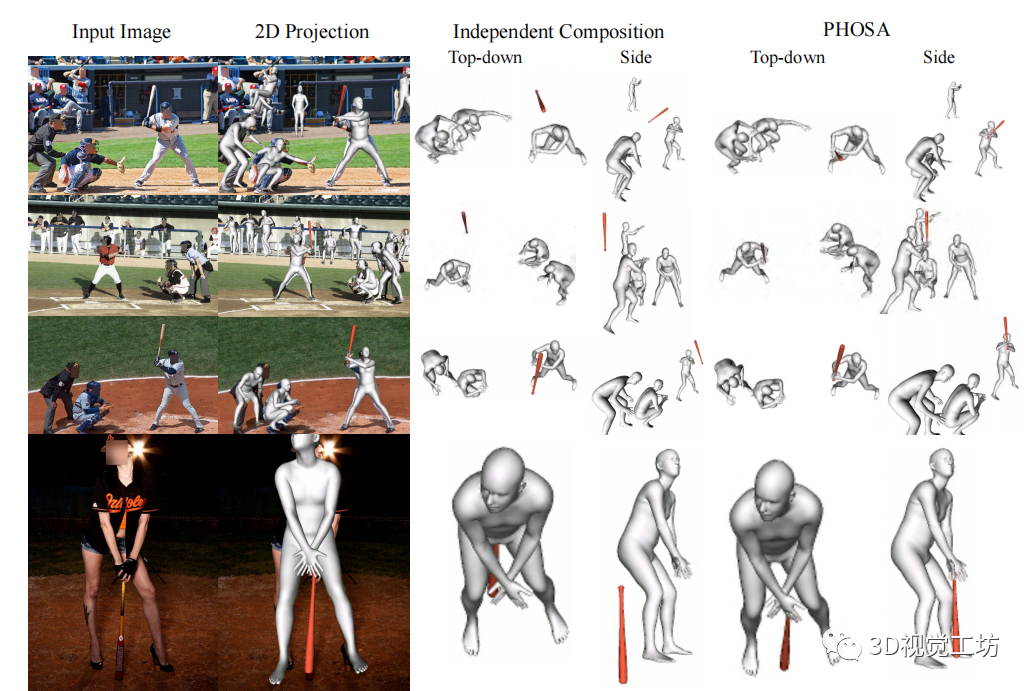
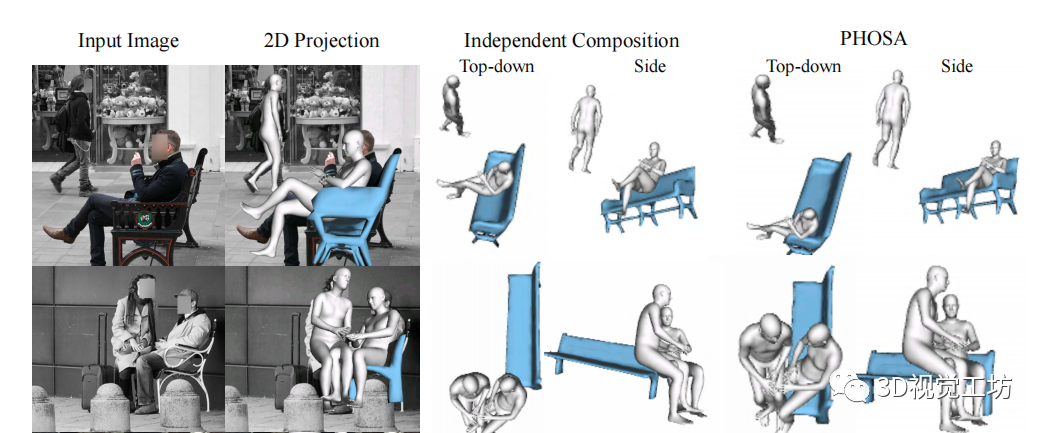
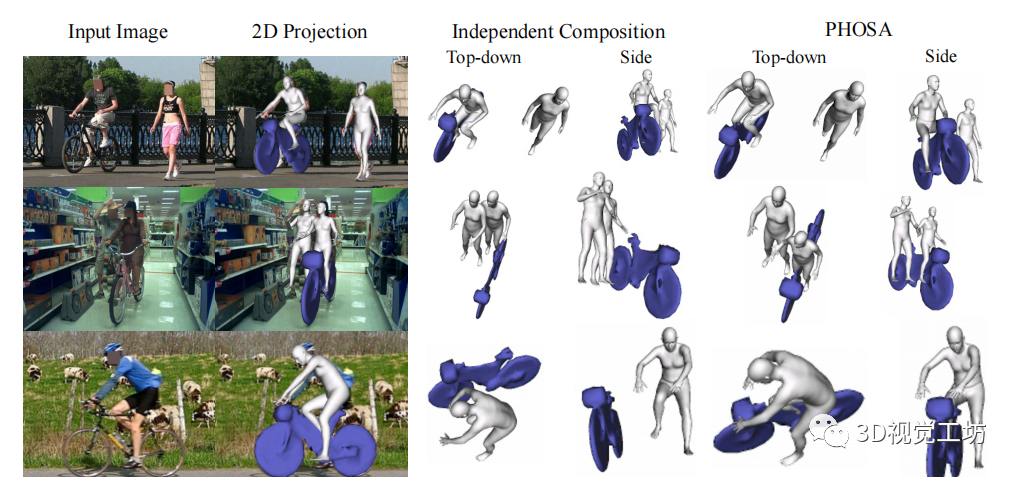
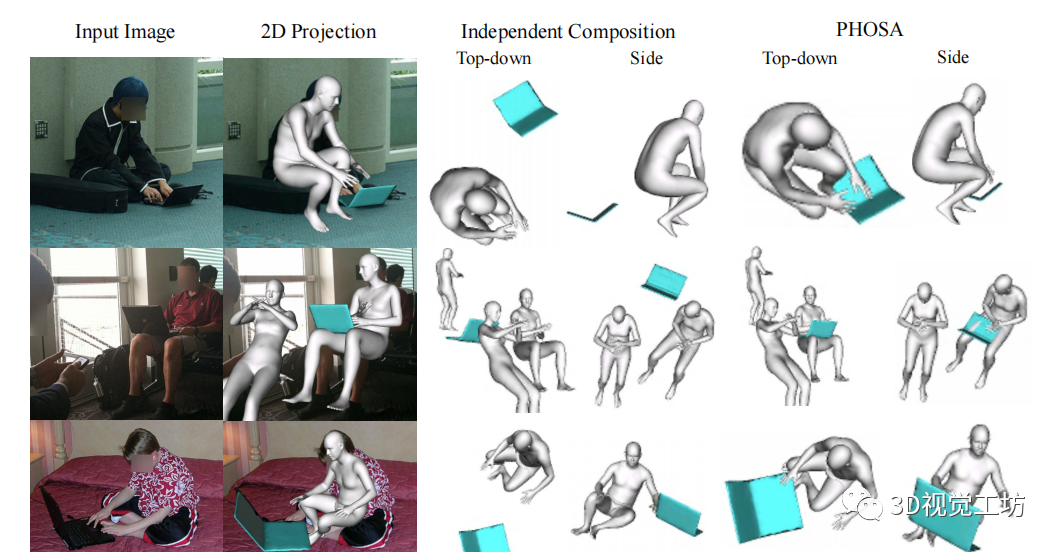
给定一张图片,该方法能够产生两种不同的3D场景,这两种场景具有相似的2D投影,如上图所示。使用人、物体和他们之间的联系,就能够恢复更加合理的场景。
这里有三个重要的问题需要解决。第一,这是一个不适定的问题,多个三维模型排列可能产生相同的2D投影,使用数据的一些先验知识可以解决这个问题。但是这样又会带来第二个问题,即获取大量带有3D监督的数据集是非常困难的,特别是在自然场景下。第三个问题是,尽管现在已经有成熟的技术来实现人类的重建,但是对于其他物体来说,这个工具并不太适用。

