
可视化各个监控指标的使用,分别对以下选项卡进行介绍, TensorFlow 版本不一样会导致该界面也略有不同, 0.9.0 版本的 TensorFlow 有 5 个分栏,分别是SCALARS(标量)、 IMAGES(图片)、 AUDIO(音频)、 GRAPHS(计算图)、 DISTRIBUTIONS(数据分布)、 HISTOGRAMS(直方图)和EMBEDDINGS (嵌入向量)
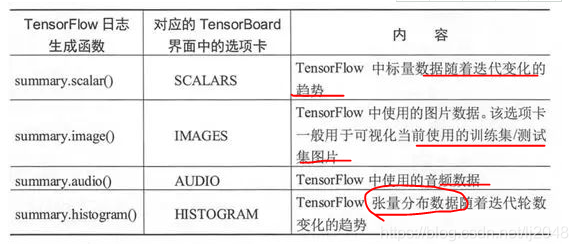
常用!!!打开的 Tensor Board 界面会默认进入 SCALARS 选项卡,我们对可视化内容的介绍也先从标量开始。标题中的 accuracy 表示我们在命名 空间 accuracy 下计算正确率并运行 summary.scalar()函数,标题中的 accuracy scalar 是汇总时函数的 name 参数值(当时我们赋值为 accuracy_scalar) 。accuracy/ accuracy_scalar 折线图按照训练的步数展示了正确率的值,将光标停在折线上时会在紧挨着图表的下方显示一个黑色的提示框,里面有 折线图上某一点更精确的数值信息,甚至包括得到数值的时间。紧挨着图表的左下方有两个蓝色按钮,左边的蓝色按钮单击之后可以放大这个图表。右边的蓝色按钮(Toggle y-axis log scale)单击之后可以调整纵坐标轴的范围,以便更清楚地显示。这样使得折线能够占据图上较大的空间
0.2、IMAGES 选项卡(图像数据可视化)SCALARS 选项卡的右侧是 IMAGES 选项卡,该选项卡用于展示汇总的图片信息。我们在程序中确实使用summary.image()函数汇总了 MNIST 的二维图片数据(大概在命名空间 input_reshape 下〉,并且在汇总时设置函 数的 max_outputs 参数为 10,表示图片的汇总数目最大为 10 张。在 input_reshape 标签的右侧,我们能看到数字 10, 表示这里有 10 张图片。在每张图片的左下角有两个蓝色的小按钮,左边的那个用于放大图片 以便在更大的屏幕区域观察图片的细节,右边的那个用于以实际像素显示图片。MNIST 数据集的图片大小是 28x28 ,如果以实际像素显示图片,那么会显得非常非常小。IMAGES 选项卡左侧的控制区域没有太多的可选项, Split onunderscores 选项的含义和 SCALARS 选项卡中该选项的含义相同。
0.3、AUDIO选项卡(音频数据可视化)IMAGES 选项卡右侧是AUDIO选项卡。在程序中,我们没有通过summa可audio()函数汇总音频数据, 所以在 AUDIO 栏会显示“No audio data was found”。汇总音频数据的情况通常出现在解决自然语言处理的相关问题时,读者可以自己搜集一段 MP3 数据进行汇总, 然后在 AUDIO 边项卡中查看汇总音频数据的情况。
0.4、GRAPHS 选项卡(计算图结构可视化)常用!!!!AUDIO 选项卡的右侧是GRAPHS 选项卡,也就是展示计算图可视化效果的地方。我们选择 GRAPHS 选项卡作为重点介绍的对象,实际上它也正是整个 TensorBoard 的灵魂所在 。在 GRAPHS 选项卡中可以看到整个 Tensor Flow 计算图的结构。
一些主要的部分己经用命名空间的名称表示出来,例如 layer_1 和 layer_y,以及 cross_entropy、 accuracy 和 train,这也正 是我们在程序中使用命名空间划分各部分的原因。通过命名空间手动调整计算图的可视化效果图是一种不错的做法,除此之外, TensorBoard 也会智 能调整计算图上的节点。例如,计算图中会有一些执行相同操作的节点,这会造成计算图中存在比较多的依赖关系,如果全部画在一张图上会使可 视化得到的效果图非常拥挤,于是 TensorBoard 将计算图分成了主图(Main Graph)和辅助图(Auxiliary Graph)两个部分来呈现。在上图中,左侧展示的是计算图的主图部分;右侧展示的是辅助图部分,辅助图部分包含 一些单独列出来的节点,从这些单独列出来的节点可以看到,layer_1 和 layer_y 和 train 都包含有 init 节点。我们先来关注网络的前向传播过程。
