
本文转载自:AI科技评论
作者 | 于旭敏 编辑 | 王晔
我们提出了一种几何敏感的点云补全Transformer,通过将点云表示成为一组无序的点代理,并采用Transformer的Encoder-Decoder结构进行缺失点云生成。除此以外,我们提出了两个更具有挑战性的点云补全Benchmark——ShapeNet-55/34。我们的论文已被ICCV接收为Oral Presentation,代码、数据集与模型均以开源。

PoinTr: Diverse Point Cloud Completion with Geometry-Aware Transformers
代码仓库:https://github.com/yuxumin/PoinTr
论文链接:https://arxiv.org/abs/2108.08839
视频:https://youtu.be/mSGphas0p8g
1
简介
在现实场景下,现有的3D传感器由于物体自遮挡等问题只能采集到缺失且稀疏的点云数据,所以如何将这样缺失且稀疏的点云进行补全以得到高品质的点云,具有重大意义。
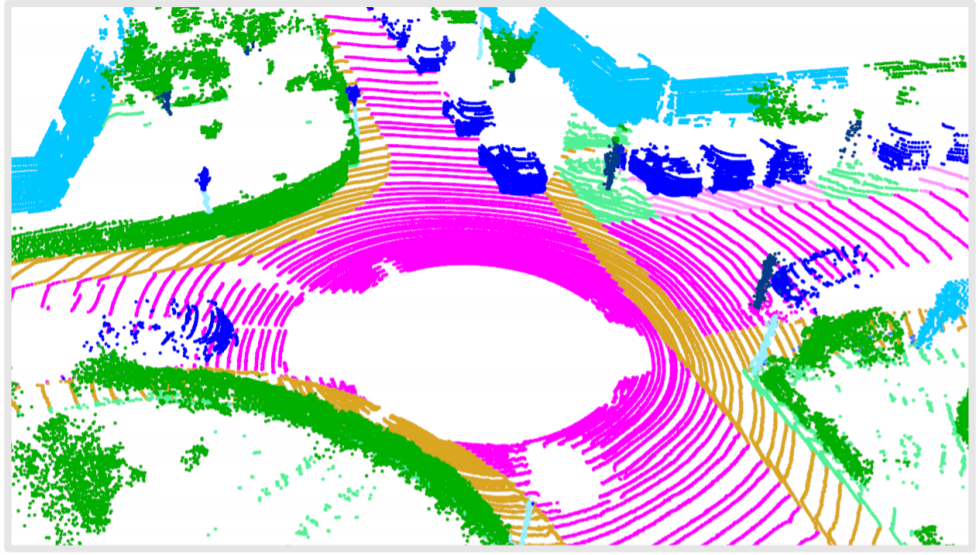
想要借助无序且缺乏结构的点云数据进行3D物体形状的补全,我们需要充分挖掘已知点云中的结构信息与长程关系。为此,我们将点云补全问题建模为一个集合到集合的翻译问题,即通过已知的点云的信息翻译得到缺失部分的点云。我们提出了PoinTr模型,其核心在于通过Transformer-Encoder充分建模已知点云的结构信息与点间关系,再通过Transformer-Decoder学习缺失部分与存在部分的相互关系并以此重建缺失点云。
同时我们提出两个更具挑战性的点云补全Benchmark,用以检验点云补全模型在更贴近真实条件下的补全表现。其中ShapeNet-55相比于PCN数据集考虑了更多样的任务(点云补全与点云上采样)、更多样的种类(从原本的8类到55类)、更多样的缺失视角(从原本的8视角到任意可能视角)以及更多样级别的缺失(缺失25%到75%的点云);ShapeNet-34则可以测试模型在训练集中不存在的类别的物体上的补全表现。

(ShapeNet-55/34数据集)
2
方法
下面介绍我们的整体框架,我们提出的PoinTr主体由Transformance Encoder-Decoder构成:

