
点击上方“3D视觉工坊”,选择“星标”
干货第一时间送达

作者丨paopaoslam
来源丨泡泡机器人SLAM
标题:Accurate and Robust Scale Recovery for Monocular Visual Odometry Based on Plane Geometry
作者:Rui Tian,Yunzhou Zhang,Delong Zhu,Shiwen Liang,Sonya Coleman,Dermot Kerr
来源:ICRA 2021
编译:廖邦彦
审核:lionheart
摘要

尺度模糊性是单目视觉里程计的一个基本问题。典型的解决方案包括回环检测和环境信息提取。对于自动驾驶汽车等应用场景,回环检测并不总是可用的,因此从环境中提取先验知识成为一种更有前景的方法。在本文中,假设相机与地面保持恒定高度,我们设计了一个轻量的尺度恢复框架,利用准确和稳健的地面估计。该框架包括一种在地面平面上提取高质量点的地面点提取算法,以及一种在局部滑窗中将提取的地面点聚合到一起的地面点点聚合算法。在聚合数据的基础上,利用基于RANSAC的优化器求解最小二乘问题,最终恢复了尺度。足够的数据和健壮的优化器实现了一个高度精确的尺度恢复。在KITTI数据集上的实验表明,该框架可以在平移误差方面达到SOTA性能,同时在旋转误差方面保持竞争性能。由于轻量级的设计,我们的框架也在数据集上实现20hz的更新频率。

主要贡献

-
我们提出了一个基于Delaunay三角剖分的地面点提取算法(GPE),并且能够准确的提取地面点。
-
我们提出了一个地面点聚合算法(GPA),能够高效的聚合局部地面点,并且能够实现鲁棒的对于地面的参数的优化。
-
基于提出的算法,我们实现了一个实时的单目视觉里程计,并且可以实现精确且鲁棒的尺度恢复,最终达到降低尺度漂移并且为缺少回环约束的长距离里程计提供高精度的里程计。

系统概述

状态定义

系统的符号标记,分别是第t帧在全局坐标系下的相机位姿,t帧和t-1帧间相对位姿,针孔相机的内参矩阵,3D点以及对应在图像平面上的2D坐标,平面参数,不同状态的估计的相机高度。
问题定义
给定标定过后的单目相机的连续图像帧,我们的目标是估计相机姿态的绝对尺度,然后利用先前已知的相机高度恢复真实的相机轨迹。在尺度模糊情况下,根据图像特征计算的相机高度h与真实的保持一个确定比例
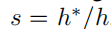
因此,尺度恢复本质上是为了计算s,关键在于准确估计地面。
系统框架 我们提出的系统基于这样一个假设,局部地面是平坦的,并且可以使用一个平面法向量近似。如图1中的红色方块所示。对于从单目视觉里程计线程中提取的每个图像帧,首先应用Delaunay三角剖分将匹配的特征点分割成一组三角形。然后将每个三角形反向投影到相机帧中,并估计相关的平面参数。在此之后,利用一些几何约束来挑选,然后细化地面点点。 需要注意的是,所筛选的地面点不足以准确估计平面参数。因此,我们提出了GPA算法,使用滑动窗口方法聚合来自多个帧的基点,如图1的橙色块所示。在聚合的局部点的基础上,采用鲁棒参数估计方法来拟合地面平面。因此,可以估计每一帧的相对相机高度,并恢复相机的绝对轨迹,如图1中的蓝色块所示。
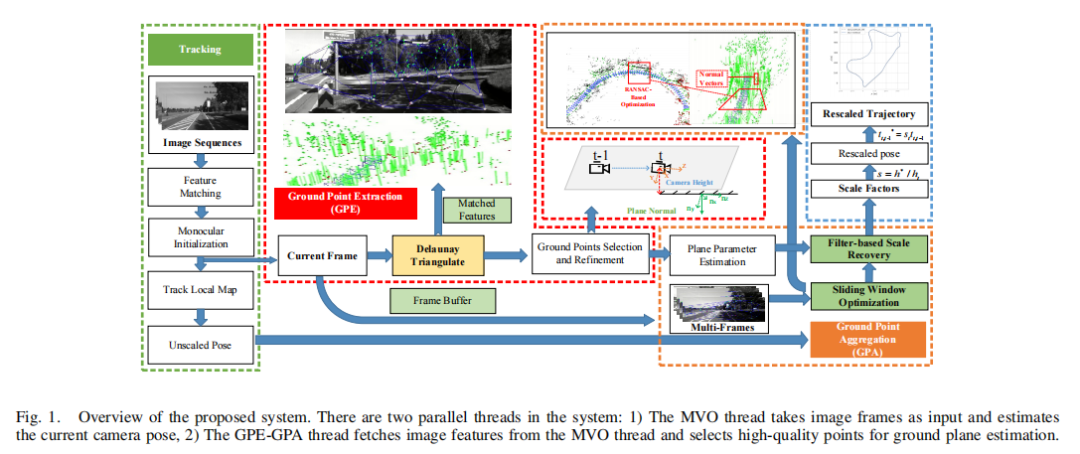