x-input节点代表训练神经网络需要输入的数据,这些输入数据会提供给第一个隐藏层 layer_1 以及 input_reshape (汇总图像数据的命名空间) , layer_1 处理之后的数据会传递到 layer_y, layer_y 的输出会传递到 cross_entropy 和 accuracy。cross_ entropy 和 accuracy 同时还接收了来自 y-input 节点的数据用于计算交叉熵损失和准确率。最后 cross_entropy节点的数据会提供给神经网络的优化过程,也就是图中位train 所代表的节点 。训练中 backward 的求解梯度和更新参数等操作是 TensorFlow自动创建的,从 train 到 layer 1 和 layer_y 也有两条边,这代表的就是 求解梯度和更新参数的过程。。最多的一种边是通过 实线表示的,这种边描述的是不同节点间的数据传输。比如 layer_1 和 layer_y 之间的边表示了 layer_1 的输出将会作为 layer_y 的输入。有时一些 边上会有双向的箭头(当然在上图中不存在这样的边),这表示两个节点间的数据传递是双向的。计算图可视化后的边上还标注了张量的维度信息。下图展示了单击 节点右上角的“+”图标后放大的 layer_1 节点。从图中可以看出, weights 节点和 Wx_add_b 节点之间传输的张量的维度为 784x500。这说明了该层的单元数为 500,输入层单元的个数为 784。如果两个节点之间传输的张量的个数大于 1,则边上将只显示张量的个数(如 4 tensors 表示 4 个张量)。边的粗细表示的是两个节点之间传输的标量维度的总大小(包含标量汇总为张量时张量的个数),所以不能仅仅通过边的粗细来比较哪条边传输的标量个数更多。
当我们单击选中的节点为一个命名空间时, 信息框会展示这个命名空间内 所有计算节点的输入、输出以及依赖关系。虽然属性( Attriubtes)也会展示 在信息框中,但是属性栏下不会有任何内 容。当单击选中的节点为一个 Tensor Flow 程序的计算节点时,对应的信息框会显示更加详细的内容,就 连属性( Attriubtes)中的内容也被展示出来(属性栏下显示了选中的计算节 点是在什么设备上运行的,以及运行这个计算时传入的参数)。
0.5、 DISTRIBUTIONS(数据分布可视化)和 HISTOGRAMS(直方图可视化〉对于 DISTRIBUTIONS 选项卡, TensorFlow 并没有在 summar.py 中 提供 distribution()函数来汇总分布数据,该选项卡中的数据来源于 summar. histogram()函数汇总的结果:也就是说, DISTRIBUTIONS 选项卡和 HISTOGRAMS 选项卡中的数据相同,只是可视化的形式不同。DISTRIBUIONS 选项卡的可视化,记录的是各个神经网络层输出的分布,包括在激活函数前的结 果以及在激活函数后的结果;也可以将 DISTRIBUTIONS 选项卡中可视化数据的形式转换为直方图的形式,HISTOGRAMS 选项卡,这里展示的就是转 换为直方图后的结果
0.6、EMBEDDINGS (嵌入向量可视化)选项卡可以看到降维后的嵌入向量的可视化效果,这属于 TensorBoard 的 Embedding Projector 功能。只要我们使用 save.Saver() 函数保存了整个模型, 就能让 TensorBoard 自动对模型中的二维 Variable 进行可视化。尽量不要在程序中把 checkpoint 文件以及模型保存过程中产生的其他 3 个文件保存得和日志文件相隔太远。如果保存后的模型文件相对于程序中指定的模型保存路径发生了偏移,那么 TensorBoard 会在 EMBEDDINGS 选项卡中报无法找到 Checkpoint 文件的错误。
0.7、 Split on underscores 选项最后,在 Data download links 选择项的上部有一个 Split on underscores 选项(默认没有选中),用于合并标签中以“_”符号分隔的含有相同宇段的标签。这样说可能难以理解,比如对于 layer_1 和 layer_y标签,如果勾选了 Split on underscores 复边框,则会合并为一个名为 layer 的标签,这个新的 layer 标签会折叠 16 个图表数据(layer_1和 layer_y 各包含 8 个)。展开layer,其图表的标题仍以 layer_1 或 layer_y 开头。
参考
Tensorboard计算图可视化结果 - 知乎
tensorboard标量数据可视化结果 - 知乎
Tensorboard其它监控指标可视化 - 知乎
1、使用 1.1、启用tensorboard1)打开终端cmd--->找到存放Events文件的文件夹所在的路径(也就是Log生成的event存放位置的上一级--project位置):如本文的project是batchsize_test,logdir存放的位置是log(此处的命名是随意的),因此打开cmd后,需要即先输入d: --->再输入cd D:\Code\pythonCode\batchsize_test