简单来说,在对点云进行补全时,我们会先将点云处理成为固定数目的点代理,方便作为Transformer的输入;然后我们通过Encoder对现有点云进行编码,通过Query Generator后生成第一阶段的点云中心和对应的动态Queries;最后这些Queries通过Decoder被翻译成点代理,点代理经过一个FoldingNet得到相对于特定中心点的偏移量,通过将对应中心进行移动,我们可以得到某个点代理对应的局部点云。
-
点代理生成:
想要将点云作为Transformer的输入,首先我们需要将点云处理成一个序列。最简单的想法是将每一个点作为序列的一个元素作为输入,但是这样会带来非常大的计算资源负担。所以我们提出可以将点云处理成一系列的点代理,用来代表点云上的一个局部区域特征。首先,我们对点云进行最远点采样(FPS),得到固定的N个中心点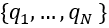 ;然后,我们使用一个轻量的DGCNN对局部区域进行特征提取,这样我们可以得到N个局部区域的特征
;然后,我们使用一个轻量的DGCNN对局部区域进行特征提取,这样我们可以得到N个局部区域的特征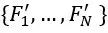 ,其中
,其中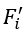 对应了以
对应了以 为中心点的区域的特征。最后,我们利用一个MLP网络
为中心点的区域的特征。最后,我们利用一个MLP网络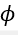 ,提取每一个局部特征的位置嵌入(positional embedding),相加后得到点代理,即
,提取每一个局部特征的位置嵌入(positional embedding),相加后得到点代理,即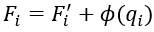 ,作为Encoder的输入。
,作为Encoder的输入。
-
Encoder-Decoder结构:
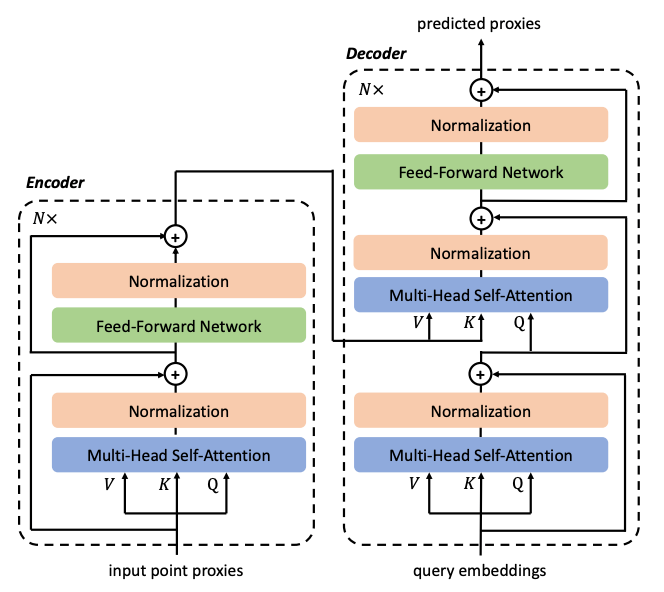
如上图所示,Encoder由多头自注意力层(multi-headself-attention layer)与前馈神经网络(feed-forward network)组成,Decoder则由多头自注意力层、编码器解码器交叉注意力层和前馈神经网络构成。
-
几何敏感的Transformer:

我们针对点云输入设计了一种即插即用的新型transformer block。在原本的transformer 模块中,网络只利用自注意力机制挖掘不同部分之间的关系,这其实是一种基于特征相似度的长程语义关系,为了利用点云数据的归纳偏置,我们将局部几何关系补充到自注意力模块。
我们根据点代理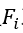 对应的三维点坐标
对应的三维点坐标 ,使用kNN将空间中相邻的点代理拼接在一起,使用一层线性层进行局部几何信息学习,通过将该结果和自注意力机制的结果进行融合,我们可以同时挖掘长程语义相关性,也同时保留了有效的局部几何关系,有效的提高了模型的性能。
,使用kNN将空间中相邻的点代理拼接在一起,使用一层线性层进行局部几何信息学习,通过将该结果和自注意力机制的结果进行融合,我们可以同时挖掘长程语义相关性,也同时保留了有效的局部几何关系,有效的提高了模型的性能。
-
Query生成器:
Queries是待预测点代理的初始状态,用于指导缺失点云的重建。我们首先通过Encoder的输出特征得到全局特征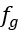 ,如最大池化,并通过一个线性层预测粗略的缺失点云中心点坐标
,如最大池化,并通过一个线性层预测粗略的缺失点云中心点坐标 。将缺失点云中心点坐标与全局特征拼接后,用一个多层感知机生成query特征,即
。将缺失点云中心点坐标与全局特征拼接后,用一个多层感知机生成query特征,即
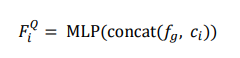
-
点云预测:
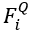 通过Decoder被翻译为一个点代理
通过Decoder被翻译为一个点代理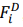 ,该点代理对应了
,该点代理对应了 以为中心的局部点云。我们利用FoldingNet对点代理进行偏移坐标重建:即
以为中心的局部点云。我们利用FoldingNet对点代理进行偏移坐标重建:即

