

来源:Facebook AI
编辑:LRS
【导读】长久以来CV的训练一直停留在二维数据上,三维数据因为标注成本高等原因都需要专业人员来开发专用模型。Facebook在ICCV 2021 发布两个3D模型3DETR和DepthContrast,将模型的通用性全面升级,也许标志着CV研究全面进入三维时代!从大规模的数据中进行预训练,在计算机视觉中得到了广泛应用,也是在特定任务上得到高性能模型的基础。
但这种方法有一个致命缺陷,那就是如果目标数据类型还没有大量标注数据的话,就没办法使用这种模式。
例如3D 扫描、识别的标注数据集就很稀缺,主要是因为3D 数据集的标注十分耗时,并且用于 3D 理解的模型通常依赖于与用于训练的特定 3D 数据集的手工架构设计。
在 ICCV 2021 上,Facebook AI提出了两个新模型3DETR和DepthContrast,这两个互补的新模型可促进3D理解并更容易上手。新模型建立了简化的3D理解的通用架构,并且能够通过不需要标签的自监督学习方法来解决这些问题。
代码目前也已开源。

出于各种原因,目前的CV 模型还主要集中在二维图片,但构建机器以了解有关世界的 3D 数据非常重要。例如自动驾驶汽车需要 3D 理解才能移动并避免撞到障碍物,而 AR/VR 应用程序可以帮助人们完成实际任务,例如可以可视化沙发是否适合客厅。
来自 2D 图像和视频的数据表示为规则的像素网格,而 3D 数据则反映为点坐标。由于 3D 数据更难获取和标记,因此 3D 数据集通常也比图像和视频数据集小得多。这意味着它们通常在整体大小和它们包含的类或概念的数量方面受到限制。
以前,专注于 3D 理解的从业者需要大量的领域知识来调整标准的 CV 架构。单视图 3D 数据(取自一台同时记录深度信息的相机)比多视图 3D 更容易收集,后者利用两个或更多相机记录同一场景。多视图3D数据往往是通过对单视图3D进行后处理生成的,但是这个处理步骤有失败的可能,一些研究人员估计,由于源图像模糊或相机运动过度等原因,这个失败率可能高达 78%。
DepthContrast 主要解决了这些数据上的问题,因为它可以从任何 3D 数据(无论是单视图还是多视图)训练自监督模型,因此消除了处理小型未标记数据集的挑战。一般的CV 模型即使是对大量 2D 图像或视频进行预训练也不太可能为 AR/VR 等复杂应用产生准确的 3D 理解。

