
目录
1. 哈希表(散列表)
1.1 哈希表的介绍
- 1. 哈希表(散列表)
-
- 1.1 哈希表的介绍
- 1.2 哈希表的程序实现
- 2. 树的优点和常用术语介绍
-
- 2.1 为什么会有树结构
- 2.2 树的常用术语
哈希表(Hash table,也叫散列表),主要用来提高查询速度
数据的保存过程:一条数据根据key经过映射函数/散列函数(例如进行hash计算然后取模)计算,根据得到的值将数据保存到哈希表(用数组实现)对应的位置
数据的查询过程:查询数据也是指定key,然后将该key经过散列函数计算,再根据得到的值从哈希表(用数组实现)指定的位置获取数据
1.2 哈希表的程序实现需求:将大量员工的数据进行保存,员工信息包含id、name,添加员工数据时id是递增的;当输入员工id时,要求不使用数据库,使用少量内存且快速的查询该员工信息。可以使用哈希表进行实现
实现思路:使用数组来实现哈希表,数组的元素类型是链表(也可用二叉树实现),一个链表用来保存相同散列函数结果值的多个员工的数据,链表的head就是第一个添加的员工
程序如下:
public class HashTableDemo {
public static void main(String[] args) {
// 创建哈希表
HashTable hashTable = new HashTable(5);
// 将多个员工数据添加到哈希表
Emp emp1 = new Emp(1, "emp1");
Emp emp2 = new Emp(2, "emp2");
Emp emp3 = new Emp(6, "emp6");
hashTable.add(emp1);
hashTable.add(emp2);
hashTable.add(emp3);
// 根据员工id查询员工信息
hashTable.findEmpById(6);
// 显示所有员工的信息
hashTable.show();
}
}
// 表示一个员工
class Emp {
public int id;
public String name;
// 用来实现链表,默认是null
public Emp next;
public Emp(int id, String name) {
this.id = id;
this.name = name;
}
}
// 链表用来保存相同散列函数结果值的多个员工的数据
class EmpLinkedList {
// 链表的head就是第一个添加的员工,默认是null
private Emp head;
// 添加员工到链表
// 因为员工的id是递增的,所以直接将新员工添加到链表的最后即可
public void add(Emp emp) {
// 第一个员工直接赋值给head
if (this.head == null) {
this.head = emp;
return;
} else {
// 找到链表的最后一个节点,然后添加新员工到后面
Emp currentEmp = this.head;
while (currentEmp.next != null) {
currentEmp = currentEmp.next;
}
currentEmp.next = emp;
}
}
// 根据员工id查询员工信息
public Emp findEmpById(int empId) {
// 如果链表为空,直接返回null
if (this.head == null) {
System.out.println("链表为空");
return null;
} else {
Emp currentEmp = this.head;
while (true) {
// 如果找到了,则返回当前员工
if (currentEmp.id == empId) {
return currentEmp;
// 如果下一个节点为null,则返回null
} else if (currentEmp.next == null) {
return null;
// 如果还有下一个节点,则进行下一个节点的查找
} else {
currentEmp = currentEmp.next;
}
}
}
}
// 遍历显示链表所有员工的数据。参数为链表在哈希表中的编号
public void show(int empLinkedListNo) {
// 如果链表为空
if (this.head == null) {
System.out.println("第" + (empLinkedListNo + 1) + "号链表为空");
return;
} else {
System.out.print("第" + (empLinkedListNo + 1) + "号链表的信息为: ");