最后我们将输入点云与预测结果进行拼接,即可以得到最终的预测结果。
3
实验结果
首先我们将PoinTr和现有一些方法在ShapeNet-55与ShapeNet-34上进行了实验,在Simple,Moderate与Hard三个难度下(缺失25%,50%,75%点云),PoinTr在Chamfer Distance与F1指标上都取得了最好表现;
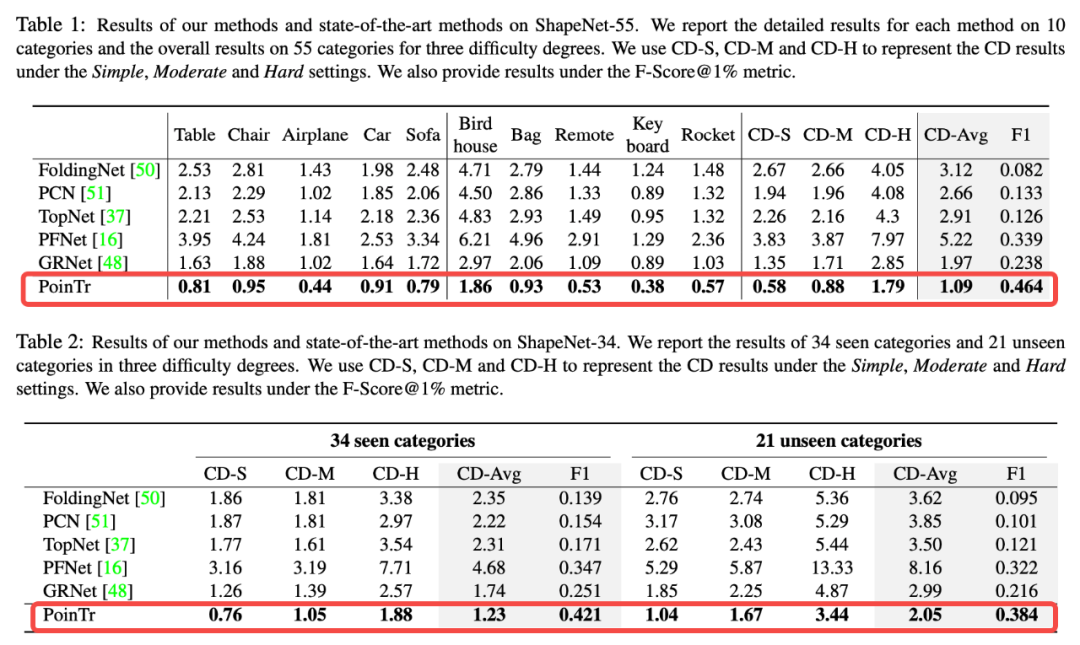
同时我们也在PCN数据集上进行了测试,也取得了最好表现。
