
作者:Jin.Carlo | 已授权转载(源:知乎)编辑:CVer
https://zhuanlan.zhihu.com/p/474955539
先上我们文章和代码:

论文:https://arxiv.org/abs/2102.12252
代码:https://github.com/HikariTJU/LD
代码2:
https://github.com/open-mmlab/mmdetection/tree/master/configs/ld
方法概括:把用于分类head的KD(知识蒸馏),用于目标检测的定位head,即有了LD (Localization Distillation)。
做法:先把bbox的4个logits输出值,离散化成4n个logits输出值,之后与分类KD完全一致。
意义:LD使得logit mimicking首次战胜了Feature imitation。分类知识与定位知识的蒸馏应分而治之、因地制宜。
一. LD的诞生 1. bbox分布与定位模糊性说起LD,就不得不说起bbox分布建模,它主要来源于GFocalV1 (NeurIPS 2020) 与Offset-bin (CVPR 2020)这两篇论文。
我们知道bbox的表示通常是4个数值,一种如FCOS中的点到上下左右四条边的距离 (tblr),还有一种是anchor-based检测器中所用的偏移量,即anchor box到GT box的映射 (encoded xywh).
GFocalV1针对tblr形式的bbox建模出了bbox分布,Offset-bin则是针对encoded xywh形式建模出了bbox分布,它们共同之处就在于尝试将bbox回归看成一个分类问题。并且这带来的好处是可以建模出bbox的定位模糊性。

大象的下边界与冲浪板的右边界都是模糊的
那么用n个概率值去描述一条边,可以显示出模型对一个位置的定位模糊估计,越尖锐的分布说明这个位置几乎没有模糊性(比如大象的上边界),越平坦的分布说明这个位置有很强的模糊性(大象的下边界)。当然不光是bbox分布的平坦度,形状上还可分为单峰型,双峰型,甚至多峰型。
2. 知识蒸馏Knowledge Distillation (KD)最早是针对图像分类而设计的。核心思想是:用一个预训练的大模型(teacher)去指导一个小模型(student)的学习。
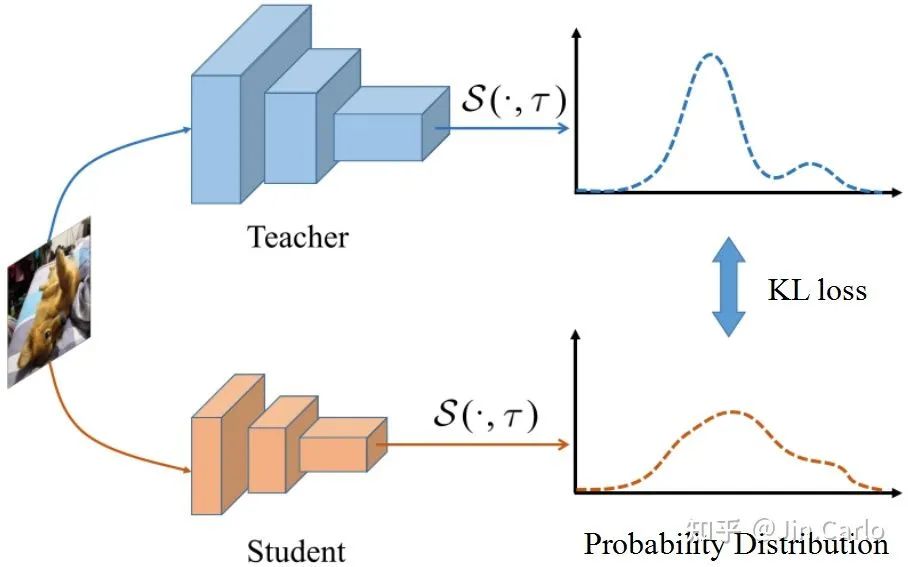

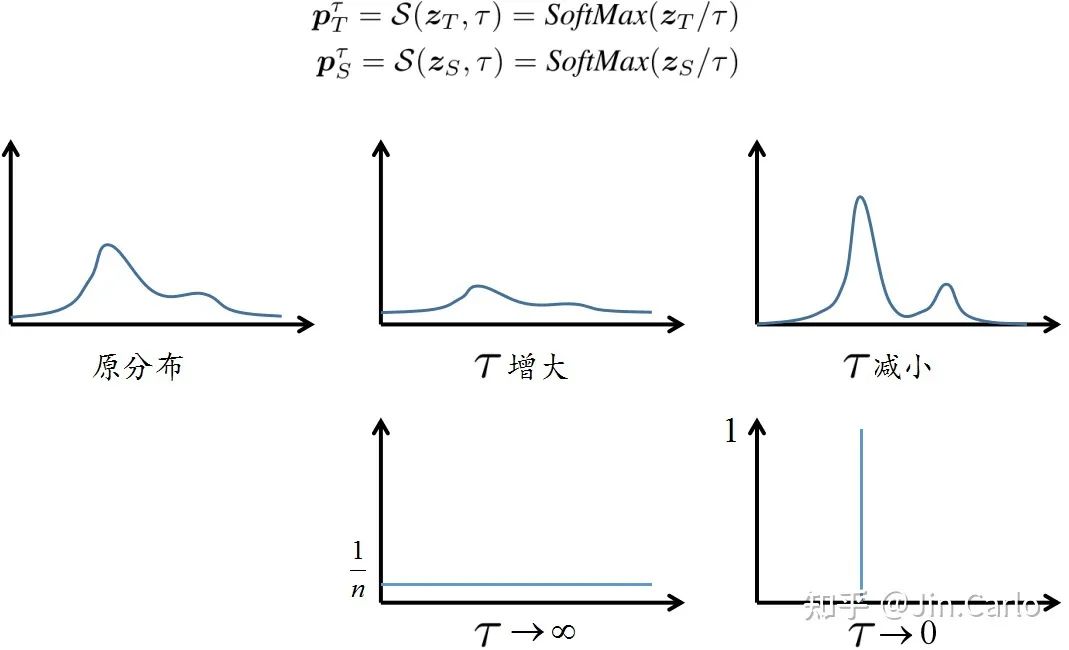