Emp currentEmp = this.head; //辅助指针
// 循环打印所有员工的信息
while (true) {
System.out.printf(">>>>>>id=%d, name=%s\t", currentEmp.id, currentEmp.name);
if (currentEmp.next == null) {
break;
} else {
currentEmp = currentEmp.next;
}
}
System.out.println();
}
}
}
// 使用数组来实现哈希表,数组的元素类型是链表
class HashTable {
private EmpLinkedList[] empLinkedListArray;
// 链表的个数
private int empLinkedListArraySize;
public HashTable(int empLinkedListArraySize) {
this.empLinkedListArraySize = empLinkedListArraySize;
this.empLinkedListArray = new EmpLinkedList[empLinkedListArraySize];
// 初始化每个链表
for (int i = 0; i < this.empLinkedListArraySize; i++) {
this.empLinkedListArray[i] = new EmpLinkedList();
}
}
// 添加员工
public void add(Emp emp) {
// 将员工的id经过散列函数计算, 然后将该员工添加到对应的链表
int empLinkedListNo = this.hashFunction(emp.id);
this.empLinkedListArray[empLinkedListNo].add(emp);
}
// 根据员工id查找员工信息
public void findEmpById(int empId) {
// 将要查找的员工的id经过散列函数计算, 然后从对应的链表进行查询
int empLinkedListNo = this.hashFunction(empId);
Emp emp = this.empLinkedListArray[empLinkedListNo].findEmpById(empId);
if (emp != null) {
System.out.printf("在第%d号链表中找到id=%d的员工,其name=%s\n", (empLinkedListNo + 1), emp.id, emp.name);
} else {
System.out.printf("未找到id=%d的员工的信息\n", empId);
}
}
// 遍历哈希表的所有链表,显示所有员工信息
public void show() {
for (int i = 0; i < this.empLinkedListArraySize; i++) {
this.empLinkedListArray[i].show(i);
}
}
// 散列函数。这里只进行简单的取模
public int hashFunction(int empId) {
return empId % this.empLinkedListArraySize;
}
}
运行程序,结果如下:
在第2号链表中找到id=6的员工,其name=emp6 第1号链表为空 第2号链表的信息为: >>>>>>id=1, name=emp1 >>>>>>id=6, name=emp6 第3号链表的信息为: >>>>>>id=2, name=emp2 第4号链表为空 第5号链表为空2. 树的优点和常用术语介绍 2.1 为什么会有树结构
数组的缺点:按数组的值顺序插入值,或删除值。都要新建一个数组,进行原数组的值拷贝,再进行操作,效率较低。ArrayList的底层也是通过数组来储存数据的 链表的缺点:检索某个值,需要从头节点开始遍历,效率较低
树的优点:能提高数据存储,读取的效率。比如利用二叉排序树(Binary Sort Tree),既可以保证数据的检索速度,同时也可以保证数据的插入,删除,修改的速度
2.2 树的常用术语
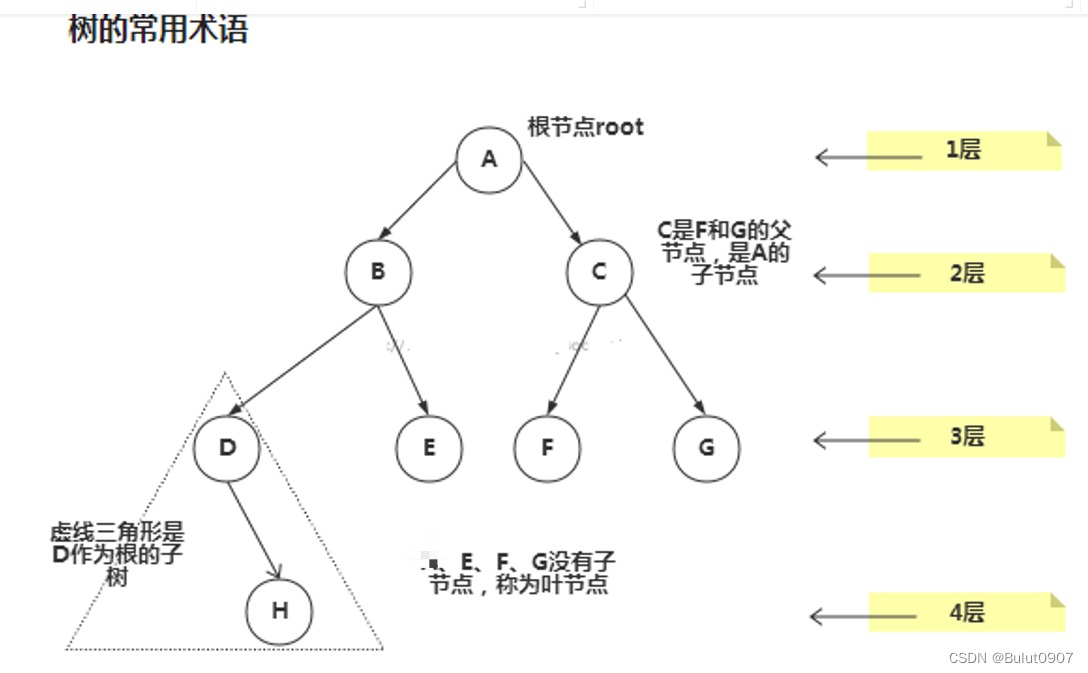
树的常用术语:
- 节点
- 根节点
- 父节点
- 子节点
- 叶子节点(没有子节点的节点)
- 节点的权(节点值)
- 路径(从root节点找到该节点的路线)
- 层
- 子树
- 树的高度(最大层数)
- 森林(多颗子树构成森林)