https://arxiv.org/abs/2101.02691
自监督学习一直是研究界和FAIR的主要兴趣领域, DepthContrast也是业界在不使用标记数据的情况下学习强大3D表示的最新尝试。这项研究继承自FAIR 之前的工作PointContrast,也是3D的一种自我监督技术。
现在获得3D数据的机会很多。传感器和多视图立体算法通常为视频或图像提供补充信息。然而,理解这些数据以前一直是一个挑战,因为3D数据具有不同的物理特性,这取决于它的获取方式和位置。
例如,与来自室外传感器(如 LiDAR)的数据相比,来自商用手机传感器的深度数据看起来非常不同。AI研究中使用的大多数3D数据都是以单视图深度图的形式获取的,这些数据通过为3D registration的步骤进行后处理以获得多视图3D。先前的工作依赖于多视图3D数据来学习自监督特征,训练目标主要考虑3D点对应关系。
虽然将单视图数据转换为多视图数据的失败率很高,但DepthContrast表明仅使用单视图3D数据就足以学习最先进的3D特征。
使用3D数据增强可以从单视图深度图生成略有不同的3D深度图。DepthContrast通过使用对比学习来对齐从这些增强深度图获得的特征来实现这一点。
并且研究结果表明该学习信号可用于预训练不同类型的3D架构,例如PointNet++和Sparse ConvNets。
更重要的是,DepthContrast可以应用于任何类型的3D数据,无论是在室内还是室外,单视图还是多视图。我们的研究表明,使用DepthContrast预训练的模型在ScanNet 3D检测基准上绝对是最先进的。
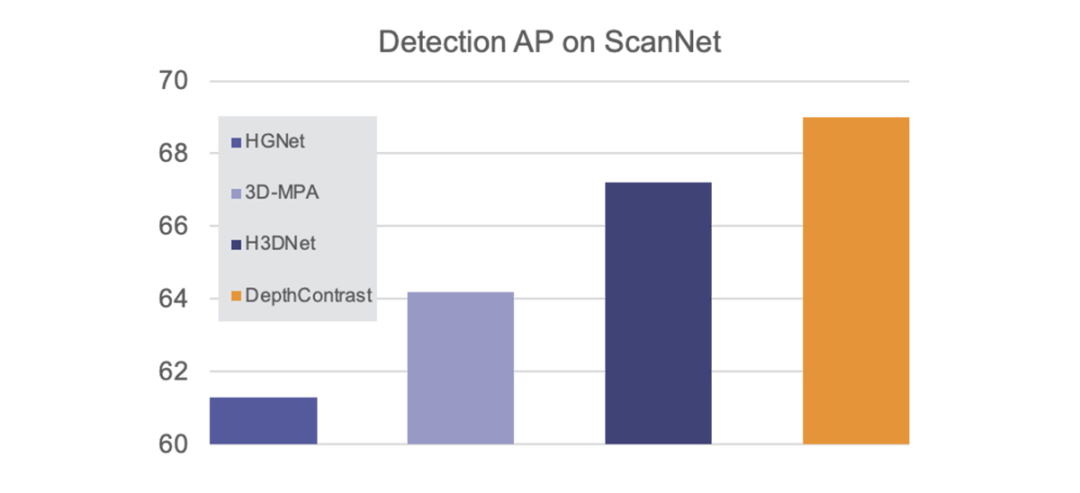
DepthContrast的功能在形状分类、对象检测和分割等任务的各种3D基准测试中提供了增益。
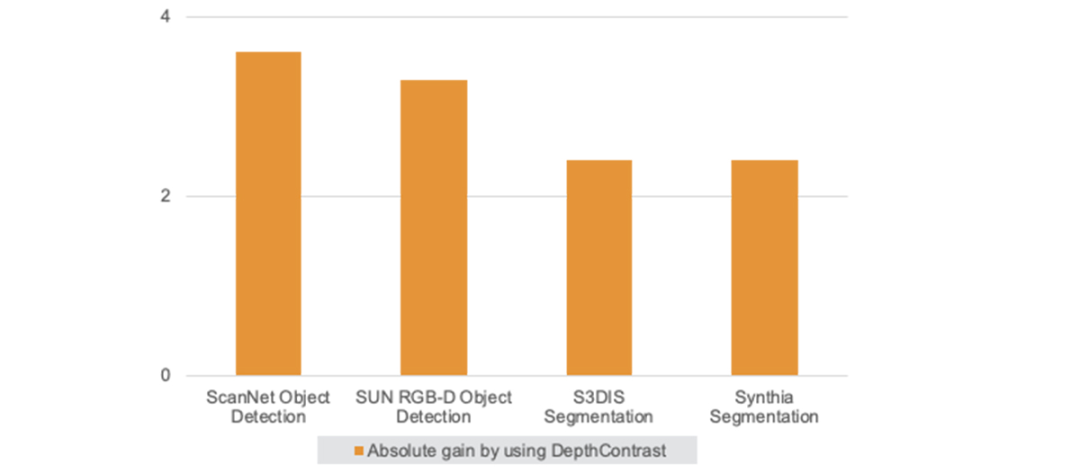
DepthContrast表明自监督学习也有希望用于3D理解。事实上,DepthContrast分享了学习增强不变特征的基本原理,该原理已被用于支持自监督模型,例如Facebook AI的SEER。
第二个工作3DETR是3D Detection Transformer的缩写。该模型是一种基于Transformer的简单三维检测和分类架构,可作为检测和分类任务的通用三维模型,该模型简化了用于训练3D检测模型的损失函数,更容易实现。它的性能也相当于或超过了依赖于手动调整的3D架构和损耗函数的现有最先进的方法。

https://arxiv.org/abs/2109.08141
3DETR将三维场景(表示为点云或一组XYZ点坐标)作为输入,并为场景中的对象生成一组三维边界框。这项新的研究建立在VoteNet和Detection Transformers(DETR)的基础上,其中VoteNet是FAIR在3D点云中检测物体的模型,DETR是Facebook AI为重新定义物体检测挑战而创建的一种更简单的架构。

