
转载
目录
大纲
GCN中暴露的问题
DGL
NodeFlow
Neighbor Sampling
具体实现
Control Variate
后话
Reference
大纲本文为GNN教程的系列干货。之前介绍了DGL这个框架,以及如何使用DGL编写一个GCN模型,用在学术数据集上,这样的模型是workable的。然而,现实生活中会遇到非常庞大的图数据,庞大到邻接矩阵和特征矩阵不能同时塞进内存中,这时如何解决这样的问题呢?
DGL采用了和GraphSAGE类似的邻居采样策略,通过构建计算子图缩小了每次计算的图规模,这篇博文将会介绍DGL提供的采样模型。

解决这个问题的方式,正如我们在GraphSAGE的博文中提到的那样,通过mini-batch训练的方式,每次只构建该batch内节点的一个子图进行更新。DGL这个框架自version 0.3之后正式支持这种mini-batch的训练方式,下面我们重点介绍一下它的编程框架。
DGL和GraphSAGE中一致,DGL将mini-batch 训练的前期准备工作分为两个层面,首先建立为了更新一个batch内节点embedding而需要的所有邻居节点信息的子图,其次为了保证子图的大小不会受到”超级节点“影响,通过采样的技术将每个节点的邻居个数保持一致,使得这一批节点和相关邻居的embedding能够构成一个Tensor放入显卡中计算。
这两个模块分别叫NodeFlow和Neighbor Sampling,下面来详细得介绍它们。
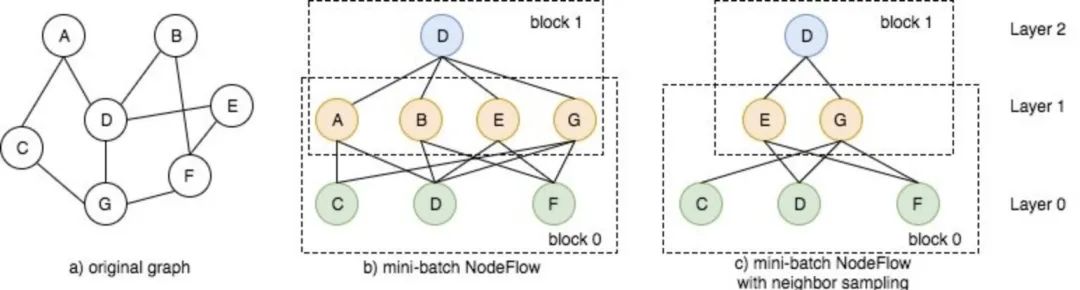
记一个batch内需要更新embedding的节点集合为![]() ,从这个节点集合出发,我们可以根据边信息查找计算所要用到的所有邻居节点,比如在下图的例子中,
,从这个节点集合出发,我们可以根据边信息查找计算所要用到的所有邻居节点,比如在下图的例子中,
- 图结构如a)所示,假设我们使用的是2层GCN模型(每个节点的更新考虑其2度以内的邻居embedding),某个batch内我们需要更新节点D的embedding
- 根据更新规则,为了更新,我们需要其一度节点的embedding信息,即需要节点ABEG,而这些节点的更新又需要节点CDF的embedding。
- 因此我们的计算图如图b)所示,先由CDF(Layer 0)更新的embedding,再由ABEG的embedding更新D的embedding。这样的计算图在DGL中叫做
NodeFlow。
NodeFlow是一种层次结构的图,节点被组织在层之内(比如上面例子中2层的GCN节点分布在Layer0, Layer1 和 Layer2中),只有在相邻的层之间才存在边,两个相邻的层称为块(block)。NodeFlow是反向建立(从内到外建立,图b的从上到下)的,首先确立一个batch内需要更新的节点集合(即Layer2中的节点),然后这个节点的1阶邻居构成了NodeFlow的下一层(即Layer1中的节点),再将下一层的节点当做是需要更新的节点集合,重复该操作,直到建立好所有层节点信息。
通过这种方式,在每个batch的训练中,我们实际上将原图a)转化成了一个子图b),因此当原图很大无法塞进内存的时候,我们可以通过调小batch_size解决这样的问题。
根据逐层更新公式可知,每一个block之间的计算是完全独立的,因此NodeFlow提供了函数block_compute以提供底层embedding向高层的传递和计算工作。
现实生活中的图的节点分布常常是长尾的,这意味着有一些“超级节点”的度非常高,而还有一大部分节点的度很小。如果我们在NodeFlow的建立过程中关联到“超级节点“的话,”超级节点“就会为NodeFlow的下一层带来很多节点,使得整个NodeFlow非常庞大,违背了设计小的计算子图的初衷。为了解决这样的问题,GraphSAGE提出了邻居采样的策略,通过为每个节点采样一定数量的邻居来近似,加上采样策略之后,节点embedding的更新公式变为(相比GCN,也就是对A进行限定多个采样):
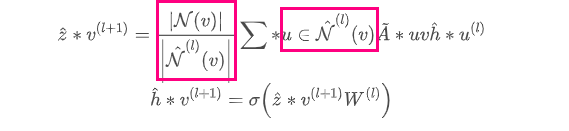