作者设计了一个基于优化的框架。给定一张图片,首先检测人类和物体的实例,然后预测每个人的姿态和形状,并且通过mask优化每一个物体的3D姿势。将每个3D实例在自己的局部坐标系中转换为使用内在尺度的世界坐标,最后再使用空间布局优化的方法,产生一个紧密连接的输出,如上图所示。
由于没有ground truth来验证这个任务的效果,作者在COCO-2017数据集上面定量定性地验证了该方法,效果图见文末。
相关工作从单张图片恢复人体的三维形状和姿势:这是以一个非常模糊的任务,现在的大多数方法都是采用统计的三维人体模型,这些模型具有强大的形状先验,并使用已知的运动结构来建模关节。综合考虑各个方法,作者最后选择了3D回归网络【1】作为主体,用来恢复人体的三维形状和姿势。
从单张图片恢复物体的三维形状:在单目三维重建方面有大量的文献,例如采用对模型变形的方法。在这项工作中,由于这些图像没有3D监督,作者采用传统的基于类别的模型拟合方法获得物体的初始6-DoF姿态,并细化其与场景中人类和其他物体的空间排列。
三维人体-物体交互:在这方面也有大量的方法,与本文中的工作最相关的是【2】,它实现了一种可以从单个图像中恢复3D人体姿势、3D物体和场景布局的方法,但是需要较强的三维监督。在这项工作中,作者重点恢复了在没有三维监督的情况下,人与物的三维空间布局。
方法该系统输入一张RGB图像,输出的是在一个共同的3D坐标系统中的人类和各种类别的物体。首先在每个预测边界框中分开估计人类和物体的三维模型,使用最先进的3D人体姿态估计器【1】获得3D人体模型,使用可微渲染器获得3D物体姿态。这个方法的核心思想是利用人与物体之间的交互作用,通过优化每个实例的内在尺度(指定它们的度量大小),在一个公共的3D坐标系统中对它们进行空间排列。
估计3D人体模型:通过检测算法提供的人体包围框,估计SMPL的三维形状和姿态参数、3D人体由姿态θ、形状β和一个弱相机视角π(将网格投影到图像坐标中)。为了在三维空间中定位人类,将弱透视相机转换为透视相机投影,对所有图像都假设一个固定的焦距f,其中人的距离由相机尺度参数σ的倒数决定。因此,第i个人的SMPL模型的三维顶点表示为
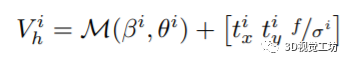
估计3D物体模型:将每一个物体看做刚体网格模型,估计他们的3D位置t、3D姿态R和内在尺度s。考虑每个物体类别的单个或者多个网格模型,根据每个类别的形状变化预先进行选择,例如滑板用了一个网格而摩托车用了四个,如下图所示。