为了实现2D检测的飞跃,Facebook AI之前的研究确定了两个重要的变化,需要解决Transformer的3D理解工作,还需要非参数查询嵌入和傅立叶编码。因为点云在大量空白空间和噪声点之间具有不同的密度,所以这两种设计决策都是必需的。
3DETR使用两种技术来处理此问题,与DETR和其他变压器模型/DETR中使用的标准(正弦)嵌入相比,傅里叶编码是表示XYZ坐标的更好方法。
其次,DETR使用一组固定的参数(称为查询)来预测对象的位置,研究结果发现此设计决策不适用于点云。取而代之的是,我们从场景中采样随机点,并预测相对于这些点的对象。实际上没有一组固定的参数来预测位置,而是随机点采样适应3D点云的不同密度。
使用点云输入,Transformer编码器生成场景中对象形状和位置的坐标表示通过一系列的自注意操作来捕获识别所需的全局和局部上下文。例如,它可以检测3D场景的几何特性如放置在圆桌周围的椅子的腿和靠背。

Transformer解码器将这些点特征作为输入并输出一组 3D 边界框,它对点特征和查询嵌入应用了一系列交叉注意操作。解码器的自注意力表明它专注于对象以预测它们周围的边界框。
Transformer编码器也足够通用,可以用于其他3D任务,例如形状分类。
总的来说,3DETR比之前的工作更容易实现。在3D基准测试中,3DETR的性能与之前手工制作的3D架构相比也有优势。它的设计决策也与之前的3D工作兼容,使研究人员能够灵活地将3DETR中的组件适应他们自己的pipeline。
从帮助机器人导航世界到为使用智能手机和未来设备(如AR眼镜)的人们带来丰富的新VR/AR体验,这些模型都具有巨大的潜力。
随着手机中3D传感器的普及,研究人员甚至可以从自己的设备上获取单视图3D数据来训练模型。深度对比技术是以自我监督的方式使用这些数据的第一步。通过处理单视图和多视图数据类型,DepthContrast大大增加了3D自监督学习的潜在使用案例。
自监督学习仍然是跨文本、图像和视频学习表示的强大工具。现在,大多数智能手机都配备了深度传感器,这为提高3D理解和创造更多人可以享受的新体验提供了重要机会。
参考资料:
https://ai.facebook.com/blog/simplifying-3d-understanding-using-self-supervised-learning-and-transformers/
本文仅做学术分享,如有侵权,请联系删文。
3D视觉精品课程推荐:
1.面向自动驾驶领域的多传感器数据融合技术
2.面向自动驾驶领域的3D点云目标检测全栈学习路线!(单模态+多模态/数据+代码) 3.彻底搞透视觉三维重建:原理剖析、代码讲解、及优化改进 4.国内首个面向工业级实战的点云处理课程 5.激光-视觉-IMU-GPS融合SLAM算法梳理和代码讲解 6.彻底搞懂视觉-惯性SLAM:基于VINS-Fusion正式开课啦 7.彻底搞懂基于LOAM框架的3D激光SLAM: 源码剖析到算法优化 8.彻底剖析室内、室外激光SLAM关键算法原理、代码和实战(cartographer+LOAM +LIO-SAM)
重磅!3DCVer-学术论文写作投稿 交流群已成立
扫码添加小助手微信,可申请加入3D视觉工坊-学术论文写作与投稿 微信交流群,旨在交流顶会、顶刊、SCI、EI等写作与投稿事宜。
同时也可申请加入我们的细分方向交流群,目前主要有3D视觉、CV&深度学习、SLAM、三维重建、点云后处理、自动驾驶、多传感器融合、CV入门、三维测量、VR/AR、3D人脸识别、医疗影像、缺陷检测、行人重识别、目标跟踪、视觉产品落地、视觉竞赛、车牌识别、硬件选型、学术交流、求职交流、ORB-SLAM系列源码交流、深度估计等微信群。
一定要备注:研究方向+学校/公司+昵称,例如:”3D视觉 + 上海交大 + 静静“。请按照格式备注,可快速被通过且邀请进群。原创投稿也请联系。

▲长按加微信群或投稿

▲长按关注公众号
3D视觉从入门到精通知识星球:针对3D视觉领域的视频课程(三维重建系列三维点云系列结构光系列、手眼标定、相机标定、激光/视觉SLAM、自动驾驶等)、知识点汇总、入门进阶学习路线、最新paper分享、疑问解答五个方面进行深耕,更有各类大厂的算法工程人员进行技术指导。与此同时,星球将联合知名企业发布3D视觉相关算法开发岗位以及项目对接信息,打造成集技术与就业为一体的铁杆粉丝聚集区,近4000星球成员为创造更好的AI世界共同进步,知识星球入口:
学习3D视觉核心技术,扫描查看介绍,3天内无条件退款

圈里有高质量教程资料、答疑解惑、助你高效解决问题
觉得有用,麻烦给个赞和在看~

