
本文的文字及图片来源于网络,仅供学习、交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理。
作者: 朱小五 PS:如有需要Python学习资料的小伙伴可以加点击下方链接自行获取
python免费学习资料以及群交流解答点击即可加入
12月1日,《咬文嚼字》编辑部以一首“顺口溜”发布2019年度十大流行语。“文明互鉴”、“区块链”、“硬核”、“融梗”、“××千万条,××第一条”、“柠檬精”、“996”、“我太难/南了”、“我不要你觉得,我要我觉得”、“霸凌主义”十条流行语入选。
微博评论下有很多网友纷纷表示,XXX为什么能上榜?XXX为什么没上榜?
这点呢,小五表示理解,毕竟采用不同的统计口径得出的结论可能不同。
那么,小五干脆也自己定义个统计口径,重新“定义”一下【2019十大网络流行语】
获取数据通过搜索“网络流行语”,可以发现已经有网站帮我们做了整理。 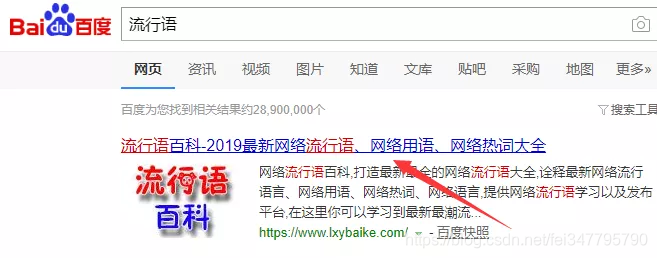 利用python爬虫可以获取该网站的2019年度所有网络流行语。
利用python爬虫可以获取该网站的2019年度所有网络流行语。
def main():
data = []
n = 1
for i in range(4542,5589):
dic = {}
url = 'https://www.lxybaike.com/index.php?doc-view-'+str(i)+'.html'
print('已成功采集{}条数据'.format(n))
html = restaurant(url)
doc = pq(html)
dic['tittle'] = doc('#doctitle').text()
dic['num'] = doc('#doc-aside > div.columns.ctxx > ul > li:nth-child(1)').text()
data.append(dic)
time.sleep(random.random())
n = n + 1
return data
爬取成功√
共929个词语。
我们在获取这些热门流行词的同时,也获取了他们的一些其他数据,比如浏览次数和出现时间。  但浏览次数很难作为评判这个词语是否热门的指标,毕竟大家又不是都来这个网站搜索,所以还是需要一个全网的数据才更准确一点。
但浏览次数很难作为评判这个词语是否热门的指标,毕竟大家又不是都来这个网站搜索,所以还是需要一个全网的数据才更准确一点。
一开始选择了百度指数,结果发现很多词语没有收录,需要付费。于是我就选用了搜狗指数! 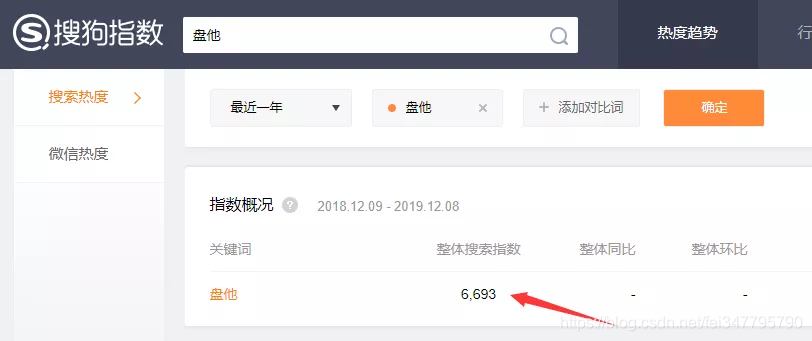 将刚才爬取得到的929个网络流行语,可以根据下面式子来构造url。
将刚才爬取得到的929个网络流行语,可以根据下面式子来构造url。
urls= 'http://zhishu.sogou.com/index/searchHeat?kwdNamesStr='+str(name)+'&timePeriodType=YEAR&dataType=SEARCH_ALL'
再循环爬取依次得到他们的年度平均搜索指数。
成功得到2019年度网络热门流行词排行榜(凹凸玩数据版)! 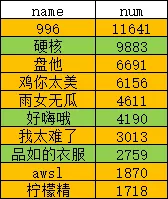 其中标记绿色的词语为2018年末出现,在2019年开始流行,在统计时也列入列入2019流行语中。
其中标记绿色的词语为2018年末出现,在2019年开始流行,在统计时也列入列入2019流行语中。
根据上文得到的热门流行词排行榜,小五又搜集了一些网上的资料 ,利用PS来制作了十张流行词的解释图。
下面开始颁奖: 








 一千个人眼中就有一千个哈姆雷特。
一千个人眼中就有一千个哈姆雷特。
相信每个人心里都有自己的一个流行语排行榜。
完整代码import requests
from pyquery import PyQuery as pq
import pandas as pd
import time
import random
from fake_useragent import UserAgent
ua = UserAgent()
headers = {'User-Agent':ua.random}
def main():
data = []
n = 1
for i in range(4543,4550): #自己设置id范围
dic = {}
url = 'https://www.lxybaike.com/index.php?doc-view-'+str(i)+'.html'
print('已成功采集{}条数据'.format(n))
html = requests.get(url,headers=headers).text
doc = pq(html)
dic['tittle'] = doc('#doctitle').text()
dic['num'] = doc('#doc-aside > div.columns.ctxx > ul > li:nth-child(1)').text().replace('浏览次数:','').replace(' 次','')
dic['zan'] = doc('#ding > span').text().replace('[','').replace(']','')
dic['id'] = i
data.append(dic)
time.sleep(random.random())
n = n + 1
return data
if __name__ == '__main__':
data = main()
final_result = pd.DataFrame(data)
final_result.to_csv('凹凸玩数据.csv',encoding="utf_8",index = False)

