不靠昂贵的动捕,直接通过视频也能提取3D人体模型然后进行生成训练:
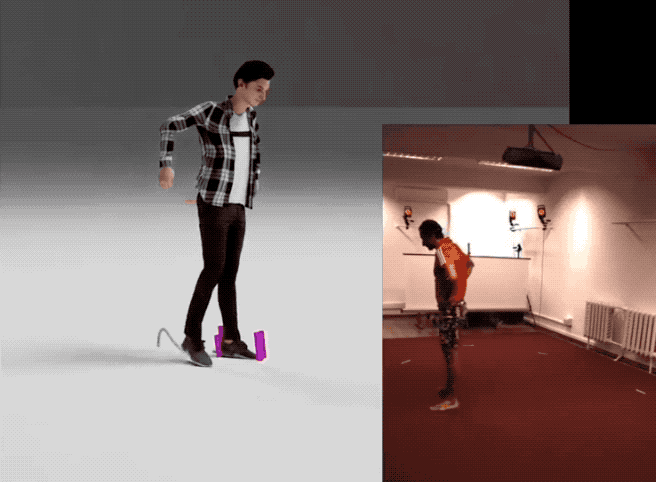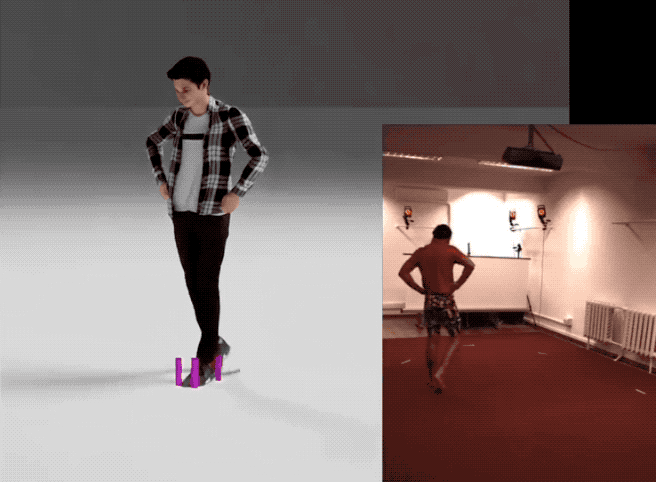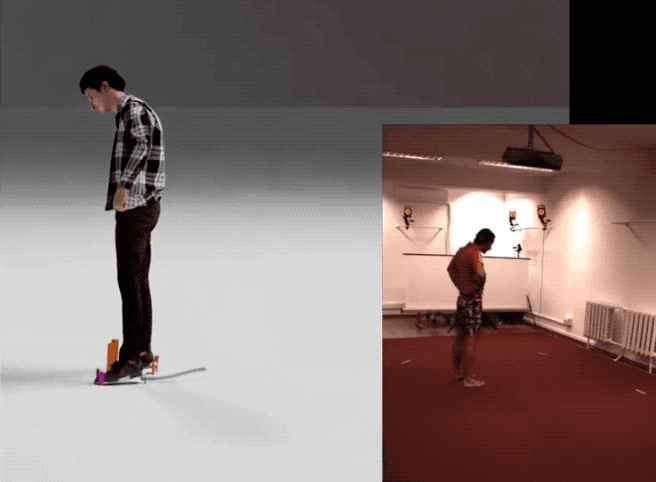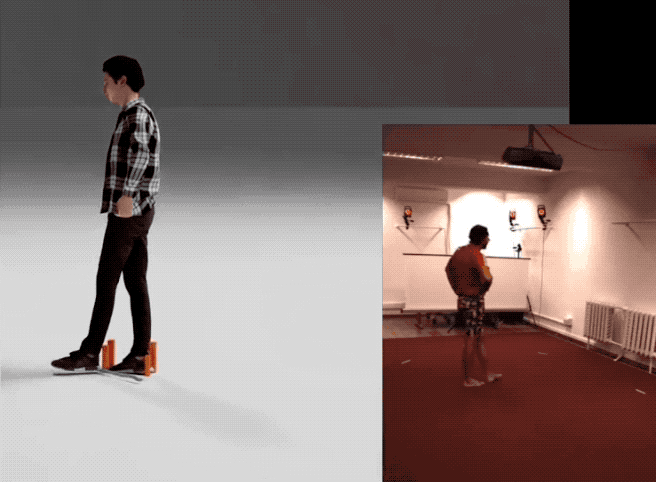

英伟达这项最新研究不仅省钱,效果也不错——
其合成的样本完全可以用在以往只在动捕数据集上训练的运动合成模型,且在合成动作的多样性上还能更胜一筹。
成果已被ICCV 2021接收。

下图概述了英伟达提出的这个从视频中获得动作样本的框架。

包含4步:
1、首先输入一个视频,使用单目姿势预估模型(pose estimator)生成由每帧图像组成的视频序列。
2、然后利用反向动力学,用每帧的3D关键点形成SMPL模型动作。
SMPL是一种参数化人体模型,也就是一种3D人体建模方法。
3、再使用他们提出的基于物理合理性的修正方法来优化上述动作;
4、 使用上述步骤处理所有视频,就可以使用获得的动作代替动捕来训练动作生成模型了。
概括起来就是用输入视频生成动作序列,然后建模成3D人体,再进行优化,最后就可以像使用标准动作捕捉数据集一样使用它们来训练你的动作生成模型。
下面是他们用该方法生成的一个样本合集:

研究人员对比了该方法与一些动捕模型,比如最新的PhysCap等。
PhysCap,一款基于AI算法的单目3D实时动捕方案。
结果发现,他们的方法在平均关节位置(MPJPE)的误差低于PhysCap。

其中的基于物理的修正方法更是将样本的脚切线速度误差降低40%以上,高度误差降低80%。

那用这些样本来训练生成模型的效果如何呢?
他们使用3个不同的训练数据集训练相同的DLow模型。
DLow(GT)是使用实际动捕数据进行训练的人体运动模型。 DLow(PE-dyn)是他们提出的方法,使用物理校正后的姿势训练。 DLow(PE-kin)也是他们的方法,没有优化过动作。
结果是DLow(PE-dyn)模型的多样性最好,超越了动捕数据集下的训练。
但在最终位移误差(FDE)和平均位移误差(ADE)上略逊一筹。

最后,作者表示,希望这个方法继续改进成熟以后,能够非常强大地利用身边的在线视频资源为大规模、逼真和多样的运动合成铺平道路。
作者信息Xie Kevin,多伦多大学计算机专业硕士在读,也是英伟达AI Lab的实习生。

王亭午,多伦多大学机器学习小组博士生,清华本科毕业,研究兴趣为强化学习和机器人技术,重点集中在迁移学习、模仿学习。

Umar Iqbal,英伟达高级研究科学家,德国波恩大学计算机博士毕业。

后面还有其他3位来自多伦多大学和英伟达的作者,就不一一介绍了。
论文地址: https://arxiv.org/abs/2109.09913
参考链接:
https://nv-tlabs.github.io/physics-pose-estimation-project-page/
本文仅做学术分享,如有侵权,请联系删文。
3D视觉精品课程推荐:
1.面向自动驾驶领域的多传感器数据融合技术 2.彻底搞透视觉三维重建:原理剖析、代码讲解、及优化改进 3.国内首个面向工业级实战的点云处理课程 4.激光-视觉-IMU-GPS融合SLAM算法梳理和代码讲解 5.彻底搞懂视觉-惯性SLAM:基于VINS-Fusion正式开课啦 6.彻底搞懂基于LOAM框架的3D激光SLAM: 源码剖析到算法优化 7.彻底剖析室内、室外激光SLAM关键算法原理、代码和实战(cartographer+LOAM +LIO-SAM)
干货领取:
1. 在「3D视觉工坊」公众号后台回复:3D视觉,即可下载 3D视觉相关资料干货,涉及相机标定、三维重建、立体视觉、SLAM、深度学习、点云后处理、多视图几何等方向。
2. 在「3D视觉工坊」公众号后台回复:3D视觉github资源汇总,即可下载包括结构光、标定源码、缺陷检测源码、深度估计与深度补全源码、点云处理相关源码、立体匹配源码、单目、双目3D检测、基于点云的3D检测、6D姿态估计源码汇总等。
3. 在「3D视觉工坊」公众号后台回复:相机标定,即可下载独家相机标定学习课件与视频网址;后台回复:立体匹配,即可下载独家立体匹配学习课件与视频网址。
重磅!3DCVer-学术论文写作投稿 交流群已成立
扫码添加小助手微信,可申请加入3D视觉工坊-学术论文写作与投稿 微信交流群,旨在交流顶会、顶刊、SCI、EI等写作与投稿事宜。
同时也可申请加入我们的细分方向交流群,目前主要有3D视觉、CV&深度学习、SLAM、三维重建、点云后处理、自动驾驶、多传感器融合、CV入门、三维测量、VR/AR、3D人脸识别、医疗影像、缺陷检测、行人重识别、目标跟踪、视觉产品落地、视觉竞赛、车牌识别、硬件选型、学术交流、求职交流、ORB-SLAM系列源码交流、深度估计等微信群。
一定要备注:研究方向+学校/公司+昵称,例如:”3D视觉 + 上海交大 + 静静“。请按照格式备注,可快速被通过且邀请进群。原创投稿也请联系。

▲长按加微信群或投稿

▲长按关注公众号
3D视觉从入门到精通知识星球:针对3D视觉领域的视频课程(三维重建系列三维点云系列结构光系列、手眼标定、相机标定、orb-slam3知识点汇总、入门进阶学习路线、最新paper分享、疑问解答五个方面进行深耕,更有各类大厂的算法工程人员进行技术指导。与此同时,星球将联合知名企业发布3D视觉相关算法开发岗位以及项目对接信息,打造成集技术与就业为一体的铁杆粉丝聚集区,近2000星球成员为创造更好的AI世界共同进步,知识星球入口:
学习3D视觉核心技术,扫描查看介绍,3天内无条件退款

圈里有高质量教程资料、答疑解惑、助你高效解决问题
觉得有用,麻烦给个赞和在看~ 