 2)输入tensorboard --logdir=./log --host=127.0.0.1(其中“./log”是我存放日志文件的路径,你需要指定到你自己命名的路径上去;另外为何此处有--host=127.0.0.1,是因为有的时候tensorboard返回的网址在电脑浏览器中打不开,则需要添加此) 3)然后在浏览器中打开http://127.0.0.1:6006/即可(如果2输入的是tensorboard --logdir=./log,则此步可以输入http:localhost:6006) 4)如果生成的图有虚线/点数显示不全,可以通过下面的方法解决
2)输入tensorboard --logdir=./log --host=127.0.0.1(其中“./log”是我存放日志文件的路径,你需要指定到你自己命名的路径上去;另外为何此处有--host=127.0.0.1,是因为有的时候tensorboard返回的网址在电脑浏览器中打不开,则需要添加此) 3)然后在浏览器中打开http://127.0.0.1:6006/即可(如果2输入的是tensorboard --logdir=./log,则此步可以输入http:localhost:6006) 4)如果生成的图有虚线/点数显示不全,可以通过下面的方法解决
5)还有一个更加简便的方法,省去了切换盘符各种问题(区别在于此处的路径到了log生成的event存放的位置--log),即跑完代码后直接打开cmd-->tensorboard --logdir D:\Code\pythonCode\batchsize_test\log --host=127.0.0.1-->将返回的网址http://127.0.0.1:6006/进行复制,输入到浏览器中
1.2、代码需要4步1)logdir = './log' 2)将节点信息加入summary tf.summary.scalar('loss', loss_op) tf.summary.scalar('accuracy', accuracy) 3)开启会话前后分别合并summary.op+创建写入器 merged_summary = tf.summary.merge_all() # 将图形、训练过程等数据合并在一起,即将所有的想要的节点信息通过tf.summary.merge_all()打包为一个节点 with tf.Session() as sess: summary_writer = tf.summary.FileWriter(logdir, graph=tf.get_default_graph()) # 将训练日志写入到logdir文件夹下,为后续的写入磁盘创建接口 4)、在内外循环之间给合并的merged_summary喂数据,即在训练过程中运行打包后的节点,并获取序列化的节点信息 result1 = sess.run(merged_summary, feed_dict={X: mnist.test.images[:256], Y: mnist.test.labels[:256], keep_prob: 1.0}) summary_writer.add_summary(result1, j)#j是外循环的变量,为了将序列化的节点信息写入磁盘中的Events文件,这个操作通过写入器writer实现;
参考
https://jingyan.baidu.com/article/e9fb46e1c55ac93520f7666b.html
https://jingyan.baidu.com/article/e9fb46e1c55ac93520f7666b.html
2、虚线问题跑完代码可视化时,出现了如下曲线,很明显的,不想要那个碍事的虚线。。。那么,如何解决

叮叮当~方法来了

那是因为上面smoothing默认0.6将线给你平滑了。。。。虚线使我们真实的折线,实线是平滑后的。。。因此改成0,是不是很骚操作

有时候出现有些点没有显示出来,真的是着急死人。。。一度怀疑自己。。。
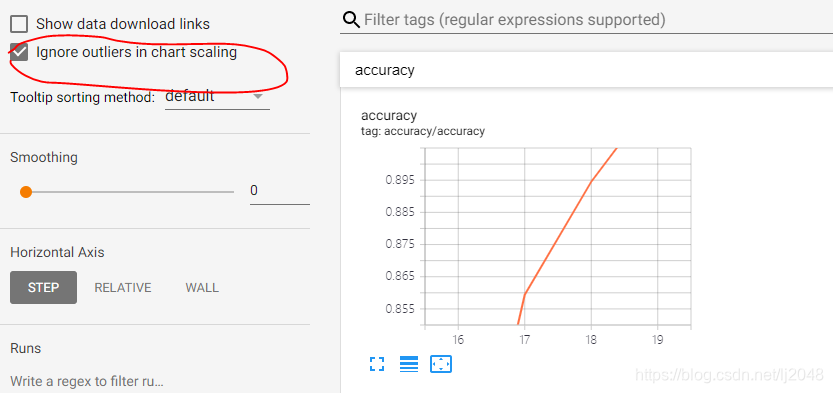
发现原来是圈起来的那里自动默认给圈住了异常值不显示。。。感觉很不友好!!!快到斩乱麻,勾选取消!!!

参考
tensorboard 中ignore outliers in chart scaling的含义? - 知乎
tensorboard同时显示训练数据和测试数据的曲线 - 极客分享
4、有趣的网络tensorboard正常在浏览器中可视化后,默认打开的是scalars,就是我们代码跑的折线图,点击上面的GRAPHS可以看到我们详细的模型结构图,是不是很有趣,哈哈哈哈嗝~