由以上可以看到,定位蒸馏LD与分类蒸馏KD从公式上来看是完全一致的,都是针对head的输出logits做知识传递,这为目标检测知识蒸馏提供了一个统一的logit mimicking框架。
三、分类KD的低效性与Feature imitation以往许多工作指出了分类KD的蒸馏效率低下(涨点低),这主要有两个方面:
-
在不同的数据集中,类别数量会变化,较少的类别可能给student提供不了很多有用的信息。
-
一直以来logit mimicking都只能在分类head上操作,而无法在定位head上操作,这自然忽视了定位知识传递的重要性。
基于这两个原因,人们将视线转向了另一个很有前景的知识蒸馏方法,Feature imitation。该方法主要受到FitNet的启发,一言以概之,就是不光分类head上要做logit mimicking,中间隐藏层(特征图)也要让student去拟合teacher,通过最小化L2 loss来完成。
于是形成了如下的目标检测知识蒸馏框架:

目标检测知识蒸馏框架总览
其中分类head上是logit mimicking(分类KD),特征图上是Feature imitation (teacher与student特征图之间的L2 loss),定位head上是伪bbox regression,即把teacher预测框当成额外的回归目标。
Feature imitation在师生的特征图上施加监督,最常见的做法是先将student的特征图尺寸与teacher特征图对齐,之后再选择一些感兴趣的区域作为蒸馏区域,例如FitNet(ICLR 2015)在全图上蒸馏;Fine-Grained(CVPR 2019)在一些anchor box的location上蒸馏;还有DeFeat(CVPR 2021)在GT box内部用小loss weight,在GT box外部用大loss weight;亦或者是GI imitation(CVPR 2021)的动态蒸馏区域,但无论选择何种区域,最后都是在蒸馏区域上计算二者的L2 loss.
那么Feature imitation有什么好处呢?
在multi-task learning框架下,特征图相当于树根,下游的各个head相当于树的叶子。那么特征图显然包含了所有叶子所需要的知识。进行Feature imitation自然就会同时传递分类知识与定位知识,而分类KD却无法传递定位知识。
Feature imitation有什么弊端呢?