如假设每次规定采样2个节点,那么上面的图b最后变成图c,因为对中心节点D采样的时候,采样2个,本例子中选择的是 EG这两个邻居,再次分别对EG采样他们的2个邻居,本例子是DF和CF但同时又和D相连。
具体实现在具体实现中,采样和计算是两个独立的模型,也就是说,我们通过采样获得子图,再将这个子图输入到标准的GCN模型中训练,这种解耦合的方式使模型变得非常灵活,因为我们可以对采样的方式进行定制,比如Stochastic Training of Graph Convolutional Networks with Variance Reduction选择特定的邻居以将方差控制在一定的范围内。这种模型与采样分离的方式也是大部分支持超大规模图计算框架的方式(包括这里介绍的DGL,之后我们要介绍的Euler)。
DGL提供NeighborSampler类来构建采样后的NodeFlow,NeighborSampler返回的是一个迭代器,生成NodeFlow实例,们来看看DGL提供的一个结合采样策略的GCN实例代码:
note:因为nodeflow是从采样获取到的实例,因此只有拓扑结构,没有节点其他的数据信息,想要获取(如节点表示)的话,使用copy_from_parent
# dropout probability
dropout = 0.2
# batch size
batch_size = 1000
# number of neighbors to sample
num_neighbors = 4
# number of epochs
num_epochs = 1
# initialize the model and cross entropy loss
model = GCNSampling(in_feats, n_hidden, n_classes, L,
mx.nd.relu, dropout, prefix='GCN')
model.initialize()
loss_fcn = gluon.loss.SoftmaxCELoss()
# use adam optimizer
trainer = gluon.Trainer(model.collect_params(), 'adam',
{'learning_rate': 0.03, 'wd': 0})
for epoch in range(num_epochs):
i = 0
for nf in dgl.contrib.sampling.NeighborSampler(g, batch_size,
num_neighbors,
neighbor_type='in',
shuffle=True,
num_hops=L,
seed_nodes=train_nid):
# When `NodeFlow` is generated from `NeighborSampler`, it only contains
# the topology structure, on which there is no data attached.
# Users need to call `copy_from_parent` to copy specific data,
# such as input node features, from the original graph.
nf.copy_from_parent()
with mx.autograd.record():
# forward
pred = model(nf)
batch_nids = nf.layer_parent_nid(-1).astype('int64')
batch_labels = labels[batch_nids]
# cross entropy loss
loss = loss_fcn(pred, batch_labels)
loss = loss.sum() / len(batch_nids)
# backward
loss.backward()
# optimization
trainer.step(batch_size=1)
print("Epoch[{}]: loss {}".format(epoch, loss.asscalar()))
