站在门口看一眼,AI就能脑补出房间里面长什么样:

是不是有线上VR看房那味儿了?
不只是室内效果,来个远景长镜头航拍也是so easy:

而且渲染出的图像通通都是高保真效果,仿佛是用真相机拍出来的一样。
最近一段时间,用2D图片合成3D场景的研究火了一波又一波。
但是过去的许多研究,合成场景往往都局限在一个范围比较小的空间里。
比如此前大火的NeRF,效果就是围绕画面主体展开。

这一次的新进展,则是将视角进一步延伸,更侧重让AI预测出远距离的画面。
比如给出一个房间门口,它就能合成穿过门、走过走廊后的场景了。

目前,该研究的相关论文已被CVPR2022接收。
输入单张画面和相机轨迹让AI根据一个画面,就推测出后面的内容,这个感觉是不是和让AI写文章有点类似?
实际上,研究人员这次用到的正是NLP领域常用的Transformer。
他们利用自回归Transformer的方法,通过输入单个场景图像和摄像机运动轨迹,让生成的每帧画面与运动轨迹位置一一对应,从而合成出一个远距离的长镜头效果。
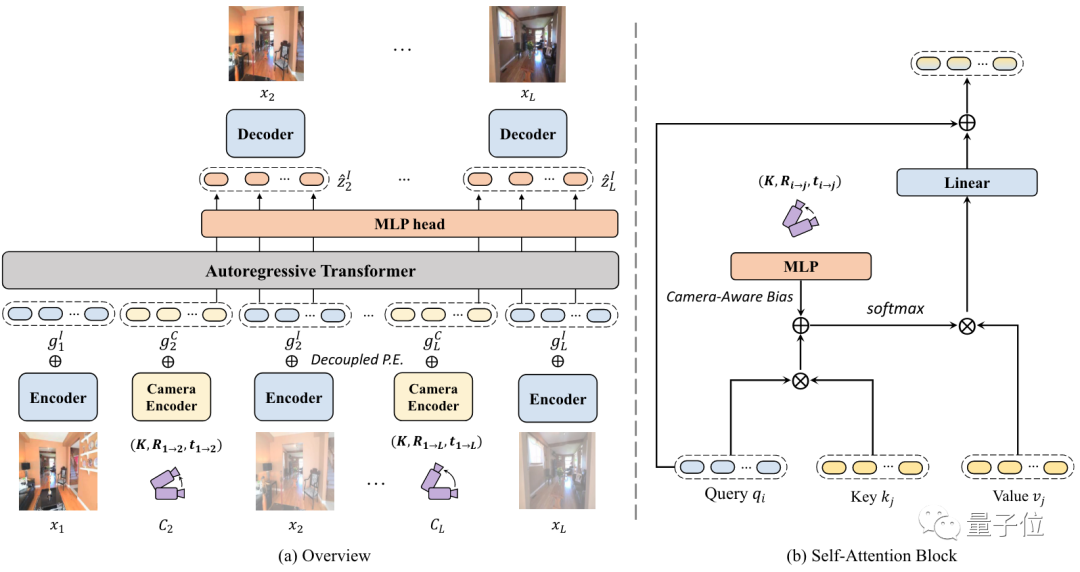
整个过程可以分为两个阶段。
-
第一阶段先预训练了一个VQ-GAN,可以把输入图像映射到token上。
VQ-GAN是一个基于Transformer的图像生成模型,其最大特点就是生成的图像非常高清。
在这部分,编码器会将图像编码为离散表示,解码器将表示映射为高保真输出。
-
第二阶段,在将图像处理成token后,研究人员用了类似GPT的架构来做自回归。
具体训练过程中,要将输入图像和起始相机轨迹位置编码为特定模态的token,同时添加一个解耦的位置输入P.E.。
然后,token被喂给自回归Transformer来预测图像。
模型从输入的单个图像开始推理,并通过预测前后帧来不断增加输入。
研究人员发现,并非每个轨迹时刻生成的帧都同样重要。因此,他们还利用了一个局部性约束来引导模型更专注于关键帧的输出。
这个局部性约束是通过摄像机轨迹来引入的。
基于两帧画面所对应的摄像机轨迹位置,研究人员可以定位重叠帧,并能确定下一帧在哪。
为了结合以上内容,他们利用MLP计算了一个“相机感知偏差”。
这种方法会使得在优化时更加容易,而且对保证生成画面的一致性上,起到了至关重要的作用。
实验结果本项研究在RealEstate10K、Matterport3D数据集上进行实验。
结果显示,相较于不规定相机轨迹的模型,该方法生成图像的质量更好。