答案自然还是它会在蒸馏区域中的每个location上同时传递分类知识与定位知识。
前后一对比,乍看之下岂不矛盾?让我来解释一下。
分类知识与定位知识的分布是不同的。这一点在以往的工作中有提到,例如Sibling Head (CVPR 2020)。
两种知识的分布不同,自然就导致了并不是在一个location上同时传递分类知识与定位知识都有利。很有可能某些区域仅对分类知识传递有利,也有可能某些区域仅对定位知识传递有利。换言之,我们需要分而治之、因地制宜地传递知识。这显然就是Feature imitation无能为力的事情了,因为它只会传递混合知识。
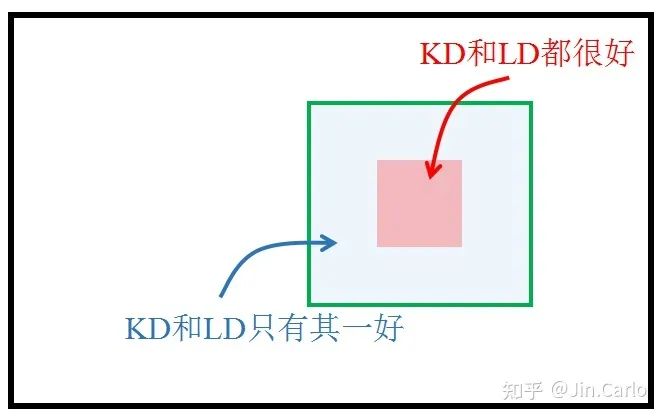
概念图
于是我们利用multi-task learning天然地把知识解耦成不同类型,这就允许我们在一个区域中有选择性地进行知识蒸馏。为此,我们引入了一个有价值定位区域 VLR (Valuable Localization Region)的概念,来帮助我们进行分而治之的蒸馏。
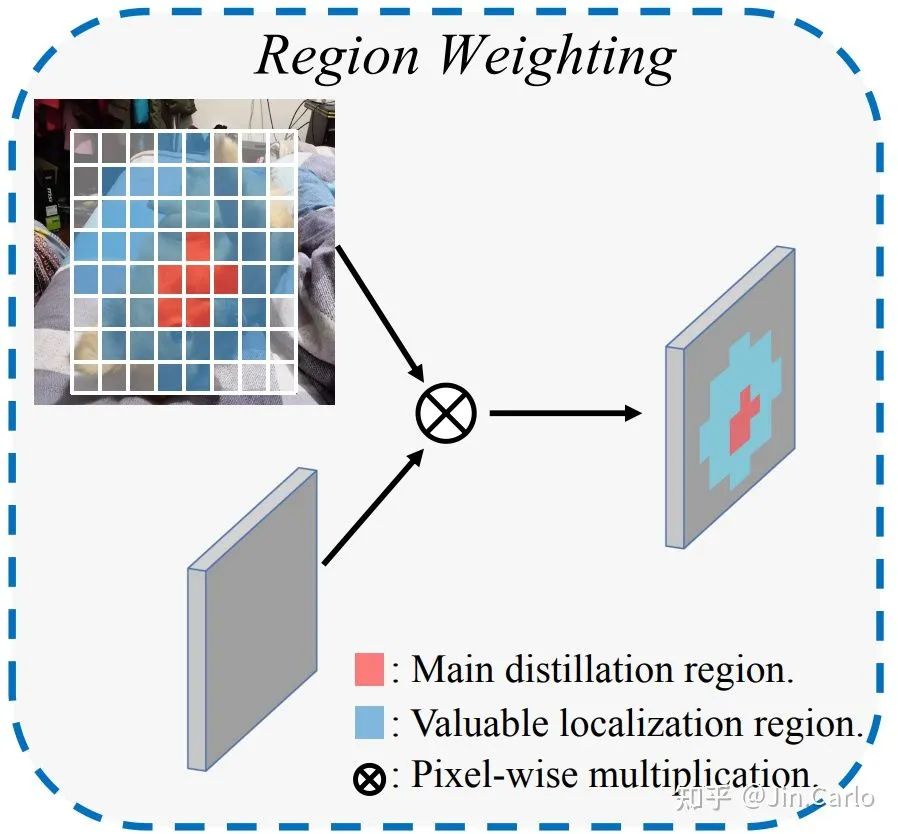
与以往的Feature imitation方法不同,我们的蒸馏分为两个区域:
-
Main distillation region (主蒸馏区域):即检测器的positive location,通过label assignment获得。
-
VLR:与一般的label assignment做法类似,但区域更大,包含了Main region,但去掉了Main region。VLR可以视为是Main region的向外扩张。
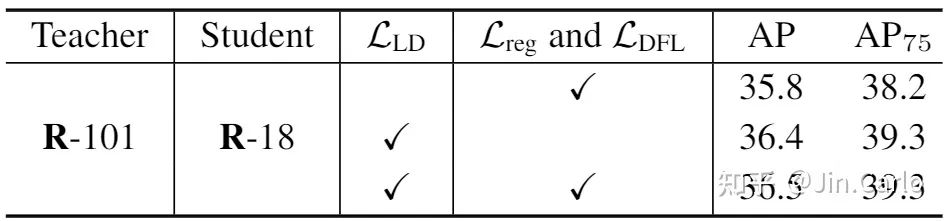
于是我们来探究一下在这两个区域上进行分类的KD与定位的LD会有什么效果。