方法概述

GROUND PLANE ESTIMATION
A. Ground Point Extraction
对于当前的图像帧中的一组给定的匹配特征点,使用Delaunay三角剖分使用每个特征点作为一个三角形顶点。我们将图像平面上的三角形反向投影到当前的相机帧中,并通过一组三角形顶点和边来表示它们。每个三角形的法向量可以通过叉积得到
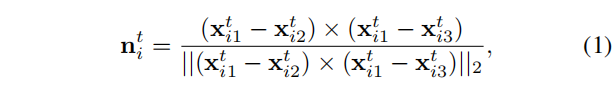
其中左式为单位长度,对于三角形的每个顶点,以下几何约束成立
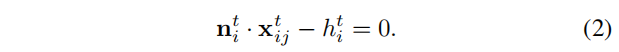
同时基于一个事实,相机总是安装在车辆的顶部,并且高于地面,我们可以得到以下约束

值得注意的是,三角形分散在整个图像平面上,因此我们需要识别出位于地平面上的三角形来估计平面参数。基于地面三角形的法向量与相机平移向量正交,且相机的俯仰角为零,可以通过以下约束条件来识别地面三角形。
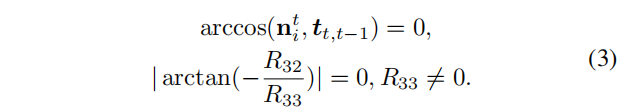
实践中,不能严格满足相等条件。因此,我们在实现中设置了一个忍耐值为5°。对于满足上述约束的地面三角形,它们的顶点被分类为一个新的点集,由于同一个顶点可能由多个三角形共享,因此我们也需要从点集中删除重复的顶点。这将确保每个点对地面平面估计的贡献相同。地面点现在最初被分割出来,但可能仍然存在一些由移动对象和一些远点引入的异常值。为了进一步提高地面点的质量,利用基于RANSAC的方法优化地面点,使平面距离误差最小化。
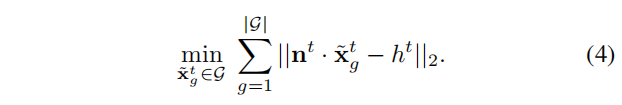

B. Ground Point Aggregation
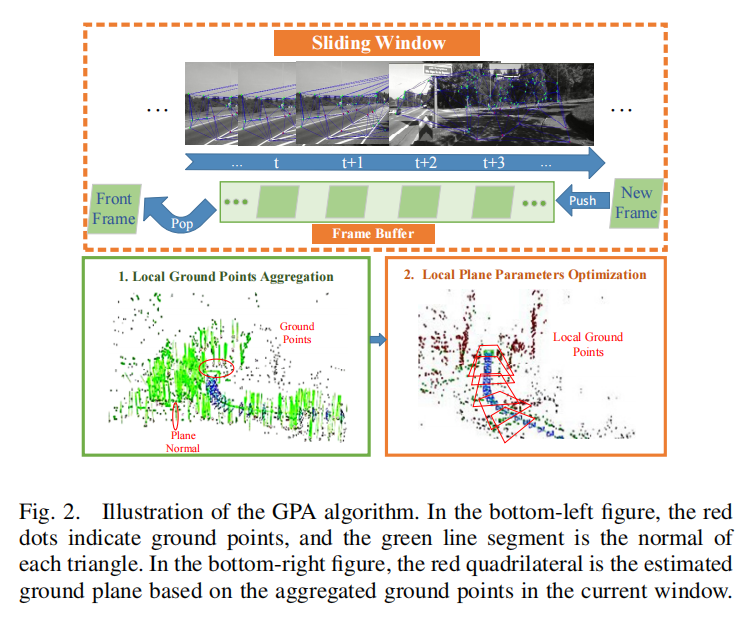
由于GPE的严格分割标准,现有的内点不足以准确估计地面。因此,我们提出了GPA算法来聚合连续图像帧中的地面点。如图2所示,我们利用滑动窗口的方法来选择图像帧,并维护一个帧缓冲区来存储当前窗口中的相机姿势和地面点。在每个时间点中,随着一个新的图像帧的到来,我们更新缓冲区,然后通过求解一个最小二乘问题来估计地面。我们先通过转移矩阵将每个内点转换到全局坐标系下面。