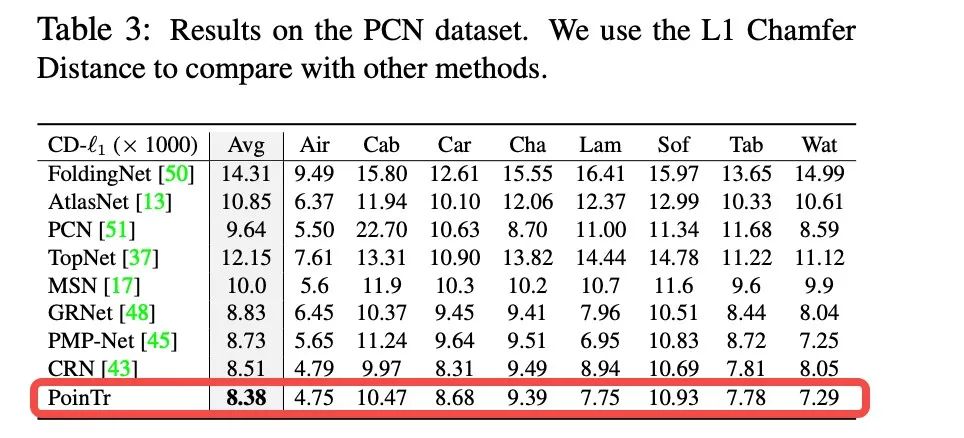
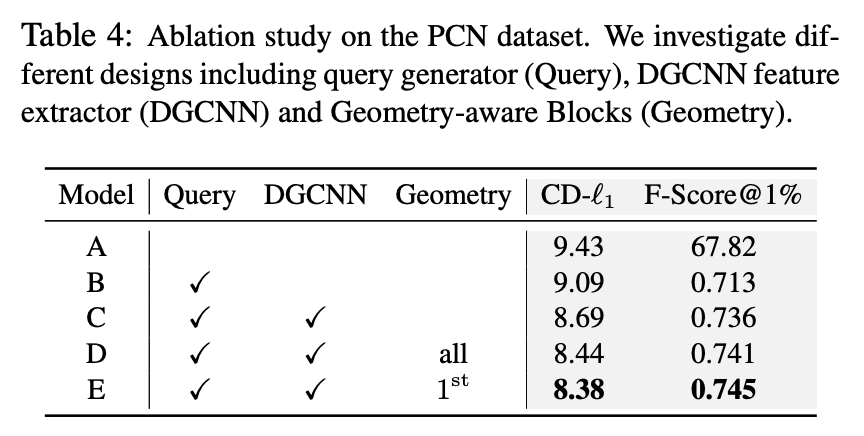
为了验证我们提出的方法的有效性,我们对我们的方法进行了消融实验,可见我们提出的方法都有效提高了Transformer模型在点云补全任务上的效果。
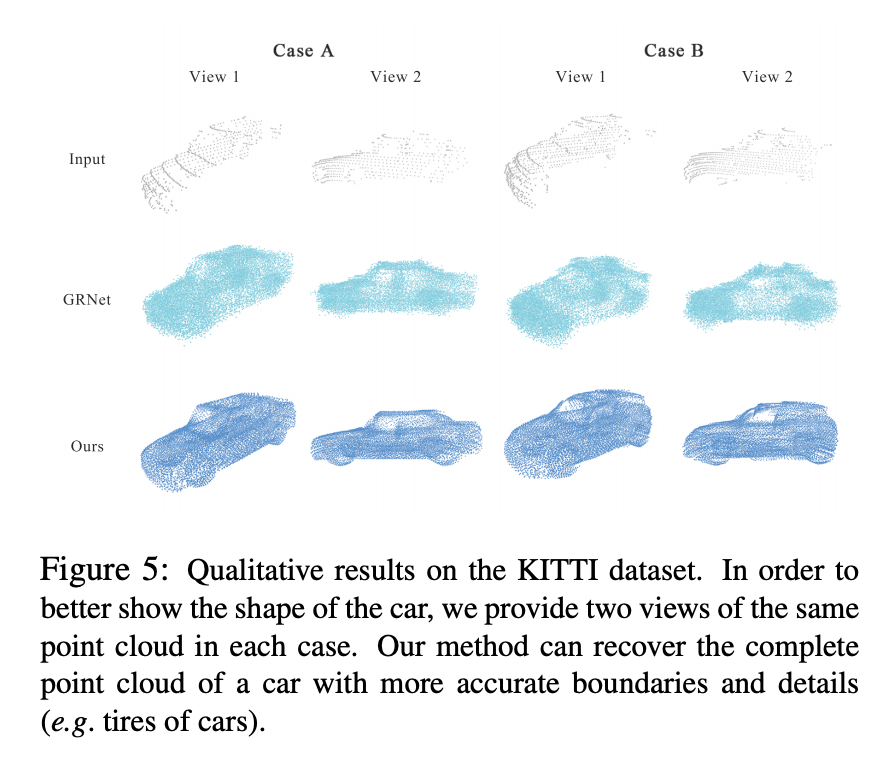
最后我们使用我们的方法对真实雷达数据进行补全,在数值结果和可视化结果下都取得了提升。