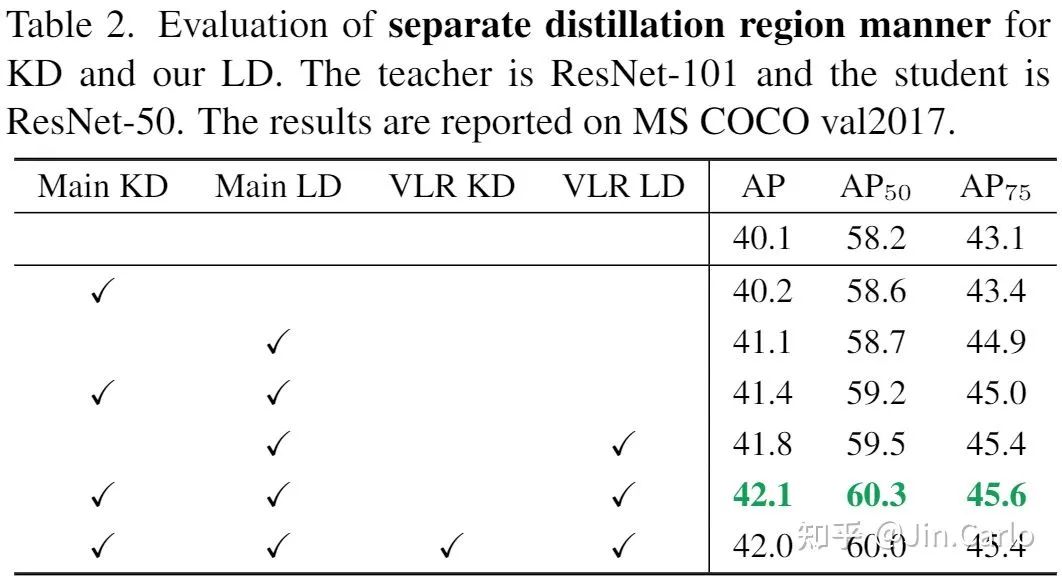
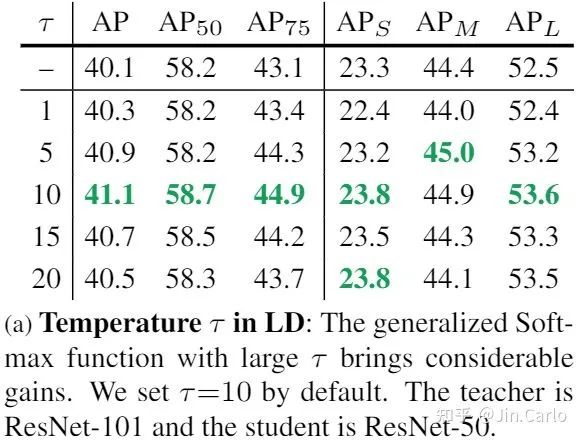
KD与LD在不同区域上的蒸馏效果
这个表格是本文的一大精髓所在,有几个有趣的现象。
-
可以看到在Main区域上,KD与LD均有效,说明在这个区域上传递分类或定位知识都有好处。但明显LD提升更大,说明定位知识的传递更有利于性能的提升。
-
VLR上LD也有效,这也是为什么我们把这样的区域命名为有价值定位区域。但VLR KD的加入却损害了性能。
于是就得到了本文的logit mimicking策略,Main KD + Main LD + VLR LD
有了这个logit mimicking策略,我们可以与Feature imitation对比一下
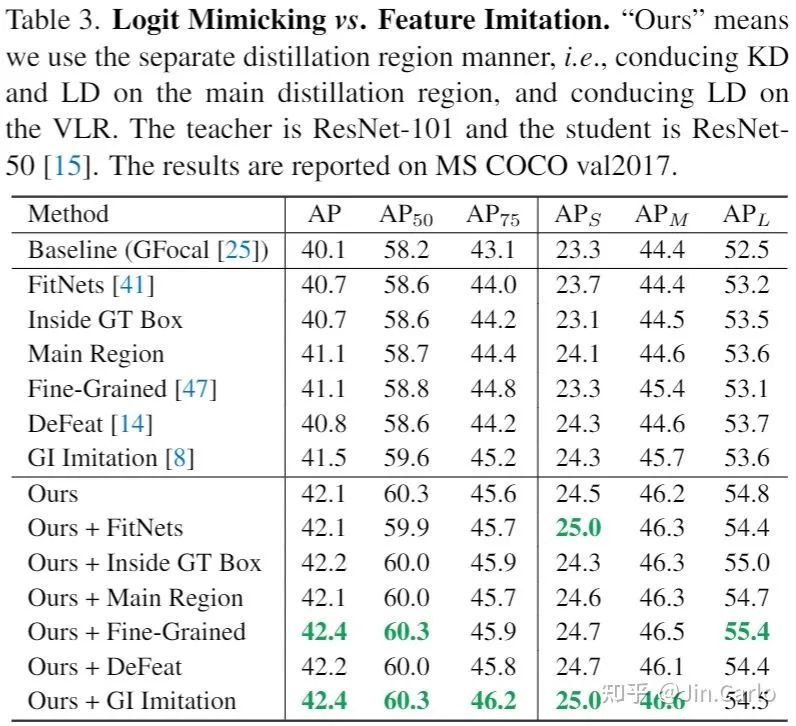
这个实验首次展示了logit mimicking的巨大潜力,也说明了logit mimicking多年以来的蒸馏效率低下的原因是缺少有效的定位知识传递。当引入了LD后,弥补了这一缺陷,logit mimicking居然可以超过Feature imitation。
当然上表也展示了,最优的蒸馏策略依然是logit mimicking与Feature imitation都用上。只是可以注意到的是,在有了logit mimicking之后,各个Feature imitation的性能差异也不是很明显了,选择哪个蒸馏区域都差不了多少。
下图展示的是student与teacher的平均分类误差与定位误差。
可以看到一些代表性Feature imitation方法(如Fine-Grained,GI)确实可以同时降低分类误差与定位误差。在仅用上LD时,定位误差得到明显下降,但分类误差无法降低也是可以理解的。而在进一步用上了KD之后,两个误差都得到了明显下降。