假设缓冲区中有N个局部地面点,基于点面距离误差最小的最小二乘问题定义如下
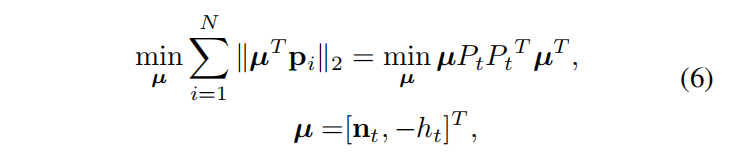
公式6可以重写为下式
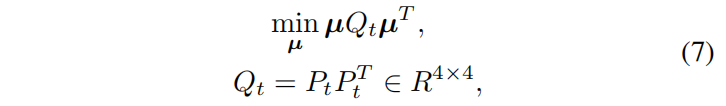
公式7可以通过SVD方法高效求解为了进一步提高对于μ的估计精度,我们提出一种权重矩阵Σ
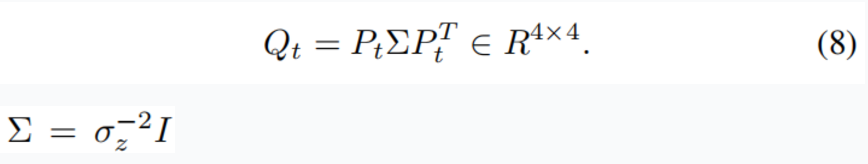
其中的σ定义为地面点深度与其平均值的归一化距离
对平面参数估计的另一个重要改进是进行基于RANSAC的优化,在每次优化迭代中,我们首先估计µ,然后计算pi与估计平面之间的距离。距离大于0.01m的点被移除,然后利用剩余的点来估计一个新的µ。这样的过程一直持续到收敛。我们用n_t表示最终的平面法向量,保留的地面点用p_k表示。然后,可以通过将相机中心投影到地面平面来计算相机的相对高度
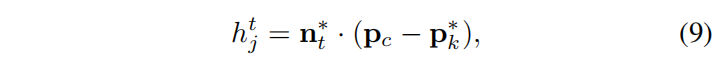
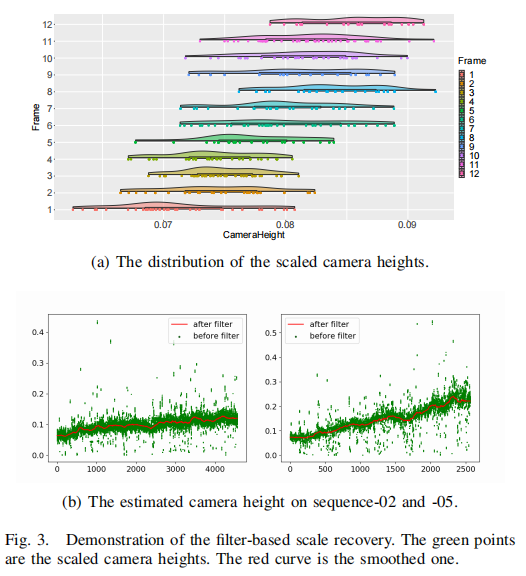
其中p_c是在世界坐标系下帧I_t的相机中心,值得注意的是,这里有K个估计的相机高度,会被进一步处理来得到一个平滑尺度,在下图中详细展示

C. Filter-Based Scale Recovery在计算每一帧的相对相机高度h后,用s_t = h∗ / h得到比例因子,使用下式将每一帧的运动比例恢复
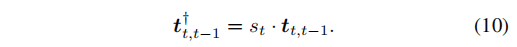
对应于公式9中的多个h值,s值也有多个。通过绘制图中每一帧的相机高度,如图所示。我们发现数据并不严格遵循高斯分布。因此,我们选择中值点作为当前帧的尺度。在时域内,应用了一个移动平均滤波器,如图所示。这可以给出一个更平稳的结果。