与离散相机轨迹的方法相比,该方法的效果也明显更好。

作者还对模型的注意力情况进行了可视化分析。
结果显示,运动轨迹位置附近贡献的注意力更多。

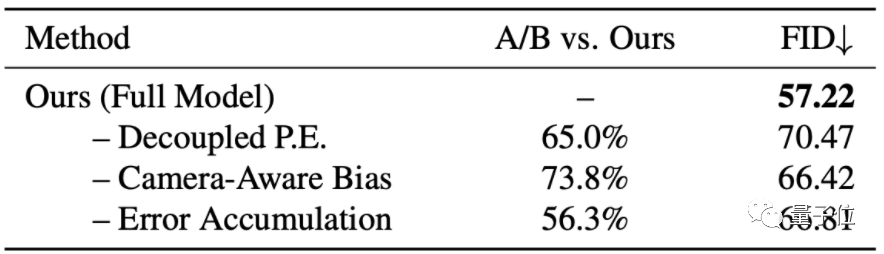
在消融实验上,结果显示该方法在Matterport3D数据集上,相机感知偏差和解耦位置的嵌入,都对提高图像质量和帧与帧之间的一致性有所帮助。
Xuanchi Ren为香港科技大学本科生。

他曾在微软亚研院实习过,2021年暑期与Xiaolong Wang教授有过合作。
Xiaolong Wang是加州大学圣地亚哥分校助理教授。

他博士毕业于卡内基梅隆大学机器人专业。
研究兴趣有计算机视觉、机器学习和机器人等。特别自我监督学习、视频理解、常识推理、强化学习和机器人技术等领域。
论文地址: https://xrenaa.github.io/look-outside-room/
本文仅做学术分享,如有侵权,请联系删文。
干货下载与学习
后台回复:巴塞罗那自治大学课件,即可下载国外大学沉淀数年3D Vison精品课件
后台回复:计算机视觉书籍,即可下载3D视觉领域经典书籍pdf
后台回复:3D视觉课程,即可学习3D视觉领域精品课程
3D视觉精品课程推荐:
1.面向自动驾驶领域的多传感器数据融合技术
2.面向自动驾驶领域的3D点云目标检测全栈学习路线!(单模态+多模态/数据+代码) 3.彻底搞透视觉三维重建:原理剖析、代码讲解、及优化改进 4.国内首个面向工业级实战的点云处理课程 5.激光-视觉-IMU-GPS融合SLAM算法梳理和代码讲解 6.彻底搞懂视觉-惯性SLAM:基于VINS-Fusion正式开课啦 7.彻底搞懂基于LOAM框架的3D激光SLAM: 源码剖析到算法优化 8.彻底剖析室内、室外激光SLAM关键算法原理、代码和实战(cartographer+LOAM +LIO-SAM)
9.从零搭建一套结构光3D重建系统[理论+源码+实践]
10.单目深度估计方法:算法梳理与代码实现
11.自动驾驶中的深度学习模型部署实战
12.相机模型与标定(单目+双目+鱼眼)
13.重磅!四旋翼飞行器:算法与实战
14.ROS2从入门到精通:理论与实战
重磅!3DCVer-学术论文写作投稿 交流群已成立
扫码添加小助手微信,可申请加入3D视觉工坊-学术论文写作与投稿 微信交流群,旨在交流顶会、顶刊、SCI、EI等写作与投稿事宜。
同时也可申请加入我们的细分方向交流群,目前主要有3D视觉、CV&深度学习、SLAM、三维重建、点云后处理、自动驾驶、多传感器融合、CV入门、三维测量、VR/AR、3D人脸识别、医疗影像、缺陷检测、行人重识别、目标跟踪、视觉产品落地、视觉竞赛、车牌识别、硬件选型、学术交流、求职交流、ORB-SLAM系列源码交流、深度估计等微信群。
一定要备注:研究方向+学校/公司+昵称,例如:”3D视觉 + 上海交大 + 静静“。请按照格式备注,可快速被通过且邀请进群。原创投稿也请联系。

▲长按加微信群或投稿

▲长按关注公众号
3D视觉从入门到精通知识星球:针对3D视觉领域的视频课程(三维重建系列、三维点云系列、结构光系列、手眼标定、相机标定、激光/视觉SLAM、自动驾驶等)、知识点汇总、入门进阶学习路线、最新paper分享、疑问解答五个方面进行深耕,更有各类大厂的算法工程人员进行技术指导。与此同时,星球将联合知名企业发布3D视觉相关算法开发岗位以及项目对接信息,打造成集技术与就业为一体的铁杆粉丝聚集区,近5000星球成员为创造更好的AI世界共同进步,知识星球入口:
学习3D视觉核心技术,扫描查看介绍,3天内无条件退款

圈里有高质量教程资料、答疑解惑、助你高效解决问题
觉得有用,麻烦给个赞和在看~ 


