前言
本文的文字及图片来源于网络,仅供学习、交流使用,不具有任何商业用途,如有问题请及时联系我们以作处理。
PS:如有需要Python学习资料的小伙伴可以加点击下方链接自行获取
python免费学习资料以及群交流解答点击即可加入
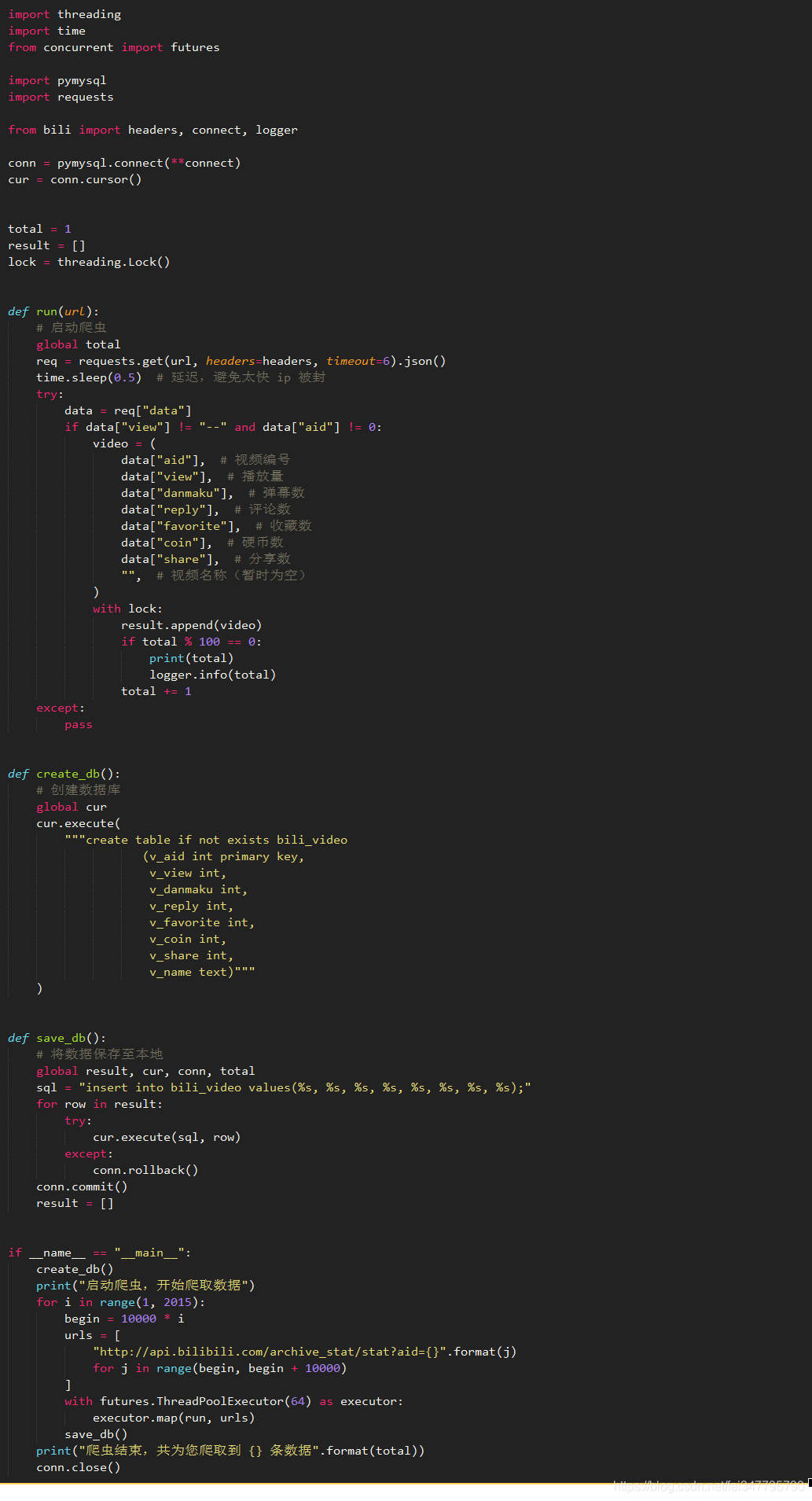
B 站我想大家都熟悉吧,其实 B 站的爬虫网上一搜一大堆。不过 纸上得来终觉浅,绝知此事要躬行,我码故我在。最终爬取到数据总量为 1300 万 条。