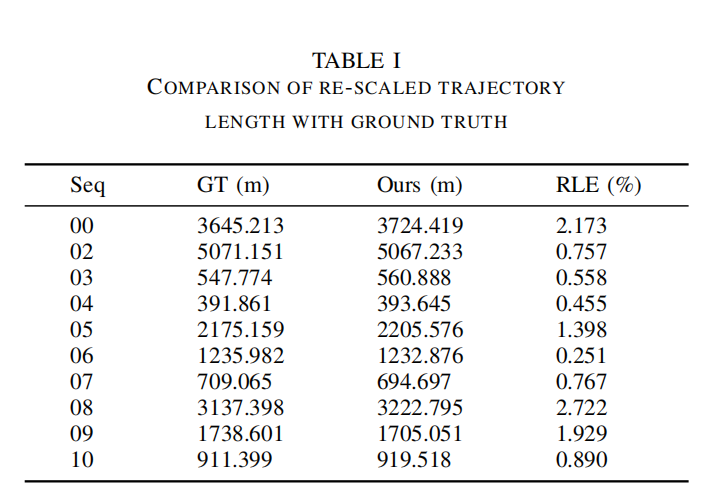
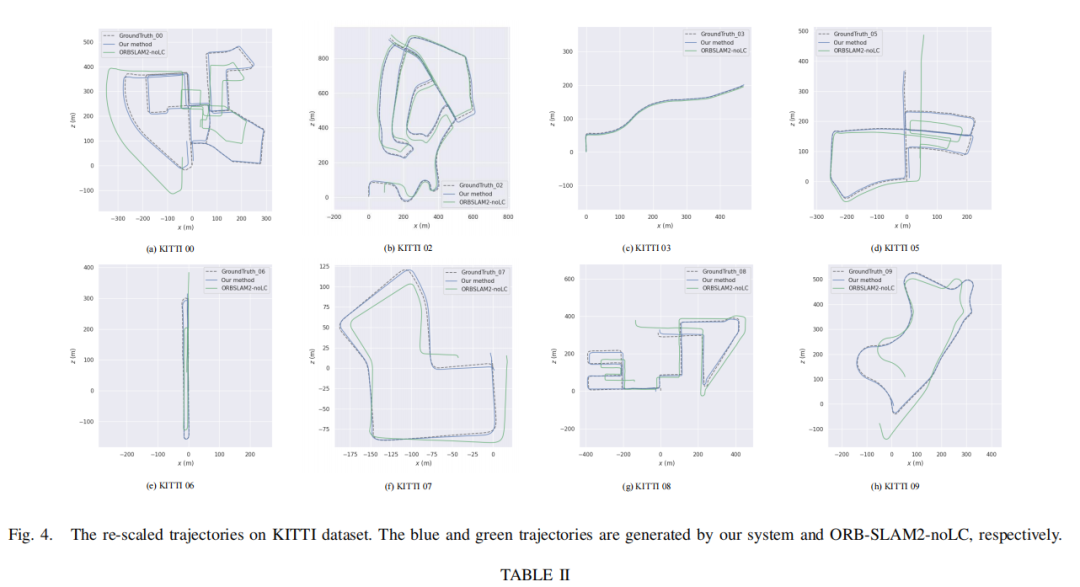
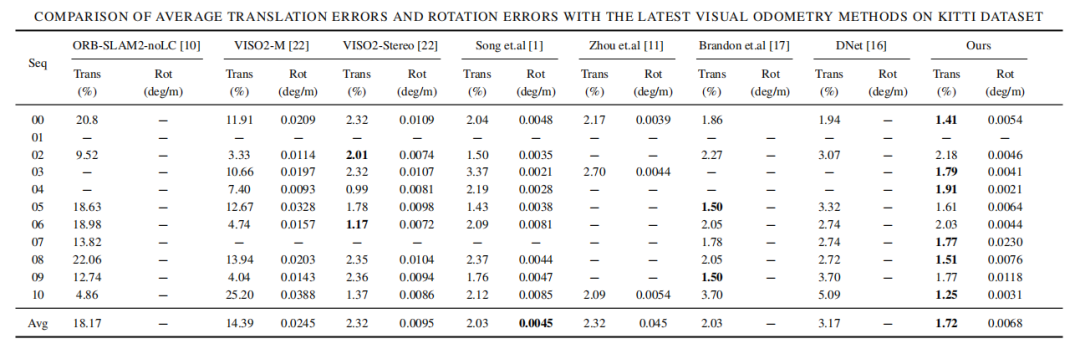
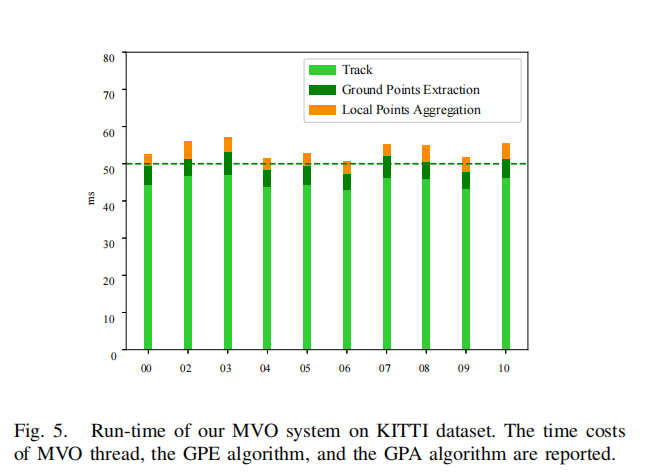
实验结果

