
标题:Semantic Graph Based Place Recognition for 3D Point Clouds
作者:Xin Kong, Xuemeng Yang , Guangyao Zhai , Xiangrui Zhao ,Xianfang Zeng , Mengmeng Wang , Yong Liu , Wanlong Li and Feng Wen
Zhejiang University
来源:arxiv 2020
编译:丛阳滋
审核:zhiyong
转载:泡泡机器人SLAM

摘要

由于空间的遮挡与视角的改变,提取用于三维激光点云场景识别的描述子仍然是一个开放的问题,不同于大部分基于原始点云数据局部、全局和统计特征对场景进行描述,本文的方法主要依靠语义信息来提高对不同场景的适应性。模仿人类的认知习惯,我们利用场景中的语义目标及其空间位置分布信息,提出了一种基于语义图的场景识别方法。首先我们创新地提出了语义图的表达方式,直接保留了原始点云的语义和拓扑信息,随后将场景识别建模为图匹配问题,利用提出的网络计算图间的相似度。Kitti的结果表明我们的方法很大程度上优于SOTA,并且开源。

主要贡献

-
基于人类认知习惯,我们提出了一种语义图来表达原始点云中的语义信息以及语义目标之间的拓扑关系;
-
我们提出了一种用于估计图匹配相似性的网络,可以用于回环检测;
-
KITTI上的大量实验证明我们的方法达到SOTA的效果,对反向回环、遮挡与视点变换很鲁棒。

算法流程


本文方法的流程如上图所示,主要分为语义图表达与基于学习的图相似度计算两个部分。
A 语义图表达

我们利用RangeNet++使用SemanticKITTI的语义标签对数据进行语义分割,再通过聚类获得语义目标,如上图所示,每一个节点由中心点坐标以及语义信息构成;
B 图相似度网络

受SimGNN的启发,我们将语义目标表达为DGCNN中的superpoints,利用EdgeConv来提取局部空间特征,并且我们利用K邻近来构建欧氏空间关系,将两个部分分开进行特征的融合,如上图所示;
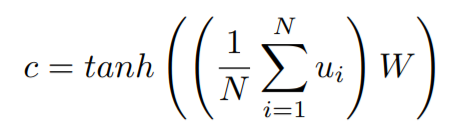
对每个结点进行加权来获得一个整体图的表达,通过上式来计算一个全局的图上下文信息(Global Graph Context);

通过上式,我们认为与全局上下文信息更相似的节点具有更大的权值,最终我们得到语义图的嵌入表达(Graph Embedding);

一对图之间的关系可以用NTN的方法进行估计,如上式所示,由此得到图间相似性的度量。

实验结果


本文利用KITTI数据集进行广泛的测试,结果如上图所示,效果优于现有方法;

我们使用最大F1分数来进行定量的评价,可以看出在S08数据上表现尤为突出;

为了测试鲁棒性,我们使用遮挡的数据对方法进行评价,结果如上图所示;

从上图可以看到重访区域的相似度大小;

本文还测试了不同阈值对方法精度的影响,如上图所示,另外本文方法可以达到实时的效率。
------------------------------------------------
Abstract
Due to the difficulty in generating the effective descriptors which are robust to occlusion and viewpoint changes,place recognition for 3D point cloud remains an open issue.Unlike most of the existing methods that focus on extractinglocal, global, and statistical features of raw point clouds,our method aims at the semantic level that can be superiorin terms of robustness to environmental changes. Inspiredby the perspective of humans, who recognize scenes throughidentifying semantic objects and capturing their relations, thispaper presents a novel semantic graph based approach for placerecognition. First, we propose a novel semantic graph representation for the point cloud scenes by reserving the semantic andtopological information of the raw point cloud. Thus, placerecognition is modeled as a graph matching problem. Thenwe design a fast and effective graph similarity network tocompute the similarity. Exhaustive evaluations on the KITTIdataset show that our approach is robust to the occlusion aswell as viewpoint changes and outperforms the state-of-theart methods with a large margin. Our code is available at:https://github.com/kxhit/SG_PR
本文仅做学术分享,如有侵权,请联系删文。
下载1
在「3D视觉工坊」公众号后台回复:3D视觉,即可下载 3D视觉相关资料干货,涉及相机标定、三维重建、立体视觉、SLAM、深度学习、点云后处理、多视图几何等方向。
下载2
在「3D视觉工坊」公众号后台回复:3D视觉github资源汇总,即可下载包括结构光、标定源码、缺陷检测源码、深度估计与深度补全源码、点云处理相关源码、立体匹配源码、单目、双目3D检测、基于点云的3D检测、6D姿态估计源码汇总等。
下载3
在「3D视觉工坊」公众号后台回复:相机标定,即可下载独家相机标定学习课件与视频网址;后台回复:立体匹配,即可下载独家立体匹配学习课件与视频网址。
重磅!3DCVer-学术论文写作投稿 交流群已成立
扫码添加小助手微信,可申请加入3D视觉工坊-学术论文写作与投稿 微信交流群,旨在交流顶会、顶刊、SCI、EI等写作与投稿事宜。
同时也可申请加入我们的细分方向交流群,目前主要有3D视觉、CV&深度学习、SLAM、三维重建、点云后处理、自动驾驶、多传感器融合、CV入门、三维测量、VR/AR、3D人脸识别、医疗影像、缺陷检测、行人重识别、目标跟踪、视觉产品落地、视觉竞赛、车牌识别、硬件选型、学术交流、求职交流、ORB-SLAM系列源码交流、深度估计等微信群。
一定要备注:研究方向+学校/公司+昵称,例如:”3D视觉 + 上海交大 + 静静“。请按照格式备注,可快速被通过且邀请进群。原创投稿也请联系。

▲长按加微信群或投稿

▲长按关注公众号
3D视觉从入门到精通知识星球:针对3D视觉领域的视频课程(三维重建系列、三维点云系列、结构光系列、手眼标定、相机标定、orb-slam3等视频课程)、知识点汇总、入门进阶学习路线、最新paper分享、疑问解答五个方面进行深耕,更有各类大厂的算法工程人员进行技术指导。与此同时,星球将联合知名企业发布3D视觉相关算法开发岗位以及项目对接信息,打造成集技术与就业为一体的铁杆粉丝聚集区,近2000星球成员为创造更好的AI世界共同进步,知识星球入口:
学习3D视觉核心技术,扫描查看介绍,3天内无条件退款

圈里有高质量教程资料、可答疑解惑、助你高效解决问题
觉得有用,麻烦给个赞和在看~ 