开发环境为:Windows10 + python3
准备工作
首先打开 B 站,随便在首页找一个视频点击进去。常规操作,打开开发者工具。这次是目标是通过爬取 B 站提供的 api 来获取视频信息,不去解析网页,解析网页的速度太慢了而且容易被封 ip。
勾选 JS 选项,F5 刷新
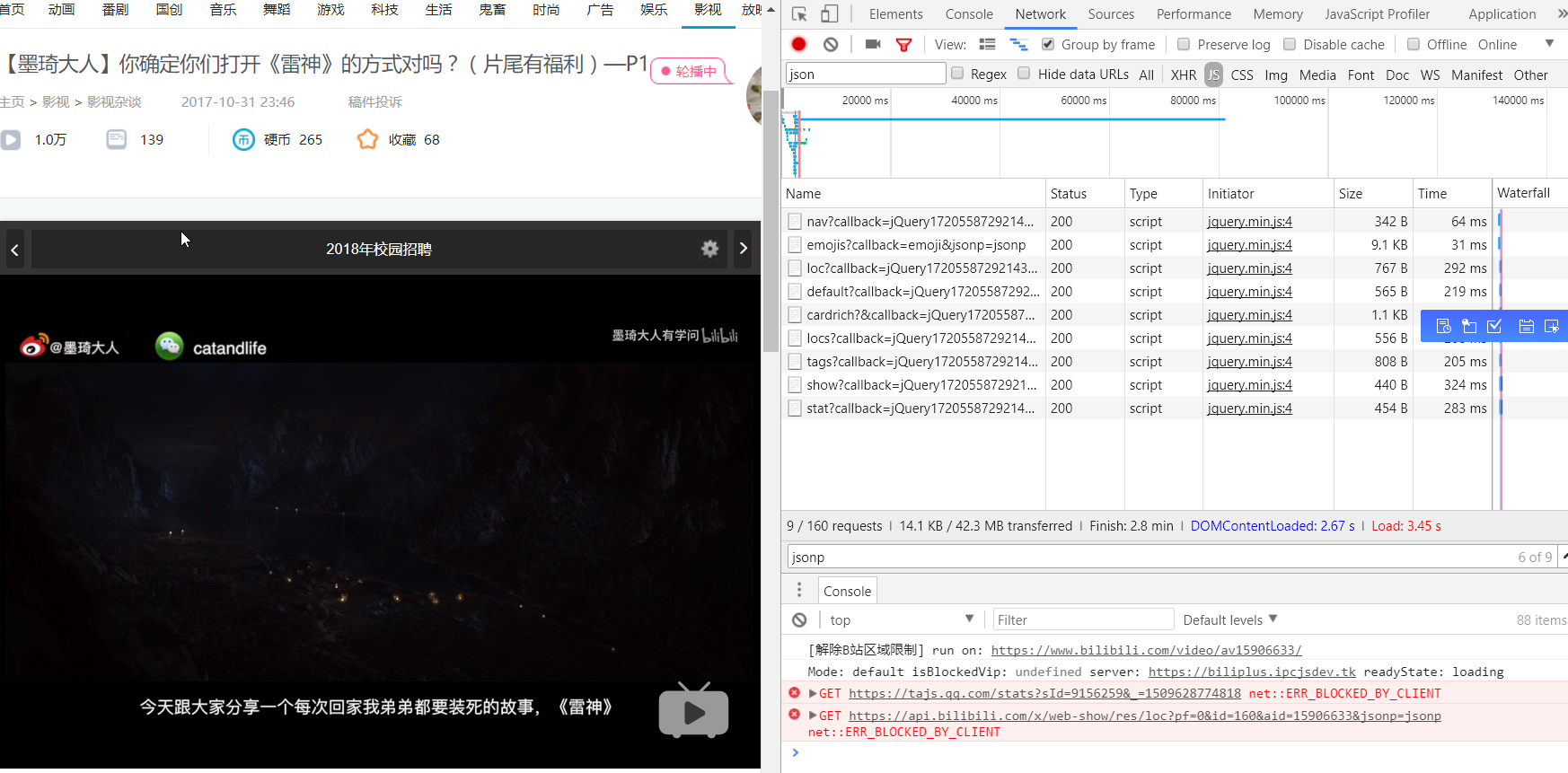
找到了 api 的地址
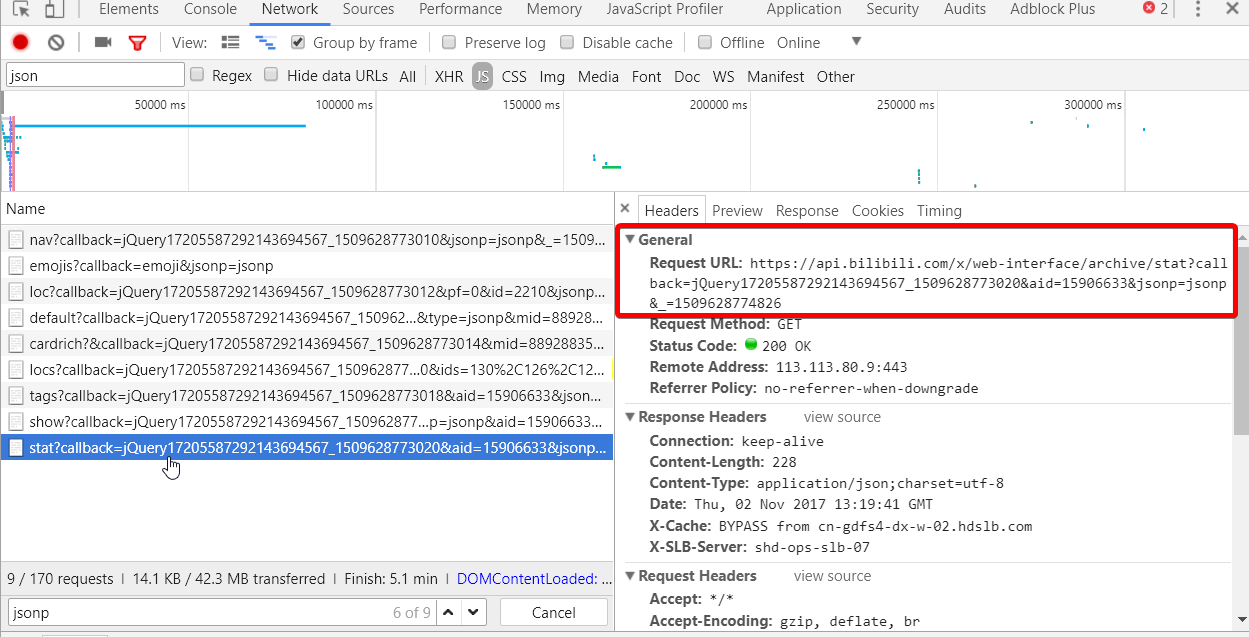
