
目录
1. 背景
- 1. 背景
- 2. 安装
- 3. 使用
-
- 3.1 获取page_source
有的时候我们在抓取网页的时候,会遇见动态加载的页面,比如动态的加载销量、跟据不同的条件动态的加载结果;如果我们采用Ajax的方式来抓取数据,可能会特别麻烦;所以由的时候我们可能会想到使用selenium来模拟浏览器,获取已经加载好的结果数据
2. 安装2.1 python安装selenium
pip install selenium
2.2 安装浏览器驱动 我们需要模拟控制浏览器,总需要一个连接浏览器的东西吧,这个东西就是webdriver驱动文件
这里我们以Chrome浏览器为例讲解,其它浏览器类似
-
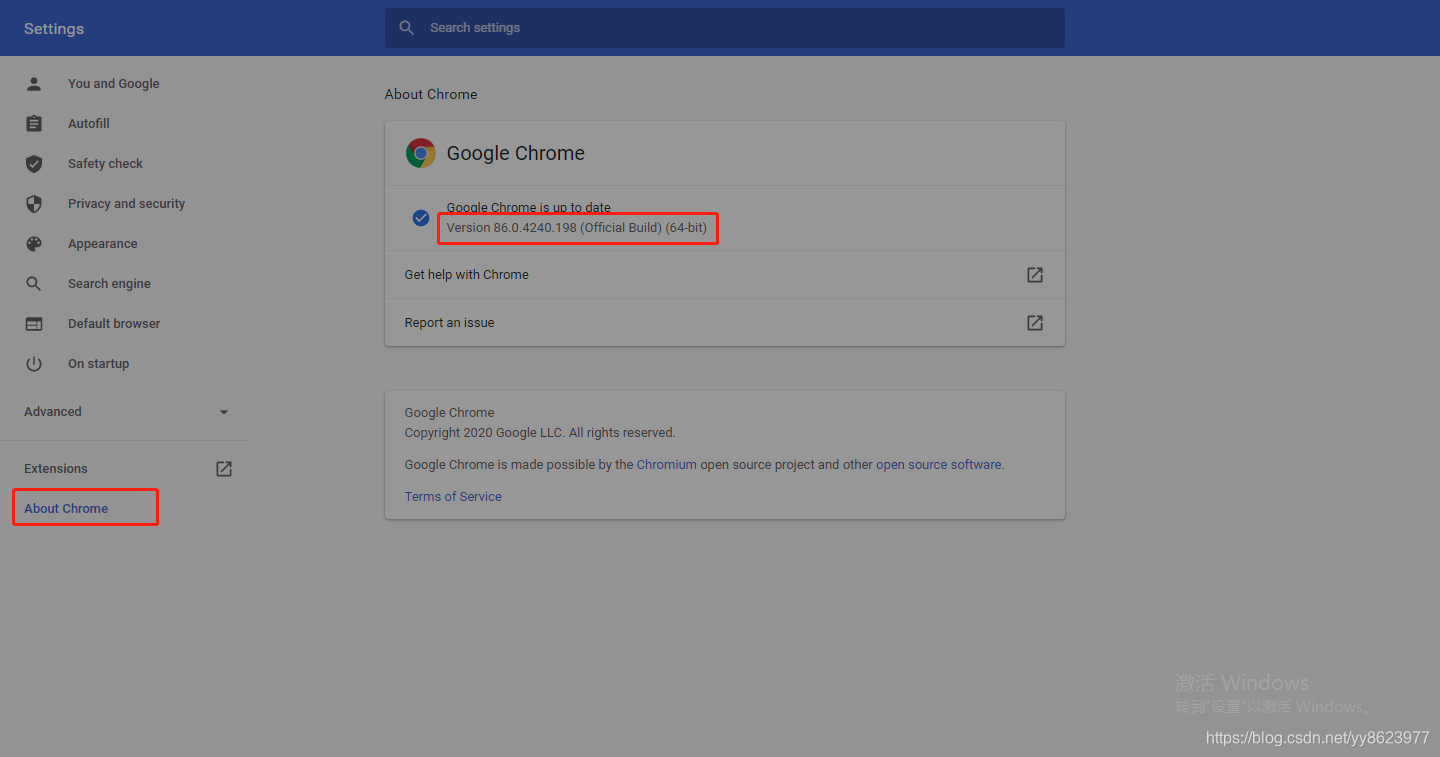
确定Chrome浏览器的版本 打开浏览器的settings,查看方式如下图所示:
-
下载webdriver 从chromedriver的taobao镜像下载对应你浏览器版本和操作系统版本的chromedriver
-
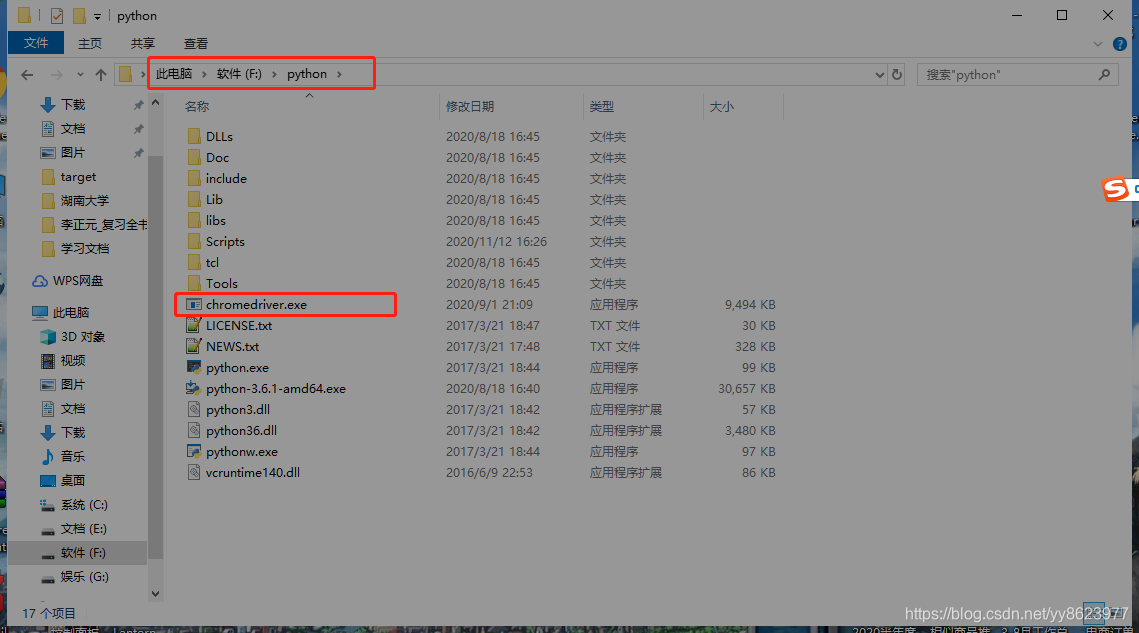
解压放到python的安装目录下 如下图所示:
from selenium import webdriver
option=webdriver.ChromeOptions() option.add_argument('headless') # 参数设置浏览器后台运行 browser=webdriver.Chrome(chrome_options=option) # 加载参数 browser.get("http://z.kktijian.com/Project/ProjectDetail?projectId="+project_id) brower_html_text=browser.page_source
browser.close() print(type(brower_html_text)) #
说明:
- 获取到的brower_html_text是动态加载后的网页源码,接着就可以使用BeautifulSoup等库来解析brower_html_text了