i += 1
# We only train the model with 32 mini-batches just for demonstration.
if i >= 32:
break
上面的代码中,model由GCNsampling定义,虽然它的名字里有sampling,但这只是一个标准的GCN模型,其中没有任何和采样相关的内容,和采样相关代码的定义在dgl.contrib.sampling.Neighborsampler中,使用图结构g初始化这个类,并且定义采样的邻居个数num_neighbors,它返回的nf即是NodeFlow实例,采样后的子图。因为nf只会返回子图的拓扑结构,不会附带节点Embedding,所以需要调用copy_from_parent()方法来获取Embedding,layer_parent_nid返回该nodeflow中每一层的节点id,根据上面的图示,当前batch内的节点(称为种子节点)位于最高层,所以layer_parent_nid(-1)返回当前batch内的节点id。剩下的步骤就是一个标准的模型训练代码,包括前向传播,计算loss,反向传播在此不再赘述。

具体到我们的场景上,X是某次采样节点邻居的聚合,Y是该节点所有邻居的聚合。基于control variate的方法训练GCN的过程为(相比如基于采样的方法,对中间h的计算进行了调整-减去一值):
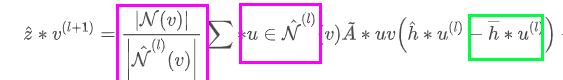
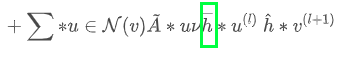
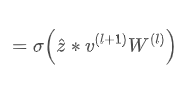
那么上面的代码可以按照这种思路改写为:
g.ndata['h_0'] = features
for i in range(L):
g.ndata['h_{}'.format(i+1)] = mx.nd.zeros((features.shape[0], n_hidden))
# With control-variate sampling, we only need to sample 2 neighbors to train GCN.
for nf in dgl.contrib.sampling.NeighborSampler(g, batch_size, expand_factor=2,
neighbor_type='in', num_hops=L,
seed_nodes=train_nid):
for i in range(nf.num_blocks):
# aggregate history on the original graph
g.pull(nf.layer_parent_nid(i+1),
fn.copy_src(src='h_{}'.format(i), out='m'),
lambda node: {'agg_h_{}'.format(i): node.mailbox['m'].mean(axis=1)})
nf.copy_from_parent()
h = nf.layers[0].data['features']
for i in range(nf.num_blocks):
prev_h = nf.layers[i].data['h_{}'.format(i)]
# compute delta_h, the difference of the current activation and the history
nf.layers[i].data['delta_h'] = h - prev_h
# refresh the old history
nf.layers[i].data['h_{}'.format(i)] = h.detach()
# aggregate the delta_h
nf.block_compute(i,
fn.copy_src(src='delta_h', out='m'),
lambda node: {'delta_h': node.data['m'].mean(axis=1)})
delta_h = nf.layers[i + 1].data['delta_h']
agg_h = nf.layers[i + 1].data['agg_h_{}'.format(i)]
# control variate estimator
nf.layers[i + 1].data['h'] = delta_h + agg_h
nf.apply_layer(i + 1, lambda node : {'h' : layer(node.data['h'])})
h = nf.layers[i + 1].data['h']
# update history
nf.copy_to_parent()
上文代码中,nf是NeighborSampler返回的对象,在nf的对象的每一个block内,首先调用pull函数获取(即代码中的agg_h_{}),然后计算和(即代码中的delta_h和agg_h),最后将更新后的结果拷贝回原大图中。
这一篇博文介绍了DGL这个框架怎么对大图进行计算的,总结起来,它吸取了GraphSAGE的思路,通过为每个mini-batch构建子图并采样邻居的方式将图规模控制在可计算的范围内。这种采样-计算分离的模型基本是目前所有图神经网络计算大图时所采用的策略。
有两个细节没有介绍,第一、具体的采样方法,对于邻居的采样方法有很多种,除了最容易想到的重采样/负采样策略很多学者还提出了一些更加优秀的策略,之后我们会在"加速计算、近似方法"模块中详细讨论这些方法的原理;第二、对于超大规模的图,很多框架采用的是分布式的方式,典型的如Euler,这一系列我们还将写一篇关于Euler的博文,介绍它与DGL的异同,它的分布式架构和在超大规模图计算上做的创新。
ReferenceDGL Tutorial on NodeFlow and Neighbor Sampling