复制下来,去除没必要的内容,得到 https://api.bilibili.com/x/web-interface/archive/stat?aid=15906633 ,用浏览器打开,会得到如下的 json 数据

动手写码
好了,到这里代码就可以码起来了,通过 request 不断的迭代获取数据,为了让爬虫更高效,可以利用多线程。
核心代码
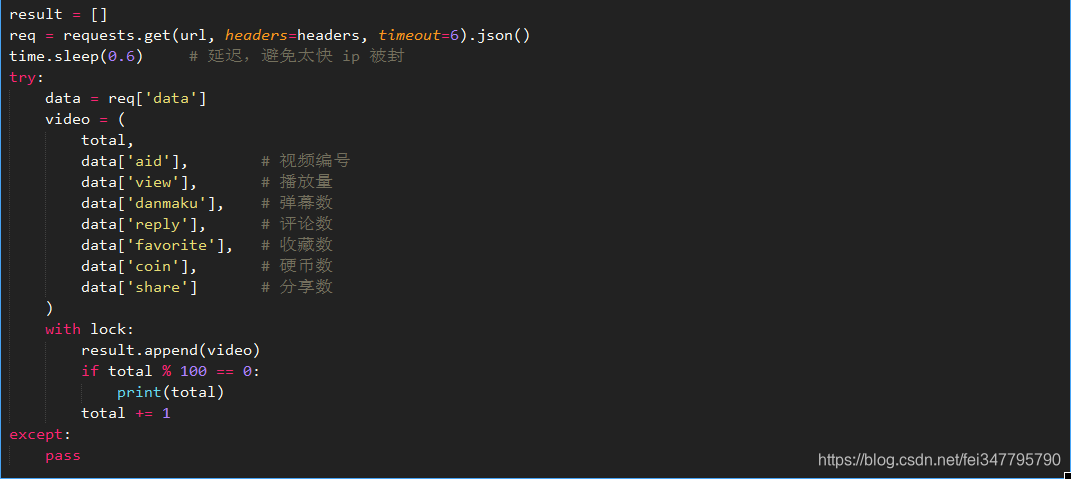
迭代爬取

爬取后数据存放进了 MySQL 数据库,总共爬取到了 1300w+ 条数据