Abstract
Scale ambiguity is a fundamental problem in monocular visual odometry. Typical solutions include loopclosure detection and environment information mining. For applications like self-driving cars, loop closure is not always available, hence mining prior knowledge from the environment becomes a more promising approach. In this paper, with the assumption of a constant height of the camera above the ground, we develop a light-weight scale recovery framework leveraging an accurate and robust estimation of the ground plane. The framework includes a ground point extraction algorithm for selecting high-quality points on the ground plane, and a ground point aggregation algorithm for joining the extracted ground points in a local sliding window. Based on the aggregated data, the scale is finally recovered by solving a least-squares problem using a RANSAC-based optimizer. Sufficient data and robust optimizer enable a highly accurate scale recovery. Experiments on the KITTI dataset show that the proposed framework can achieve state-of-the-art accuracy in terms of translation errors, while maintaining competitive performance on the rotation error. Due to the light-weight design, our framework also demonstrates a high frequency of 20 Hz on the dataset.
本文仅做学术分享,如有侵权,请联系删文。
3D视觉精品课程推荐:
1.面向自动驾驶领域的多传感器数据融合技术
2.面向自动驾驶领域的3D点云目标检测全栈学习路线!(单模态+多模态/数据+代码) 3.彻底搞透视觉三维重建:原理剖析、代码讲解、及优化改进 4.国内首个面向工业级实战的点云处理课程 5.激光-视觉-IMU-GPS融合SLAM算法梳理和代码讲解 6.彻底搞懂视觉-惯性SLAM:基于VINS-Fusion正式开课啦 7.彻底搞懂基于LOAM框架的3D激光SLAM: 源码剖析到算法优化 8.彻底剖析室内、室外激光SLAM关键算法原理、代码和实战(cartographer+LOAM +LIO-SAM)
9.从零搭建一套结构光3D重建系统[理论+源码+实践]
10.单目深度估计方法:算法梳理与代码实现
11.自动驾驶中的深度学习模型部署实战
12.相机模型与标定(单目+双目+鱼眼)
重磅!3DCVer-学术论文写作投稿 交流群已成立
扫码添加小助手微信,可申请加入3D视觉工坊-学术论文写作与投稿 微信交流群,旨在交流顶会、顶刊、SCI、EI等写作与投稿事宜。
同时也可申请加入我们的细分方向交流群,目前主要有3D视觉、CV&深度学习、SLAM、三维重建、点云后处理、自动驾驶、多传感器融合、CV入门、三维测量、VR/AR、3D人脸识别、医疗影像、缺陷检测、行人重识别、目标跟踪、视觉产品落地、视觉竞赛、车牌识别、硬件选型、学术交流、求职交流、ORB-SLAM系列源码交流、深度估计等微信群。
一定要备注:研究方向+学校/公司+昵称,例如:”3D视觉 + 上海交大 + 静静“。请按照格式备注,可快速被通过且邀请进群。原创投稿也请联系。

▲长按加微信群或投稿

▲长按关注公众号
3D视觉从入门到精通知识星球:针对3D视觉领域的视频课程(三维重建系列、三维点云系列、结构光系列、手眼标定、相机标定、激光/视觉SLAM、自动驾驶等)、知识点汇总、入门进阶学习路线、最新paper分享、疑问解答五个方面进行深耕,更有各类大厂的算法工程人员进行技术指导。与此同时,星球将联合知名企业发布3D视觉相关算法开发岗位以及项目对接信息,打造成集技术与就业为一体的铁杆粉丝聚集区,近4000星球成员为创造更好的AI世界共同进步,知识星球入口:
学习3D视觉核心技术,扫描查看介绍,3天内无条件退款

圈里有高质量教程资料、答疑解惑、助你高效解决问题
觉得有用,麻烦给个赞和在看~