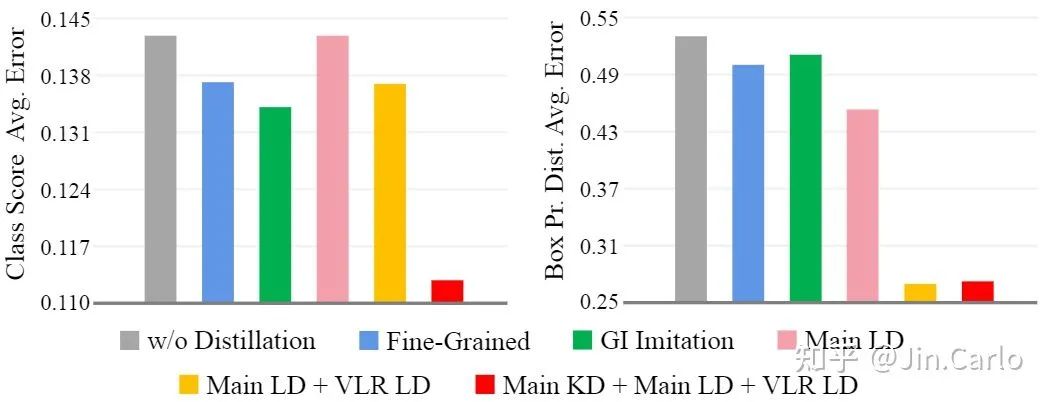
分类score误差与bbox定位误差
下图则是在两个FPN层级上的定位误差可视化
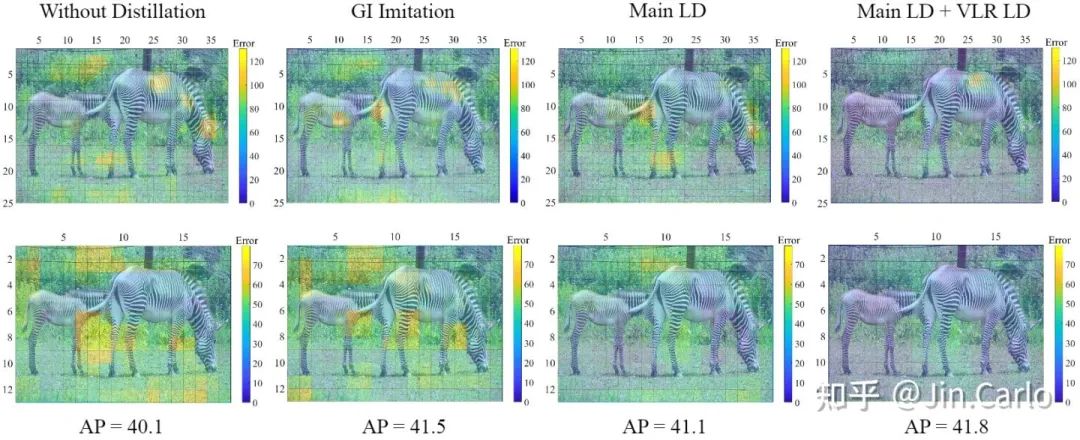
定位误差,越暗越好
四、一些有意思但不知何用的东西-
LD loss对定位的指导可以取缔bbox regression,即不使用bbox regression亦可超过baseline. (这表明teacher bbox分布的监督非常强悍)
2. VLR仅仅提供了分而治之蒸馏的初步解决方案,未来设计一种更优雅的区域选择机制,进行因地制宜地传递分类知识和定位知识或许是一个可供研究的方向。
3. LD的出现揭示了目标检测的分类知识与定位知识可以分开传递,这对其他领域(如实例分割)是否也存在第三种mask知识可供分别传递还有待研究。
有关LD更多的信息与insight,于3月末更新,敬请期待
本文仅做学术分享,如有侵权,请联系删文。
3D视觉精品课程推荐:
1.面向自动驾驶领域的多传感器数据融合技术
2.面向自动驾驶领域的3D点云目标检测全栈学习路线!(单模态+多模态/数据+代码) 3.彻底搞透视觉三维重建:原理剖析、代码讲解、及优化改进 4.国内首个面向工业级实战的点云处理课程 5.激光-视觉-IMU-GPS融合SLAM算法梳理和代码讲解 6.彻底搞懂视觉-惯性SLAM:基于VINS-Fusion正式开课啦 7.彻底搞懂基于LOAM框架的3D激光SLAM: 源码剖析到算法优化 8.彻底剖析室内、室外激光SLAM关键算法原理、代码和实战(cartographer+LOAM +LIO-SAM)
