
ML之FE:数据处理—特征工程之数据集划分成训练集、验证集、测试集三部分简介、代码实现、案例应用之详细攻略
目录
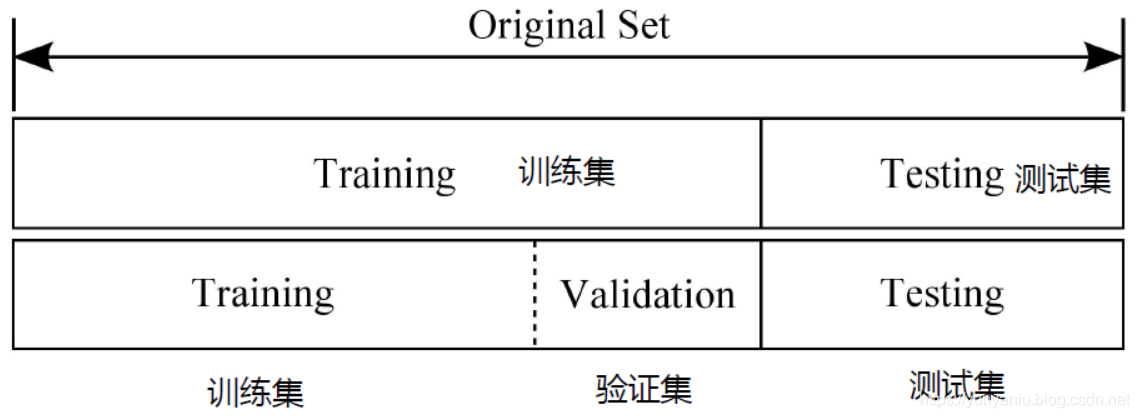
数据集划分成训练、验证、测试三种数据的简介
1、训练集、验证集的作用
2、验证数据集
数据集划分成三部分的代码实现
数据集划分成训练、验证、测试三种数据案例应用
数据集划分成训练、验证、测试三种数据的简介
分割训练数据前,先打乱了输入数据和教师标签。因为数据集的数据可能存在偏向(比如,数据从“0”到“10”按顺序排列等)。 # (1)、如果是MNIST数据集,从训练数据中,事先分割20%作为验证数据
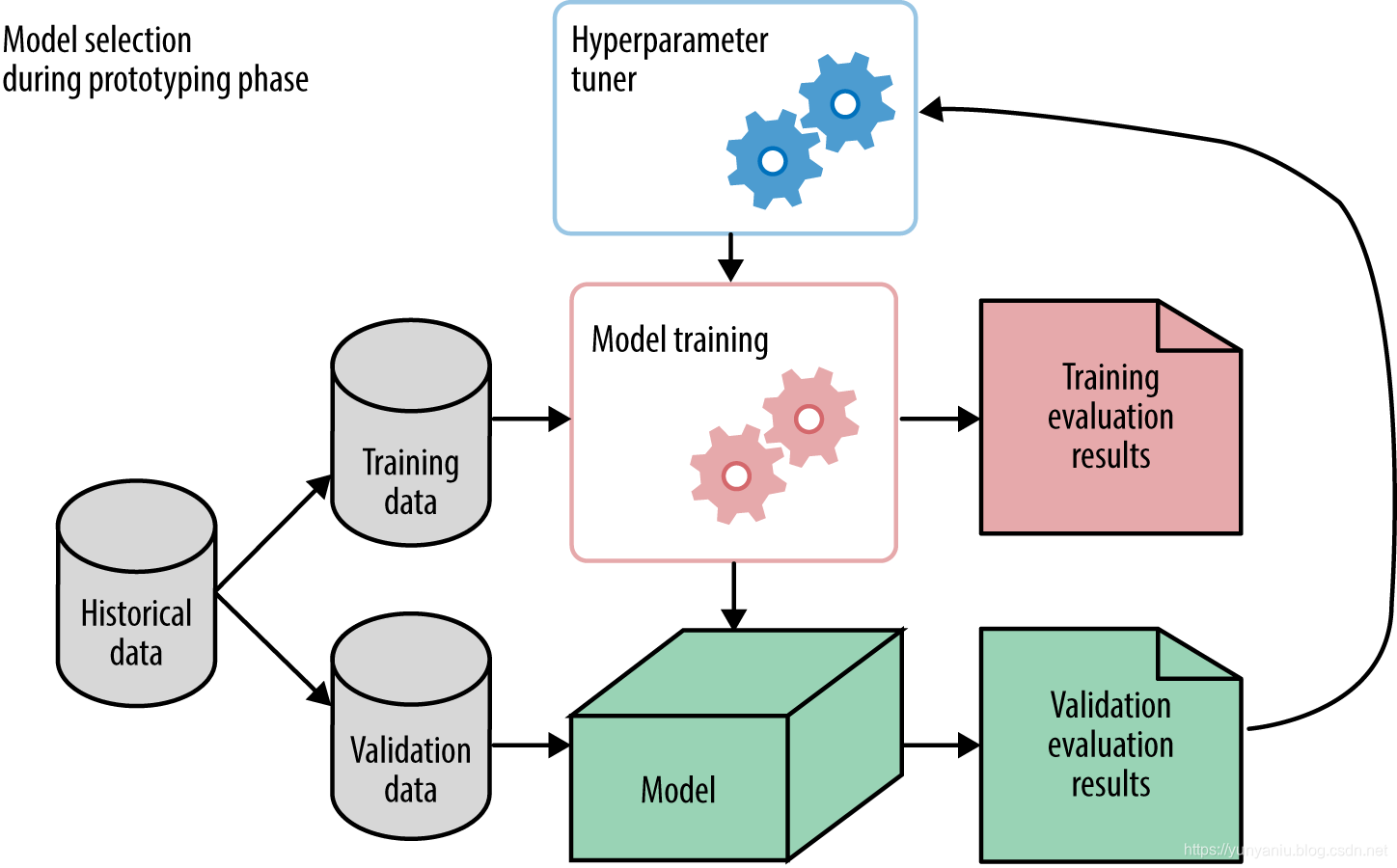
1、训练集、验证集的作用训练集:训练网络模型参数。 验证集:网络模型的超参数。
ML之Validation:机器学习中模型验证方法的简介、代码实现、案例应用之详细攻略
数据集划分成三部分的代码实现
1、MNIST数据集,从训练数据中,事先分割20%作为验证数据
#分割训练数据前,先打乱了输入数据和教师标签。因为数据集的数据可能存在偏向(比如,数据从“0”到“10”按顺序排列等)。
# (1)、如果是MNIST数据集,从训练数据中,事先分割20%作为验证数据
def shuffle_dataset(x, t):
"""打乱数据集
Parameters
----------
x : 训练数据
t : 监督数据
Returns
-------
x, t : 打乱的训练数据和监督数据
"""
permutation = np.random.permutation(x.shape[0])
x = x[permutation,:] if x.ndim == 2 else x[permutation,:,:,:]
t = t[permutation]
return x, t
#数据集预处理:划分为x_train、t_train、x_test、t_test
(x_train, t_train), (x_test, t_test) = load_mnist()
x_train, t_train = shuffle_dataset(x_train, t_train) #调用shuffle_dataset()函数,打乱训练数据
#进行定义验证数据集
validation_rate = 0.20
validation_num = int(x_train.shape[0] * validation_rate) #分割验证数据
x_val = x_train[:validation_num]
t_val = t_train[:validation_num]
x_train = x_train[validation_num:]
t_train = t_train[validation_num:]数据集划分成训练、验证、测试三种数据案例应用
DL之DNN:自定义MultiLayerNet【6*100+ReLU,SGD】对MNIST数据集训练进而比较【多个超参数组合最优化】性能