第j个物体的三维形状表示为:
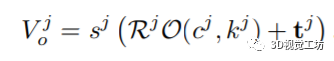
轮廓的损失表示为:
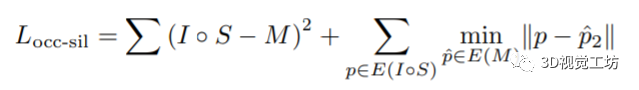
为了估计3D物体姿态,最小化上面的轮廓损失函数:
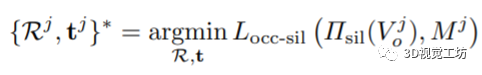
3D空间布局的建模:独立推理人类和物体的3D姿势可能产生不一致的3D场景排列,例如物体受到深度模糊的困扰:距离远的大物体可以投射到与距离近的小物体相同的图像坐标上,例如下图的冲浪板。因此,无法估计绝对的三维深度。在这项工作中,作者发现人与物之间的相互作用可以为人与物之间相对空间排列的推理提供重要线索。利用这一点需要两个步骤:识别交互的人和物体,定义一个目标函数,以正确调整其空间排列。

确定人和物的交互:假设人和物体在一定的世界坐标附近,在人和物体之间使用3D 边界框重叠来确定物体是否与人交互,对于较大对象类别,世界坐标中的每个类别三维边界框的大小设置为较大。输入一张图像,首先独立地估计人和物体的3D姿态,然后再利用先验知识产生更加合理的排列,如下图所示。其中,一个合理的初始尺度对于识别人与物体的交互很重要,因为如果物体被缩放到太大或太小,它就不会靠近人。在这里,作者利用一些常识推理初始化比例,通过互联网找到物体的平均大小。
优化3D空间排列的损失函数如下:
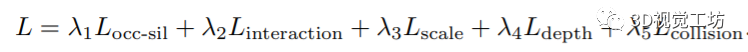
第一个前面已经介绍过。第二个表示交互损失,首先引入一个粗糙的每个实例间的交互损失,将人和物体拉近:
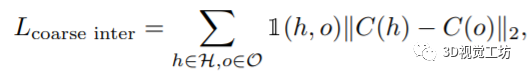
然后使用标签拉近交互区域以实现更好的对齐:
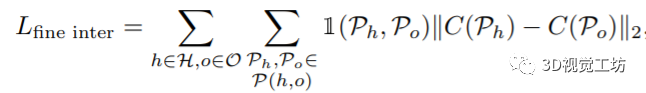
作者发现在一个类别内,物体大小的变化是有限的。因此,作者使用了特定类别的平均尺度,在同一类别实例的内在尺度上加入一个高斯先验:

从3D位置推断出的深度顺序应该与图像的深度顺序相匹配,使用顺序深度可以为遮挡器和被遮挡对象提供更平滑的梯度。对于每一对实例,在轮廓和mask的交叉处进行像素比较,最后定义的损失如下:

促进人和物体之间的靠近又会面临空间相互占用的问题,因此作者使用了【3】引入的碰撞损失来惩罚那些人和物体相互渗透的姿势。
效果图:
【1】Joo, H., Neverova, N., Vedaldi, A.: Exemplar fine-tuning for 3d human pose fitting towards in-the-wild 3d human pose estimation. arXiv preprint arXiv:2004.03686(2020)
【2】Chen, Y., Huang, S., Yuan, T., Qi, S., Zhu, Y., Zhu, S.C.: Holistic++ scene understanding: Single-view 3d holistic scene parsing and human pose estimation with human-object interaction and physical commonsense. In: CVPR (2019)
【3】Ballan, L., Taneja, A., Gall, J., Van Gool, L., Pollefeys, M.: Motion capture of hands in action using discriminative salient points. In: ECCV (2012)
备注:作者也是我们「3D视觉从入门到精通」特邀嘉宾:一个超干货的3D视觉学习社区
本文仅做学术分享,如有侵权,请联系删文。
下载1
在「3D视觉工坊」公众号后台回复:3D视觉,即可下载 3D视觉相关资料干货,涉及相机标定、三维重建、立体视觉、SLAM、深度学习、点云后处理、多视图几何等方向。
下载2
在「3D视觉工坊」公众号后台回复:3D视觉github资源汇总,即可下载包括结构光、标定源码、缺陷检测源码、深度估计与深度补全源码、点云处理相关源码、立体匹配源码、单目、双目3D检测、基于点云的3D检测、6D姿态估计源码汇总等。
下载3
在「3D视觉工坊」公众号后台回复:相机标定,即可下载独家相机标定学习课件与视频网址;后台回复:立体匹配,即可下载独家立体匹配学习课件与视频网址。
重磅!3DCVer-学术论文写作投稿 交流群已成立
扫码添加小助手微信,可申请加入3D视觉工坊-学术论文写作与投稿 微信交流群,旨在交流顶会、顶刊、SCI、EI等写作与投稿事宜。
同时也可申请加入我们的细分方向交流群,目前主要有3D视觉、CV&深度学习、SLAM、三维重建、点云后处理、自动驾驶、多传感器融合、CV入门、三维测量、VR/AR、3D人脸识别、医疗影像、缺陷检测、行人重识别、目标跟踪、视觉产品落地、视觉竞赛、车牌识别、硬件选型、学术交流、求职交流、ORB-SLAM系列源码交流、深度估计等微信群。
一定要备注:研究方向+学校/公司+昵称,例如:”3D视觉 + 上海交大 + 静静“。请按照格式备注,可快速被通过且邀请进群。原创投稿也请联系。

▲长按加微信群或投稿

▲长按关注公众号
3D视觉从入门到精通知识星球:针对3D视觉领域的视频课程(三维重建系列、三维点云系列、结构光系列、手眼标定、相机标定、orb-slam3等视频课程)、知识点汇总、入门进阶学习路线、最新paper分享、疑问解答五个方面进行深耕,更有各类大厂的算法工程人员进行技术指导。与此同时,星球将联合知名企业发布3D视觉相关算法开发岗位以及项目对接信息,打造成集技术与就业为一体的铁杆粉丝聚集区,近2000星球成员为创造更好的AI世界共同进步,知识星球入口:
学习3D视觉核心技术,扫描查看介绍,3天内无条件退款

圈里有高质量教程资料、可答疑解惑、助你高效解决问题
觉得有用,麻烦给个赞和在看~ 