9.从零搭建一套结构光3D重建系统[理论+源码+实践]
10.单目深度估计方法:算法梳理与代码实现
11.自动驾驶中的深度学习模型部署实战
12.相机模型与标定(单目+双目+鱼眼)
13.重磅!四旋翼飞行器:算法与实战
14.ROS2从入门到精通:理论与实战
重磅!3DCVer-学术论文写作投稿 交流群已成立
扫码添加小助手微信,可申请加入3D视觉工坊-学术论文写作与投稿 微信交流群,旨在交流顶会、顶刊、SCI、EI等写作与投稿事宜。
同时也可申请加入我们的细分方向交流群,目前主要有3D视觉、CV&深度学习、SLAM、三维重建、点云后处理、自动驾驶、多传感器融合、CV入门、三维测量、VR/AR、3D人脸识别、医疗影像、缺陷检测、行人重识别、目标跟踪、视觉产品落地、视觉竞赛、车牌识别、硬件选型、学术交流、求职交流、ORB-SLAM系列源码交流、深度估计等微信群。
一定要备注:研究方向+学校/公司+昵称,例如:”3D视觉 + 上海交大 + 静静“。请按照格式备注,可快速被通过且邀请进群。原创投稿也请联系。

▲长按加微信群或投稿

▲长按关注公众号
3D视觉从入门到精通知识星球:针对3D视觉领域的视频课程(三维重建系列、三维点云系列、结构光系列、手眼标定、相机标定、激光/视觉SLAM、自动驾驶等)、知识点汇总、入门进阶学习路线、最新paper分享、疑问解答五个方面进行深耕,更有各类大厂的算法工程人员进行技术指导。与此同时,星球将联合知名企业发布3D视觉相关算法开发岗位以及项目对接信息,打造成集技术与就业为一体的铁杆粉丝聚集区,近4000星球成员为创造更好的AI世界共同进步,知识星球入口:
学习3D视觉核心技术,扫描查看介绍,3天内无条件退款

圈里有高质量教程资料、答疑解惑、助你高效解决问题
觉得有用,麻烦给个赞和在看~