4
总结
在这项工作中,我们提出了适合点云补全的PoinTr模型,很好地将Transformers引入到点云补全任务中,并在已有的合成数据集与真实数据集上取得了目前最好性能。除此以外,我们提出了更具挑战性的ShapeNet-55和ShapeNet-34,来模拟真实条件下的复杂缺失场景。我们希望本文提出的PoinTr和新的Benchmark可以为未来点云补全提供思路与启发。
参考文献:
[1]Ashish Vaswani, Noam Shazeer,Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Lukasz Kaiser, andIllia Polosukhin. Attention is All You Need. NeurIPS, pages 5998–6008, 2017.
[2]Haozhe Xie, Hongxun Yao, Shangchen Zhou, Jiageng Mao,Shengping Zhang, and Wenxiu Sun. GRNet: Gridding Residual Network for Dense PointCloud Completion. ECCV, pages 365–381, 2020.
[3]Wentao Yuan, Tejas Khot, David Held, Christoph Mertz,and Martial Hebert. PCN: Point Completion Network. 3DV, pages 728–737, 2018.
[4]Zhirong Wu, Shuran Song, Aditya Khosla, Fisher Yu,Linguang Zhang, Xiaoou Tang, and Jianxiong Xiao. 3D ShapeNets: A Deep Representationfor Volumetric Shapes. CVPR, pages 1912–1920, 2015.
[5]Andreas Geiger, Philip Lenz, Christoph Stiller, andRaquel Urtasun. Vision Meets Robotics: The KITTI Dataset. International Journalof Robotics Research, 2013.
本文仅做学术分享,如有侵权,请联系删文。
下载1
在「3D视觉工坊」公众号后台回复:3D视觉,即可下载 3D视觉相关资料干货,涉及相机标定、三维重建、立体视觉、SLAM、深度学习、点云后处理、多视图几何等方向。
下载2
在「3D视觉工坊」公众号后台回复:3D视觉github资源汇总,即可下载包括结构光、标定源码、缺陷检测源码、深度估计与深度补全源码、点云处理相关源码、立体匹配源码、单目、双目3D检测、基于点云的3D检测、6D姿态估计源码汇总等。
下载3
在「3D视觉工坊」公众号后台回复:相机标定,即可下载独家相机标定学习课件与视频网址;后台回复:立体匹配,即可下载独家立体匹配学习课件与视频网址。
重磅!3DCVer-学术论文写作投稿 交流群已成立
扫码添加小助手微信,可申请加入3D视觉工坊-学术论文写作与投稿 微信交流群,旨在交流顶会、顶刊、SCI、EI等写作与投稿事宜。
同时也可申请加入我们的细分方向交流群,目前主要有3D视觉、CV&深度学习、SLAM、三维重建、点云后处理、自动驾驶、多传感器融合、CV入门、三维测量、VR/AR、3D人脸识别、医疗影像、缺陷检测、行人重识别、目标跟踪、视觉产品落地、视觉竞赛、车牌识别、硬件选型、学术交流、求职交流、ORB-SLAM系列源码交流、深度估计等微信群。
一定要备注:研究方向+学校/公司+昵称,例如:”3D视觉 + 上海交大 + 静静“。请按照格式备注,可快速被通过且邀请进群。原创投稿也请联系。

▲长按加微信群或投稿

▲长按关注公众号
3D视觉从入门到精通知识星球:针对3D视觉领域的视频课程(三维重建系列、三维点云系列、结构光系列、手眼标定、相机标定、orb-slam3等视频课程)、知识点汇总、入门进阶学习路线、最新paper分享、疑问解答五个方面进行深耕,更有各类大厂的算法工程人员进行技术指导。与此同时,星球将联合知名企业发布3D视觉相关算法开发岗位以及项目对接信息,打造成集技术与就业为一体的铁杆粉丝聚集区,近2000星球成员为创造更好的AI世界共同进步,知识星球入口:
学习3D视觉核心技术,扫描查看介绍,3天内无条件退款

圈里有高质量教程资料、答疑解惑、助你高效解决问题
觉得有用,麻烦给个赞和在看~ 

