
来源 | PaperWeekly 作者 | 洛英 编辑 | 极市平台
Vision Transformer 如今已经成为了一个热门的方向,Self-Attention 机制为视觉信息的表示和融合都带来了新的思路。那么问题来了,作为 Attention 机制的一种,Self-Attention 会呈现出怎样的一种 Q K V 交互模式呢?为了搞清这个问题,我们只要将 Vit 中间的 Attention Map 拿出来看看不就行了嘛,然而把 Attention Map 拿出来可不是那么简单的事情。
为了可视化 Attention Map,你是否有以下苦恼:
-
Return 大法好:通过 return 将嵌套在模型深处的 Attention Map 一层层地返回回来,然后训练模型的时候又不得不还原;
-
全局大法好:使用全局变量在 Attention 函数中直接记录 Attention Map,结果训练的时候忘改回来导致 OOM。
不管你有没有,反正我有,由于可视化分析不是一锤子买卖,实际过程中你往往需要在训练-可视化-训练-可视化两种状态下反复横跳,所以不适合采用以上两种方式进行可视化分析。
1 PyTorch hook 的局限性咨询了专业人士的意见后,发现 pytorch 有个 hook 可以取出中间结果,大概查了一下,发现确实可以取出中间变量,但需要进行如下类似的 hook 注册。
handle = net.conv2.register_forward_hook(hook)
这样我们就可以拿出来 net.conv2 这层的输出啦。然而!进行这样操作的前提是我们知道要取出来的模块名,但是 Transformer 类模型一般是这样定义的(以 Vit 为例)。
class VisionTransformer(nn.Module): def __init__(self, *args, **kwargs): ... self.blocks = nn.Sequential(*[Block(...) for i in range(depth)])
然后每个Block中都有一个Attention。
class Block(nn.Module): def __init__(self, *args, **kwargs): ... self.attn = Attention(...) ...
然后我们想要的 attention map 又在 Attention 里面。
class Attention(nn.Module): def __init__(self, dim, num_heads=8, qkv_bias=False, attn_drop=0., proj_drop=0.): super().__init__() ... def forward(self, x): B, N, C = x.shape qkv = self.qkv(x).reshape(B, N, 3, self.num_heads, C // self.num_heads).permute(2, 0, 3, 1, 4) q, k, v = qkv[0], qkv[1], qkv[2] # make torchscript happy (cannot use tensor as tuple) attn = (q @ k.transpose(-2, -1)) * self.scale attn = attn.softmax(dim=-1) attn = self.attn_drop(attn) # <-在这 x = (attn @ v).transpose(1, 2).reshape(B, N, C) x = self.proj(x) x = self.proj_drop(x) return x
如果想要用 hook 来取出 Vit 中的 Attention Map,存在的问题就是:
-
嵌套太深,模块名不清晰,我们根本不知道我们要取的 attention map 怎么以 model.bla.bla.bla 这样一直点出来!
-
一般来说,Transformer 中 attention map 每层都有一个,一个个注册实在太麻烦了。那怎么办呢....
Visualizer!
所以我就思考并查找能否通过更简洁的方法来得到 Attention Map(尤其是 Transformer 的),而 visualizer 就是其中的一种,它具有以下特点:
-
精准直接,你可以取出任何变量名的模型中间结果;
-
快捷方便,一个操作,就可以同时取出 Transformer 类模型中的所有 attention map;
-
非侵入式,你无须修改函数内的任何一行代码;
-
训练-测试一致,可视化完成后,训练时无须再将代码改回来。
项目主页:https://github.com/luo3300612/Visualizer
首先,git clone 并安装它:
python setup.py install
使用方法非常简单!只需要用 get\_local 装饰一下 Attention 的函数,forward 之后就可以拿到函数内与装饰器参数同名的局部变量。
使用方法一比如说,我想要函数里的 attention_map 变量。在模型文件里,我们这么写:
from visualizer import get_local@get_local('attention_map') # 我要拿attention_map这个变量,所以把他传参给get_localdef your_attention_function(*args, **kwargs): ... attention_map = ... ... return ...
在可视化代码里,我们这么写:
from visualizer import get_localget_local.activate() # 激活装饰器from ... import model # 被装饰的模型一定要在装饰器激活之后导入!!# load model and data...out = model(data)cache = get_local.cache # -> {'your_attention_function': [attention_map]}
最终就会以字典形式存在 get_local.cache 里,其中 key 是你的函数名,value 就是一个存储 attention_map 的列表。
使用方法二使用 Pytorch 时我们往往会将模块定义成一个类,此时也是一样只要装饰类内计算出 attention_map 的函数即可:
from visualizer import get_localclass Attention(nn.Module): def __init__(self): ... @get_local('attn_map') def forward(self, x): ... attn_map = ... ... return ...
其他细节请参考:
https://nbviewer.jupyter.org/github/luo3300612/Visualizer/blob/main/demo.ipynb
可视化结果这里是部分可视化 vit_small 的结果,全部内容在 demo.ipynb 文件里。
因为普通 Vit 所有 Attention map 都是在 Attention.forward 中计算出来的,所以只要简单地装饰一下这个函数,我们就可以同时取出 vit 中 12 层 Transformer 的所有 Attention Map!
一个 Head 的结果:
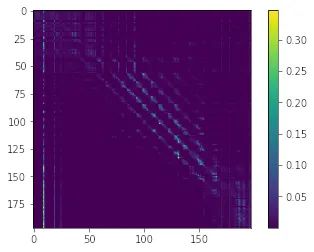
一层所有 Heads 的结果:

红色 grid 作为 query 的 Attention Map:

在可视化这张图片的过程中,我也发现了一些有趣的现象。首先,靠前层的 Attention 大多只关注自身,进行真·self attention 来理解自身的信息,比如这是第一层所有 Head 的 Attention Map,其特点就是呈现出明显的对角线模式。
随后,模型开始逐渐增大感受野,融合周围的信息,呈现出多条对角线的模式,如下分别是第 4、6 层的 Attention Map。


最后,重要信息聚合到某些特定的 token 上,Attention 出现与 query 无关的情况,在 Attention Map 上呈现出竖线的模式,如下第 11 层的 Attention Map:

当然,这些只是一张图片可视化的结果,说不定多看几张图片还有更多或者不同的结论呢。
注意在使用 visualizer 的过程中,有以下几点需要注意:
-
想要可视化的变量在函数内部不能被后续的同名变量覆盖了,因为 get_local 取的是对应名称变量在函数中的最终值;
-
进行可视化时,get_local.activate() 一定要在导入模型前完成,因为 python 装饰器是在导入时执行的;
-
训练时你不需要删除装饰的代码,因为在 get_local.activate() 没有执行的情况下,attention 函数不会被装饰,故没有任何性能损失(同上一点,因为 python 装饰器是在导入时执行的)。
当然,其实 get_local 本质就是获取一个函数中某个局部变量的最终值,所以它应该还有其他更有趣的用途。
4 小结Visualizer 是一个辅助深度学习模型中 Attention 模块可视化的小工具,主要功能是帮助取出嵌套在模型深处的 Attention Map,欢迎大家多多 star!
本文仅做学术分享,如有侵权,请联系删文。
下载1
在「3D视觉工坊」公众号后台回复:3D视觉,即可下载 3D视觉相关资料干货,涉及相机标定、三维重建、立体视觉、SLAM、深度学习、点云后处理、多视图几何等方向。
下载2
在「3D视觉工坊」公众号后台回复:3D视觉github资源汇总,即可下载包括结构光、标定源码、缺陷检测源码、深度估计与深度补全源码、点云处理相关源码、立体匹配源码、单目、双目3D检测、基于点云的3D检测、6D姿态估计源码汇总等。
下载3
在「3D视觉工坊」公众号后台回复:相机标定,即可下载独家相机标定学习课件与视频网址;后台回复:立体匹配,即可下载独家立体匹配学习课件与视频网址。
重磅!3DCVer-学术论文写作投稿 交流群已成立
扫码添加小助手微信,可申请加入3D视觉工坊-学术论文写作与投稿 微信交流群,旨在交流顶会、顶刊、SCI、EI等写作与投稿事宜。
同时也可申请加入我们的细分方向交流群,目前主要有3D视觉、CV&深度学习、SLAM、三维重建、点云后处理、自动驾驶、多传感器融合、CV入门、三维测量、VR/AR、3D人脸识别、医疗影像、缺陷检测、行人重识别、目标跟踪、视觉产品落地、视觉竞赛、车牌识别、硬件选型、学术交流、求职交流、ORB-SLAM系列源码交流、深度估计等微信群。
一定要备注:研究方向+学校/公司+昵称,例如:”3D视觉 + 上海交大 + 静静“。请按照格式备注,可快速被通过且邀请进群。原创投稿也请联系。

▲长按加微信群或投稿

▲长按关注公众号
3D视觉从入门到精通知识星球:针对3D视觉领域的视频课程(三维重建系列、三维点云系列、结构光系列、手眼标定、相机标定、orb-slam3等视频课程)、知识点汇总、入门进阶学习路线、最新paper分享、疑问解答五个方面进行深耕,更有各类大厂的算法工程人员进行技术指导。与此同时,星球将联合知名企业发布3D视觉相关算法开发岗位以及项目对接信息,打造成集技术与就业为一体的铁杆粉丝聚集区,近2000星球成员为创造更好的AI世界共同进步,知识星球入口:
学习3D视觉核心技术,扫描查看介绍,3天内无条件退款

圈里有高质量教程资料、答疑解惑、助你高效解决问题
觉得有用,麻烦给个赞和在看~ 

