
点击上方“3D视觉工坊”,选择“星标”
干货第一时间送达

作者丨泡泡图灵智库
来源丨 泡泡机器人SLAM
标题:RAFT-3D: Scene Flow using Rigid-Motion Embeddings
作者:Zachary Teed, Jia Deng
来源:ICCV 2021
编辑:方川
审核:张海晗
大家好,今天给大家带来的是Princeton VL的RAFT系列工作: RAFT-3D: Scene Flow using Rigid-Motion Embeddings. 这篇工作的额目的是估计图像中3D场景流, 不同于之前的RAFT估计图像的2D光流, 本工作还会输出图像中稠密像素的6DoF运动信息. 主干网络结构仍然使用RAFT网络, 但是使用Dense-SE3嵌入了刚体变换信息。实验表明这种方法得到了比其他光流估计方法更好的精度, 在FlyThings3D和KITTI数据集上取得了很好的结果.
摘要
本文提了RAFT-3D: 一种基于RAFT光流法的场景流估计网络, 目的是为了解决场景流估计问题: 给定一对连续的双目/RGB-D图像帧, 估计稠密像素点的3D运动. 不同于RAFT估计2D像素运动, RAFT-3D估计场景中所有像素的3D刚体运动SE3. 刚体运动嵌入是RAFT-3D网络的关键部分, 它可以把图像中的不同物体分为不同组别, 网络中主要依靠Dense-SE3 layer来实现物体分组和几何关系约束的功能. 实验表明, 在FlyThings3D数据集上,我们预测的2D光流场和3D光流场(场景流)都取得了sota的效果.
-
本文介绍了一种刚体运动嵌入的网络设计方法, 图像中的所有像素会被软分类为若干组, 每一组中的所有像素具有相同的SE3运动;
-
本文设计了可微的Dense-SE3 layer, 可以基于LM方法迭代的更新稠密像素的SE3运动. 由此我们可以直接使用2D光流场来监督网络的训练;
-
我们的网络不需要显式的标注/分割物体作为监督信息;
算法流程
RAFT-3D网络的框架如图:
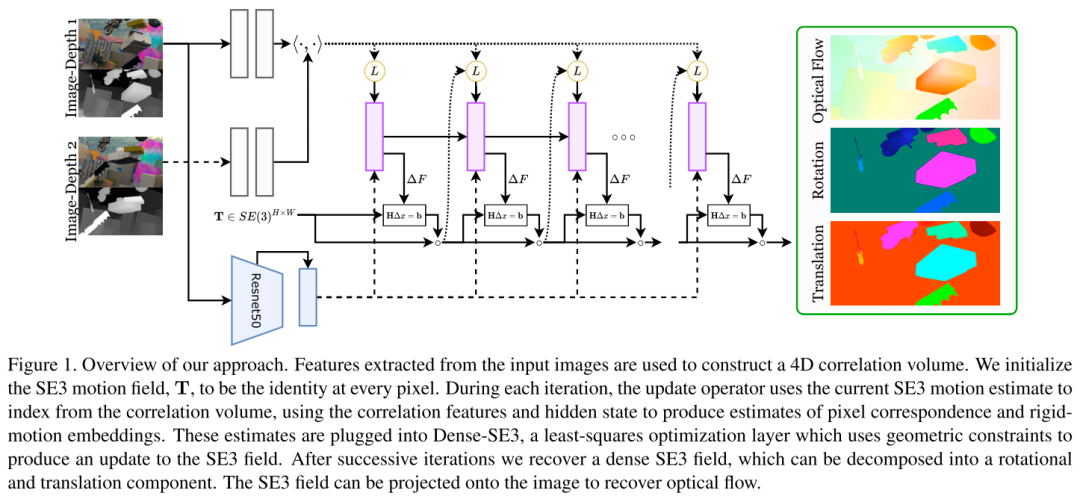
RAFT-3D的输入是一对时域上相邻的RGB-D图像, 在图像上提取特征并构建4D correlation volume, 在GRU更新模块中维护稠密的场景流(pixelwise SE3 motion), 每次迭代过程会先根据当前估计的SE3 motion来推导出2D光流, 进而索引correlation volume获取correlation feature. GRU根据correlation feature来估计2D光流变化和刚体运动嵌入信息rigid-motion embedding. 这些嵌入信息输入Dense-SE3 layer, 进用来更新场景流SE3 motion.
-
Notation
现有RGB-D相机, 我们的网络输入为一对在时域上相邻的图像对和, 为深度图, 输出是图像上每个像素的刚体变换场. 应用到双目相机的情况, 我们需要先把计算出来.
-
Preliminary
相机坐标系下空间点的投影和反投影过程可以公式化为:
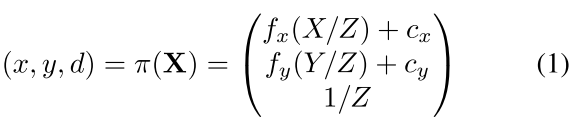
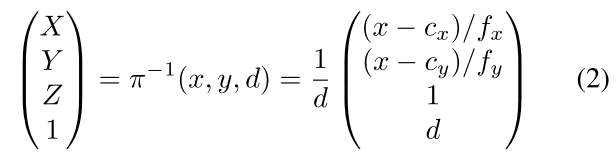
为相机内参, 为逆深度.
假设已知稠密的变换场, 图像上的像素变换到图像上的过程可以用公式(3)描述:

就是的对应点, 则就是两张图像的光流场.
根据上述投影、变换过程, 我们可以写出像素相对于空间点的Jacobian矩阵:
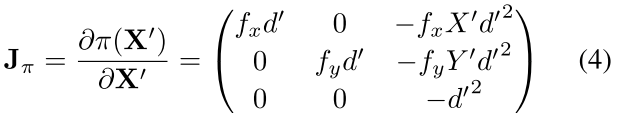
空间点相对于变换的Jacobian矩阵:

最终相对于的Jacobian矩阵: .
有了Jacobian矩阵, 我们可以去解决加权最小二乘问题, 误差函数可以写为(6):
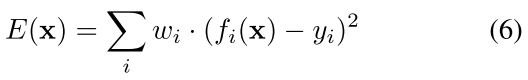
应用Gauss-Newton法来优化误差函数(6):

上式可以写成线性公式(10):
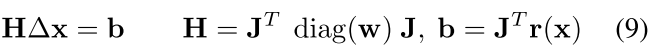
叫做Hessian矩阵.
-
网络结构:
特征提取:
这里使用了两个网络feature encoder和context encoder. feature encoder的网络结构和RAFT网络一样, 都是堆叠的残差模块, 作用在输入的和上, 输出大小为1/8原图分辨率下的128维feature map. context encoder使用了ResNet50(代码中是以resnet50为backbone的FPN), 因为该网络能够更好的提取语义上下文特征, 这对场景中物体的分类起到了很大的帮助作用.
计算特征相似信息体correlation volume:
这里还是采用两幅图像的feature map点乘的方法计算4D correlation volume:
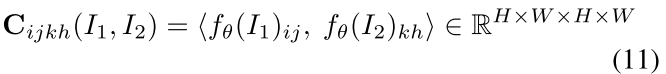
同样在最后两维进行池化, 得到不同分辨率组成的correlation pyramid :
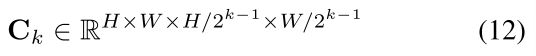
索引correlation volume:
这部分与RAFT中的索引 correlation volume操作一样, 根据当前估计的flow fields , 扩大一定的邻域范围, 在correlation volume中索引feature map:

不同的是, 这里的是根据更新的motion fields 推导出来的, 而不是使用GRU模块输出的delta flow直接索引correlation feature.
更新模块Update Operator:
GRU模块的输入:
-
context feature map + hidden state;
-
索引得到的correlation features: ;
-
current flow filed: ;
-
李代数下的motion fields: ;
-
逆深度的残差项: , 深度图是由公式(3)得到的深度, 是根据公式(3)得到的(x', y')索引得到的深度值.
输出:
-
更新后的hidden state + delta_flow;
-
rigid-motion embedding map ;
-
flow fields的修正项和逆深度的修正项, 这里的光流修正项是作用于motion fields 推导出来的光流场, 而不是直接作用于GRU中迭代的光流场;
-
置信度特征图, 对噪声和遮挡进行建模.
Dense-SE3 Layer:
Dense-SE3层的目的是根据刚体运动嵌入层, 修正项和来更新SE3变换场. 刚体运动嵌入层是被用来对图像中的物体进行软分组的特征图, 同一组的所有像素应该有一致的刚体运动.
给定两个嵌入向量, 我们需要计算仿射系数: 是sigmoid函数:

因此在Dense-SE3层的优化目标就是希望把图像上的像素分为不同物体组, 每个组的像素共享同一个变换:
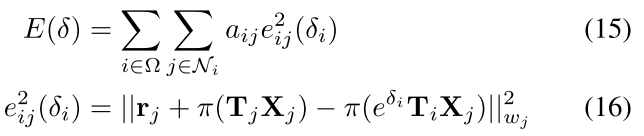
rigid-motion embedding的bi-Laplacian优化:
为了避免图像中较大物体的分类出现不收敛问题, 我们实现了一个bi-laplacian optimization layer来平滑物体运动的边缘. 给定embedding map , 边缘权重, bi-laplacian optimization layer目标函数是:
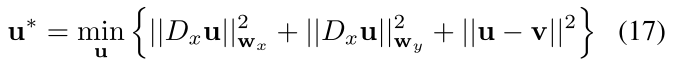
其中是一种线性微分算子. 公式(17)的目的是希望新的embedding map 尽可能的逼近原始embedding map, 并且保证smooth motion boundary.
-
监督信息:
网络的监督使用optical flow的真值和逆深度的真值(stereo数据下需要提前计算depth map). 对于迭代过程中得到的刚体变换, 我们可以使用任一来计算delta optical flow和delta inverse depth:
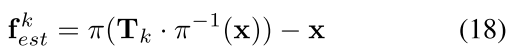
是图像中的稠密像素坐标, 因此我们对所有迭代更新结果的损失函数计算:
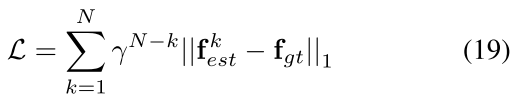
实验结果
本文提出的网络在训练过程中, 首先在FlyingThings3D数据集上训练了200k轮, 然后在KITTI 2015 stereo/sceneflow数据集上refine训练50k轮, KITTI 2015 stereo数据上预先使用GA-Net得到了深度图.
在FlyingThings3D上的可视化结果:

下面的表格评估了RAFT-3D的2D opticalflow、3D 欧式距离的end-point-error(EPE). 我们将RAFT-3D和基于RAFT修改的网络的输出结果做了对比:
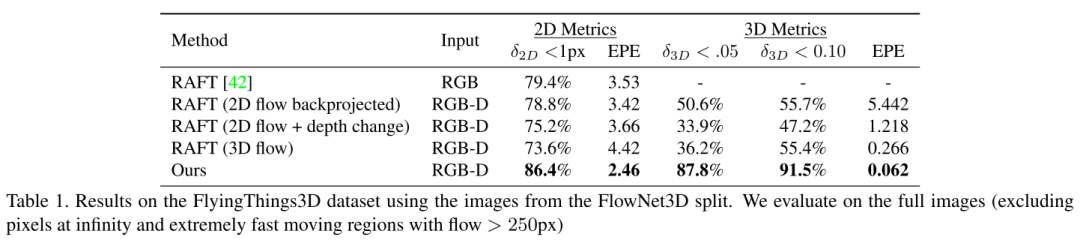
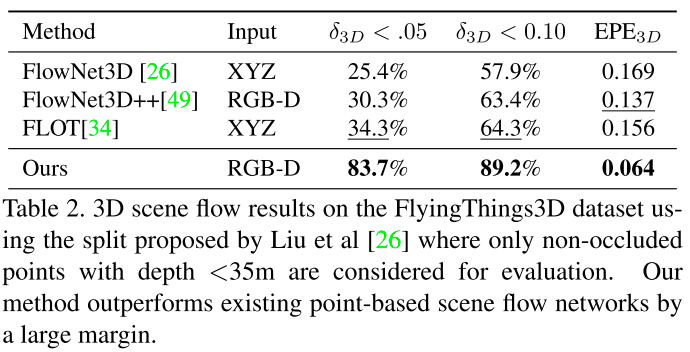
RAFT-3D与基于点云的sceneflow方法的结果对比:
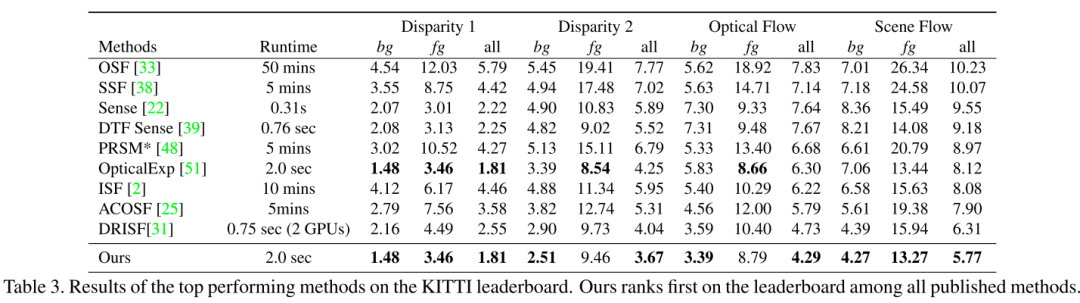
在KITTI 2015 sceneflow数据上的结果与其他方法的对比:
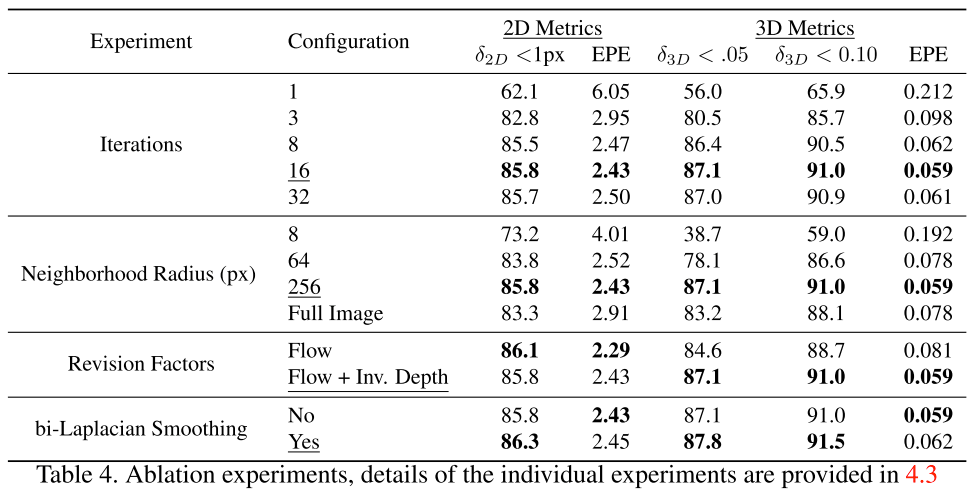
消融实验:
本文仅做学术分享,如有侵权,请联系删文。
3D视觉精品课程推荐:
1.面向自动驾驶领域的多传感器数据融合技术
2.面向自动驾驶领域的3D点云目标检测全栈学习路线!(单模态+多模态/数据+代码) 3.彻底搞透视觉三维重建:原理剖析、代码讲解、及优化改进 4.国内首个面向工业级实战的点云处理课程 5.激光-视觉-IMU-GPS融合SLAM算法梳理和代码讲解 6.彻底搞懂视觉-惯性SLAM:基于VINS-Fusion正式开课啦 7.彻底搞懂基于LOAM框架的3D激光SLAM: 源码剖析到算法优化 8.彻底剖析室内、室外激光SLAM关键算法原理、代码和实战(cartographer+LOAM +LIO-SAM)
9.从零搭建一套结构光3D重建系统[理论+源码+实践]
10.单目深度估计方法:算法梳理与代码实现
11.自动驾驶中的深度学习模型部署实战
12.相机模型与标定(单目+双目+鱼眼)
13.重磅!四旋翼飞行器:算法与实战
重磅!3DCVer-学术论文写作投稿 交流群已成立
扫码添加小助手微信,可申请加入3D视觉工坊-学术论文写作与投稿 微信交流群,旨在交流顶会、顶刊、SCI、EI等写作与投稿事宜。
同时也可申请加入我们的细分方向交流群,目前主要有3D视觉、CV&深度学习、SLAM、三维重建、点云后处理、自动驾驶、多传感器融合、CV入门、三维测量、VR/AR、3D人脸识别、医疗影像、缺陷检测、行人重识别、目标跟踪、视觉产品落地、视觉竞赛、车牌识别、硬件选型、学术交流、求职交流、ORB-SLAM系列源码交流、深度估计等微信群。
一定要备注:研究方向+学校/公司+昵称,例如:”3D视觉 + 上海交大 + 静静“。请按照格式备注,可快速被通过且邀请进群。原创投稿也请联系。

▲长按加微信群或投稿

▲长按关注公众号
3D视觉从入门到精通知识星球:针对3D视觉领域的视频课程(三维重建系列、三维点云系列、结构光系列、手眼标定、相机标定、激光/视觉SLAM、自动驾驶等)、知识点汇总、入门进阶学习路线、最新paper分享、疑问解答五个方面进行深耕,更有各类大厂的算法工程人员进行技术指导。与此同时,星球将联合知名企业发布3D视觉相关算法开发岗位以及项目对接信息,打造成集技术与就业为一体的铁杆粉丝聚集区,近4000星球成员为创造更好的AI世界共同进步,知识星球入口:
学习3D视觉核心技术,扫描查看介绍,3天内无条件退款

圈里有高质量教程资料、答疑解惑、助你高效解决问题
觉得有用,麻烦给个赞和在看~

